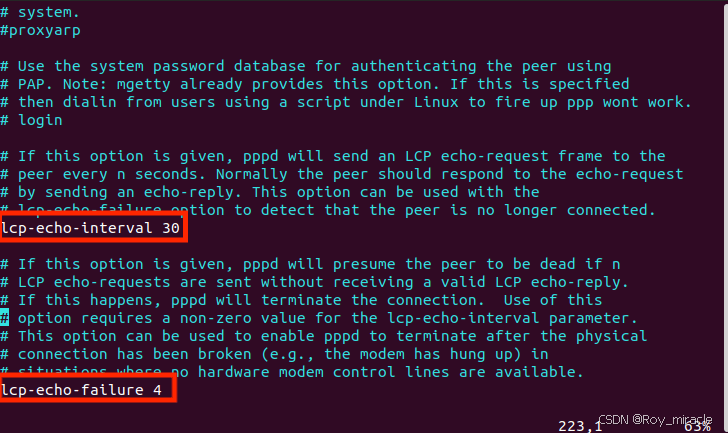
网络药理学:11、分子对接之PDB数据库使用、PubChem如果没有3D结构、autodock+mgltools实现大分子蛋白(PDB ID已知)和小分子配体对接
PDB数据库使用
官方地址:https://www.rcsb.org/
首页如下:
我们以热休克蛋白HSP90AA1为例,其PDB ID为7DHG,所以我们在搜索栏输入7DHG:
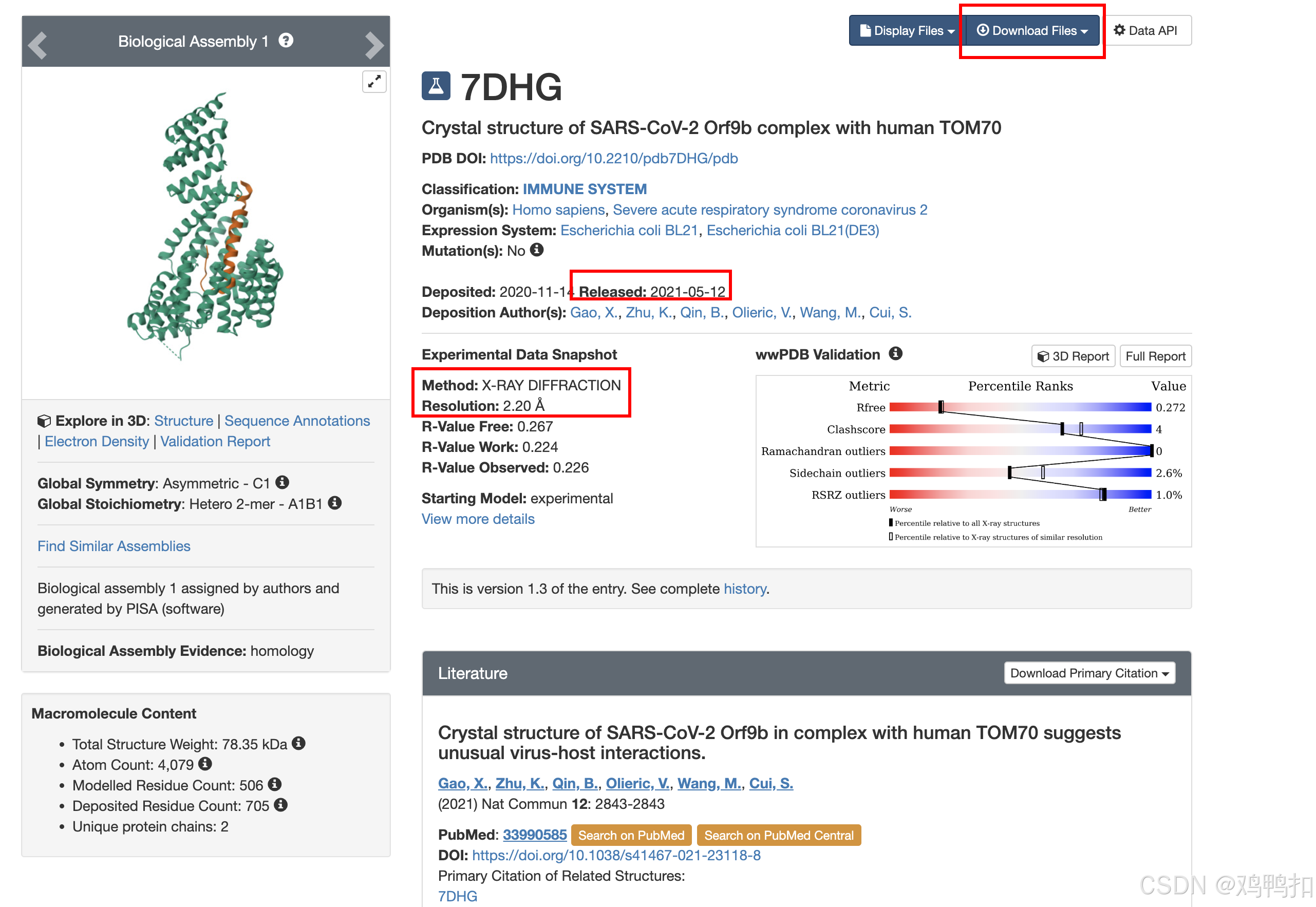
主要关注红框里的几个地方。
Download下载文件,一般选择PDB Format即可Released发表时间Method一般只有X-Ray(X射线)和NMR两种。其中X射线最常见也最好Resolution分辨率相关的指标,越小说明分辨率越高。一般小于2A就足够好了,具体看论文的指标。
再往下翻,主要看该蛋白有几条链,并且右下角Go to UniProtKB可以直接跳转到UnitProt数据库
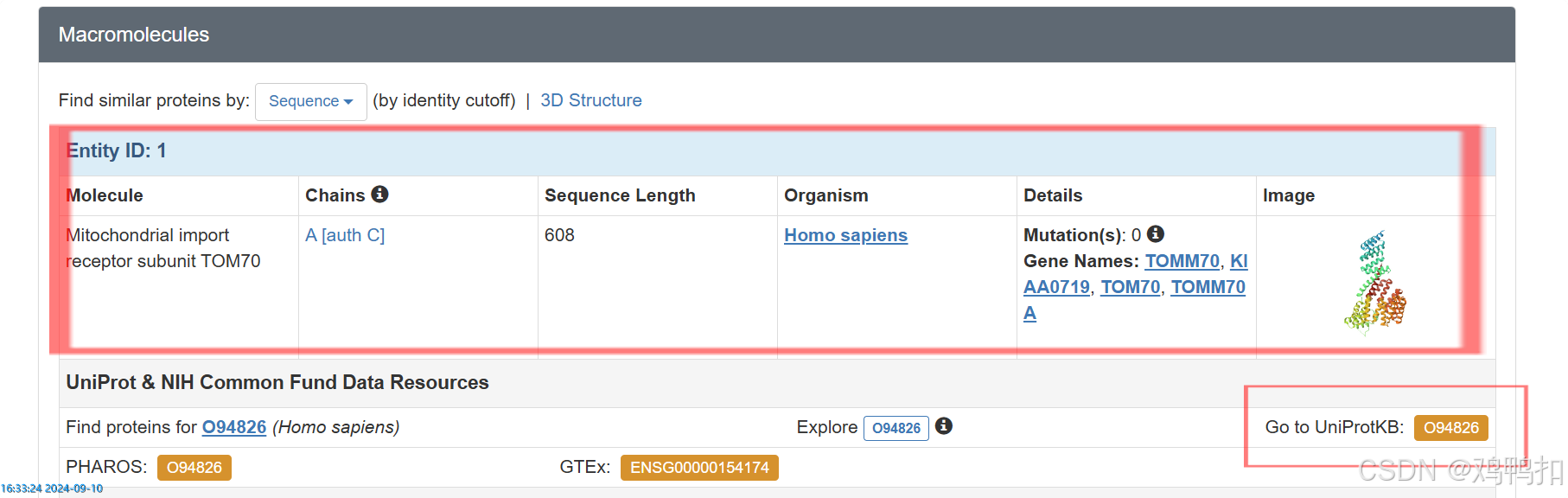
可以看到,这里该蛋白是有两条链的。
同时,对于一些有小分子的蛋白也最好看看相关信息,这里我展示另一个7A2O示例:
一般要记住这里的ID,在处理蛋白的时候要去除。

PubChem数据库如果没有3D结构
PubChem数据库如果没有3D结构,只有2D结构的SDF,我们可以下载Chem3D软件,将2D结构的SDF文件导入进去,并且Calculations/MM2/Minimize Energe实现能量最小化。
但是该软件只有windows版本,属于ChemOffice全家桶的一部分,资源比较难找。
推荐直接去其他数据库再找找小分子配体的mol2结构。
然后再通过OpenBabel/mgltools转化为pdbqt的格式。
分子对接前言
我们这里要复现的是一篇大黄素对食管癌的影响的论文。
大分子蛋白这里以ESR2蛋白为例,其PUB ID为7XVY。
小分子配体这里以大黄素emodin为例,其分子ID为MOL000472。
B站相关推荐视频如下:https://www.bilibili.com/video/BV1NK411i7No/
Autodock tools和autodock本身下载和注意事项这里并不涉及,后续会单独出一个博客讲解。
文章的快速实践命令总结位于:http://t.csdnimg.cn/hGanb
大分子蛋白准备
PDB数据库下载蛋白
