Linux -- 环境开发工具【上】
目录
一、软件包管理器yum
1、Linux中安装软件的方式
1.1 源代码安装
1.2 rpm安装
1.3 yum安装
2、Linux软件生态
2.1 如何评估一个操作系统的好坏?
2.2 安装流程
2.3 开源不代表免费
3、yum的安装与删除
3.1 yum源
3.2 演示lrzsz安装
3.3 lrzsz卸载
二、vim编辑器
1、vim的概念
2、vim的三种模式
3、vim的相关配置方法
4、vim的快捷键
5、vim的两个小技巧
三、编译器 (gcc/g++)
1、程序运行的四个阶段(预处理,编译,汇编,链接)
1.1 预处理(进行宏替换)
1.1.1 条件编译的用途
1.1.2 命令行级别的宏定义
1.2 编译(生成汇编)
1.3 汇编(生成机器可识别代码)
1.3.1 为什么C/C++编译要先变成汇编?
1.4 链接(生成可执行文件或库文件)
2、多文件的编译习惯
3、ldd指令
4、静态链接和动态链接
4.1 动/静态库文件
4.2 动态/静态链接理解
4.3 动/静态库/链接对比
一、软件包管理器yum
1、Linux中安装软件的方式
- 源码安装
- 软件包安装 -- rpm
- 包管理器 yum(CentOS) 、apt/apt-get(Ubuntu)
1.1 源代码安装
# 直接给你源码,你去进行编译 —— 对用户要求太高!
# 但是,仅仅是源码还不够,我们还需要把别人的一些相关编译环境配置也得搞过来。比如说我这个代码是用C语言写的,那么我们就需要C语言相关的编译器和库,对使用者来说太麻烦了!
1.2 rpm安装
# 直接给你已经编译好的软件包 —— 解决了环境问题,但解决不了安装依赖。
# 安装依赖就是,我们使用这个软件的前提需要安装一些前置软件,而我们在安装这些前置软件的时候,我们得需要知道在哪下载,下载不完全就会导致依赖缺失的问题。即使下载完全,可能该软件还有很多不同的版本,而一些版本可能会因为太新或者太老而不适合在当前的环境下使用,导致出现了版本兼容性的问题,这些对用户的要求太高了!
1.3 yum安装
# 解决了安装源、安装版本、安装依赖等问题 —— 对使用者友好。
# 包管理器会将程序和其他依赖分别拷贝进系统的不同配置文件里面,就相当于我们把编译好的软件包和具有依赖关系的软件都自动配置好了,这样用户直接无脑下载即可,什么都不需要操心。对使用者的要求降低! 这就有点像我们在windows下的应用商店里面下载一样,只要我们下载了就一定可以直接去使用!
# 由于包管理器会将程序和其他依赖分别拷贝进系统的不同配置文件里面,所以下载时必须使用root权限。也不用担心别人不能读取和执行,因为不是安装到/home目录下面,而是安装到系统里面,所以会把other的 r 和 x 权限打开,只要安装一次,任何人都能使用。
# 包管理器就类似于我们手机上面的app store
2、Linux软件生态
# 所以软件包,就是有些人把一些需要用到的软件提前编译打包好,放在一个服务器上(即软件包管理器,他们的关系就好比APP和应用商店的关系),其实每个软件都内置有一个下载链接,当用户点击的时候会自动跳转过去下载安装,然后客户就可以正常使用。
# 而yum(Yellow dog Updater, Modified)是Linux下非常常用的一种软件包管理器。主要应用在Fedora, RedHat, Centos等发行版上。
2.1 如何评估一个操作系统的好坏?
