Atlas 800 9000服务器 910B 上部署大模型,以及测试
1.查看驱动,并进行更新
npu-smi info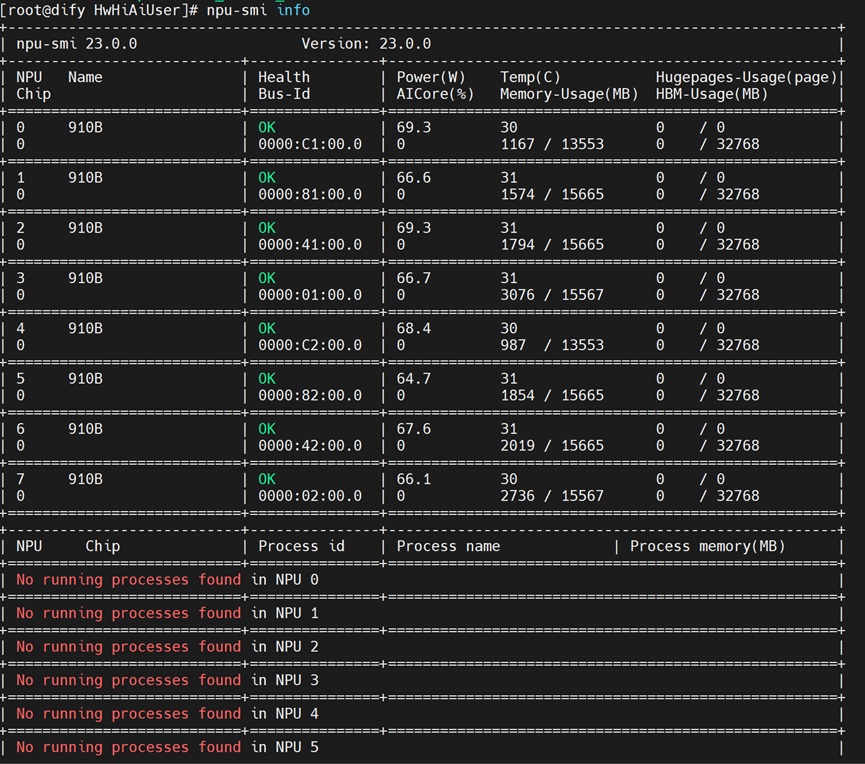
升级最新的驱动与固件,前往官网下载最新的 驱动与固件 社区版-固件与驱动-昇腾社区

注意产品系列和产品型号不要选错,这边我们下载 .run的版本
cd /home/HwHiAiUser
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Ascend%20HDK/Ascend%20HDK%2023.0.2.1/Ascend-hdk-910-npu-driver_23.0.2_linux-aarch64.run
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Ascend%20HDK/Ascend%20HDK%2023.0.2.1/Ascend-hdk-910-npu-firmware_7.1.0.4.220.run
chmod 777 Ascend-hdk-910-npu-driver_23.0.2_linux-aarch64.run
chmod 777 Ascend-hdk-910-npu-firmware_7.1.0.4.220.run
sudo ./Ascend-hdk-910-npu-driver_23.0.2_linux-aarch64.run --full --force
sudo ./Ascend-hdk-910-npu-firmware_7.1.0.4.220.run --full --force 然后我们重启一下服务器
sudo reboot2.下载 modelscpoe ,指定版本1.18.0
pip install modelscope==1.18.03. 下载模型权重
(如果想要跑其他模型,可以去魔塔社区按照模型下载的指引下载魔搭社区)
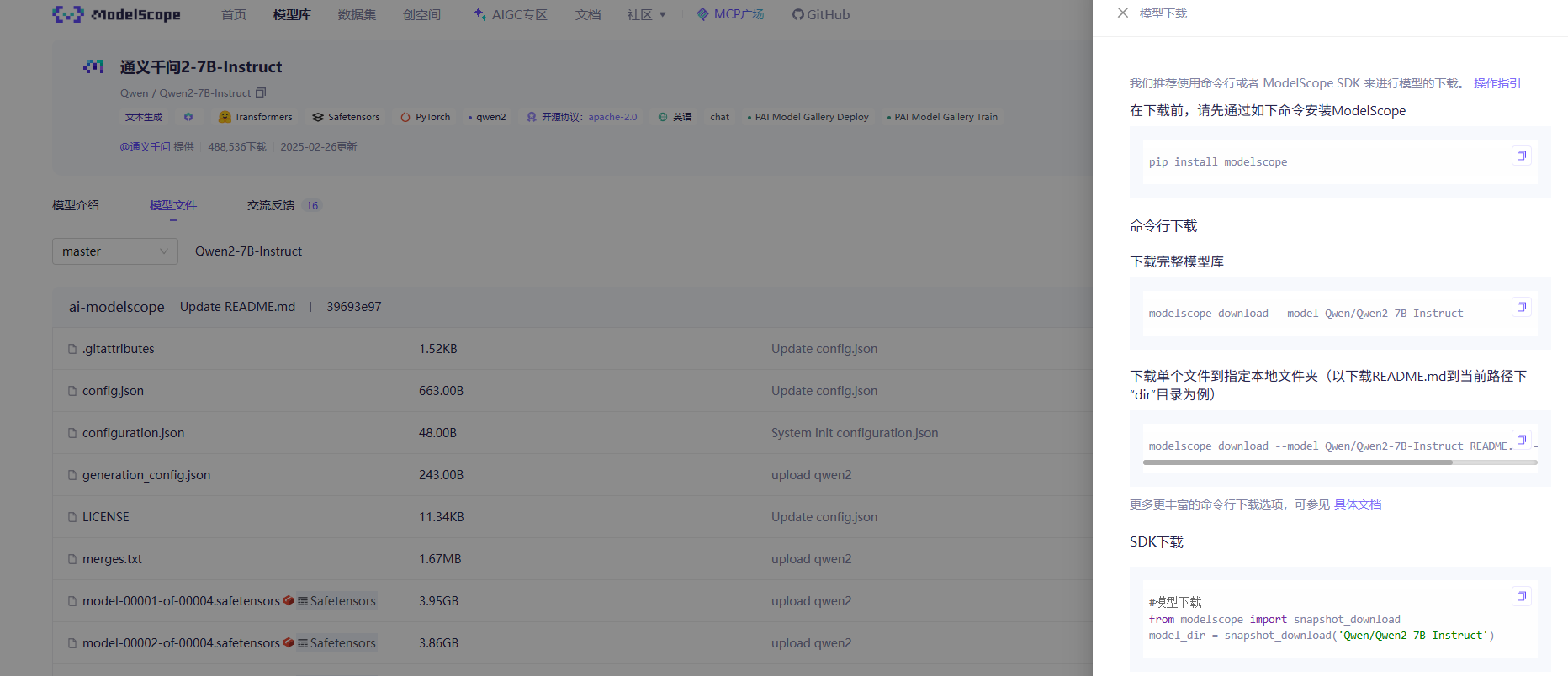
具体方式就是复制其中的SDK下载的内容到 download.py文件中,并python 下载它
cd /home/HwHiAiUser
vim download.py
cat download.py#模型下载 from modelscope import snapshot_download model_dir = snapshot_download('Qwen/Qwen2-7B-Instruct',cache_dir="/home/HwHiAiUser/")
##添加cachedir 的路径为当前目录
python3 download.py可能会有一点卡顿,但是最终我们会下载成功的
4.构建mindie镜像容器
cd /home/HwHiAiUser4.1.下载docker
yum install docker
4.2.更新docker源
vim /etc/docker/daemon.json{ "insecure-registries": ["https://swr.cn-east-317.qdrgznjszx.com"], "registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"] }
systemctl restart docker.service4.3 拉取镜像
docker pull swr.cn-east-317.qdrgznjszx.com/sxj731533730/mindie:atlas_800_90004.4 创建镜像
vim docker_run.sh#!/bin/bash
docker_images=swr.cn-east-317.qdrgznjszx.com/sxj731533730/mindie:atlas_800_9000
model_dir=/home/HwHiAiUser #根据实际情况修改挂载目录
docker run -it --name qdaicc --ipc=host --net=host
--device=/dev/davinci3
--device=/dev/davinci4
--device=/dev/davinci5
--device=/dev/davinci6
--device=/dev/davinci7
--device=/dev/davinci_manager
--device=/dev/devmm_svm
--device=/dev/hisi_hdc
-v /usr/local/dcmi:/usr/local/dcmi
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi
-v /usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/common
-v /usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/driver