不会操作的具体可见我的另一篇博客:http://t.csdnimg.cn/QDEAS
pymol前置处理
不会操作的具体可见我的另一篇博客:http://t.csdnimg.cn/i0vpE
其他处理(添加分子伴侣、判断是否删去同源肽链)
蛋白质的层级结构
回顾一下蛋白质的层级结构:
一级结构、二级结构、超二级结构、结构域、三级结构、四级结构(亚基)
-
一级结构:氨基酸序列,无空间意义。可以在Uniprot数据库查询。
主要作用力:肽键、二硫键 -
二级结构:肽链主链骨架的空间位置(α-螺旋、β-折叠、β-转角、无规则卷曲)。
主要作用力:氢键
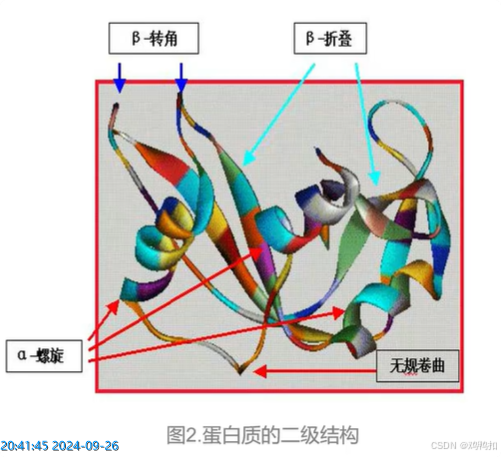
-
超二级结构:相邻的二级结构单元形成的有规则的组合体。例如:αα(两个α-螺旋)。仍旧没有活性。
-
结构域:肽链上几个相邻的超二级结构单元的组合,每个结构域分别代表一种功能单位。是拥有活性的。一般说的蛋白口袋/活性位点就是一个结构域。
-
三级结构:多肽链中全部氨基酸残基的相对空间位置。结构域是三级结构层次上的独立功能区。
主要作用力:疏水作用、盐键、二硫键、氢键、离子键。 -
四级结构:蛋白质含有2条或2条以上多肽链。每一条多肽链都有其完整的三级结构,称为亚基。亚基与亚基之间呈特定的三维空间排布,并以非共价键相连接。蛋白质分子中各个亚基的空间排布及亚基接触部位的布局和相互作用,称为蛋白质的四级结构。
主要作用力(亚基之间的作用力):氢键、离子键。在2个亚基组成的四级结构蛋白质中,若亚基结构相同、氨基酸序列相同、三级结构相同(又称同源),称之为同二聚体,若亚基分子不同,则称之为异二聚体,多个亚基可以此类推。
总结:
- 一级结构:氨基酸序列
- 二级结构:碳链碳骨架空间位置,α-螺旋等。
- 超二级结构:二级结构组合体,αα(两个α-螺旋)等。
- 结构域:超二级结构组合体。开始有生物活性。
- 三级结构:多肽链中氨基酸的空间位置。
- 四级结构:亚基(有完整三级结构的多肽链)之间的相对空间位置。
分子伴侣
理论上讲,如果蛋白质的多肽链随机折叠,可能产生成千上万种可能的空间构象。而实际上,蛋白质合成后,只形成一种正确的空间构象。除一级结构为决定因素外,还需要在一类称为分子伴侣的蛋白质辅助下,合成中的蛋白质才能折叠成正确的空间构象。只有形成正确的空间构象的蛋白质才具有生物学功能。
所以在分子对接之前,我们可能需要添加分子伴侣。
判断是否需要删去同源肽链
如果一个蛋白有多个同源的肽链,分子对接可以只保留一条吗?
