ubuntu离线安装Ollama并部署Llama3.1 70B INT4并对外发布服务
文章目录
- 1.安装Ollama
- 1.1 下载
- 1.2 验证Ollama是否安装完成
- 2. 配置大模型
- 2.1 下载所需要的大模型文件
- 2.2 加载`.GGUF`文件(推荐、更容易)
- 2.3 加载`.Safetensors`文件(不建议使用)
- 3. 使用ngrok发布大模型服务
- 3.1 配置环境变量使Ollama可以供外部调用
- 3.2 验证大模型是否可以在内网访问
- 3.3 安装ngork
- 3.4 在本机、非内网环境下验证
- 3.5 在外部设备、非内网环境下验证
- 3.6 在外部设备、内网环境下验证
- 3.7 在外部设备、非内网环境下验证
- 3.8 ngrok设置固定域名
- TODO List
- 4、使用open webui交互界面集成llama3/qwq32b模型
- 4.1 解决openwebui中模型输出不会停止的问题
- -------------------------------------下面内容供参考-------------------------------------------
- 4. 下载安装Ollama的安装命令文件install.sh
- 5. 安装并验证Ollama
- 6. 配置大模型文件
- 7. 模型文件合并
参考:
1、 如何在离线的Linux服务器上部署 Ollama,并运行 Qwen 大模型(附教程)
2、 【三步搭建 本地 编程助手 ollama + codegeex】
本文的目的:记录将Ollama和Llama3.1 70B INT4版本离线安装在一台有4张A5000显卡的Ubuntu20.04系统上,并使用ngrok实现外部设备可以免费调用大模型
在实际安装的过程中,还是对能力有一些要求的
比如:
1、熟悉ollama的命令
2、熟悉linux的一些命令,如tar、chmod、touch、cat、curl 、vim、nvidia-smi -l
3、了解浏览器的请求方法和如何用post方法请求一个地址
可以参考:
1、Ollama命令总结
2、Linux vi中 wq 、wq!、x、q、q!区别
3、
#查看Linux版本号
cat /proc/version
#查看cpu架构
lscpu
1.安装Ollama
1.1 下载
版本:v0.5.11
下载地址:https://github.com/ollama/ollama/releases
文件:ollama-linux-amd64.tgz
下载好之后,解压该文件
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
给这个文件添加权限:
sudo chmod +x /usr/bin/ollama # 这条命令没有用到
根据下面的文章进行操作:Ollama系列—【如何离线安装ollama?】按这个
操作完了就可以直接,下载大模型文件了
(上面的方法不用下载和执行install.sh,下面还有一种安装install.sh的ollama的安装方法)
1.2 验证Ollama是否安装完成
应该使用
本机ip:11434
在浏览器中打开即可验证,如果出现Ollama is running,则表示Ollama安装完成
2. 配置大模型
2.1 下载所需要的大模型文件
在下载模型前首先需要清楚Ollama是如何加载离线的大模型的
使用ollama导入模型话,有两种的大模型的文件格式可以使用,分别是GGUF和Safetensors文件(Safetensors文件需要使用llama.cpp先转换为GGUF文件才行)
分别对两种下载并导入到Ollama中的方式进行介绍:
1)下载对应的Llama-3.1-70B、INT4计算精度的GGUF文件:Meta-Llama-3.1-70B-Instruct-Q4_K_M.gguf
下载地址:https://www.modelscope.cn/models/lmstudio-community/Meta-Llama-3.1-70B-Instruct-GGUF/files