-v /etc/ascend_install.info:/etc/ascend_install.info
-v /etc/vnpu.cfg:/etc/vnpu.cfg
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info
-v ${model_dir}:${model_dir}
-v /var/log/npu:/usr/slog ${docker_images}
/bin/bash
bash docker_run.sh
exit5. 拉起大模型服务
进入mindie容器,找到它的container_id ,这边假设为xxxxxxx
docker ps -a
docker exec -it xxxxxxx /bin/bash5.1 修改模型的配置文件
我们来到模型的下载路径下,要修改的是下面的这个config文件,不同模型的路径不同但是这个config文件都会存在
cd /home/HwHiAiUser/Qwen/Qwen2-7B
vim config.json将其中的 btype 改为 float16
5.2 在mindie上配置模型的相关信息
查看本机的ip地址,我们关注198.168开头的这个ip
ifconfig
cd /usr/local/Ascend/mindie/latest/mindie-service
vim conf/config.json修改以下参数(根据自己的情况进行更改)
"ipAddress" : "192.168.2.85" // 改为自己本机的ip地址
"managementIpAddress" : "192.168.2.85""port" : "1025" // mindie服务对外访问的端口
"httpsEnabled" : false
"npuDeviceIds" : [[0,1,2,3]], // 使用的npu_id"truncation" : true
"modelName" : "Qwen2-7B" // 模型名称
"modelWeightPath" : "/home/HwHiAiUser/Qwen/Qwen2-7B" // 存放模型的路径名称
"worldSize" : 4 // 使用的npu数量
"maxInputTokenLen" : 4096"maxIterTimes" : 4096
{
"Version" : "1.0.0",
"LogConfig" :
{
"logLevel" : "Info",
"logFileSize" : 20,
"logFileNum" : 20,
"logPath" : "logs/mindie-server.log"
},
"ServerConfig" :
{
"ipAddress" : "192.168.2.85",
"managementIpAddress" : "192.168.2.85",
"port" : 1025,
"managementPort" : 1026,
"metricsPort" : 1027,
"allowAllZeroIpListening" : false,
"maxLinkNum" : 1000,
"httpsEnabled" : false,
"fullTextEnabled" : false,
"tlsCaPath" : "security/ca/",
"tlsCaFile" : ["ca.pem"],
"tlsCert" : "security/certs/server.pem",
"tlsPk" : "security/keys/server.key.pem",
"tlsPkPwd" : "security/pass/key_pwd.txt",
"tlsCrlPath" : "security/certs/",
"tlsCrlFiles" : ["server_crl.pem"],
"managementTlsCaFile" : ["management_ca.pem"],
"managementTlsCert" : "security/certs/management/server.pem",
"managementTlsPk" : "security/keys/management/server.key.pem",
"managementTlsPkPwd" : "security/pass/management/key_pwd.txt",
"managementTlsCrlPath" : "security/management/certs/",
"managementTlsCrlFiles" : ["server_crl.pem"],
"kmcKsfMaster" : "tools/pmt/master/ksfa",
"kmcKsfStandby" : "tools/pmt/standby/ksfb",
"inferMode" : "standard",
"interCommTLSEnabled" : true,