同源的意思是指,这多条肽链氨基酸序列一样,构象一样。
要看分子对接的位点是否处于多个亚基的结合区域,如果是,则不能删。
如果否,就能删。
Autodock tools前置处理
加载蛋白
打开Autodock tools,如果页面如下
即在Dashboard/Scenario/Tools这一行没有

那么就意味着你没有把adt.bat文件和Autodock4、Autogrid4两个文件放在一起。
注意Autodock tools不可以直接将pdb文件拖入中加载(也是很垃圾的一点……
选择File/Read Molecule后选择文件加载,如下:

加氢
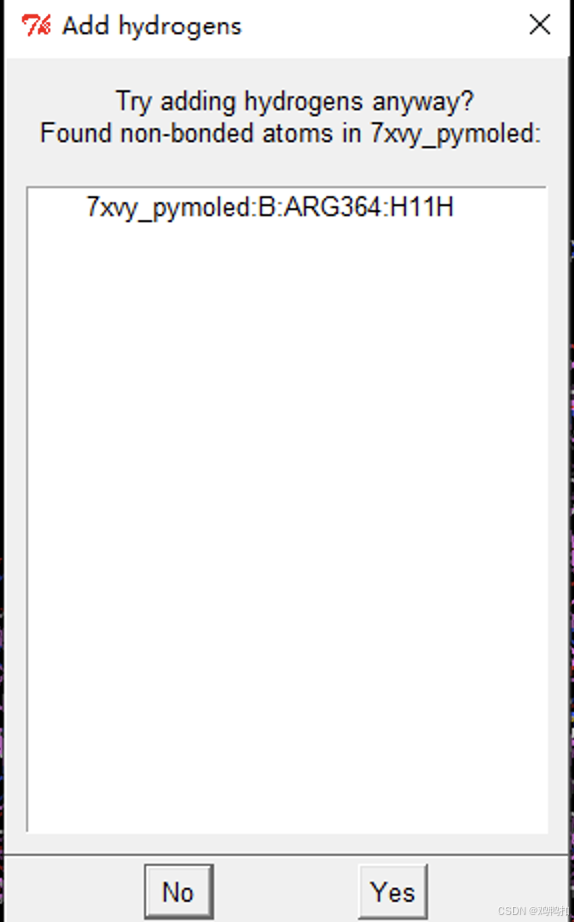
选择Edit/Hydrogens/Add进行加氢,如下会弹出一个页面,直接选择YES即可。
然后是进一步的配置界面,也直接选择Yes即可。
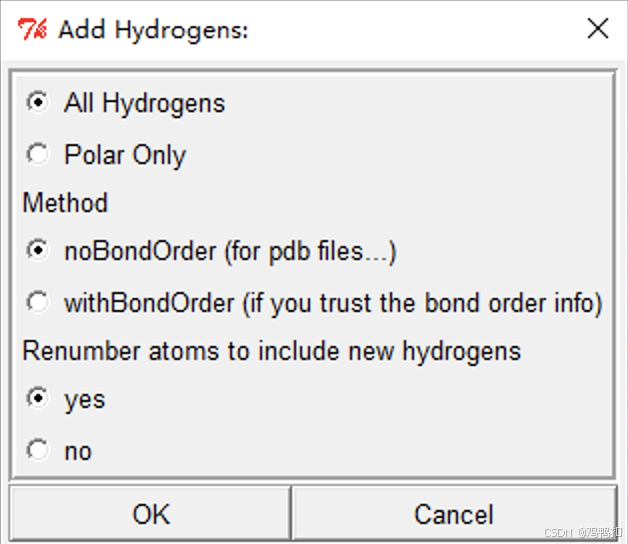
其实加氢分为几种情况,可以加全氢/极性氢/活性位点附近氨基酸残基加氢。