# 无论是软件还是操作系统,他存在目的就是对应目标群体的需求。我们此时的目标群体是职业程序员,而需求必然是希望这个操作系统能够更好地帮助我们解决各种各样的问题。
# 以下是我们需要考虑的问题:
a、操作系统的来源是否足够多,足够官方,是否有人维护。
- 公司的服务器啊,机器啊可能都需要统一用这个操作系统,那么我们肯定需要足够的数量,并且希望这个操作系统是认可度比较高的,有人定期去维护的。
b、对应的版本是否是一个稳定的版本。
- 版本可能会太老或者太新,太老的可能功能不太齐全,跟不上潮流,而太新的可能还在测试中,问题比较多,所以应该选择一个公认的稳定的版本。
c、是否有成熟、活跃的社区和网站。
- 成熟的网站和社区能够帮助我们反应一些问题,同时在上面可能能够搜索到一些问题比较成熟的解决方案。
d、成熟的开发文档介绍、使用说明。
- 使用操作系统必然要学习他的不同功能,比如说一些命令、一些接口、一些重要的开发使用说明……这些越详细越能够帮助我们快速上手使用这款操作系统。
e、其他:比如说价格低,或者是某些大公司也在使用……
# 一款操作系统背后的配套软件(像redis、docker…)也算生态的一环
# 通过以上这些问题,就能体现出了生态的重要性。
2.2 安装流程
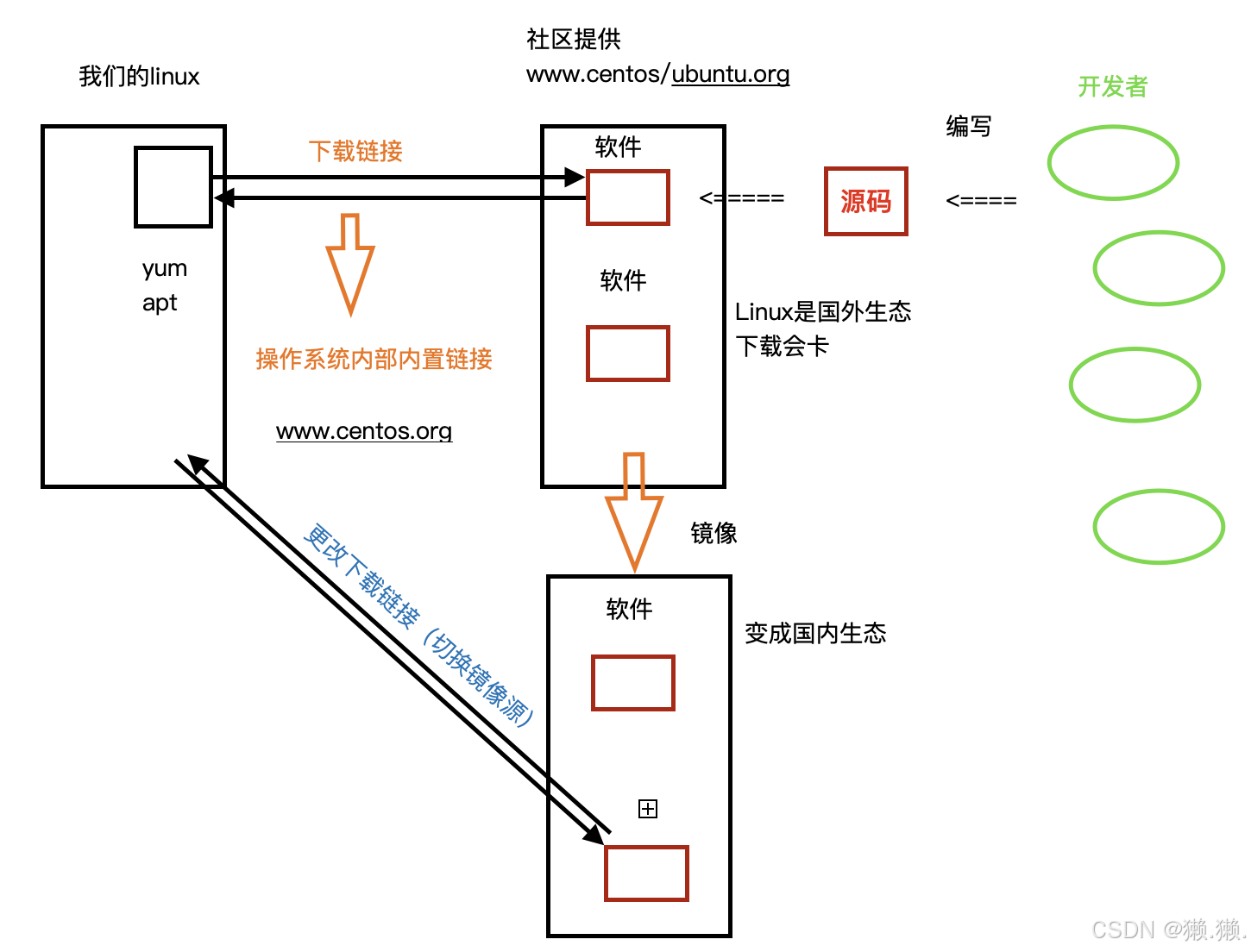
# 操作系统内部内置链接存在于:
CentOS:/etc/yum.repos.d/CentOS-Base.repo文件中
Ubuntu:/etc/apt/resources.list 文件中
2.3 开源不代表免费
# 开源是一种商业模式(当一个东西影响力足够大的时候,就越不会有人希望他消失!)
# 因为是免费的,所以使用的人越来越多,市场占有率更高,用户产生依赖之后就会害怕他消失。比方说我是一个大公司一直在使用这款操作系统,但是这个操作系统的维护资金可能不足了,而一旦瘫痪就会造成损失,所以会成为推动者进行资助,而当越来越多的大公司使用之后,就会有更多资助。
# 开源有时候也挺贵的。我们既然使用了相关的操作系统,那么必然要有人去维护,维护就需要花钱,大公司捐赠的其实最后也是通过产品转移给广大客户,就比如我们在买笔记本的时候,其实已经默认为操作系统买过单了。
3、yum的安装与删除
# 使用yum指令可以快速安装新的软件,例如执行 yum install package_name 即可安装指定软件包。同时,它也方便软件的升级,如 yum update 能更新系统中的所有软件包。对于不再需要的软件,使用指令yum remove package_name可以将其卸载。
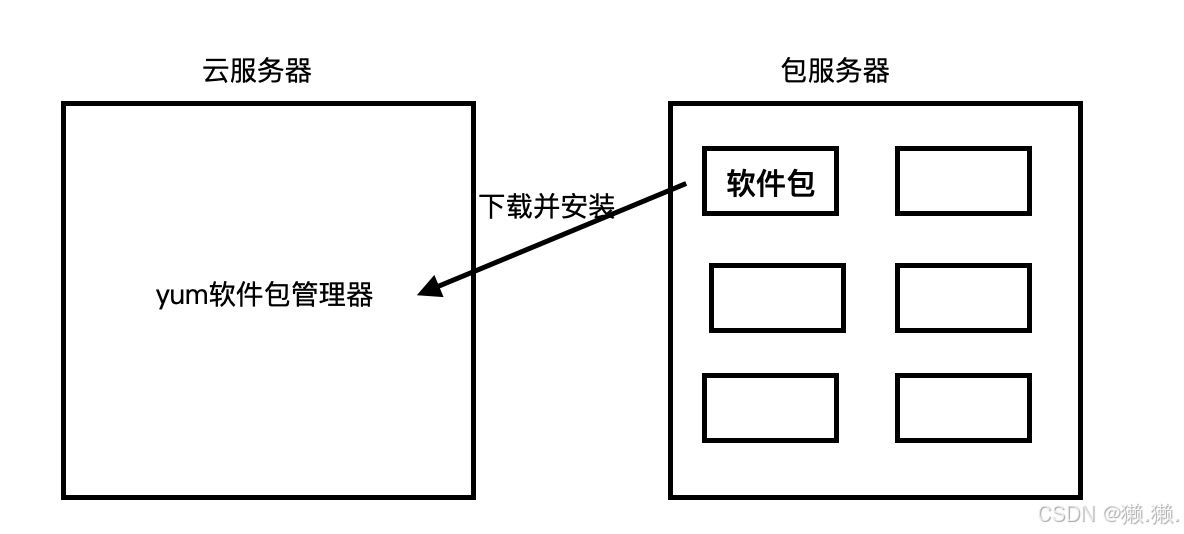
# yum的软件仓库可以是本地的,也可以是远程的网络仓库。通过配置不同的仓库源,可以获取各种不同的软件包,满足不同用户的需求。
3.1 yum源
# 一般Linux操作系统,默认配置的都是yum源是国外的,所以有可能你的yum源访问会比较慢,所以后期也可以去替换yum源文件。(一般的厂商已经替换过了)
# 查看yum源:ls /etc/yum.repos.d/ CentOS-Base.repo (默认有的是官方yum源)
# 查看apt源:ls /etc/apt/resources.list

3.2 演示lrzsz安装
这个工具用于 windows 机器和远端的 Linux 机器通过 XShell 传输文件
step1: yum 的所有操作必须保证主机(虚拟机)网络畅通
# 一个服务器同一时刻只允许一个yum进行安装,不能在同一时刻同时安装多个软件。并且因为yum是从服务器上下载RPM包,所以在下载时必须联网。我们可以通过ping指令判断是否有网。

# 使用指令yum list可以罗列出可供下载的软件:

# 这四个列数据分别是软件包的名称、软件包的版本号、软件包的版本号和。我们可以选择一个需要的软件安装。
step2: 查看软件包
# 由于包的数目可能非常之多,这里我们需要使用 grep 命令只筛选出我们关注的包。
yum list | grep lrzsz
# 我们看看别的博主centos下:
(1)软件包名称:主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构。
(2)"x86_64" 后缀表示64位系统的安装包, "i686" 后缀表示32位系统安装包,选择包时要和系统匹配。"el7" 表示操作系统发行版的版本。
(3)"el7" 表示的是 centos7/redhat7。 "el6" 表示 centos6/redhat6。
(4)base 表示的是 "软件源" 的名称,,类似于 "小米应用商店", "华为应用商店" 这样的概念。
# 再看看tata的ubuntu下:
(1)"nobel" 是软件包所属的 Ubuntu 版本代号。
(2)"0.12.21-11build1" 表示的是主版本号 "11build1" 表示 特定构建版本。
(3)"amd64" 是64 位处理器架构。
(4)lrzsz/noble 0.12.21-11build1 amd64 是 Debian/Ubuntu 系统中软件包的完整标识。
step3: 软件安装
sudo yum install lrzsz
注意:
(1)安装软件时由于需要向系统目录中写入内容, 一般需要 sudo 或者切到 root 账户下才能完成。
(2)yum安装软件只能一个装完了再装另一个。正在yum安装一个软件的过程中, 如果再尝试用yum安装另外一个软件, yum会报错。
(3)如果 yum 报错, 请自行百度。
step4: 使用软件
rz:文件从windows -> Linux
sz:文件从Linux -> windows
3.3 lrzsz卸载
sudo yum remove lrzsz
# 无论是安装还是卸载,都会询问你是否确定,如果你不希望他询问,可以加一个-y 。
二、vim编辑器
1、vim的概念
# 在Linux系统中,vim(Vi IMproved)是一款极为出色的文本编辑器。它由Vi编辑器发展而来,在功能上有显著提升,且提供了更多扩展性与定制选项。 Vi 和 Vim 虽都是多模式编辑器,但Vim作为Vi 的升级版本,兼容Vi的所有指令,同时还具备一些新特性。例如,Vim 拥有语法加亮功能,使代码阅读更加清晰直观。它不仅能在终端运行,还可以在Window、MacOS等不同操作系统环境下运行,具有很强的通用性。
# 然后我们可以使用指令vim 文件名使用vim编辑器,如果文件名不存在,系统会自动创建。
2、vim的三种模式
# vim主要有三种模式:命令模式、插入模式和底行(末行)模式。
1、命令模式:可通过各种快捷键进行高效的文本编辑操作,如移动光标、删除、复制粘贴等。
2、插入模式:用于正常输入文本,可通过特定按键进入。
3、底行(末行)模式:用于执行高级操作,如保存文件、查找替换、设置文件属性等。
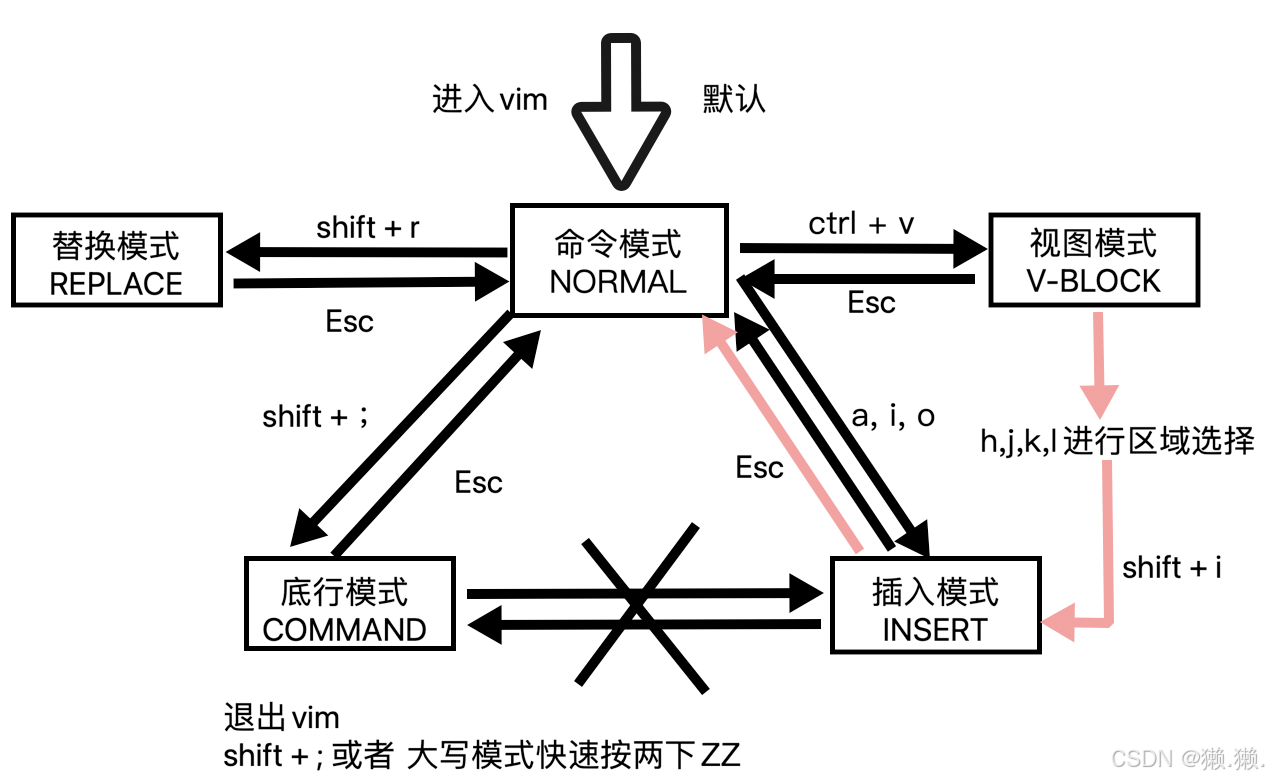
# 首先进入vim默认为命令模式。

# 输入i或者a或者o可以切换为插入模式。
输入
i:在当前光标处进入插入模式。输入
