【Linux】进程调度算法、进程切换、环境变量
前言
这篇文章聚焦 Linux 的进程调度算法、进程切换与环境变量:拆解调度规则如何分配 CPU 资源,解析进程切换的底层步骤,梳理环境变量对程序运行的影响,帮你理清这些机制在系统中的核心作用。
⚙️ Linux 进程篇
【 冯诺依曼体系 + 操作系统 】
【 进程概念 + PID + fork函数 】
【 进程状态 】
【 进程优先级 】
目录
------------进程调度------------
1、进程调度概念
2、位图(bitmap)中位的定位与状态判断
3、进程调度流程
------------进程切换------------
1、进程切换概念
2、进程上下文是什么?
3、cpu中的寄存器是什么?
【问题】:为什么函数返回值会被外部拿到?
【问题】:系统如何知道进程当前执行到哪行代码?
4、如何进行进程切换?
【小故事】:学生当兵
【进程切换核心步骤】
------------环境变量------------
1、环境变量概念
2、命令行参数
3、如何获取和设置环境变量?
4、环境变量的性质
< 继承性 >
< 全局属性 >
< 本地变量 >
< 内建命令和常规命令 >
< 模拟cd内建指令 >
------------进程调度------------
1、进程调度概念
进程调度就是:操作系统用调度算法从运行队列里挑个进程,把 CPU 执行权给它,让 CPU 去跑这个进程对应的代码
进程调度的必要性与作用
CPU 是 Linux 中稀缺的硬件资源,且无法同时处理多个任务,但终端、后台服务等进程都需要 CPU 运行 —— 这就是要做进程调度的原因。
调度的作用是:让多个任务看起来像同时在运行,避免 CPU 资源闲置浪费,同时确保高优先级任务(如系统服务)能优先获得 CPU 资源。
它是 Linux 实现多任务并发的核心 “指挥者”,也是连接待执行任务与 CPU 硬件的关键纽带。
2、位图(bitmap)中位的定位与状态判断

### 位图(bitmap)中位的定位与状态判断
在优先级调度的位图机制中,通过以下方式定位指定序号N对应的比特位,并判断其状态:
1. 定位所在char元素:
i = N / (sizeof(char)*8)
(sizeof(char)*8 是单个char的比特数,通常为8;i表示N对应的比特位所在的char数组下标)
2. 定位char内的比特位:
pos = N % (sizeof(char)*8)
(pos表示N在当前char元素中的具体比特位下标)
3. 判断比特位是否置1:
实际操作应为 b.bits[i] & (1 << pos)
(通过位运算判断该比特位是否被标记为1)3、进程调度流程
【简略版运行队列结构体】:

// 定义指针数组,存储运行状态进程的task_struct指针,最多140个
task_struct *running[140];
// 定义指针数组,存储等待状态进程的task_struct指针,最多140个
task_struct *waiting[140];这两个指针数组分别存储了140个优先级对应的进程队列;
普通优先级:我们只关心下标100~139(我们都是普通的优先级,想想nice值的取值范围,可与之对应!)
实时优先级:0~99(不关心)

进程被调度时,会按照从上到下,从左到右的顺序进行轮换调度,这个时候有人就会有疑问了,进程被调度时,如果调度过程中突然有新进程插进来怎么办?
其实完全不用担心新进程插入会打乱现有队列秩序 —— 这类新进程会被精准插入到waiting数组对应优先级的队列(和running数组完全一样),并且是直接追加到队尾,不会插队到当前正在排队的进程前面,原有进程的排队顺序完全不会被改动。