从左到右的精准度会越来越高,速度越来越快,但相应的也需要提前查询文献,知道的信息越多。
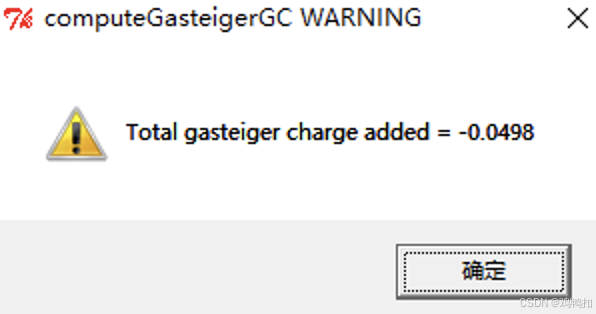
计算总电荷
再选择Edit/Chargs/Compute Gasteiger,即可计算总电荷,如下:
指定原子类型
选择Edit–Atoms–Assign AD4 type,即可指定原子类型。
转为pdbqt文件
选择File/save/write PDBQT后出现如下。
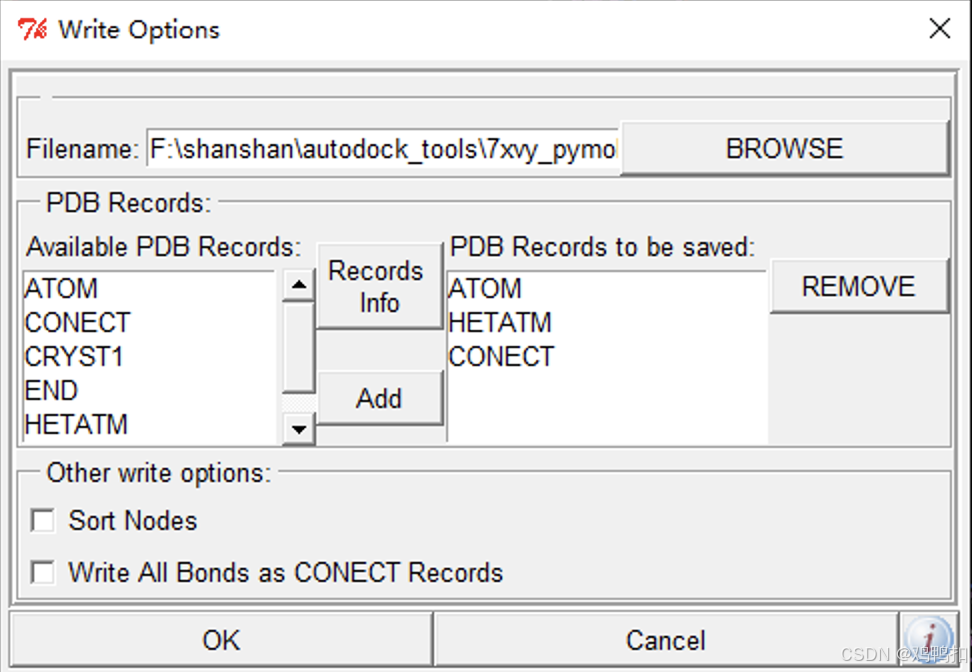
直接点击OK,转为pdbqt格式
小分子配体准备(如果事先准备好了小分子的pdbqt文件,可以跳过)
加载配体
重新打开autodock tools软件,或者点击Edit/Delete/Delete All Molecules清空页面。
注意也是不能将小分子配体下载好的mol文件直接拖拽进autodock tools界面里的。
而是选择Ligand/Input/Open(可能跳出弹窗,直接选择yes即可),加载成功如下:
选择并判断配体的 Root