a:在当前光标的后一位置进入插入模式。输入
o:在当前光标处新起一行进入插入模式。

# 然后我们可以通过Esc退出插入模式,再按下shift + ;即 : 进入底行模式。
# 输入 :q / :wq / :q! / :wq! 就能退出。
:w -> 保存
:q -> 不保存退出
:wq -> 保存退出
:q! -> 强制不保存退出
:wq! -> 强制保存退出

3、vim的相关配置方法
CentOS:
# 在没有进行任何配置的情况下,Linux默认的vim编辑器界面并不美观,且缺少很多功能
- 界面太过简单,可以说是简陋
- 编写程序时没有基本的自动缩进、高亮、自动补齐等许多
Windos编译器都有的功能,使得用起来极度不方便
# 所以我们可以通过安装插件来配置vim。
VimForCpp:快速将Vim打造成C++IDE(give.com)
# 注意:
- 1、不要在root下执行!!!
- 2、只支持 Centos7 x86_64
- 3、一个用户一个vim配置文件,相互之间不会影响
命令:curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
安装完成后: source ~/.bashrc (重新执行刚刚修改的文档)
# 设置缩进的空格数为4: set shiftwidth=4 (打开.vimrc进行修改)
# .vimrc文件是用来配置用户所属的vim编辑器的,root在他的家目录下默认有,但是普通用户需要自己在家目录下创建
Ubuntu:
# 普通用户下,使用vim ~/.vimrc命令在家目录下新建一个.vimrc文件,并将下面的代码粘贴进去保存退出,即可直接生效
syntax on " Set syntax highlighting
set number " Set the line number
set tabstop=4 " Set an indent to account for 4 spaces
set autoindent " Set up automatic indentation
set mouse=a " Set mouse is always available, set mouse= (empty) cancel
set cc=80 " Column 80 highlighted, set cc=0 cancellation
set cursorline " Settings to highlight the current row
set cindent " Format C language
set st=4 " Set the width of the soft tab to 4 spaces
set shiftwidth=4 " The width automatically indented when setting a new line is 4 spaces
set sts=4 " Set the number of spaces inserted when the Tab key is pressed in insertion mode to 4
set ruler " Show the status of the last line
set showmode " The status of this row is displayed in the lower left corner.
set bg=dark " Show different background tones
set hlsearch " Enable Search Highlight
set laststatus=2 " Always display the status bar
" Set Automatically Complete Parentheses
inoremap ' ''i
inoremap " ""i
inoremap ( ()i
inoremap [ []i
inoremap < <>i
inoremap { {} O
4、vim的快捷键
# vim提供了许多快捷键方便大家操作,以下分别为命令模式与底行模式下常见的快捷键:
命令模式:
| 功能 | 快捷键 |
| 光标上移 | k |
| 光标下移 | j |
| 光标左移 | h |
| 光标右移 | l |
| 移动到行尾 | $ |
| 移动到行首 | ^ |
| 移动到文本开始 | gg |
| 移动到文本末尾 | Shift + g |
| 移动到第 n 行行首 | n + Shift + g |
| 当前光标向下移动 n 行 | n + Enter |
| 跳到下一个单词的开头 | w |
| 跳到下一个单词的结尾 | e |
| 跳到上一个单词的开头 | b |
| 删除光标所在位置的字符 | x |
| 删除光标所在位置开始往后的 n 个字符 | nx |
| 删除光标所在位置的前一个字符 | X |
| 删除光标所在位置的前 n 个字符 | nX |
| 删除光标所在行 | dd |
| 删除光标所在行开始往下的 n 行 | ndd |
| 复制光标所在行到缓冲区 | yy |
| 复制光标所在行开始往下的 n 行到缓冲区 | nyy |
| 将光标所在位置开始到字尾的字符复制到缓冲区 | yw |
| 将光标所在位置开始往后的 n 个字复制到缓冲区 | nyw |
| 剪切光标所在行 | dd |
| 剪切光标所在行开始往下的 n 行 | ndd |
| 将已复制/剪切的内容在光标的下一行粘贴上 | p |
| 将已复制/剪切的内容在光标的下一行粘贴 n 次 | np |
| 撤销 | u |
| 恢复刚刚的撤销 | Ctrl + r |
| 完成光标所在位置字符的大小写切换 | ~ |
| 完成光标所在位置开始往后的 n 个字符的大小写切换 | n~ |
| 替换光标所在位置的字符 | r |
进入replace模式,替换(覆盖)光标所到位置的字符,直到按下 Esc 键为止 | Shift + r |
| 将光标所在位置开始到字尾的字符删除,并进入插入模式 | cw |
| 将光标所在位置开始往后的 n 个字删除,并进入插入模式 | cnw |
| 上翻一页 | Ctrl + b |
| 下翻一页 | Ctrl + f |
| 上翻半页 | Ctrl + u |
| 下翻半页 | Ctrl + d |
# 按下shift + # 可以选中一个单词,在按 n 可以进行逆向查找。
底行模式:
| 功能 | 快捷键 |
|---|---|
| 显示行号 | set nu |
| 取消行号 | set nonu |
| 保存文件 | w |
退出 vim(强制退出可在后面加 !) | q、q! |
| 保存退出 | wq |
| 实现多文件的编辑 | vs 文件名 |
| 光标在多屏幕下进行切换 | Ctrl + w + w |
| 在不退出 vim 的情况下执行 Linux 指令 | ! + 指令 |
# :%s/dst/src/指令可以将dst全部替换成src。
# /单词 指令可以查找这个单词,按 n 进行逆向查找。
视图模式:
# 命令模式下按ctrl + v 进入视图模式,用h,j,k,l进行区域选择,选择完区域后,按shift + i 回到插入模式,在刚刚选择的区域开头输入 // ,再按Esc,即可一键注释区域代码。
| 功能 | 快捷键 |
|---|---|
| 选择区域左移1行 | h |
| 选择区域下移1行 | j |
| 选择区域上移1行 | k |
| 选择区域右移1行 | l |
| 选择区域左移n行 | nh |
| 选择区域下移n行 | nj |
| 选择区域上移n行 | nk |
| 选择区域右移n行 | nl |
| 全选为选择区域 | shift + g |
# 除了批量化注释功能,我们也可以在视图模式下,用一系列快捷操作来批量化增删改代码!!!
5、vim的两个小技巧
# vim 文件 +n -- 打开时光标定位到第n行
# !v -- 执行最近使用的一条vim指令
三、编译器 (gcc/g++)
# 在 Linux 系统中,gcc 和 g++是两个极为重要的编译器。一般而言我们通过gcc编译C语言,g++编译C++。一般而言它们都将经历预处理,编译,汇编,链接四个阶段。
1、程序运行的四个阶段(预处理,编译,汇编,链接)
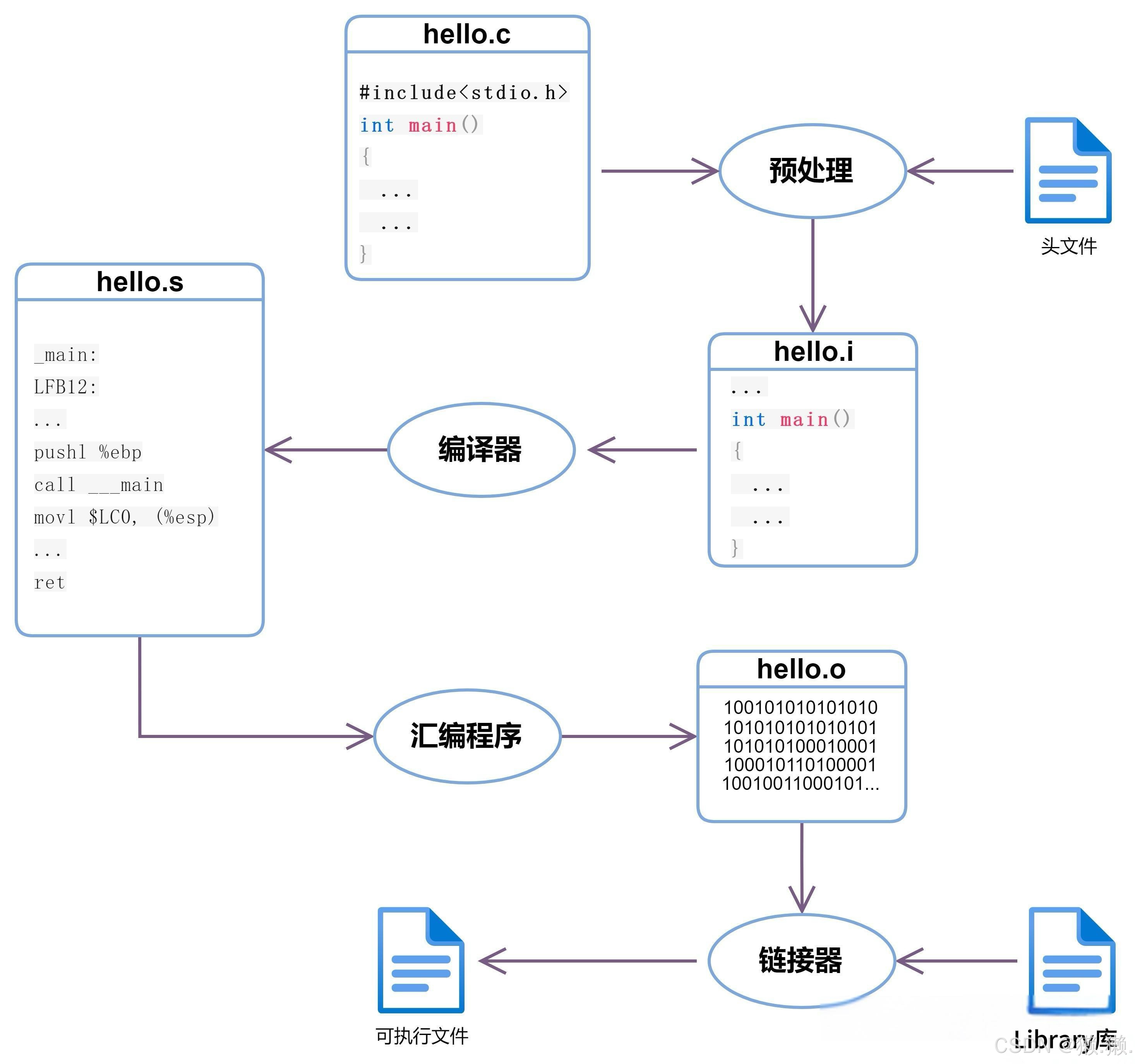
1.1 预处理(进行宏替换)
- 去注释
注释我们一般用于对我们的代码进行解释说明,但并不参与编译,所以是可以直接去掉的,节省文件的大小。
- 头文件展开
头文件里面包含了我们需要的一些函数的声明,由于在链接之前各个文件都是独立进行编译和转汇编的,所以头文件将函数声明展示出来其实就是为了在编译过程的时候告诉编译器,这个函数是存在的,一定要放行,而最后的函数定义一般得等到链接的时候才能找到。
- 条件编译
条件编译其实就是有选择的编译,比较常见的一种情况比如说我们要通过打印来观察代码的运行情况(调试),但是仅仅只是为了起到一个调试的作用,所以我们调试后还要删掉其实有点可惜,所以我们可以通过条件编译来对他进行保留,在必要的时候启动这段代码或者是去掉这段代码。