2)下载的Safetensors文件:Meta-Llama-3.1-70B-Instruct-GPTQ-INT4:
下载地址:https://hf-mirror.com/hugging-quants/Meta-Llama-3.1-70B-Instruct-GPTQ-INT4/tree/main
2.2 加载.GGUF文件(推荐、更容易)
可以参考:Ollama自定义导入DeepSeek-R1-Distill-Qwen-1.5B模型(第二部分)
下面是上面的博主给的:
创建Modelfile文件,并写入以下内容:
FROM ./deepseek-r1-distill-qwen-1.5b-q2_k.gguf # 以deepseek模型文件为例
执行下面命令来验证
ollama create my_DeepSeek-R1-Distill-Qwen-1.5B -f Modelfile
ollama ls
ollama run my_DeepSeek-R1-Distill-Qwen-1.5B
下面是实际的操作:
在uugf文件同一个目录下创建Modelfile文件,
touch Modelfile
使用插入模式i,并写入以下内容:
FROM ./Meta-Llama-3.1-70B-Instruct-Q4_K_M.gguf #
在uugf文件同一个目录下执行下面命令来验证
ollama create llama-70B-INT4 -f Modelfile
ollama ls
ollama run llama-70B-INT4
2.3 加载.Safetensors文件(不建议使用)
Ollama 仅支持 GGUF 格式的模型,因此需使用llama.cpp库将 .safetensors 转换为 .gguf 格式:
因为好像需要llama.cpp对该文件进行处理,比较麻烦就不介绍了,之后遇到这种情况,就在这里记录
可以参考:Ollama自定义导入DeepSeek-R1-Distill-Qwen-1.5B模型(第三部分)
3. 使用ngrok发布大模型服务
3.1 配置环境变量使Ollama可以供外部调用
首先设置环境变量,一般是在/home/用户/.bashrc保存环境变量,使用
vim /home/用户/.bashrc
打开.bashrc文件
添加
export OLLAMA_HOST=0.0.0.0
export OLLAMA_MODELS=/放置模型权重文件的路径/ollama/models # models里面放了模型文件,如Meta-Llama-3.1-70B-Instruct-Q4_K_M.gguf
修改完后,退出vim,使用
source /home/用户/.bashrc
来更新这个bashrc文件
之后重启 ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama
systemctl是一个用于控制系统服务(systemd services)的命令工具。systemd是Linux系统中常用的初始化系统(init system),它负责管理系统启动过程和运行时的服务。
daemon-reload是systemctl命令的一个参数选项。daemon-reload的作用是重新加载系统服务的配置文件。当你修改了服务的配置文件(比如.service文件)后,需要运行这个命令来让systemd重新读取配置,这样新的配置才能生效。restart命令用于重启系统服务。这个命令是systemd的一部分,systemd是一个系统和服务管理器,用于替代传统的init系统。通过systemctl,用户可以启动、停止、重启和管理各种系统服务。使用命令systemctl restart服务名称。例如,要重启Apache服务,可以使用systemctl restart apache2
重启完成后,启动大模型
ollama run llama-70B-INT4
3.2 验证大模型是否可以在内网访问