选择Ligand > Torsion Tree > Choose Root”和“Ligand > Torsion Tree > Detect Root。
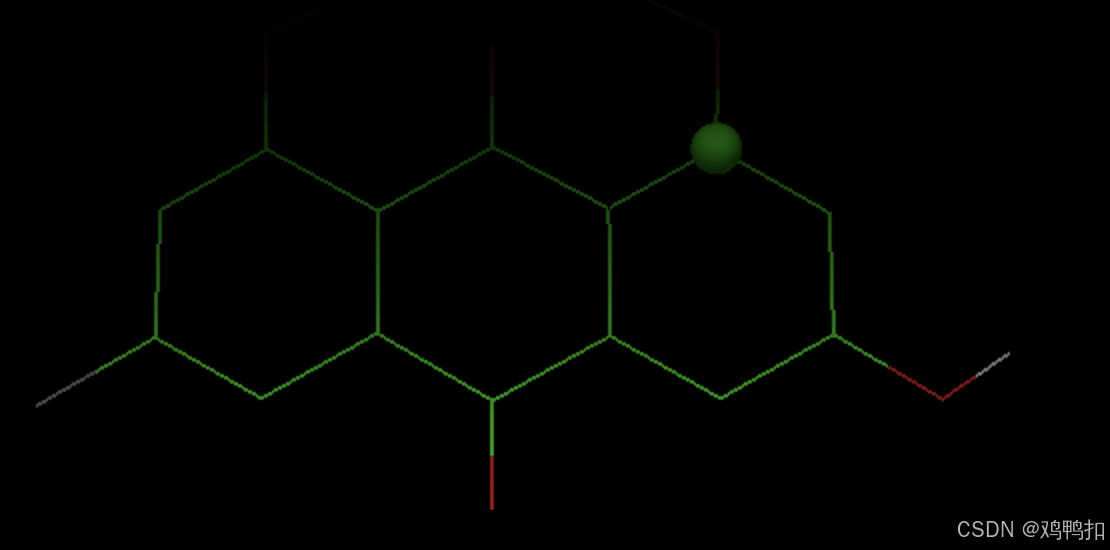
然后选择Ligand > Torsion Tree > Show Root Expansion,如下:
查看可旋转的键
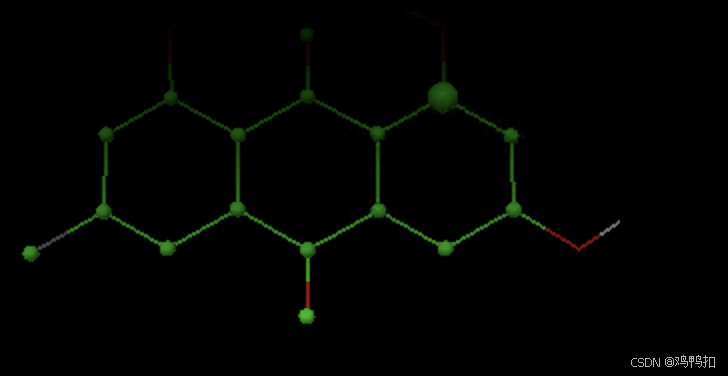
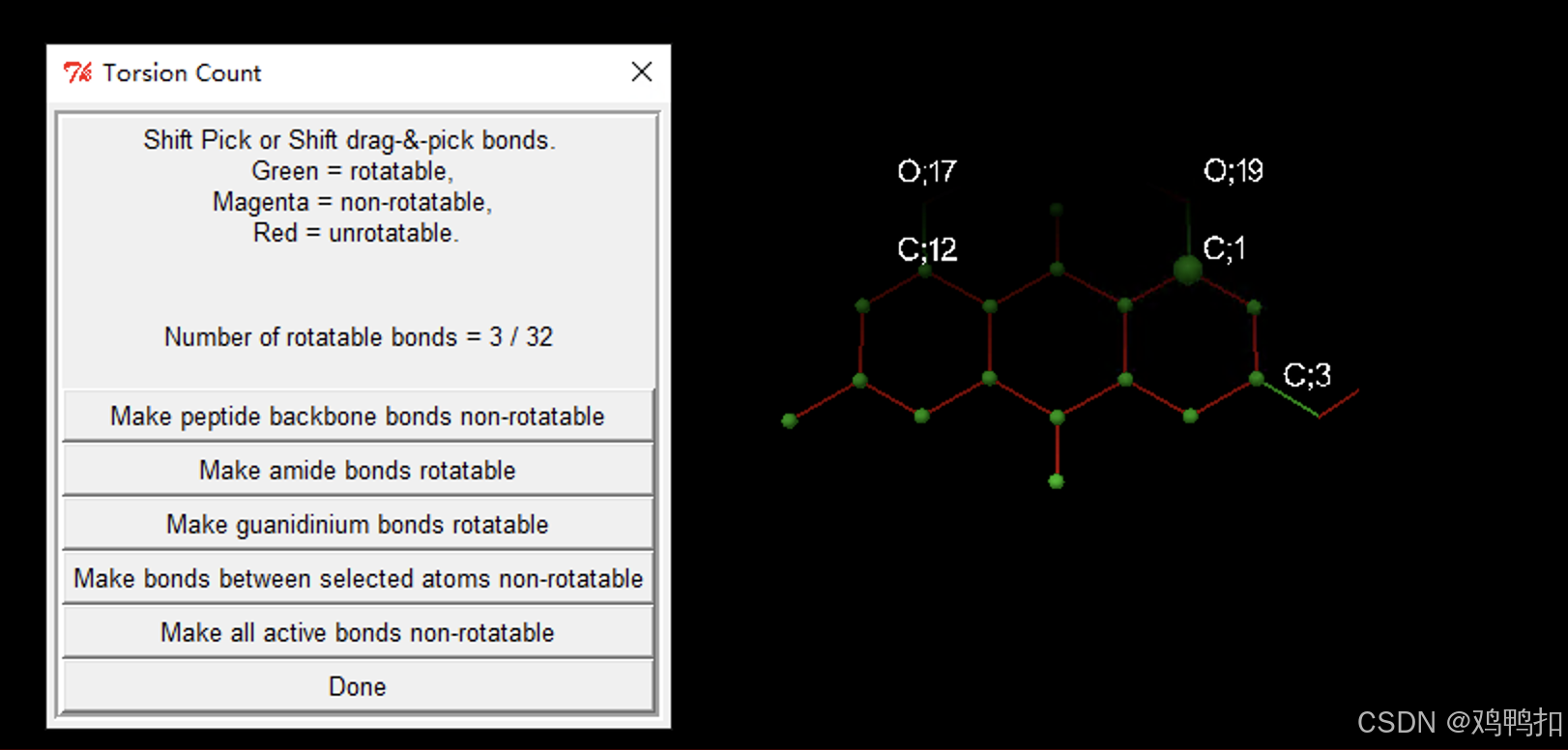
选择Ligand > Torsion Tree > Choose Torsion,绿色的表示可以旋转,然后点击Done。
保存成PDBQT
点击Ligand—Output > Save as PDBQT即成功保存pdbqt文件
随后点击Edit/Delete/Delete All Molecules清空软件页面(页面留下绿色小球不影响后续操作)
Grid map准备
重新打开autodock tools软件,或者点击Edit/Delete/Delete All Molecules清空页面。