1.1.1 条件编译的用途
- 业务上,对软件进行专业度、收费情况等进行区分,使用条件编译,可以进行代码动态裁剪。
- 内核源代码也是使用条件编译来进行代码裁剪。
- 开发工具、应用软件使用条件编译来适配,实现在多平台上使用。
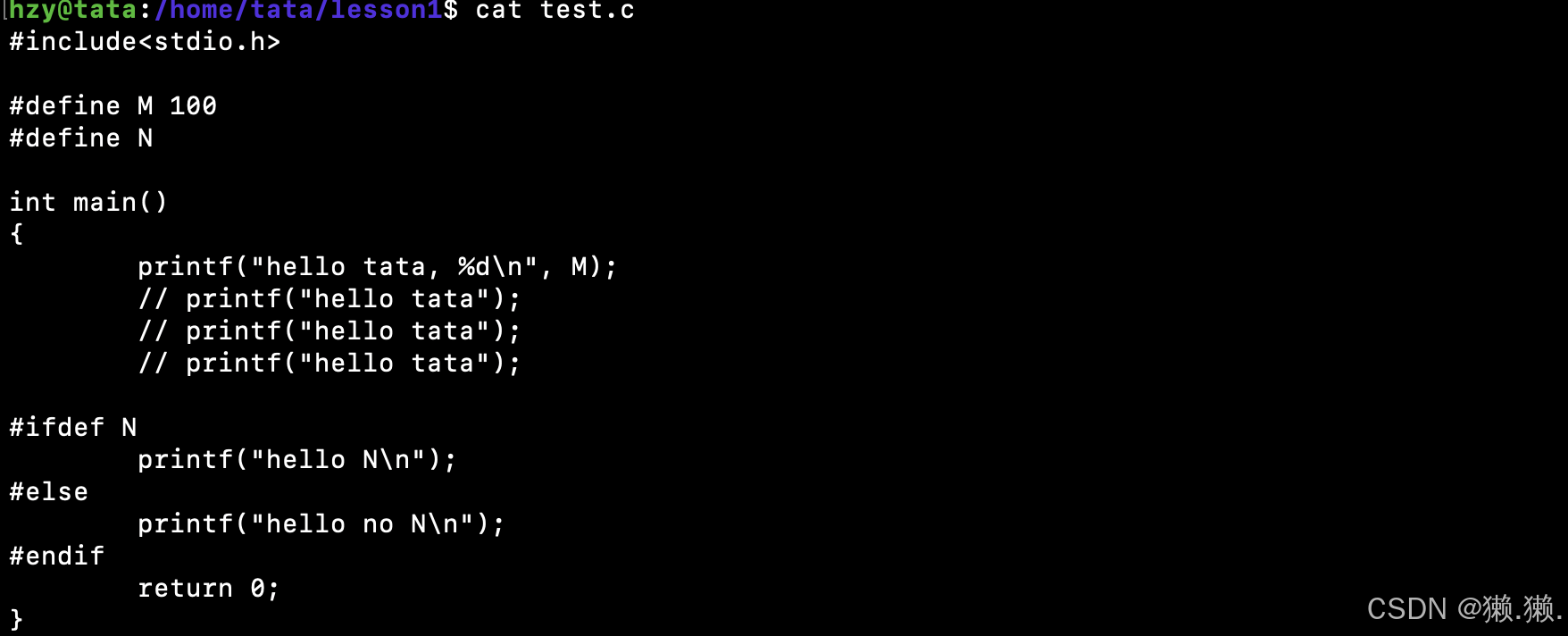
1.1.2 命令行级别的宏定义
选项:-D
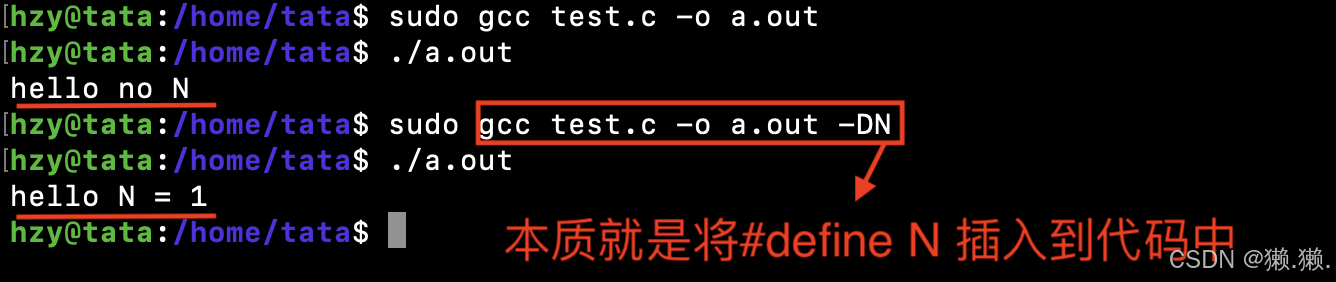
- 宏替换
-E选项:开始进行程序翻译,在预处理做完的时候就停下来,生成 .i 文件,可以直接运行。

1.2 编译(生成汇编)
# 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等(有错误会直接崩掉),以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。其实头文件里包含的函数声明,其实就是告诉编译器,这个函数是存在的,你要放行!
-S选项:开始进行程序编译,将编译过程做完就停下来,生成 .s 文件,可以直接运行。
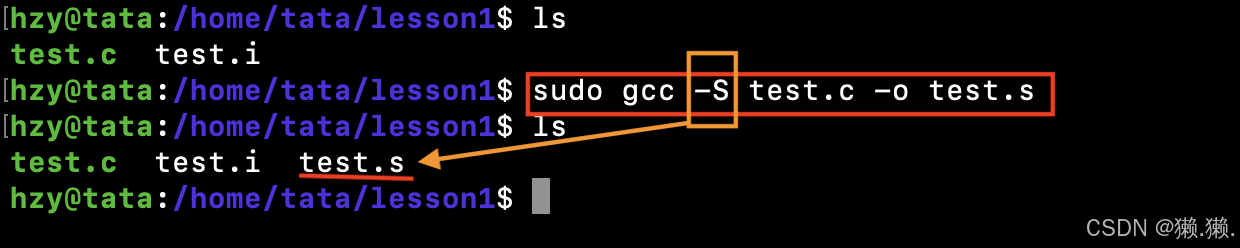
1.3 汇编(生成机器可识别代码)
# 汇编阶段是把编译阶段生成的 .s 文件转成目标文件(可重定位目标二进制文件)。
-c选项:开始进行程序编译,汇编结束就停下来 ,生成 .o 文件,不可以直接运行!因为我们的源文件中会包含很多的库方法,而在我们的程序中并没有和这些库方法链接起来,也就是说没有库方法的具体实现。
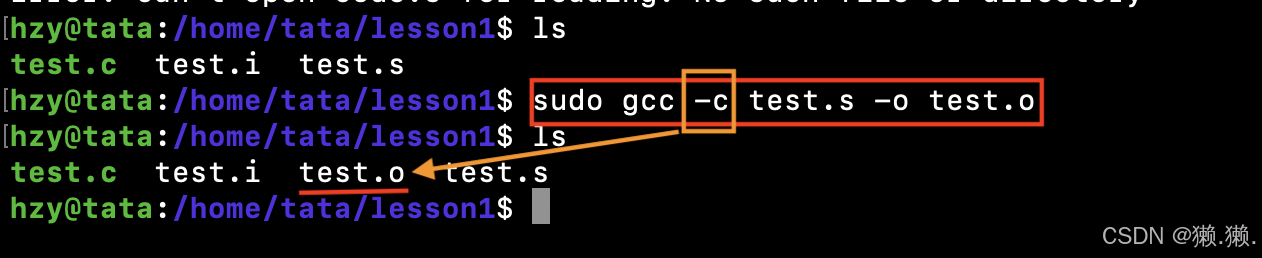

1.3.1 为什么C/C++编译要先变成汇编?
