基于多尺度因果膨胀卷积的变压器振动-电压时序预测算法(Pytorch)
实现了一个基于改进型时序卷积网络(TCN)的变压器振动数据到电压的预测方法。首先从多个MATLAB文件中加载不同电压等级下的变压器振动数据,按照时间顺序将每个文件的数据划分为训练集、验证集和测试集,并将所有文件的数据拼接在一起形成完整的数据集。
然后分别对振动特征和电压目标进行最小-最大归一化处理,使所有数据范围在0到1之间。接着采用滑动窗口方法将连续的时间序列数据分割为固定长度的样本,每个样本包含60个时间点的振动数据作为输入,对应的电压值作为输出标签。
算法核心是一个精心设计的改进型时序卷积网络,网络采用多尺度因果膨胀卷积架构,通过两层初始卷积层提取基础特征,然后经过多个TCN块进行深层特征提取,每个TCN块包含因果卷积、批量归一化、ReLU激活和Dropout正则化,并采用残差连接保持信息流动。TCN块的膨胀率呈指数增长,以捕获不同时间尺度的依赖关系。网络最后通过全局平均池化和三层全连接层生成最终的电压预测值。
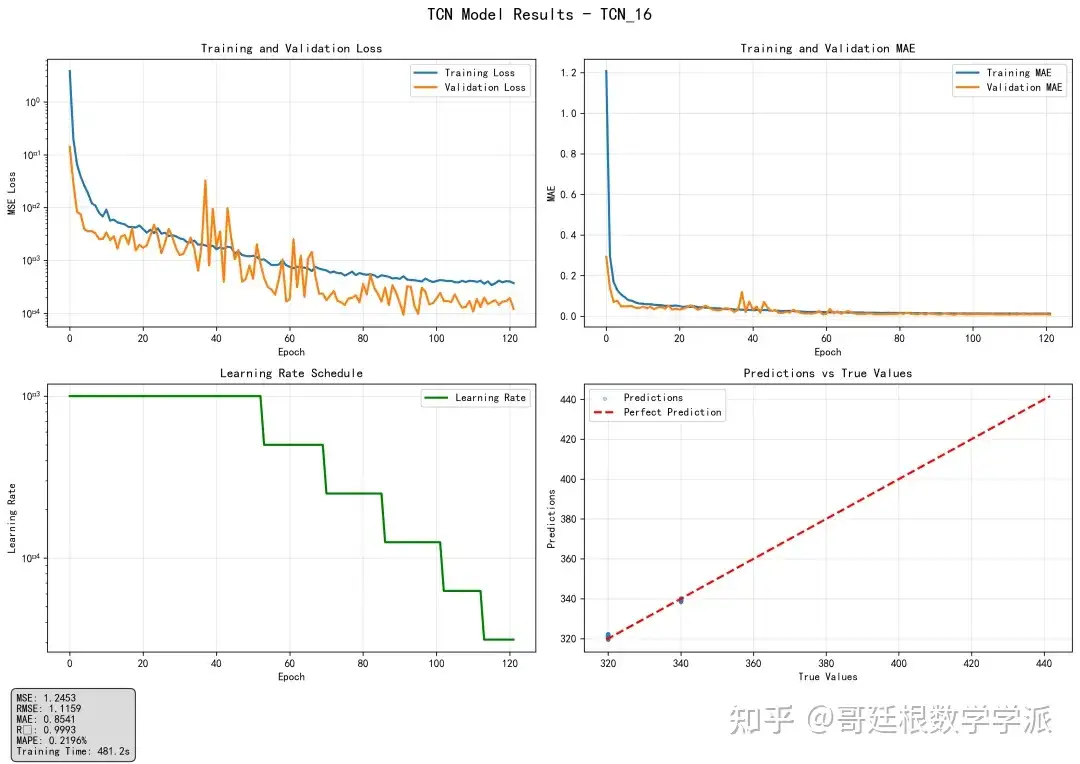
训练过程中采用AdamW优化器配合动态学习率调整策略,使用均方误差作为损失函数,并实施梯度裁剪防止梯度爆炸。每轮训练后在验证集上评估模型性能,当验证损失不再改善时降低学习率,连续多个epoch性能无提升时触发早停机制。训练完成后在测试集上全面评估模型性能,计算包括均方误差、平均绝对误差、平均绝对百分比误差、R²分数在内的多个指标,并反归一化到原始电压尺度进行分析。最后保存训练好的模型参数、训练历史记录和评估结果,并生成训练曲线、预测对比图、误差分布图等多种可视化图表供分析使用。
详细算法步骤
数据采集与加载阶段
读取七个不同电压等级(320V至440V)的MATLAB数据文件,每个文件包含变压器振动的时间序列数据和对应的电压标签。
数据预处理与划分阶段
将每个文件的数据按时间顺序分割为三部分:训练集、验证集和测试集,比例分别为9/16、3/16和4/16,然后将所有文件的数据分别合并形成完整的数据集。