加载大分子蛋白和小分子配体
点击Grid > Macromolecule > Open,导入大分子蛋白的pdbqt文件,提示是否保留分子中的电荷,选择Yes(之后可能再次冒出两个提示的弹窗,全都选择Yes即可)
如果你是刚刚根据上文用autodock tools处理小分子配体为pdbqt格式文件的话,选择Grid > Set Map Types > Choose Ligand…导入小分子配体的pdbqt格式文件
如果你是之前就处理好了小分子配体的pdbqt格式文件的话,直接选择Grid > Set Map Types > Open Ligand…
最终页面如下(如果没看到小分子配体的话,可以旋转缩放一下界面,可能挡住了而已):
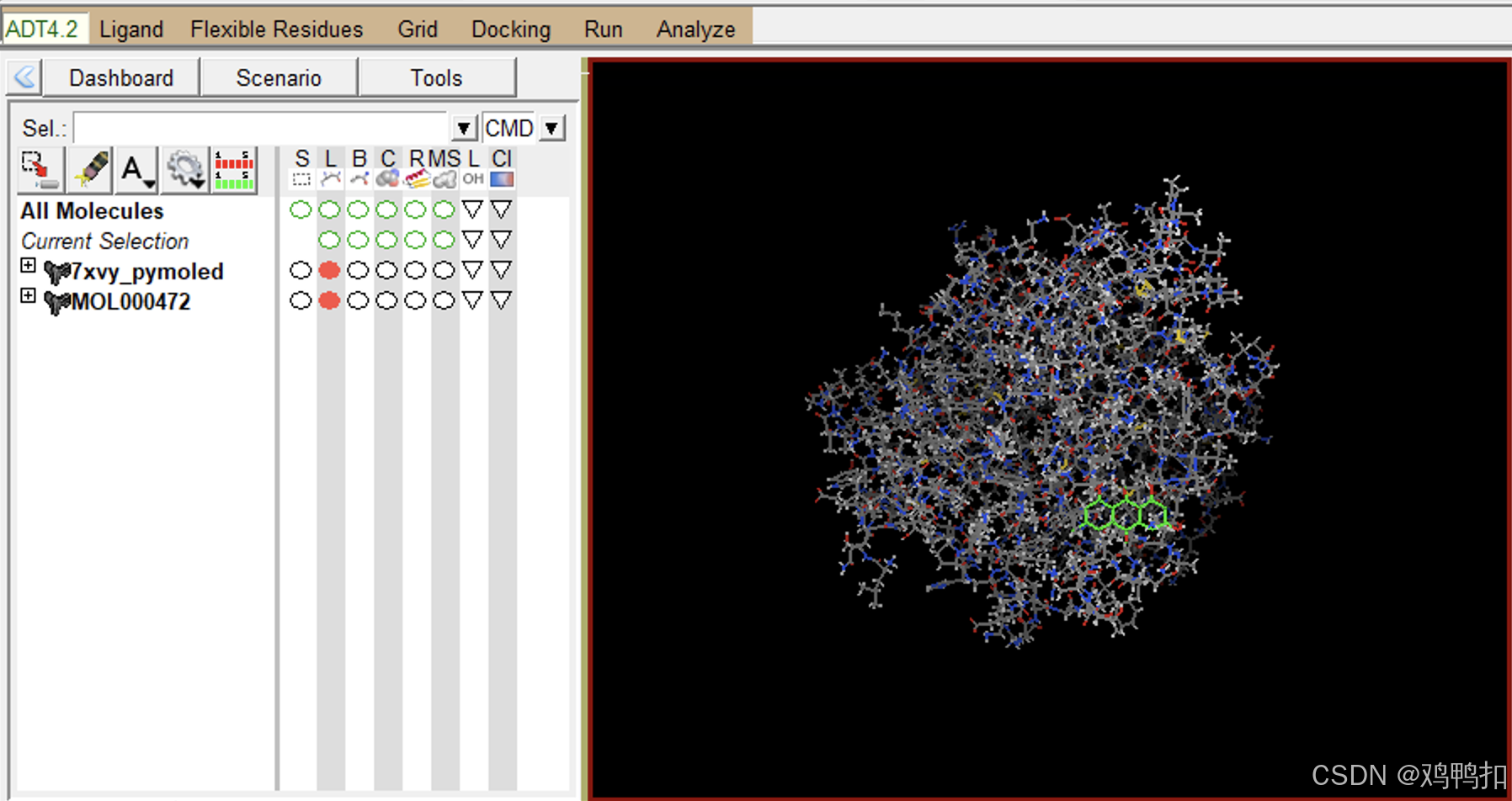
移动小分子配体
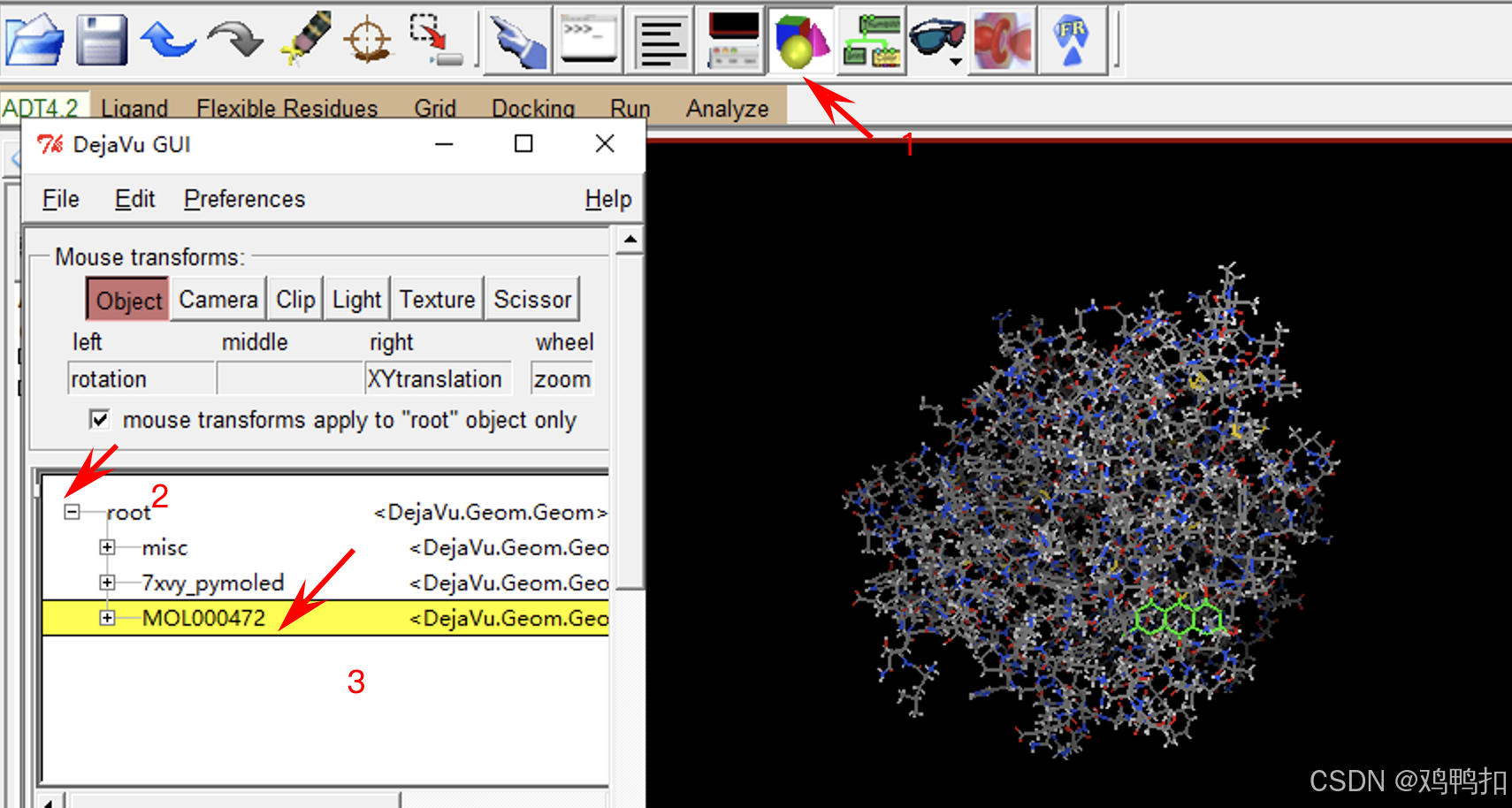
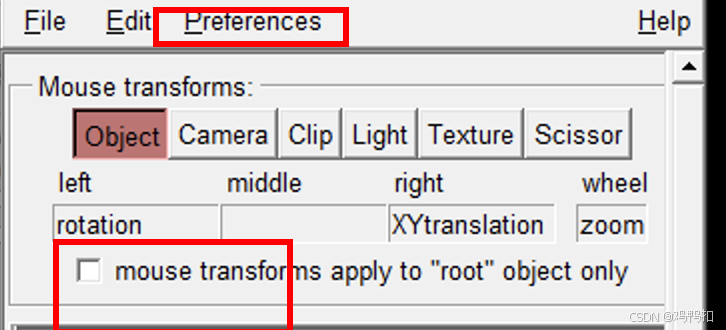