# 最开始的计算机采用打孔编程来代表二进制代码,后来汇编语言出现了方便了编程过程,再后来C/C++/Java…等出现,因为从C/C++/Java…到汇编,是文本与文本之间的转化,效率高,把汇编到二进制语言的过程交给编译器完成就行了;
# 编译器的自举过程:编译汇编语言的编译器,由字面意思可得到他是由汇编语言写的,是一个二进制版汇编编译器,就可以编译汇编了,此时就可以用汇编写一个编译汇编的编译器,就能编译汇编语言了。
1.4 链接(生成可执行文件或库文件)
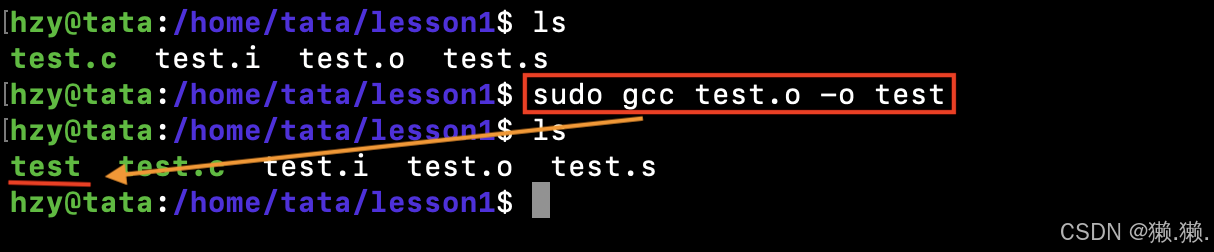
# 将目标文件和库进行链接,就得到了可执行程序。
gcc test.o -o test
2、多文件的编译习惯
# 我们一般习惯先将多个源文件分别统一编译成 .o 文件,再将所有 .o 文件打包成一个可执行程序。
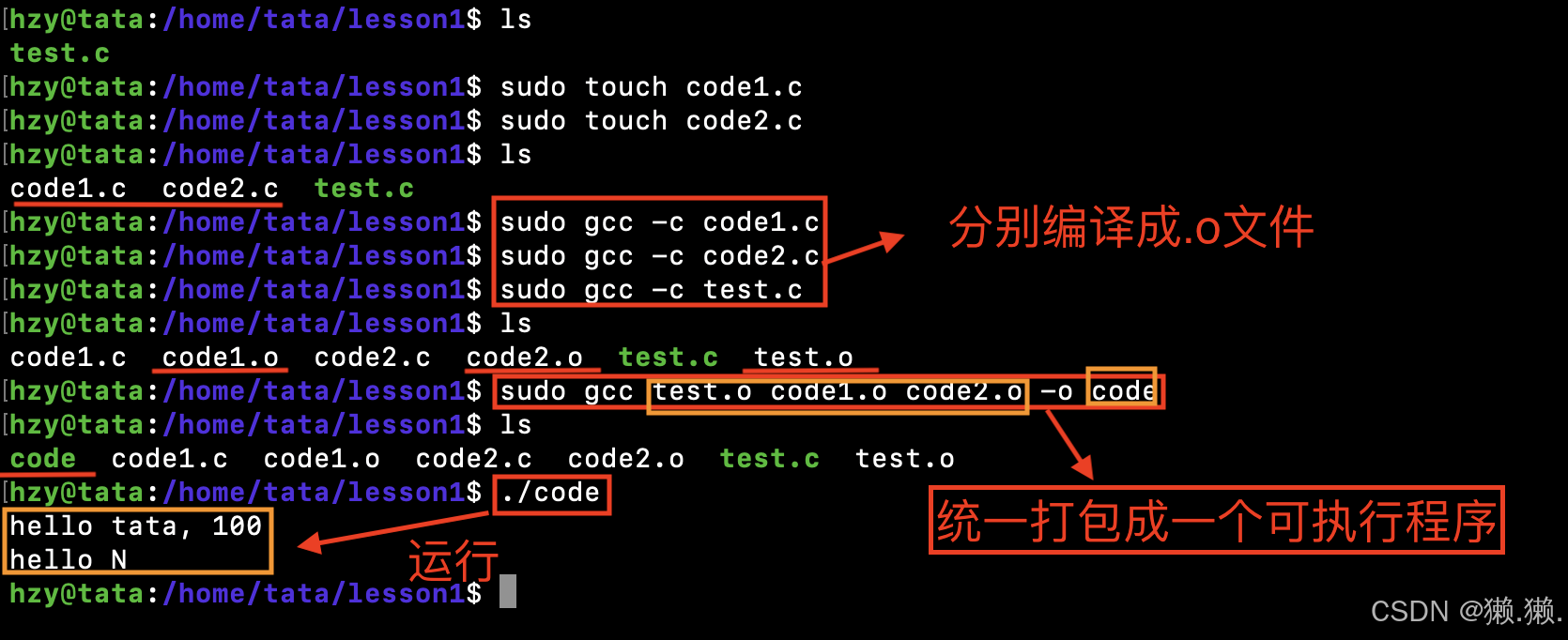
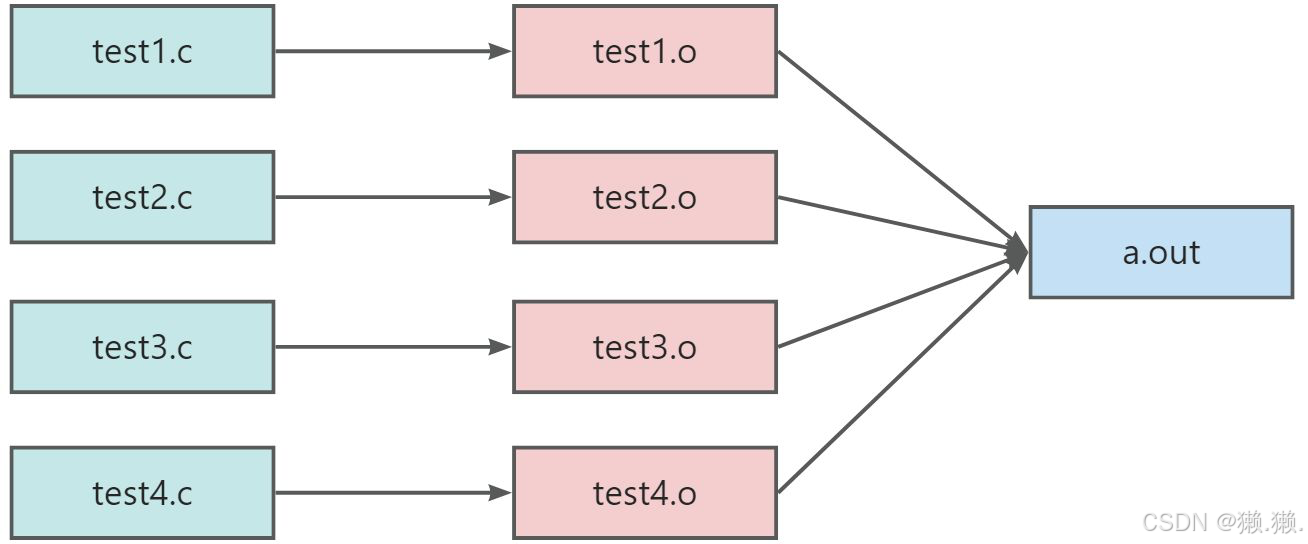
为什么要分别编译成 .o ,再将 .o 文件打包成一个可执行程序?
- 因为编译器在编译时,不仅仅要形成可执行程序,还有可能要形成库,所谓的库,就是把所有 .o 文件打了个包,因此如果要形成可执行程序的话,就必须要先形成 .o 文件,而不能形成可执行程序。
3、ldd指令
指令:ldd 文件名
作用:查看该可执行程序所依赖的动态库

# 接下来我们来看.o是如何和库进行链接的。
4、静态链接和动态链接
4.1 动/静态库文件
Linux中: .so(动态库) .a(静态库)
命名规则:libname.so.XXX
windows中:.dll(动态库) .lib(静态库)
# 在Linux中,通过ls /usr/lib64/libc.so* 可以看到我们的动态库文件。

# 还有之前我们知道其实指令的本质就是可执行程序,所以我们也可以去查看指令所依赖的动态库,我们会发现大部分都是用C的库。