调度的顺序是先把running数组里的进程调度完,再去调度waiting数组里的进程。

这里的run和wait两个指针,就是用来管理这两个数组的:run指针负责指向running数组,wait指针负责指向waiting数组。等要切换调度的数组时,不用动数组里的进程数据,只需要把这两个指针存储的地址交换一下,就能从调度running数组的进程,切换到调度waiting数组的进程了。
进程调度流程
1、选进程运行
遍历普通优先级队列queue[100~139],取首个非空队列的队首进程,通过上下文切换使其进入运行态(R 态),占用 CPU 执行。
2、进程切换触发条件
进程运行中,触发任意情况则立即切换:
被动切换 1:当前进程时间片耗尽;
被动切换 2:有更高优先级进程就绪(抢占 CPU);
主动切换:当前进程请求 I/O/ 调用
sleep()(主动放弃 CPU)。
3、切换后的收尾处理
完成切换后,对原运行进程做状态 + 队列安置:
时间片耗尽:保持 R 态,尾插到原优先级队列队尾;
被抢占:保持 R 态,回到原优先级队列队首;
主动放弃 CPU:进入可中断睡眠态(S 态),移出运行队列(runqueue),加入等待队列(waitqueue)。
4、循环调度
回到调度起点,重复步骤 1,从运行队列选新进程运行。
进程调度算法是基于优先级的时间片轮转的核心逻辑规则,定义了 “选进程、定切换时机、处理切换后进程” 的策略,是整个调度行为的决策依据;
进程调度流程是算法的落地执行步骤,将算法的抽象规则转化为 “选进程→触发切换→收尾处理→循环调度” 的可执行序列;
进程切换是流程中的核心执行操作,负责完成 CPU 执行权在进程间的实际交接,是算法决策的落地动作。
三者关系可概括为:算法定规则,流程走步骤,切换做动作。
时间复杂度分析
若直接遍历queue[140](即使只看[100,139]区间),虽然时间复杂度属于常数级,但每次都要逐个检查队列是否为空,实际执行效率并不高。
因此这里引入了位图优化:用char bits[5](共 40 个比特位),让每个比特位对应一个优先级队列 —— 比特位为 1 表示对应队列非空,为 0 则表示队列为空。
借助这种方式,无需遍历数组,直接通过位运算就能快速定位到第一个非空队列,彻底解决了 “遍历判空效率低” 的问题。