点击Preference,选择取消Transf. Root Only后可以看到mouse transforms apply ...前面的勾也被取消了。
此时我们就可以鼠标右键选择小分子配体了,把小分子配体移动到合适的位置(即远离大分子蛋白一定的距离),如下:
然后我们把Transf. Root Only选项再勾上。
设置对接口袋
选择Grid > Grid Box…,打开Grid Options对话框。
鼠标中键滚轮可以调整x,y,z三维大小及Spacing(也就是前四个选项)
其中Spacing (angstrom)是整体缩放盒子大小的。
最终调整盒子大小和位置为完全包裹住大分子且不接触小分子配体(如果明确蛋白活性口袋位置,那么也可以只包裹住该位置),如下:
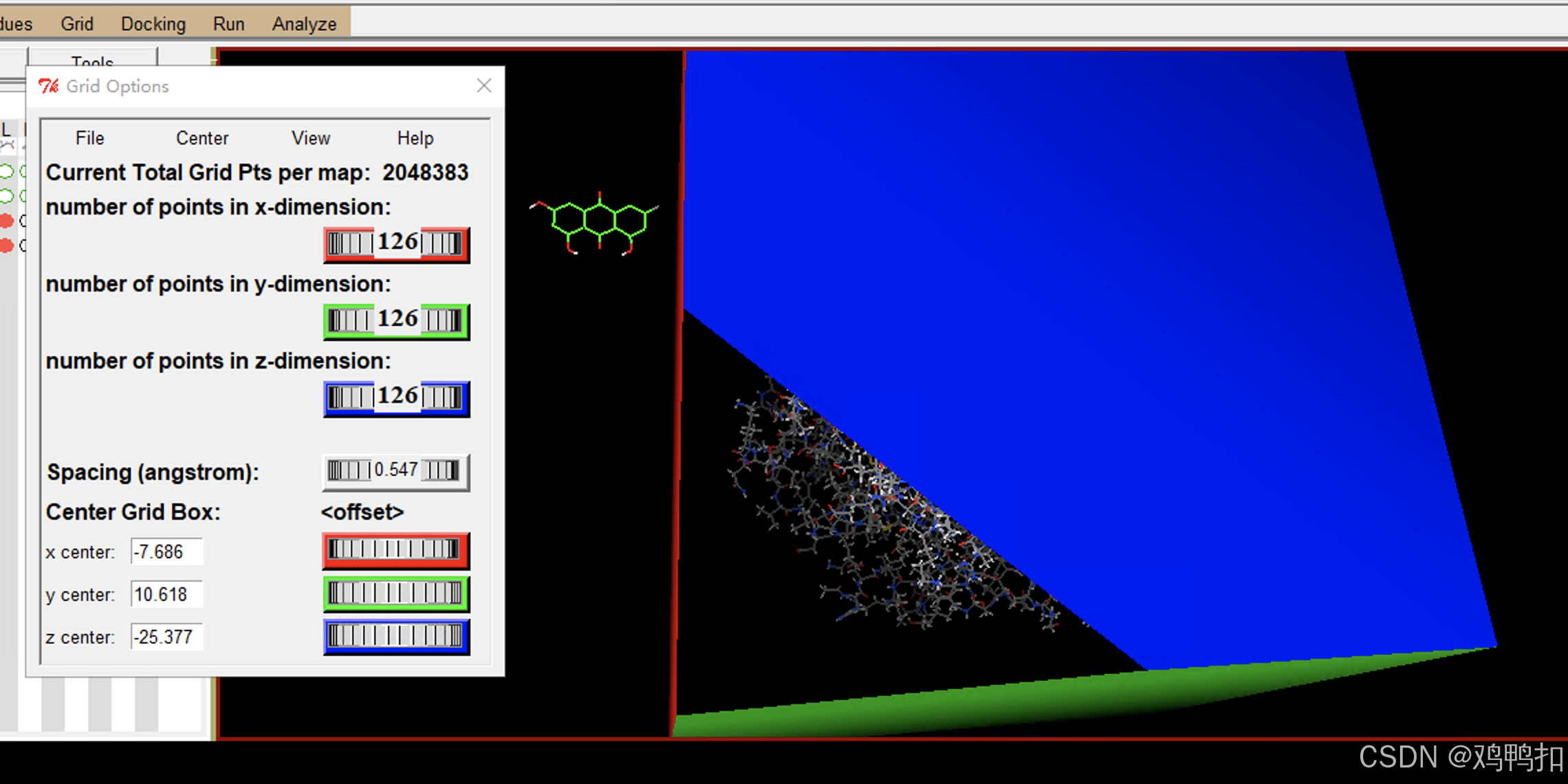
点击Grid Options弹窗的File > Close saving current退出。
保存GPF文件
选择Grid > Output > Save GPF...,文件名需要手动加上后缀名.gpf。