"interCommPort" : 1121,
"interCommTlsCaPath" : "security/grpc/ca/",
"interCommTlsCaFiles" : ["ca.pem"],
"interCommTlsCert" : "security/grpc/certs/server.pem",
"interCommPk" : "security/grpc/keys/server.key.pem",
"interCommPkPwd" : "security/grpc/pass/key_pwd.txt",
"interCommTlsCrlPath" : "security/grpc/certs/",
"interCommTlsCrlFiles" : ["server_crl.pem"],
"openAiSupport" : "vllm"
},
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1,
"npuDeviceIds" : [[0,1,2,3]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
"interNodeTlsCaPath" : "security/grpc/ca/",
"interNodeTlsCaFiles" : ["ca.pem"],
"interNodeTlsCert" : "security/grpc/certs/server.pem",
"interNodeTlsPk" : "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrlPath" : "security/grpc/certs/",
"interNodeTlsCrlFiles" : ["server_crl.pem"],
"interNodeKmcKsfMaster" : "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb",
"ModelDeployConfig" :
{
"maxSeqLen" : 2560,
"maxInputTokenLen" : 4096,
"truncation" : true,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "Qwen2-7B",
"modelWeightPath" : "/home/HwHiAiUser/Qwen/Qwen2-7B",
"worldSize" : 4,
"cpuMemSize" : 5,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false
}
]
},
"ScheduleConfig" :
{
"templateType" : "Standard",
"templateName" : "Standard_LLM",
"cacheBlockSize" : 128,
"maxPrefillBatchSize" : 50,
"maxPrefillTokens" : 8192,
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 200,
"maxIterTimes" : 4096,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000
}
}
}5.3 启动大模型服务
chmod -R 750 /home/HwHiAiUser/Qwen/Qwen2-7B
cd /usr/local/Ascend/mindie/latest/mindie-service
./bin/mindieservice_daemon5.4 记录大模型启动成功的日志

6. 大模型提问测试
重新启动一个终端,并输入以下指令查看是否后台在正常运作大模型
npu-smi info 提问相关的问题,注意这边的ip和端口
提问相关的问题,注意这边的ip和端口
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"inputs": "停车识别系统的主要识别对象",
"parameters": {
"decoder_input_details": true,
"details": true,
"do_sample": true,
"max_new_tokens": 50,
"repetition_penalty": 1.03,
"return_full_text": false,
"seed": null,
"temperature": 0.5,
"top_k": 10,
"top_p": 0.95,
"truncate": null,
"typical_p": 0.5,
"watermark": false
}
}' http://192.168.2.85:1025/generate
测试结果,注意格式!!!