这整个流程是标准的 O (1) 调度算法:从位图快速定位非空队列、调度时直接取队列头进程执行,到新进程队尾插入、交换 run/wait 指针切换调度数组,所有关键操作均只需固定步数完成,耗时与进程 / 队列数量无关,整体为常数时间复杂度。
------------进程切换------------
1、进程切换概念
进程切换:操作系统中,CPU 从正在执行的 A 进程,暂停其运行并切换到 B 进程继续执行的核心操作。
核心是 “保存 + 加载” 上下文:先把 A 进程的运行现场(执行位置、寄存器数据、地址映射等)保存到进程控制块(PCB),再从 B 进程的 PCB 中加载其上下文并恢复,让 B 进程从上次暂停的节点无缝继续执行,最终实现多进程 “并发”(宏观同时运行,微观 CPU 轮流执行)。
2、进程上下文是什么?
进程上下文:进程运行的完整 “现场快照”,是进程能被暂停后无缝恢复执行的核心依据,包含进程继续运行所需的所有关键信息,可分为四大类核心组成(每类都对应实际运行必需的功能)
1、CPU 执行相关(核心中的核心)
- 程序计数器(PC):记录 CPU 下一条要执行的指令地址,确保恢复时知道 “从哪继续跑”。
- 通用寄存器:存储当前执行的中间数据(比如计算结果、变量值),切换时必须完整保存 / 恢复,否则数据丢失。
- 状态寄存器、栈指针(SP)、基址指针(BP):记录 CPU 运行状态、栈空间地址范围,保障函数调用、数据存取的连续性。
2、内存映射相关
- 页表:记录进程虚拟地址与物理内存地址的映射关系,确保恢复后 CPU 能精准找到进程的代码、堆、栈数据。
- 地址空间信息:进程专属的虚拟地址范围(如代码段、数据段、堆、栈的边界),避免与其他进程内存冲突。
3、进程资源相关
- 打开的文件句柄:比如进程正在读写的文件、网络套接字,切换后仍能正常操作这些资源。
- 信号掩码与处理函数:记录进程能响应的信号、以及信号触发后的处理逻辑,避免信号处理混乱。
- I/O 设备状态:如打印机、键盘等设备的连接状态,确保恢复后 I/O 操作能继续
4、进程管理相关
- 进程状态(R/S/D/T 等):标记进程当前是就绪、阻塞还是运行态。
- 优先级与时间片:决定进程下次被调度的顺序和可占用 CPU 的时长。
- 进程控制块(PCB)指针:上下文的所有信息最终都存储在 PCB 中,切换时直接操作 PCB 即可。
总之,进程上下文就是进程运行的完整现场快照,核心目的是让进程被切换后重新调度时,能无缝衔接上次的执行状态,就像从未被打断过一样。
3、cpu中的寄存器是什么?
CPU 寄存器是CPU 内部的高速存储单元,用于临时存放进程运行的关键数据(属于进程上下文的核心部分),特点是速度远快于内存,主要作用是支撑进程的高效执行:
和进程的关系:寄存器里存的是当前进程的临时数据,属于进程上下文的一部分 —— 进程切换时,这些数据会被保存到 PCB,恢复时再加载回寄存器,确保进程能无缝续跑。
【问题】:为什么函数返回值会被外部拿到?
函数执行完
return a(对应mov eax 10)后,外部代码会把寄存器(如 EAX)中的值 “拷贝” 到自己的变量中—— 比如外部写int b = func(),汇编层面会执行mov b, eax,把 EAX 里的返回值拷贝到变量b的内存地址中。
【问题】:系统如何知道进程当前执行到哪行代码?
靠程序计数器(PC/EIP 寄存器):这个寄存器专门记录 “当前进程正在执行的指令的下一行指令地址”;进程运行时,CPU 会根据 PC/EIP 的地址取指令执行;进程切换时,PC/EIP 的值会随上下文保存,恢复时就能精准回到上次的执行位置。