在浏览器输入
your-ip:11434 # 11434 is the port of ollama
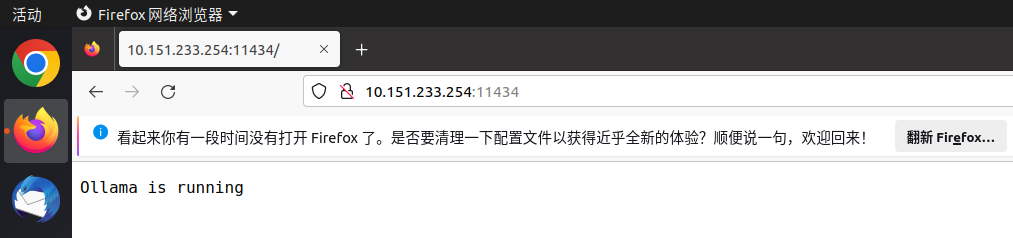
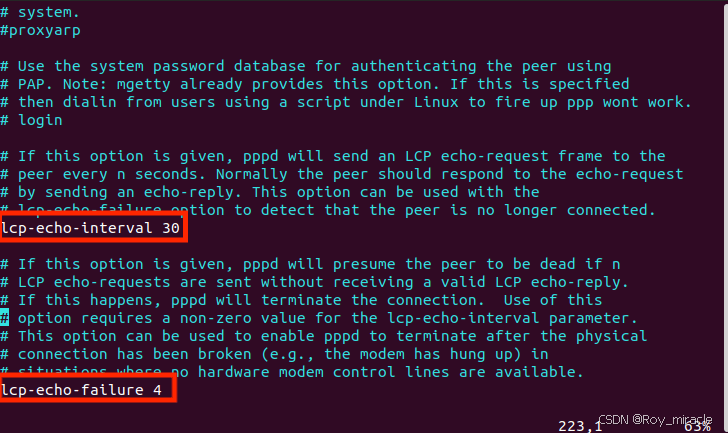
出现Ollama is running则表示Ollama可以被内网访问
同时还需要验证Ollama是否暴露了接口,验证方法是
your-ip:11434/api/chat # ollama exposes the interface
使用post方法去请求上面的地址,有两种方法可以尝试。如下
方法1:命令行
curl
-X POST http://10.151.233.254:11434/api/chat
-H "Content-Type:application/json"
-d '{"model":"llama-70B-INT4",
"messages":[
{"role":"user",
"content":"你好,你是谁"}
]
}'
在输入时去掉上面的空格和换行,上面只是为了展示命令行内都包含哪些内容,此时返回

出现上面原因的是没有设置去阻止它每个token的逐个输出
使用
curl
-X POST http://10.151.233.254:11434/api/chat
-H "Content-Type:application/json"
-d '{"model":"llama-70B-INT4",
"messages":[
{"role":"user",
"content":"你好,你是谁"}
]
"stream":false # 多了这里一个参数
}'
上面的false不能使用首字母大写,也不能加双引号
回复:
{"model":"llama-70B-INT4",
"created_at":"2025-02-28T06:23:52.387001243Z",
"message":{"role":"assistant",
"content":"很高兴认识您!我是一个人工智能语言模型,我的名字叫做“LLaMA”,这是一个由Meta公司开发的聊天机器人。我可以理解和回答您的提问,提供信息,完成任务,并进行简单的对话。"
},
"done_reason":"stop",
"done":true,
"total_duration":4626183582,
"load_duration":36728356,
"prompt_eval_count":15,
"prompt_eval_duration":69000000,
"eval_count":57,
"eval_duration":4518000000}

方法2:代码
from abc import ABC, abstractmethod
import json
import requests
def ollama_api(url, model_name, prompt):
headers = {
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json"
}
json_input = {
"model": model_name,
"messages": [{
"role": "user",
"content": prompt
}],
"stream": False
}
while True:
response = requests.post(url,
headers=headers,
data=json.dumps(json_input))
try:
response_json = response.json()
content = response_json.get("message", {}).get("content", "")
content = json.loads(content)
print(content)
return content
except (json.JSONDecodeError, ValueError):