7.进行压力测试(性能测试)
确保大模型已经在后台跑起来了,我们这采取的方式是压力测试benchmark ,具体可看以下配置MindIE Benchmark-MindIE Benchmark-MindIE Service开发指南-服务化集成部署-MindIE1.0.RC2开发文档-昇腾社区
7.1 进入容器
docker exec -it xxxxxx /bin/bash7.2 创建压力测试配置文件
cd /usr/local/Ascend/atb-models/tests/modeltest/
vim synthetic_config.json{
"Input":{
"Method": "uniform",
"Params": {"MinValue": 512, "MaxValue": 512 }
},
"Output": {
"Method": "gaussian",
"Params": {"Mean": 100, "Var": 200, "MinValue": 512, "MaxValue": 512 }
},
"RequestCount": 16
}
简单说明一下上面参数的含义:输入的tokens是512,输出的是tokens是512,同时16个并发请求
7.3 修改文件权限
chmod 640 synthetic_config.json7.4 设置结果在控制界面
export MINDIE_LOG_TO_STDOUT="benchmark:1; client:1"7.5 测试指令
下面是指令详解
benchmark
--DatasetType "synthetic" # 数据集类型
--ModelName Qwen2-7B # 模型名称
--ModelPath "/home/HwHiAiUser/Qwen/Qwen2-7B" # 模型位置
--TestType vllm_client # 测试客户端类型
--Http http:// 192.168.2.85:1025 #推理服务API地址
--ManagementHttp http:// 192.168.2.85:1026 # 管理接口地址
--Concurrency 16 # 高并发压力
--MaxOutputLen 512 # 生成长文本
--TaskKind stream # 流式请求
--Tokenizer True # 是否启用分词器
--SyntheticConfigPath ./synthetic_config.json # 控制输入输出数据分布
benchmark --DatasetType "synthetic" --ModelName Qwen2-7B --ModelPath "/home/HwHiAiUser/Qwen/Qwen2-7B" --TestType vllm_client --Http http://192.168.2.85:1025 --ManagementHttp http://192.168.2.85:1026 --Concurrency 16 --MaxOutputLen 512 --TaskKind stream --Tokenizer True --SyntheticConfigPath ./synthetic_config.json7.6 结果分析