4、如何进行进程切换?
【小故事】:学生当兵
你是个大二高个男生,某天在食堂门口瞥见 “大学生士兵招募” 的海报 —— 服役一年就能返校接着读书,你揣着好奇报了名,居然一路通关选上了。
兴奋冲昏了头,你踹开宿舍门吼:“哥几个,我去当兵了!明年见!” 转身就走 —— 可转念一想:这一年不上课、不考试,回来怕是要被退学。
赶紧找辅导员救命,他一拍桌子:“得先办‘保留学籍’!” 第二天,他塞给你个牛皮档案袋,沉甸甸的:“这里面是你这学期的成绩单、学到哪章的进度表,还有你的学籍信息 ——这袋东西就是你的‘全部家底’,退伍回来必须原封不动给我,我才能把你‘接回’大二。”
揣好档案袋,你才算踏实入伍。
一年后扛着行李返校,没急着进教室,先攥着档案袋找辅导员 —— 他对着袋里的进度表核对半天,把你塞进了这届大二的班级:“跟上,从你去年停的那章接着学。”
这个事儿,和操作系统里的 “进程切换” 简直是一个模子刻的:
☋. 你 = 进程:是要干的 “活儿”(你学知识,进程算数据);
☋. 那个档案袋 = 进程上下文:装着你 “接着干” 的所有信息(档案袋存学习进度,上下文存寄存器、执行位置);
☋. 办保留学籍 = 保存上下文:先把 “干活的状态” 存好;
☋. 去当兵 = 进程离开 CPU:暂时停下,把核心资源让出去;
☋. 返校复学 = 恢复上下文:把存好的状态调出来,接着从上次停的地方干。
说白了,进程切换不是 “说停就停、说开就开”—— 得先把 “干活的摊子” 收好,腾地方,回来再原样摆开接着干,就像你揣着档案袋去当兵,回来还能续上大二的课。
【进程切换核心步骤】
1、保存当前进程上下文:进程离开 CPU 时,将其寄存器、PC、内存映射等信息写入自身 PCB(相当于 “存档案”)
2、调度器选择目标进程:由进程调度器从运行队列队列中选一个待执行的进程
3、恢复目标进程上下文:从目标进程的 PCB 中,把之前保存的信息加载回 CPU 寄存器、更新内存页表(相当于 “取档案恢复状态”)
4、CPU 执行目标进程:目标进程从上次暂停的位置继续运行
------------环境变量------------
1、环境变量概念
环境变量,是操作系统为进程提供的一组 KV 键值对
格式:变量名 = 变量值(键名通常大写,值可是字符串、路径或路径列表)。
作用:动态传递配置(如路径、身份标识),替代硬编码,适配不同环境。
特点:全局可见(进程可继承)、可临时 / 永久修改,系统自带或用户自定义均可。
例:我们在编写 C/C++ 代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
问题 1:为什么系统指令不用加./就能直接执行,自己写的指令却需要?
因为系统中有
PATH环境变量,它存储了系统指令的默认搜索路径;执行指令时,系统会依次在PATH的路径中查找,找到对应程序就直接执行(系统指令在PATH路径里,所以不用加./);而自己写的指令不在PATH默认路径中,所以需要用./指定当前目录。
问题 2:如何查看环境变量?
echo $NAME(你的环境变量名称)
例:在终端执行
echo $PATH,即可显示PATH中所有的默认搜索路径(多个路径用冒号:分隔)。
问题 3:如何让自己写的指令不用加./就能执行?
将指令目录加入PATH(临时生效):
export PATH=$PATH:指令目录绝对路径
$PATH:保留原有路径
::分隔路径
指令目录:新增搜索路径