# 静态库的文件默认是没有安装的,需要通过以下指令去手动安装.
C静态库:sudo yum install -y glibc-static
C++静态库:sudo yum install -y libstdc++-static
# 注意:动/静态库真实文件名需要去掉前缀lib,再去掉后缀.so或者.a及其后面的版本号,比如说libc-2.17.so就是C语言的标准库,其名为:c-2.17
4.2 动态/静态链接理解
# 库:是一套方法或数据集,为我们开发提供最基本的保证(基本接口、功能,加速我们二次开发)。
# 动态链接:当程序执行到某个地方时,他会跳出到动态库继续执行,然后再回来,这个过程就是动态链接。
# 下面我们举个形象的例子帮助理解动态库和动态链接:
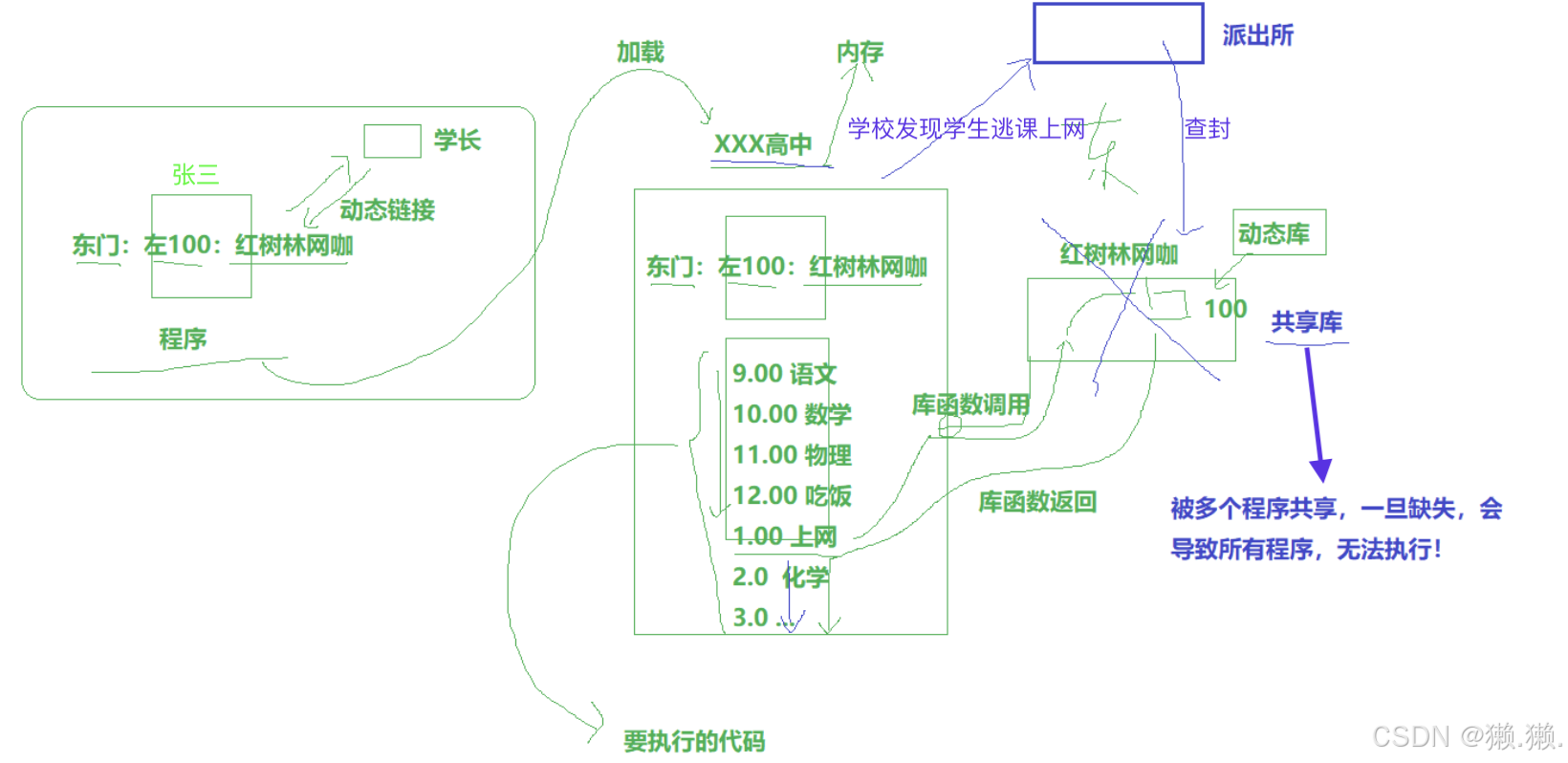
# 由上可知: 所以动态库不能缺失!!一旦缺失影响的不仅仅是一个程序,而是多个程序都会崩溃!
# 静态链接:静态库进行静态链接的时候,会将自己的方法拷贝到目标程序中,该程序以后不用再依赖静态库
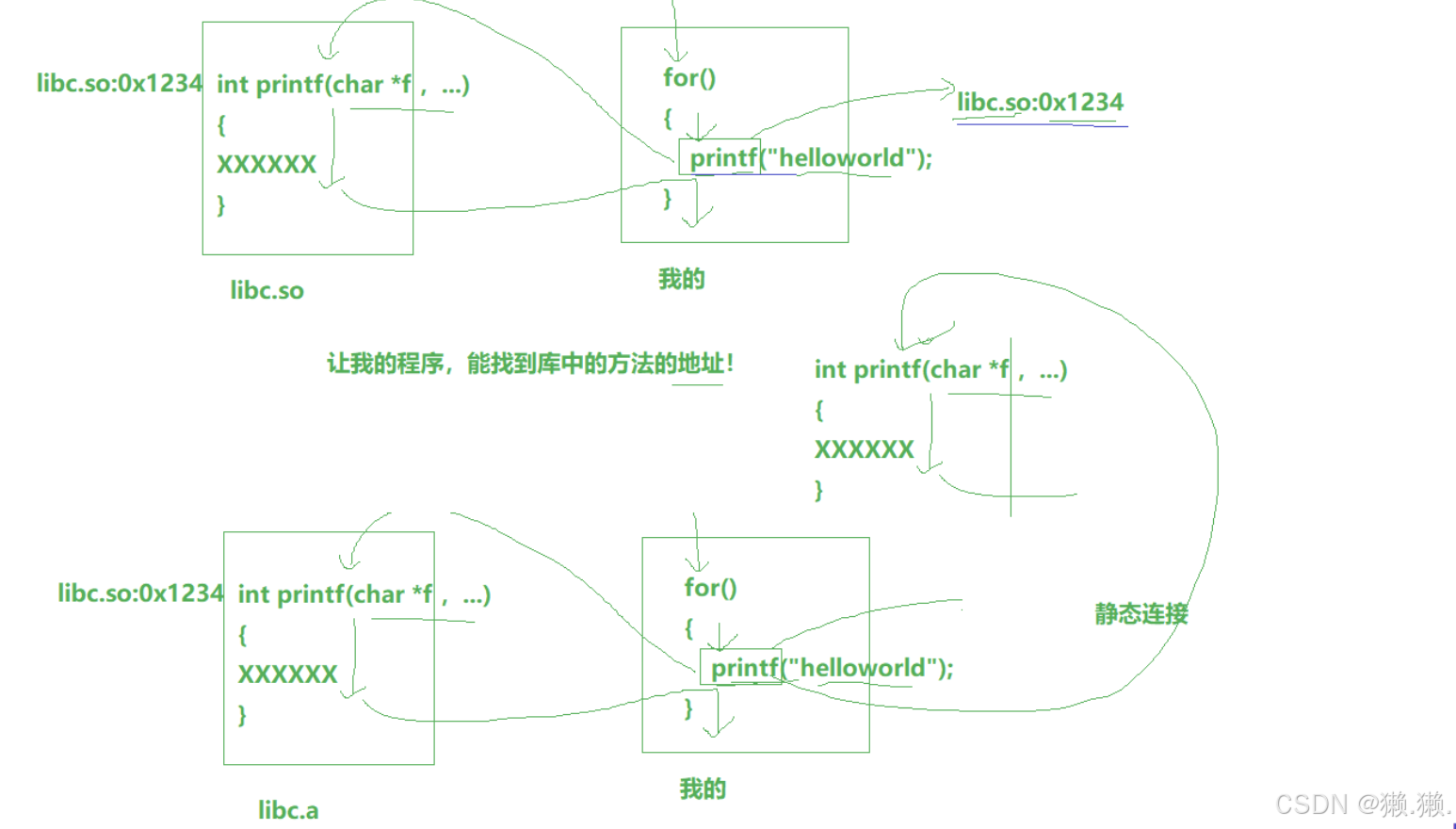
# 下面这个类似例子帮助理解静态库和静态链接:
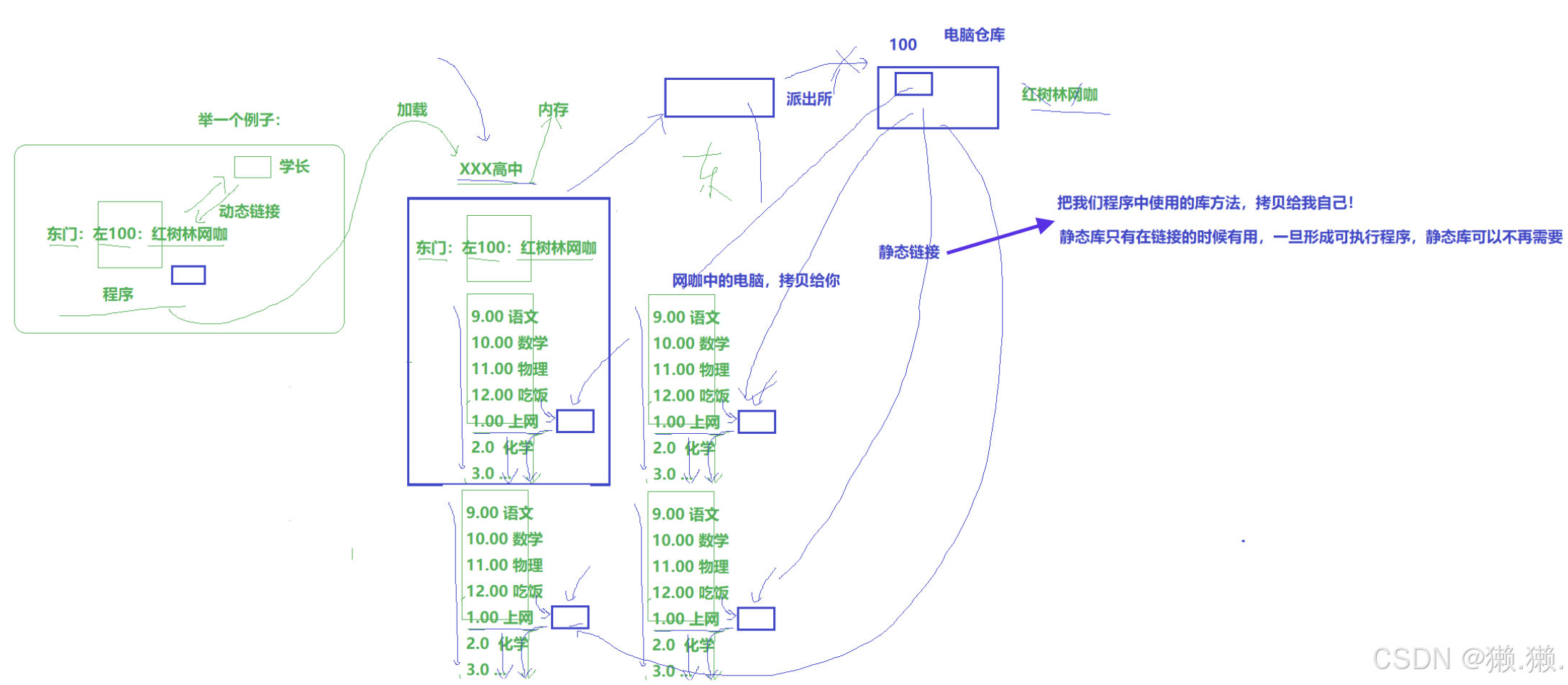
# 有一天那个老板又被举报查封了,但是这个时候学校里的学校却没有人知道这件事,因为大家都有自己的电脑了,店查不查封对他们没什么影响,所以静态链接的程序并不依赖库文件,即使静态库丢失了程序也可以正常运行。
4.3 动/静态库/链接对比