print("error")
break
url = "http://10.151.233.254:11434/api/chat"
model_name = "llama-70B-INT4"
prompt = "hello!"
response = ollama_api(url, model_name, prompt)
print(response)
输出
3.3 安装ngork
注册并登录ngrok网站:https://dashboard.ngrok.com/get-started/setup/linux
下载ngrok-v3-stable-linux-amd64.tgz,并将该文件加压到、/usr/local/bin目录下
运行下面的命令可以将自己的authtoken添加为ngrok.yml文件中
ngrok config add-authtoken your-authtoken(这个authtoken在ngrok官网上获取)
配置结果:

执行下面命令,通过 ngrok 工具将本地计算机上的 11434 端口暴露到公网,从而允许外部设备通过互联网访问该端口上的服务。
ngrok http 11434
执行上面命令后会出现
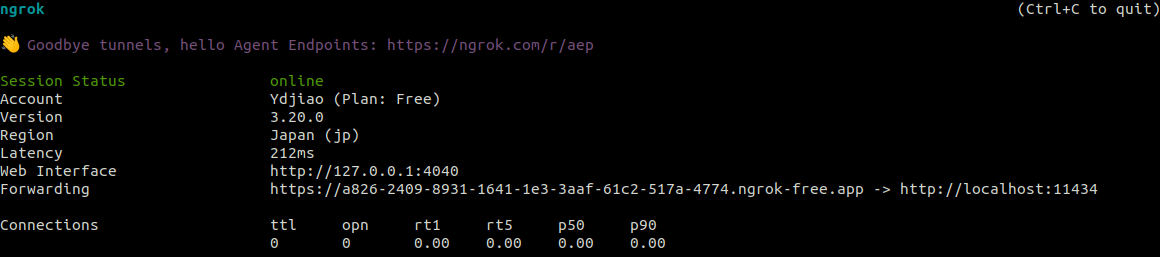
服务器在非公司内网的环境下执行以上命令,其他设备也不连公司网络,可以通过访问
3.4 在本机、非内网环境下验证
# 本机可通过以下进行验证
localhost:11434
或
127.0.0.1:11434
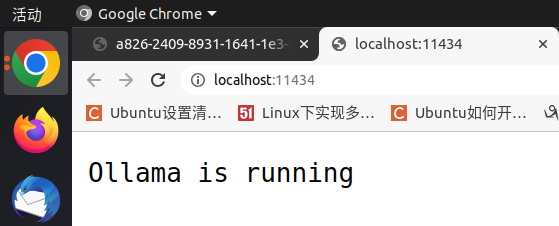
# 本机或其余设备都可通过以下命令来验证
http//a826-2409-8931-1641-1e3-3aaf-61c2-517a-4774.ngrok-free.app/
本机验证:
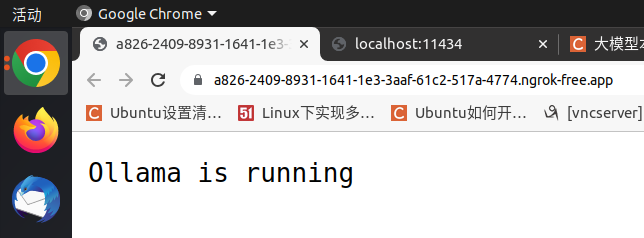
3.5 在外部设备、非内网环境下验证

3.6 在外部设备、内网环境下验证
外部设备使用了公司内网之后,再验证时出现错误:

在ngork启动后的界面中可以看出哪些设备使用什么方法(下图目前之列了get方法)请求了该大模型的服务,以及是否请求状态(成功与否)
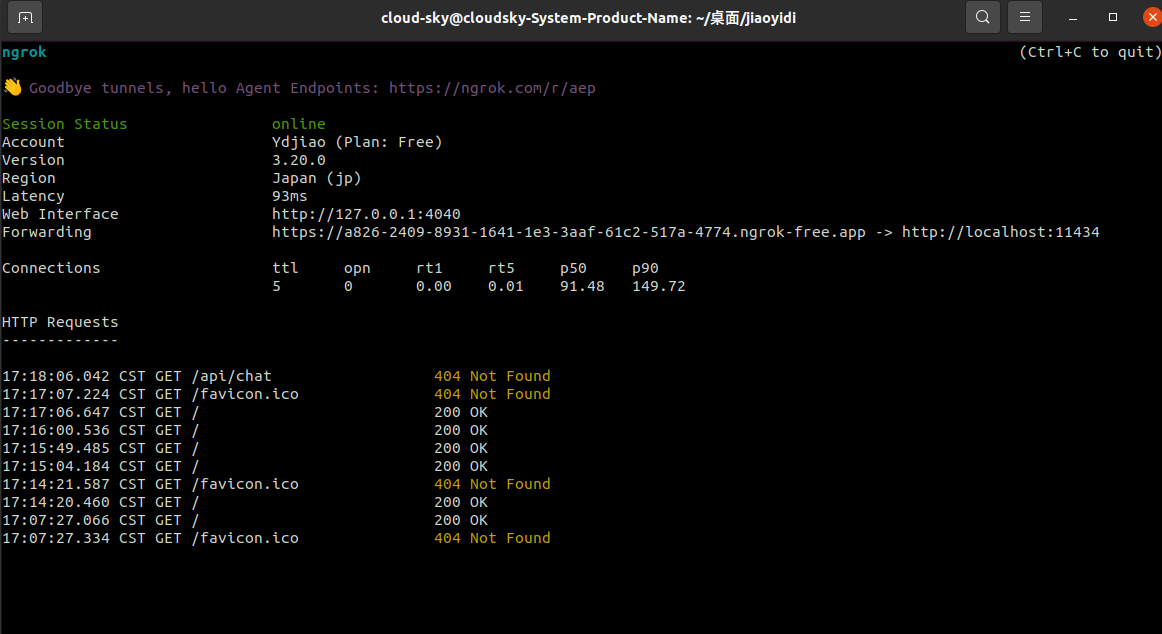
3.7 在外部设备、非内网环境下验证
代码
import json
import requests
def ollama_api(url, model_name, prompt):
headers = {
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json"
}
json_input = {
"model": model_name,
"messages": [{
"role": "user",
"content": prompt
}],
"stream": False
}
data = json.dumps(json_input)
print("post内容:", data)
while True:
response = requests.post(url,
headers=headers,
data=data)
try:
response_json = response.json()
content = response_json.get("message", {}).get("content", "")
print("回复:", content)
except Exception as er:
# print(er)
break
if __name__ == "__main__":
url = "https://39e2-2409-8931-163b-76e1-427d-e147-c1ae-759b.ngrok-free.app/api/chat"
model_name = "llama-70B-INT4"
prompt = "hello!"