特征工程与归一化阶段
将振动数据和电压标签分别提取为特征和目标,对振动特征使用训练集的最小最大值进行归一化,对电压目标也进行独立的归一化处理,确保所有数据处于0-1范围内。
时间序列样本构建阶段
采用固定窗口大小的滑动窗口方法,将连续的振动信号分割为60个时间点的样本片段,每个样本对应窗口结束时点的电压值作为预测目标。
改进TCN模型构建阶段
设计包含两层输入卷积层的网络结构,第一层卷积提取局部特征,第二层卷积进一步抽象特征,然后连接多个具有指数增长膨胀率的TCN块,每个TCN块内部采用因果卷积确保时序依赖性,配合批量归一化和ReLU激活,最后通过全局平均池化和三层全连接层输出预测结果。
模型训练优化阶段
使用AdamW优化器配合权重衰减正则化,以均方误差作为损失函数,实施梯度裁剪防止训练不稳定,采用动态学习率调整策略,当验证损失停滞时自动降低学习率,并设置早停机制防止过拟合。
模型评估与验证阶段
在独立的测试集上评估训练完成的模型,计算多个回归评估指标,包括均方误差、均方根误差、平均绝对误差、R²决定系数、相对误差和平均绝对百分比误差,并将所有指标反归一化到原始电压尺度进行解释。
结果可视化与保存阶段
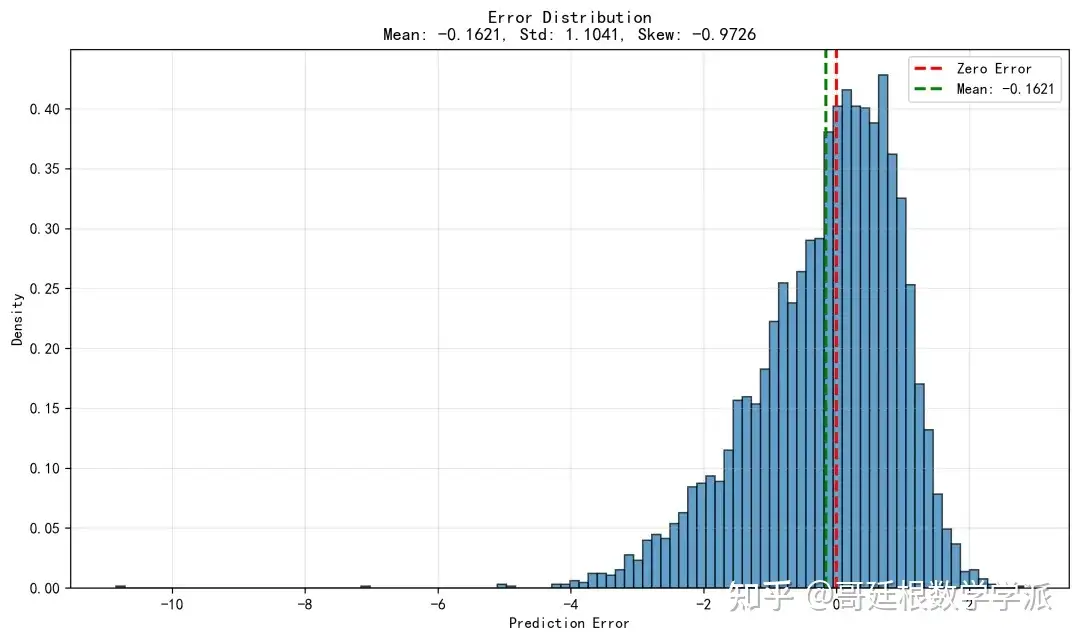
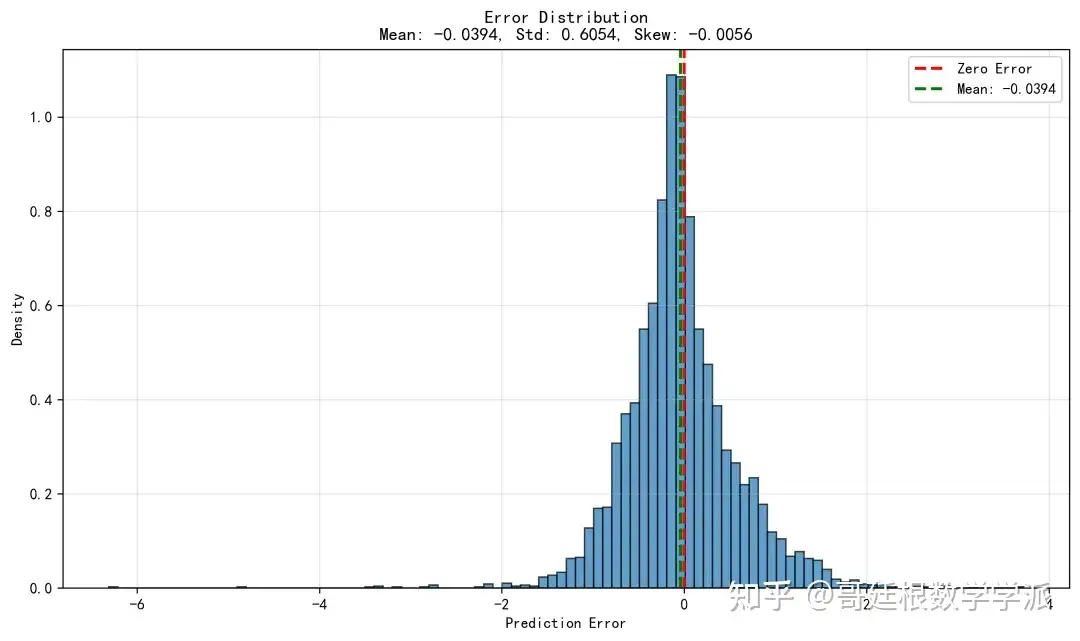
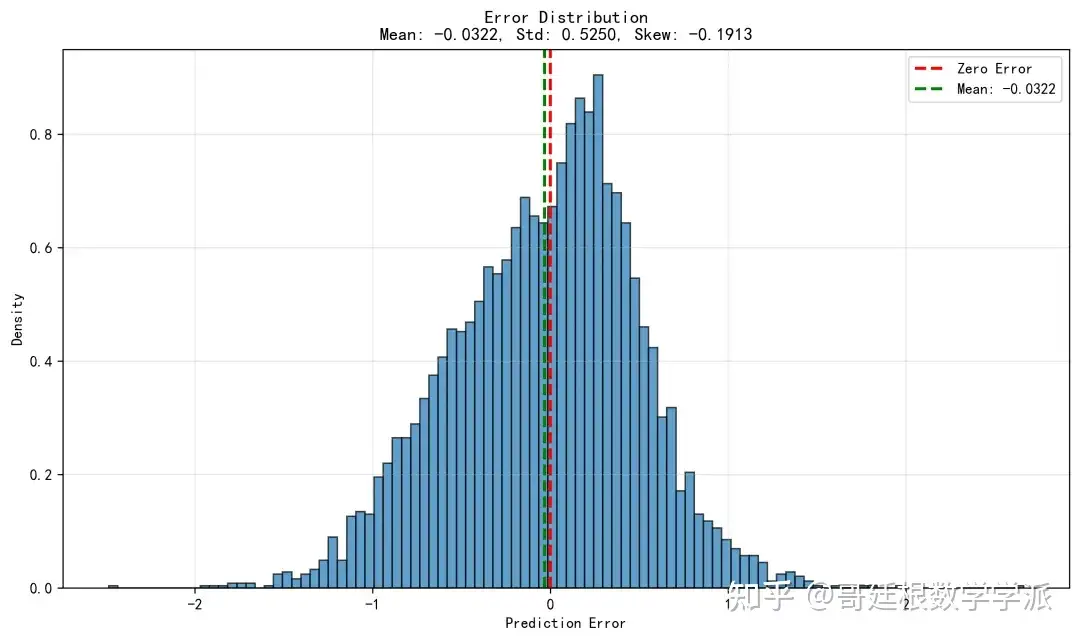
绘制训练损失曲线、验证损失曲线、学习率变化曲线、预测值与真实值对比散点图、误差分布直方图等多种图表,将所有模型参数、训练历史、评估指标和可视化结果保存到磁盘文件。
模型部署准备阶段
将最佳模型的结构、权重参数和归一化系数打包保存,确保模型可以独立加载并用于新数据的预测,同时记录完整的实验配置和超参数设置。
import os
import time
import json
import pickle
import warnings
from pathlib import Path
from typing import List, Tuple, Dict, Optional
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as io
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
# Suppress warnings for cleaner output
warnings.filterwarnings('ignore')
# Set device (GPU if available, otherwise CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# Set random seeds for reproducibility
torch.manual_seed(42)
np.random.seed(42)
if device.type == 'cuda':
torch.cuda.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# Data parameters
file_ind = ['320', '340', '360', '380', '400', '420', '440']
Fs = 3000
st = 0.02 # stationary interval in seconds
L = int(st * Fs) # block length (60 samples)
window = L # 60
step = 1
delay = 0
batch_size = 64
def load_and_preprocess_data():
"""Load and preprocess data from MATLAB files."""