# 动态库:
优点:动态库是共享库,可以有效节省资源(磁盘空间、内存空间、网络空间),形成的可执行程序体积一定很小
缺点:动态库不能缺失,一旦缺失,所有的程序将无法运行
# 静态库:
优点:可执行程序对静态库的依赖度小,程序可以独立运行
缺点:程序运行需要加载到内存,静态链接就会在内存中出现大量的重复代码,体积大,消耗资源
# 一般来说,我们在实际应用中更倾向于使用动态链接,因为体积大所带来的影响是很大的,比方说你下个游戏要1G,但是用静态链接可能就需要上百G,所以无论是我们还是Linux默认,都是会尽量选择动态链接。
# 动态链接的情况下,程序在运行的时候,将磁盘中的代码文件读到内存中,链接时再将所需动态库加载到内存中,这样不管有几个代码文件需要链接这个动态库,都不用再次加载了,直接读取内存中的那份;如果是静态链接的情况下,每个代码文件都包含静态库的拷贝,就会造成很多重复的代码,内存就被浪费了。
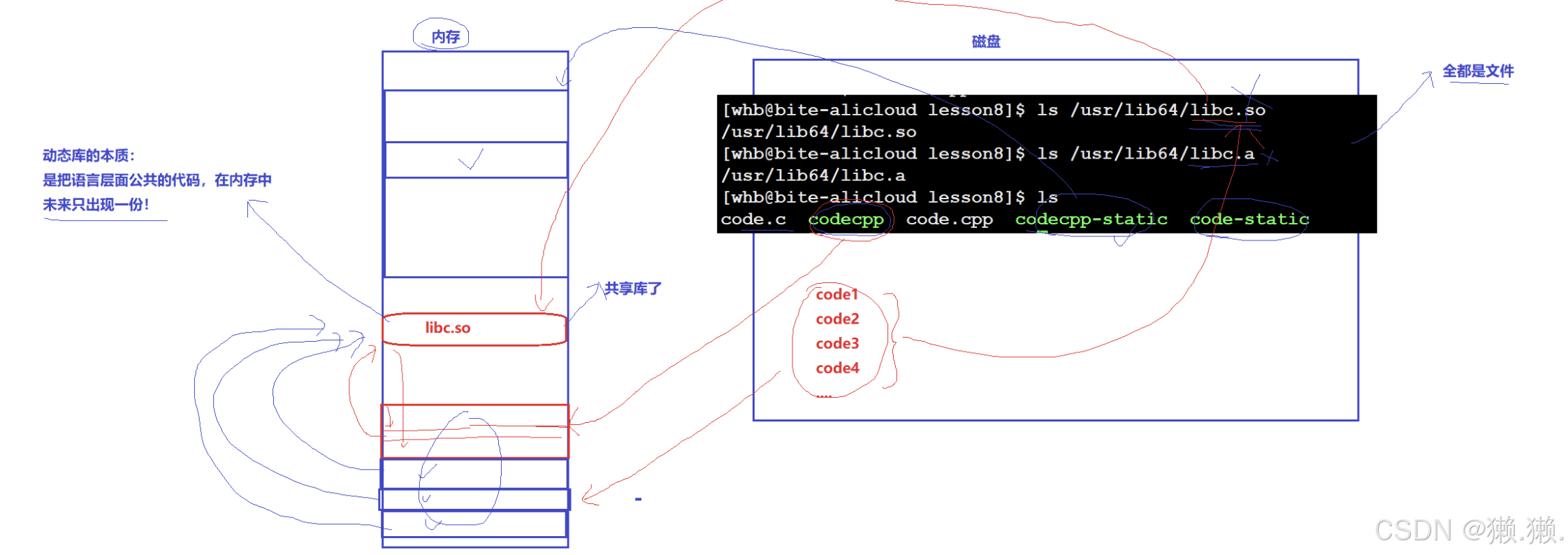
# 验证动态链接:
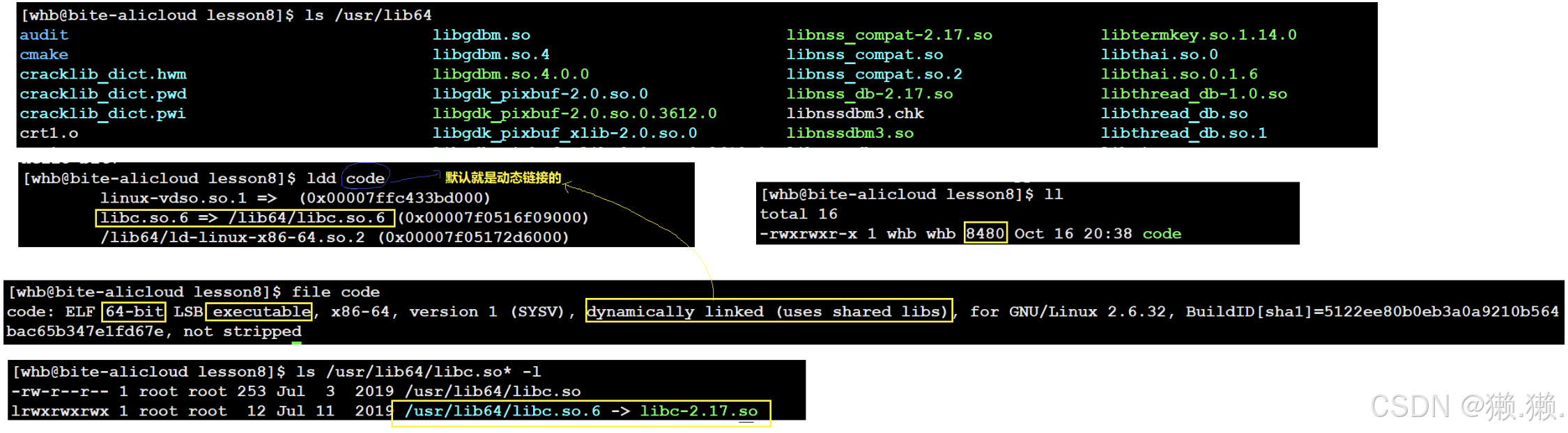
# 验证静态链接:

# 以上是C语言编译的,类似C++也一样:

# 技术上理解库:当我们写了很多个.h和.c文件时,要把我们的文件发给写mian.c的人来进行链接,但是我们不想让别人看见我们的源代码,就可以把所有.c文件先编译成.o,再把所有.o打包成一个.so或者是.a文件,这就是库。别人就可以将他的mian.c编译成mian.o,再与我们的文件进行链接,所以,链接的本质就是把所有的.o进行合并。