彻底解决 Linux “No enough disk space” 报错:从 df -h 到 ncdu 的最全排查与清理攻略
言简意赅的讲解“No enough disk space”的解决方案
一、问题背景
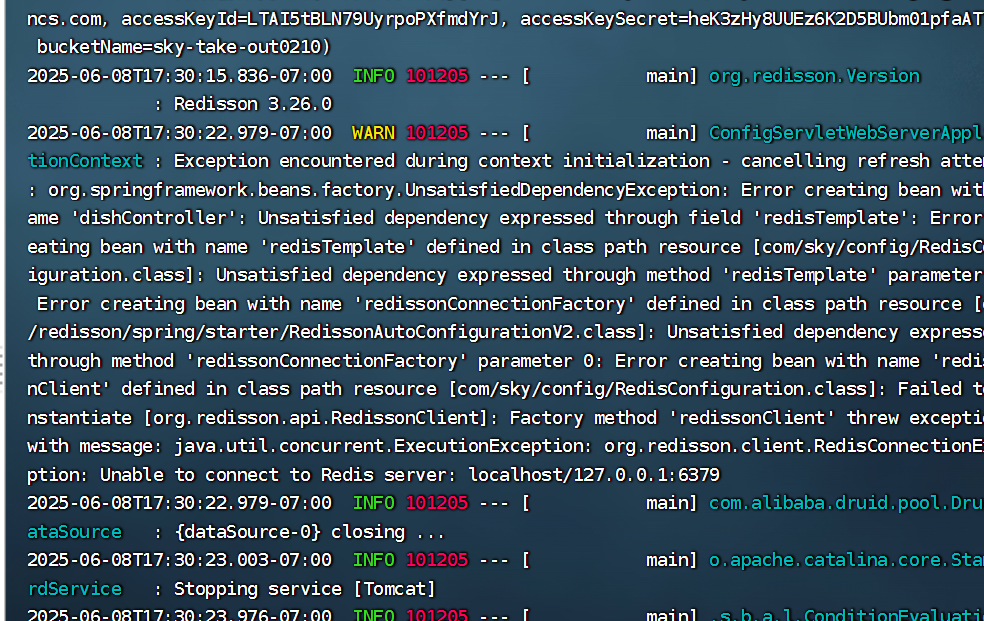
在使用 Linux 服务器或本地环境时,有时会遇到 “No enough disk space” 的报错。通常这意味着系统分区或目录已经被大量文件占满,导致无法再正常写入新的数据。
尤其当你刚接手一个不熟悉的环境,或者在临时登录一台从未使用过的服务器上,需要快速定位哪些文件或目录占用了大量磁盘空间,并且清理它们以恢复系统可用空间。
二、初步检查
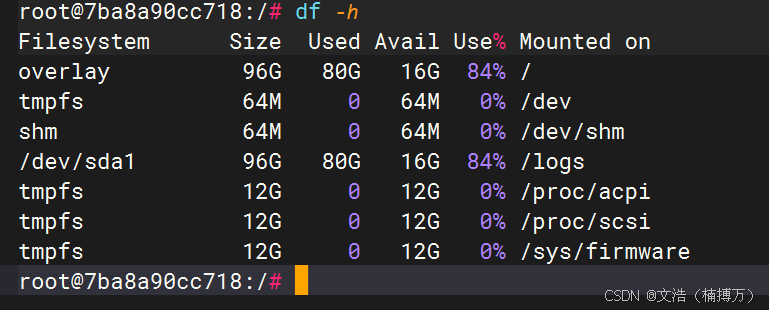
1. 使用 df -h 查看各分区使用情况
首先,要了解磁盘整体概况,最简单、最常用的命令就是 df -h。它可以以人性化的方式(单位为 KB、MB、GB、TB)展示磁盘使用率。
df -h
输出示例(仅供参考):
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 20G 18G 2G 90% /
/dev/sdb1 100G 30G 70G 30% /data
tmpfs 2.0G 0 2.0G 0% /dev/shm
其中 Use% 列可以快速帮我们定位最先需要关注的分区,比如上例中根分区(/)已经达到了 90%,极有可能触发 “No enough disk space” 问题。
2. 进入占用率高的分区查看
假如 df -h 显示根分区(/)的占用率很高,那么我们就要重点排查 / 下哪些子目录最有可能存放了大量文件或大文件。
三、查找占用空间大的文件或目录
在找到问题分区后,我们要进一步定位到底是哪些目录/文件在疯狂占用磁盘空间。这里给出几种常见方法,可以灵活组合使用。
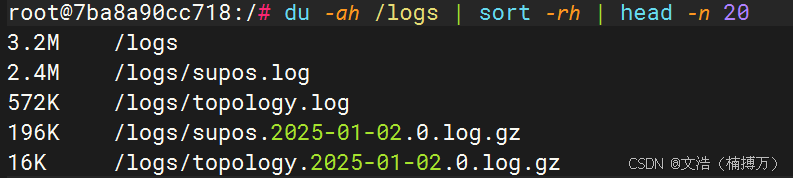
1. du -ah / | sort -rh | head -n 20
最常见的方式是在目标路径下(如 / 或者 /var/log 等具体目录),用 du 命令配合 sort 进行查看:
du -ah / | sort -rh | head -n 20
du -ah /表示递归统计/下所有文件的大小(a参数包含文件和目录,h参数可读性更好)。sort -rh将结果按照大小降序排列(r表示反向排序,h表示按照可读性大小排序)。head -n 20只显示前 20 条结果,方便我们查看最大的占用文件或目录。
根据输出结果,就能快速定位到一些超大的日志文件、备份文件、数据库转储文件,或者忽略已久的旧文件等。
2. 按子目录逐级分析
有时目录结构比较复杂,我们可以先在 / 目录执行命令,找到最大的一级目录,然后逐层深入。例如:
cd /
du -sh * | sort -rh | head -n 10
输出类似:
15G var
3.0G home
2.0G usr
...