此时直接输入 mytest,无需加 ./ 即可执行,输出结果为 “我是一个进程:PID:15019”—— 这说明自定义指令已能通过 PATH 搜索到并正常运行。
问题 4:不小心覆盖了系统指令的默认搜索路径,怎么恢复?
只需重新登录 Xshell 即可恢复 —— 因为临时修改的
PATH仅在当前终端会话生效,会话关闭(重新登录)后会自动加载系统默认的PATH配置。
Linux 终端启动时,会从
/etc/profile(系统级配置文件)、~/.bashrc(用户级配置文件)等配置文件加载默认PATH到内存。临时修改PATH仅在当前终端内存生效(未改配置文件),关闭 / 重启终端后,新会话会重新加载配置文件里的默认PATH,临时修改失效。
问题 5:为什么登录系统后会直接进入家目录?
因为
$HOME环境变量记录了当前用户的家目录路径;系统登录流程会自动读取$HOME的值,然后切换到对应的目录(比如 root 用户的$HOME是/root,普通用户的$HOME是/home/用户名)。
问题6:echo $SHELL输出/bin/bash是什么意思?它的核心作用?
$SHELL是记录当前用户默认 Shell 程序的环境变量,输出/bin/bash表示:当前用户登录后默认用bash(程序路径为/bin/bash)进行命令交互。
env命令
作用:用于查看当前终端的所有环境变量
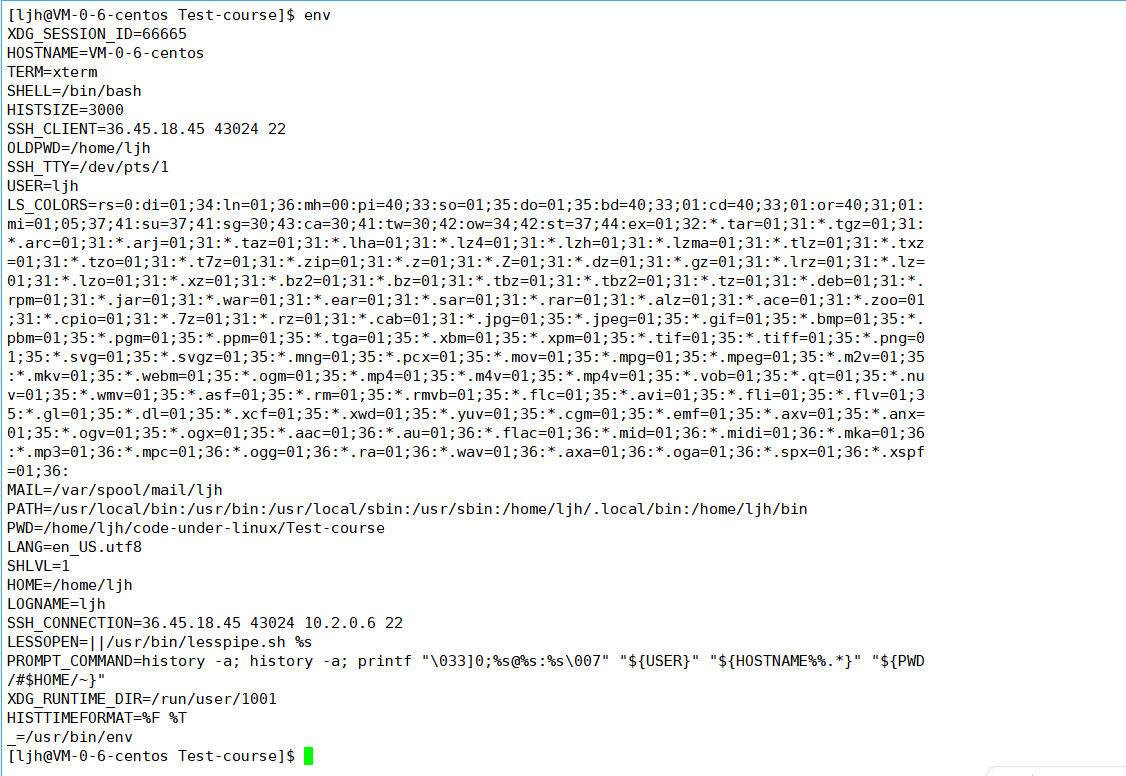
核心环境变量表格
| 环境变量名 | 核心作用 | 示例值 | 实用场景 |
|---|---|---|---|
| PATH | 系统搜索可执行命令的路径列表,决定输入命令时系统去哪里找程序 | /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin | 1. 不用加./ 直接执行自定义程序(需把程序路径加入 PATH);2. 系统指令(如 ls/cd)能直接执行的核心原因 |
| HOME | 当前用户的家目录路径,登录后默认进入的目录 | /home/ljh(普通用户)、/root(root 用户) | 1. cd ~/cd $HOME 一键回到家目录;2. 存储用户个人配置文件(如.bashrc) |
| SHELL | 当前用户默认使用的 Shell 解释器路径 | /bin/bash(最常用)、/bin/zsh | 决定终端的命令交互规则(如语法、快捷键),新手主要用 bash |
| USER | 当前登录的用户名 | ljh、root | 区分当前操作的用户身份,权限相关操作(如 sudo)会用到 |
| PWD | 当前所在的工作目录路径 | /home/ljh/code-under-linux/Test-course | 等同于 pwd 命令的输出,脚本中可动态获取当前目录 |
| LANG | 系统语言 / 字符编码设置 | en_US.utf8、zh_CN.utf8 | 决定终端 / 程序的字符显示格式(避免中文乱码) |
| TERM | 终端类型,适配终端的显示 / 交互规则 | xterm-256color | 确保终端能正常显示颜色、光标、快捷键等(Xshell/SSH 登录时自动适配) |
| LOGNAME | 当前登录用户的名称(和 USER 基本一致) | ljh | 脚本中判断当前操作用户身份 |
| OLDPWD | 上一次所在的工作目录路径 | /home/ljh | 执行 cd - 可一键回到上一次的目录,新手快速切换目录常用 |
| PS1 | 终端命令行提示符的格式(决定 [ljh@localhost ~]$ 这类显示) | [u@h W]$ | 自定义提示符样式(如显示当前路径、用户名),新手了解无需修改 |
| HISTSIZE | 控制终端保存的历史命令数量,是 “按上下键调取历史指令” 的功能源头 | 3000 | 1. 按↑/↓键快速调取之前执行过的命令;2. 调整数值可增加 / 减少历史命令的存储条数 |
环境变量如何被组织?