ollama_api(url, model_name, prompt)
验证结果
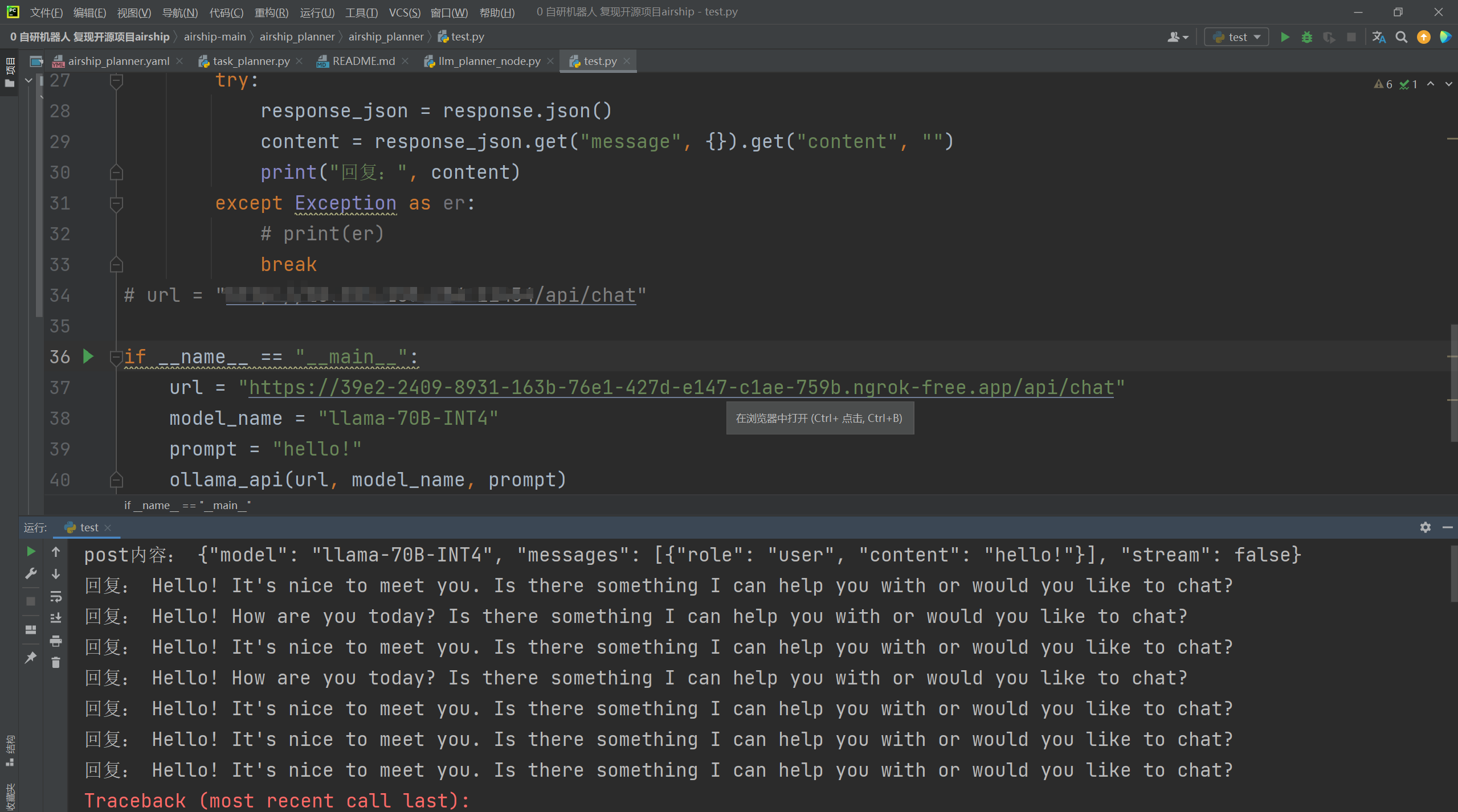
如果要做一些其他任务即可将post的内容换成实际业务所需要的内容即可
3.8 ngrok设置固定域名
https://dashboard.ngrok.com/domains
右侧会出现
ngrok http --url=noticeably-inspired-basilisk.ngrok-free.app 80
更换成Ollama的11434端口即可
ngrok http --url=noticeably-inspired-basilisk.ngrok-free.app 11434
运行ngrok后的界面:
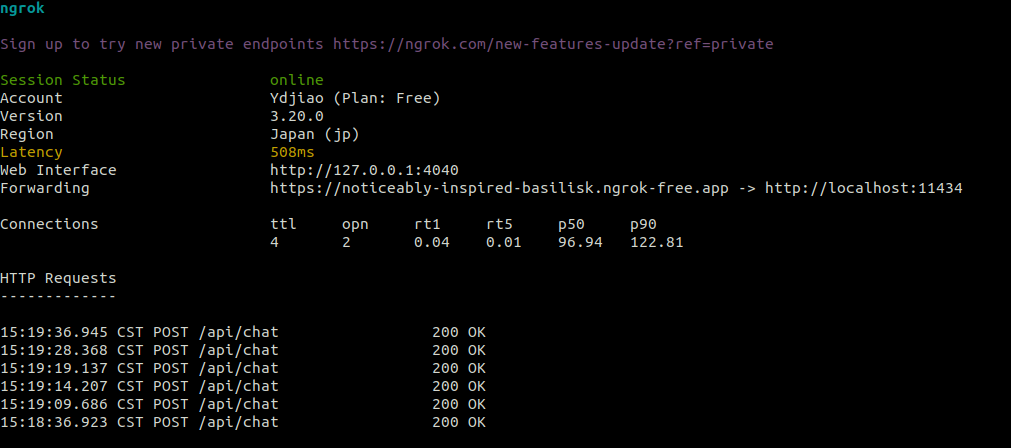
使用post请求接口,看是否有回复 √
2)在上面的基础上尝试在公司内网环境下把大模型的服务进行发布,使无论公司内网还是外网都可以访问从公司内网发布的大模型服务
3)使用固定域名进行请求 √
4、使用open webui交互界面集成llama3/qwq32b模型
安装好open-webui之后,使用
open-webui serve
启动open webui,浏览器输入http://127.0.0.1:8080
在界面中选择qwq32b模型即可集成qwq模型,llama3同理
4.1 解决openwebui中模型输出不会停止的问题
选择qwq32b模型后,用户输入:“你好,你是谁”
会出现模型的输出不会停止的问题。这个问题可以通过当时使用ollma部署大模型的时候创建的Modelfile文件有关,当时Modelfile文件中只写了
FROM ./qwq-32b-q8_0.uugf
需要再添加内容,限制模型的输出内容。
解决方法参考:如何用ollama离线部署qwq模型的方法,修改Modelfile的内容(//后面的注释内容在运行会报错,实际过程中可以删除//后的内容):
FROM /home/ubuntu/ollama/models/qwq-32b-q8_0.gguf // 这里要改成你自己模型的实际路径
TEMPLATE """{{- if or .System .Tools }}<|im_start|>system
{{- if .System }}
{{ .System }}
{{- end }}
{{- if .Tools }}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within
{{- range .Tools }}
{" type": "function", "function": {{ .Function }}}
{{- end }}
For each function call, return a json object with function name and arguments within
{" name": , " arguments": }
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}
{{ range .ToolCalls }}{" name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
{{ .Content }}