data_train_list = []
data_valid_list = []
data_test_list = []
print("Loading and preprocessing data...")
start_time = time.time()
for file in file_ind:
# Load MATLAB file
f = io.loadmat('NoLoad_' + file + 'V.mat')
a = float(file) * np.ones((len(f['Data1_AI_0']), 1))
b = np.double(f['Data1_AI_0'])
N = len(b)
# Calculate indices for train/validation/test split
I = np.floor(N / L) - 1
Ntest = int(np.floor(I / 4))
Nvalid = int(np.floor(3 * I / 16))
Ntrain = int(I - Nvalid - Ntest)
# Calculate index boundaries
train_ind_max = Ntrain * L
valid_ind_max = train_ind_max + Nvalid * L
test_ind_max = valid_ind_max + Ntest * L
# Create data segments
data_temp_train = np.concatenate((a[0:train_ind_max], b[0:train_ind_max]), axis=1)
data_temp_valid = np.concatenate((a[train_ind_max:valid_ind_max],
b[train_ind_max:valid_ind_max]), axis=1)
data_temp_test = np.concatenate((a[valid_ind_max:test_ind_max],
b[valid_ind_max:test_ind_max]), axis=1)
data_train_list.append(data_temp_train)
data_valid_list.append(data_temp_valid)
data_test_list.append(data_temp_test)
# Concatenate all data
data_train = np.concatenate(data_train_list, axis=0)
data_valid = np.concatenate(data_valid_list, axis=0)
data_test = np.concatenate(data_test_list, axis=0)
# 分别归一化特征和目标
feature_min = data_train[:, 1].min()
feature_max = data_train[:, 1].max()
feature_range = feature_max - feature_min
feature_range = max(feature_range, 1e-8)
target_min = data_train[:, 0].min()
target_max = data_train[:, 0].max()
target_range = target_max - target_min
target_range = max(target_range, 1e-8)
print(f"Feature range: [{feature_min:.6f}, {feature_max:.6f}]")
print(f"Target range: [{target_min:.4f}, {target_max:.4f}]")
# 归一化数据
data_train[:, 1] = (data_train[:, 1] - feature_min) / feature_range
data_valid[:, 1] = (data_valid[:, 1] - feature_min) / feature_range
data_test[:, 1] = (data_test[:, 1] - feature_min) / feature_range
data_train[:, 0] = (data_train[:, 0] - target_min) / target_range
data_valid[:, 0] = (data_valid[:, 0] - target_min) / target_range
data_test[:, 0] = (data_test[:, 0] - target_min) / target_range
print(f"Data preprocessing completed in {time.time() - start_time:.2f} seconds")
print(f"Training data shape: {data_train.shape}")
print(f"Validation data shape: {data_valid.shape}")
print(f"Test data shape: {data_test.shape}")
# 保存归一化参数
normalization_params = {
'feature_min': float(feature_min),
'feature_max': float(feature_max),
'feature_range': float(feature_range),
'target_min': float(target_min),
'target_max': float(target_max),
'target_range': float(target_range)
}
return data_train, data_valid, data_test, normalization_params


参考文章:
基于多尺度因果膨胀卷积的变压器振动-电压时序预测算法(Pytorch) - 哥廷根数学学派的文章
https://zhuanlan.zhihu.com/p/2000178114500788848
工学博士,担任《Mechanical System and Signal Processing》审稿专家,担任
《中国电机工程学报》优秀审稿专家,《控制与决策》,《系统工程与电子技术》,《电力系统保护与控制》,《宇航学报》等EI期刊审稿专家。
擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。