2、命令行参数
我们编写代码时写的 main 函数实际是有参数的,只不过我们先前用不到罢了 —— 而这些参数,对应的就是命令行参数:比如在终端执行./mytest arg1 arg2时,程序名./mytest后面跟着的arg1、arg2,就是命令行参数。这些内容会被传递给 main 函数的参数,让程序能根据输入的不同参数,执行对应的逻辑。

int argc(argument count)是记录终端执行程序时传入的命令行参数总数(程序名自身算第 1 个参数)
char* argv[](argument vector)是存储终端传入命令行参数的字符串数组,argv[0]是程序名 / 路径,argv[1]及以后是用户传入的参数,元素总数对应argc。

在 C 语言的char* argv[]数组中(该数组也被称为 “命令行参数表”),无论参数数量是多少,argv的最后一个有效元素的下一个位置(即argv[argc])会被系统自动初始化为 NULL。
执行
./test a b c时,argv数组会按顺序存:argv[0]="./test"(程序名)、argv[1]="a"、argv[2]="b"、argv[3]="c"(空格是参数分隔符,共拆成 4 个字符串)。
既然 main 函数可以接收 argc 和 argv 参数,这就直接证明 main 函数并非程序运行的 “原生起点”—— 程序启动时,操作系统先调用启动函数(如Startup()或CRTStartup(),不同编译环境命名略有差异),由这些启动函数完成程序运行前的基础初始化(比如内存分配、运行环境配置),最终再由启动函数主动调用 main 函数,并将命令行参数封装为 argc 和 argv 传递给它。
问题:为什么要让 main 函数支持命令行参数(argc/argv)?
核心是为指令、工具、软件等提供命令行选项的支持—— 通过在执行程序时传入不同参数,能让同一个程序实现不同功能。比如
ls -l(ls是程序,-l是命令行参数),传入-l就能让ls以详细列表形式显示文件,不传则是默认格式,灵活适配不同使用场景。
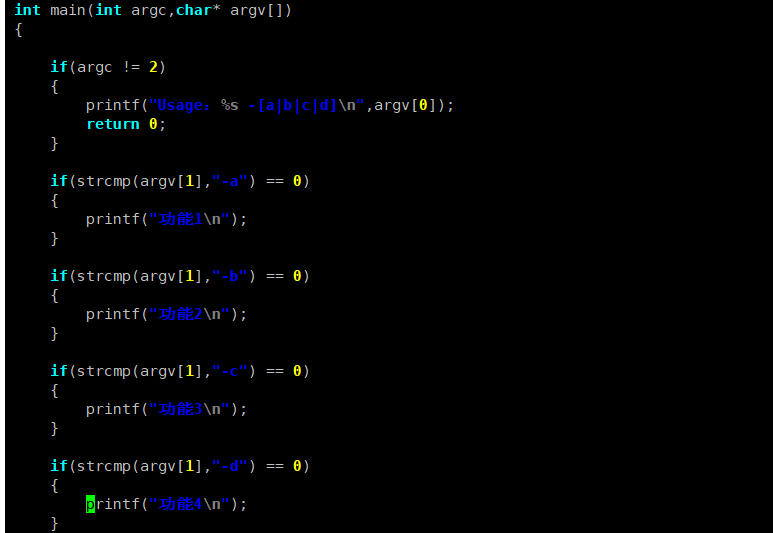