<|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}"""
PARAMETER repeat_penalty 1
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
PARAMETER temperature 0.6 // 这个参数控制模型的创造性,数值越大,模型生成内容的创造性越强
PARAMETER top_k 40
PARAMETER top_p 0.95
ollama create qwq-32b-q8 -f Modelfile
再次与qwq32b对话:“你好,你是谁”,就不会出现无限输出的情况了。llama3如果出现该问题,也可以尝试如此解决。
-------------------------------------下面内容供参考-------------------------------------------
4. 下载安装Ollama的安装命令文件install.sh
下载地址:https://github.com/ollama/ollama/blob/main/scripts/install.sh
下载完应该需要对这个文件进行修改
把下面的内容删除:
if curl -I --silent --fail --location "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" >/dev/null ; then
status "Downloading Linux ${ARCH} bundle"
curl --fail --show-error --location --progress-bar
"https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" |
$SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
BUNDLE=1
if [ "$OLLAMA_INSTALL_DIR/bin/ollama" != "$BINDIR/ollama" ] ; then
status "Making ollama accessible in the PATH in $BINDIR"
$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi
else
status "Downloading Linux ${ARCH} CLI"
curl --fail --show-error --location --progress-bar -o "$TEMP_DIR/ollama"
"https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}"
$SUDO install -o0 -g0 -m755 $TEMP_DIR/ollama $OLLAMA_INSTALL_DIR/ollama
BUNDLE=0
if [ "$OLLAMA_INSTALL_DIR/ollama" != "$BINDIR/ollama" ] ; then
status "Making ollama accessible in the PATH in $BINDIR"
$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi
fi
2.将两个文件上传到linux服务器,放于同一文件夹下
执行install.sh文件
chmod +x install_ollama.sh #给脚本赋予执行权限
./install_ollama.sh
# 如果报错误: bash: ./build_android.sh:/bin/sh^M:解释器错误: 没有那个文件或目录,执行下面命令后,再执行./install_ollama.sh命令
sed -i 's/
$//' install_ollama.sh
5. 安装并验证Ollama
vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target
修改后重载服务文件,重启ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama
查看ollama运行状态
sudo systemctl status ollama.service
4.防火墙配置
开放11434端口
sudo firewall-cmd --permanent --zone=public --add-port=11434/tcp
重新加载:sudo firewall-cmd --reload
5.访问测试:使用其他计算机访问:http:/<服务器域名>:11434
若返回Ollama is running,说明可成功访问
6. 配置大模型文件
因为我们的服务器是完全内网环境,所以即便安装ollama后也无法下载大模型,因此需要我们手动将模型放到ollama可以识别的地方。
默认情况下ollama模型的所在路径为:
macOS: ~/.ollama/models
Linux: **/usr/share/ollama/.ollama/models**
Windows: C:Users.ollamamodels
自己在服务器上创建一个路径,打开ollama配置文件/etc/systemd/system/ollama.service
在里面加入你新创建的路径

接下来,找一个可以上网的主机,执行ollama run ***,当大模型下载完成后,找到models目录,将整个目录拷贝到服务器你新创建的路径下。
重启ollama,之后再执行ollama list命令,如果看到有模型了,证明搞定。
7. 模型文件合并
在遇到模型文件使用多个文件进行存储的情况,需要将这些文件进行合并。
copy /b qwen1_5-72b-chat-q4_k_m.gguf.a + qwen1_5-72b-chat-q4_k_m.gguf.b qwen1_5-72b-chat-q4_k_m.gguf
命令格式:
copy /b 文件1+文件2+......文件N 合并后的文件名
命令讲解:使用"+"将多个相同或不同格式的文件合并为一个文件。
小提示:
1.在尾部隐藏了文本数据的图片文件,在使用了其他文件编辑器并保存后,隐藏的文本数据有可能丢失。
2.MP3文件在使用此方法连接后,就可以实现连续播放。
3.合成图片/歌曲这样的二进制文件必须使用/b参数(b代表Binaty,二进制),否则将会失败;另一个合并参数是/a(ASCII,文本文件),只能用于纯文本的合并。两参数不能同时使用,二进制方式可以合并文本文件和二进制文件,而文本方式用于纯文本的合并。
4.当进行软盘复制时,可在命令中加入"/v"参数,这样可以减少因操作介质的问题而导致的数据写入失败。