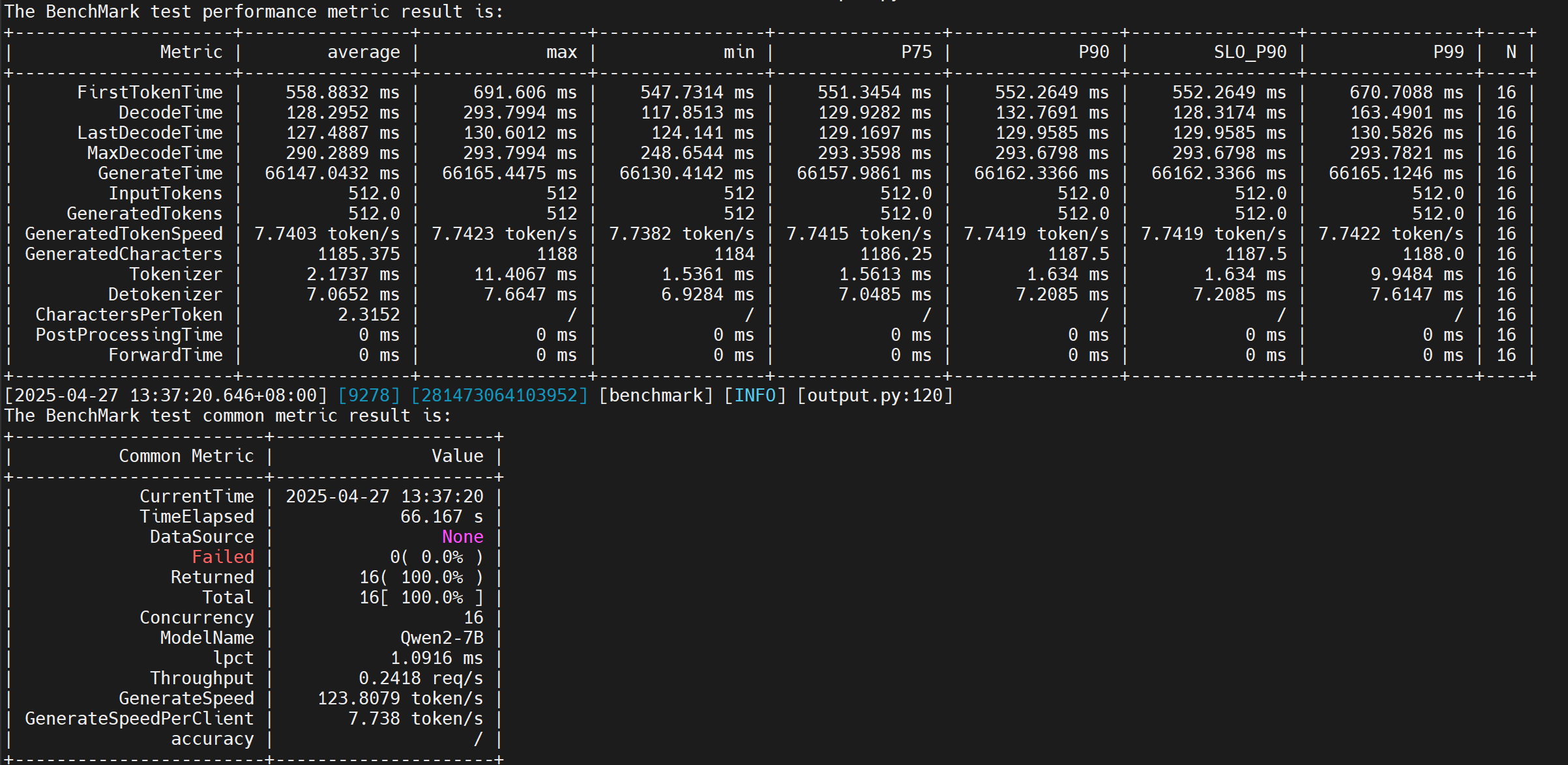
我们主要是关心 GenerateSpeedPerClient 这个参数,这个参数可以清晰的说明当前gpu的推理速度(7.738tokens/s 说慢不慢,说快不快 哈哈)
测试数据解释
| 指标 | 单位 | 说明 |
|
| FirstTokenTime | 毫秒 | 首 Token 延迟:从请求发送到收到第一个输出 Token 的时间(含网络+服务端处理)(反映用户体验的响应速度) | 高并发下首 Token 延迟较高 |
| DecodeTime | 毫秒 | 单 Token 解码延迟:每个输出 Token 的解码耗时(模型推理核心时间) | 高并发导致某些请求排队时间激增 |
| LastDecodeTime | 毫秒 | 最后一个 Token 解码延迟:生成结束前的最终解码耗时 | 如果较首 Token 略高,可能因上下文增长导致计算量增加 |
| GenerateTime | 毫秒 | 总生成时间**:从请求开始到完整输出生成的总耗时 | 与 `MaxOutputLen` 匹配,性能和效果较为理想 |
Token统计
| 指标 | 单位 | 说明 |
|
| InputTokens | 个 | 输入 Token 数量 | 固定为512(由 `synthetic_config.json` 控制)。 |
| GeneratedTokens | 个 | 输出 Token 数量 | 固定为512(受 `--MaxOutputLen 512` 限制) |
| GeneratedTokenSpeed | 个 | 每秒生成的 Token 数(整体吞吐量) | 说明模型并行处理能力 |
其它指标
| 指标 | 单位 | 说明 |
|
| Tokenizer | 毫秒 | 输入分词耗时 | 如果为0,可能未启用或未记录分词步骤 |
| Detokenizer | 毫秒 | 输出反分词耗时 | 反序列化开销时间 |
通用指标
| 指标 | 说明 |
|
| TimeElapsed | 总测试耗时 | 测试运行时间 |
| Concurrency | 并发请求数 | 反序列化开销时间 |
| Throughput | 请求吞吐量 | 吞吐量,受限于模型生成速度 |
| GenerateSpeed | 全局 Token 生成速度 | 所有请求的 Token 总和除以总时间 |
| GenerateSpeedPerClient | 单客户端 Token 速度 | 每个并发请求的平均速度 |
8. 进行精度测试
确保已经上传data.tar已经上传到服务器
8.1 进入容器
docker exec -it xxxxxx /bin/bash8.2 将文件解压到指定目录下
cd /usr/local/Ascend/atb-models/tests/modeltest
mkdir data
cd data
cp /home/HwHiAiUser/data.tar .
tar -xvf data.tar
rm -rf data.tar