如果想实现多选项,可以用循环遍历所有参数 + 逐个匹配判断,示例代码:
#include
#include
int main(int argc, char* argv[])
{
// 1. 无参数时打印用法提示(argc=1 表示只有程序名)
if (argc == 1)
{
printf("Usage: %s -[a|b|c|d] [多个参数可叠加]
", argv[0]);
printf("示例: %s -a -b -c
", argv[0]);
return 1; // 退出程序,避免后续逻辑执行
}
// 2. 遍历所有传入的参数(i从1开始,跳过argv[0]程序名)
for (int i = 1; i < argc; i++)
{
// 逐个判断参数,匹配则执行对应功能
if (strcmp(argv[i], "-a") == 0)
{
printf("执行功能1(参数-a)
");
}
else if (strcmp(argv[i], "-b") == 0)
{
printf("执行功能2(参数-b)
");
}
else if (strcmp(argv[i], "-c") == 0)
{
printf("执行功能3(参数-c)
");
}
else if (strcmp(argv[i], "-d") == 0)
{
printf("执行功能4(参数-d)
");
}
else
{
// 3. 识别到非法参数时提示,并继续处理其他参数
printf("警告:无效参数 %s,仅支持 -a/-b/-c/-d
", argv[i]);
}
}
return 0;
} 环境变量参数
实际上,我们也可以通过main函数的环境变量参数(如char *envp[]),获取当前程序所在 bash 进程的所有环境变量。
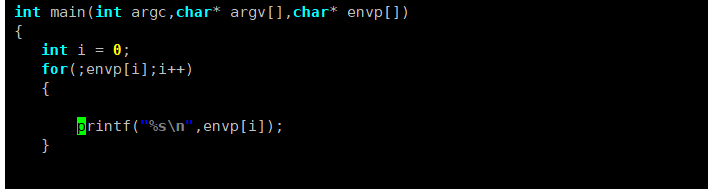
envp和argv是同类型的字符指针数组(都属于 “参数向量表”),envp对应的是环境变量表;由于环境变量的数量不固定,所以需要通过envp末尾的NULL指针来判断遍历的结束。
3、如何获取和设置环境变量?
问题:如何获取环境变量?
前面已经讲了 3 种获取环境变量的方式:
1、终端中通过echo命令(如echo $PATH),直接打印单个环境变量的值;
2、终端中通过env命令,查看所有环境变量的列表;
3、C 程序中通过main函数的环境变量参数(如char *envp[]),在代码中获取环境变量。
接下来我再讲解一种通过C语言接口获取环境变量的方法。

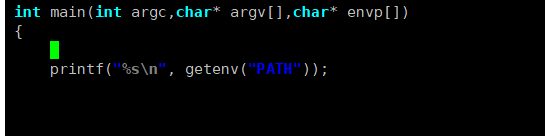

问题:如何设置环境变量?
1、临时添加环境变量(仅当前终端会话生效)
语法:
export 环境变量名=值示例:

说明:export标记变量为环境变量(子进程可继承),关终端后失效。
2、永久添加环境变量(所有终端会话生效)
需将设置指令写入 Shell 配置文件(以 Bash 为例):
编辑配置文件:
echo 'export 环境变量名=值' >> ~/.bashrc
示例:
echo 'export MYENV="hello world"' >> ~/.bashrc
✅ 当前终端进程想用新配置 → 必须执行 source ~/.bashrc(相当于 “给当前 Shell‘刷新内存’”);
✅ 不想执行 source → 直接关闭当前终端,重新打开新终端即可(新终端启动时会自动读取修改后的~/.bashrc)。
3、临时取消(仅当前终端生效,关闭终端即失效)
# 取消单个环境变量(比如你设置的MYENV)
unset MYENV
# 验证是否取消:输出为空则成功
echo $MYENV
如果想临时清空某个环境变量的值(而非彻底取消),可以直接赋值为空:
# 仅清空值,变量仍存在(不推荐,容易踩坑)
MYENV=""
# 验证:输出为空,但变量还在
env | grep MYENV # 仍能看到MYENV=
4、永久取消(所有终端生效,需删除配置文件中的定义)
针对你之前写到~/.bashrc里的export MYENV="hello world",操作步骤:
# 用vim打开~/.bashrc
vim ~/.bashrc
# 操作步骤:
# 1. 按G跳到文件最后一行
# 2. 找到你添加的export MYENV="hello world"这一行
# 3. 按dd删除该行(或在行首加#注释掉)
# 4. 按ESC → 输入:wq 保存退出
让修改生效:
# 刷新当前终端的配置(立即永久取消,不想用该指令重新打开终端也会生效)
source ~/.bashrc
# 验证:无论当前终端/新终端,echo $MYENV 都为空
echo $MYENV # 输出空注意:上述所有操作只针对当前用户
4、环境变量的性质
< 继承性 >
环境变量的继承性,是指父进程设置的环境变量,会自动传递给它启动的子进程:比如 Shell(父进程)用export定义的环境变量,它运行的程序(子进程)能通过getenv等方式读取到这个变量的值,实现环境配置的传递。
< 全局属性 >
环境变量的全局属性,指其在指定范围(系统级 / 用户级)内对所有终端、所有进程均有效且可继承的生效特性。
子进程会继承父进程的环境变量:


子进程对环境变量的修改不影响父进程:


问题:为啥子进程修改环境变量不影响父进程?
这是因为进程的环境变量是 “复制继承” 而非 “共享”,底层逻辑是:当父进程创建子进程时,会把自己的环境变量完整复制一份给子进程 —— 子进程拿到的是 “副本”,不是和父进程共享同一份数据。
< 本地变量 >
本地变量是仅在当前 Bash 进程内生效的变量(不加export的变量),不会被 Bash 的子进程继承。
证明本地变量不会被继承:
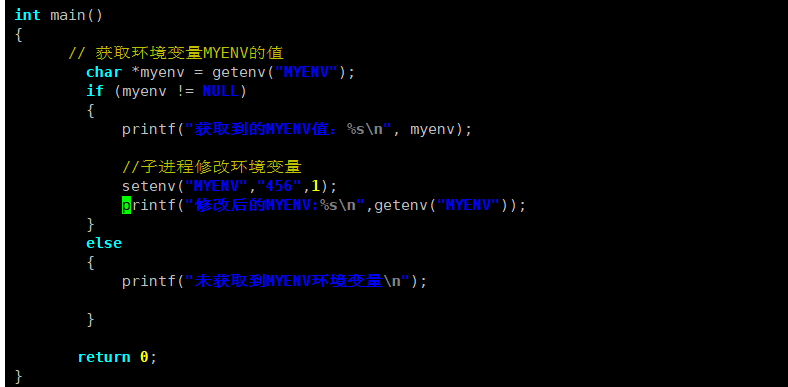

< 内建命令和常规命令 >
之前我们认为 “所有命令都会以 Bash 进程的子进程形式执行”,这个说法其实不准确。实际使用中,Shell 命令可以分为两类:常规命令和内建命令。
常规命令
常规命令的执行,是通过创建子进程来完成的—— 这些命令是独立的程序,Bash 会启动一个新的子进程,让子进程去运行这个程序,程序跑完子进程就结束。
内建命令
内建命令的执行,Bash 不会创建子进程,而是由 Bash 自己直接执行 —— 相当于 Bash 调用了自己内置的功能(类似 Bash 自己写好的函数),不用额外开新进程。


执行./test(常规命令)时,Bash 会创建子进程,但父进程的本地变量不会传给子进程,所以./test读不到MYENV;
而echo是内建命令,执行时 Bash 不会开子进程,直接在自身进程内运行,因此能访问到父进程的本地变量,所以echo $MYENV能输出123。
< 模拟cd内建指令 >
在 Shell 中,cd是内建指令,它的底层是通过chdir系统调用函数实现的。
chidr函数
原型:int chdir(const char *path);
功能:修改当前进程的工作目录
参数:path为目标路径(支持绝对 / 相对路径)
返回值:成功返回 0;失败返回 - 1 并设置errno标识错误
#include
#include
int main(int argc, char *argv[], char *envp[])
{
sleep(20); // 延迟,方便观察进程状态
printf("change begin
");
if (argc == 2) // 接收命令行参数作为目标路径
{
chdir(argv[1]); // 调用chdir修改当前进程的工作目录
}
sleep(20);
return 0;
} 
第一次(change begin前):指向的是原目录/home/lih/code-under-linux/Test-course;
第二次(change begin后):指向的是目标目录/home/lih—— 说明chdir确实成功修改了子进程的工作目录!
ls -ld /proc/[进程ID]/cwd作用:查看
cwd(进程工作目录的软链接)自身信息
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=4u7xbz032vy