然后再进入 var/ 目录,使用同样的方式:
cd /var
du -sh * | sort -rh | head -n 10
如此层层深入,直到找到具体文件。
3. 交互式工具 ncdu
如果可以安装软件的话,ncdu 是一个非常好用的交互式命令行工具。它会扫描指定目录并以可视化的树状结构显示每个文件夹的大小,并提供上下选择、查看子目录的功能,使用非常直观。
- 安装(Debian/Ubuntu 系):
sudo apt-get update sudo apt-get install ncdu - 使用:
ncdu /
然后即可在类图形界面中浏览并快速跳转、删除文件等(删除前请谨慎判断)。
四、常见占用空间原因及处理思路
1. 日志文件(/var/log)
日志文件在故障或调试模式下有可能疯狂增长,尤其是一些应用日志。
- 可选择对已过期的日志进行压缩或删除。
- 配置日志滚动策略(如
logrotate),避免单个文件持续增长。
2. 数据库转储/备份文件
数据库自动备份脚本有时会一直往磁盘写转储文件,比如 mysqldump 生成的 .sql 文件等。
- 检查定时任务(
cron),删除或备份到外部存储。 - 合理设置备份策略,避免堆积旧备份。
3. 大的临时文件(/tmp、/var/tmp)
临时文件通常应用程序用完后就可以清理,但很多时候却不会自动删除。
- 查看
/tmp目录下文件,如无必要可手动删除。 - 注意重要的正在使用的临时文件不能随意删除,要先确认是否还在被占用。
4. 容器/虚拟机相关镜像和日志
如果使用 Docker / Kubernetes / LXC 等容器技术,镜像和容器日志都可能占用大量空间。
- 容器镜像(
docker images)过多或者被标记 - 容器日志位于
/var/lib/docker/containers/下,大量日志需要定期清理或将日志设置为自动滚动。
5. 无用的缓存文件
一些应用或包管理器可能会缓存大量文件。例如:
yum或apt-get的缓存目录- 浏览器缓存、Python pip 缓存等
可以安全地清理它们来腾出空间。
6. 已被删除但仍被进程占用的文件
如果一个大文件被删除,但相关进程并未关闭该文件句柄,磁盘空间依旧被占用。
- 可使用
lsof | grep deleted来确认。 - 重启对应进程或整个服务后,该文件才真正释放空间。
五、更多进阶技巧
1. 使用 find 命令按时间或大小搜索
有时我们想快速查找最近 7 天修改过、且大于 100M 的文件:
find / -type f -mtime -7 -size +100M
-mtime -7表示修改时间在 7 天内-size +100M表示文件大小大于 100M
这样可以根据实际需求按大小或时间来筛选目标文件。
2. 分析日志滚动是否正常
针对日志类文件,可以查看系统配置 /etc/logrotate.conf 或 /etc/logrotate.d/ 下的内容,看是否存在滚动配置,以及当前执行状态是否正常。在许多 Linux 系统中,logrotate 是默认安装且每天通过 cron 作业执行滚动。
3. 利用 journalctl 管理 systemd 日志
如果系统采用 systemd,可以使用 journalctl 命令查看和限制 systemd 日志大小,例如:
journalctl --disk-usage
sudo journalctl --vacuum-size=500M
通过 --vacuum-size 可以将日志文件缩减到指定大小,避免占用过多空间。
4. 检查硬链接和软链接
某些场景下,大文件被硬链接(hard link)到多处,你删除了其中一个,但实际上并未真正减少占用。可以借助命令或工具排查硬链接数量。
5. 规划合理的分区方案
如果有权限规划磁盘,可以根据应用场景、日志大小、数据频繁度等来调整各分区大小、使用独立分区或挂载点,减少某个单点分区被意外塞满导致全盘不可用的问题。
六、后续建议
-
建立周期性巡检
- 例如使用定时脚本(cron)定期执行
df -h及相应的扫描命令,把结果邮件发送给管理员,以便提前发现潜在问题。 - 配合监控工具(如 Prometheus + Grafana、Zabbix 等)实时监控磁盘使用情况并设置告警。
- 例如使用定时脚本(cron)定期执行
-
配合版本控制、备份和归档策略
- 系统日志和业务日志应定期压缩或转移到其他存储设备,降低本地空间消耗。
- 数据库类备份的存储方式、存放周期都需要有明确的策略。
-
谨慎清理,做好预备措施
- 不要盲目删除系统关键文件,一定要先确认文件是否还被使用、是否对系统或应用有影响。
- 在正式清理前可以先将大文件移动到安全位置或压缩备份,以防误操作。
七、总结
当你在陌生的 Linux 设备上遇到 “No enough disk space” 报错,最核心的解决思路就是:
- 用
df -h找到占用率高的分区; - 用
du、ncdu或find等方法定位占用磁盘空间最大的文件或目录; - 根据具体情况(日志、备份、临时文件或容器镜像等)进行清理;
- 建立合理的日志滚动和备份归档策略,避免问题重复发生;
- 通过监控和报警机制,实现对磁盘空间的持续关注。
通过上述内容,你就已经基本理解了这个方法,基础用法我也都有展示。如果你能融会贯通,我相信你会很强
Best
Wenhao (楠博万)