我一般文件名命名为蛋白质PUB ID_小分子配体MOL ID后四位.gpf的格式,譬如这里的7xvy_0472.gpf
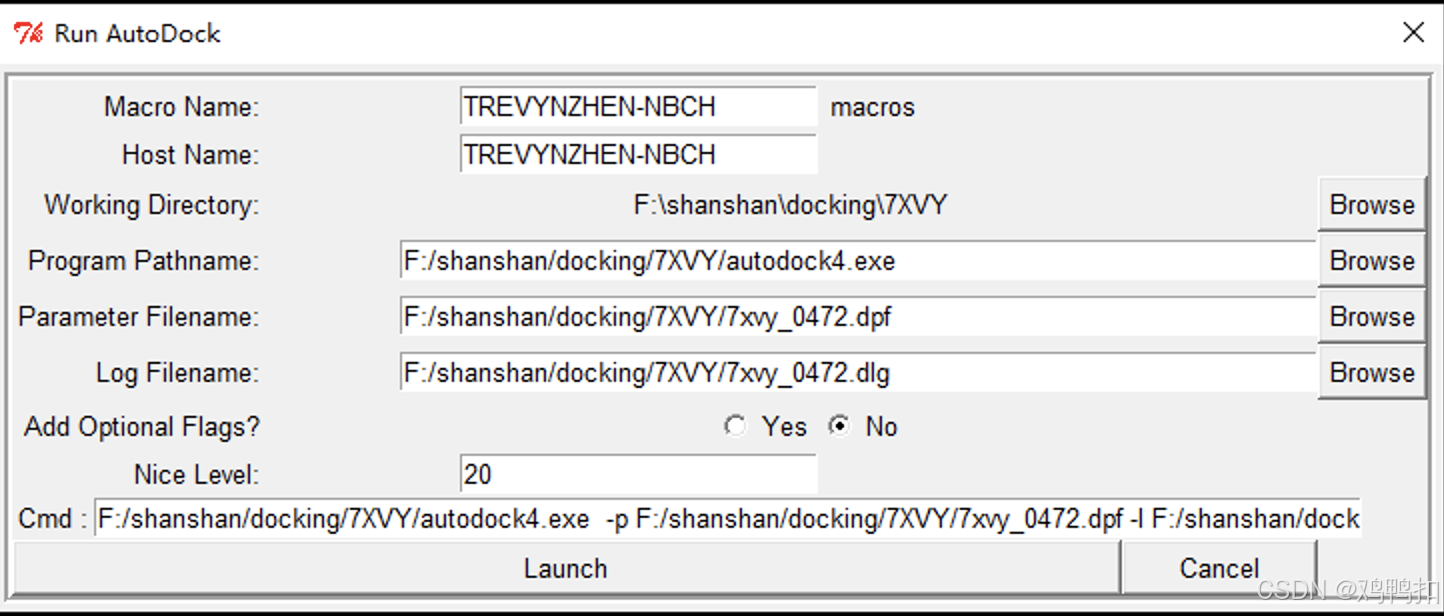
运行Grid
- 选择
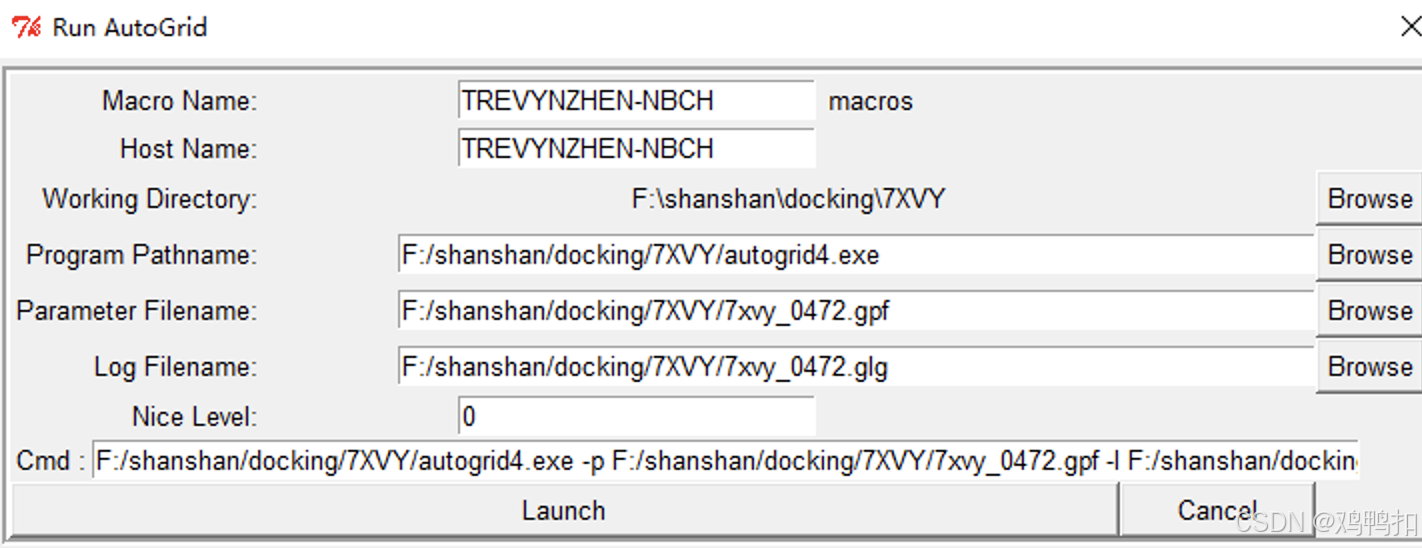
Run > Run AutoGrid,在Program Pathname框中选择atuogrid4.exe文件所在位置。注意:一定要自己选择一下,虽然这个窗口打开后这里默认有值autogrid4.exe! Parameter Filename框中选择上一步生成的.gpf文件。注意:也是要自己选择一下,虽然窗口打开后这里默认有值!选中之后可以发现Log Filename也会检测到值。- 最后点击
Launch。等待窗口的任务完成,弹窗会自动消失(需要一定时间),此时工作目录会多出一堆文件。
正式分子对接
点击Edit/Delete/Delete All Molecules清空软件页面。
加载大分子蛋白和小分子配体
-
导入
Receptor(即大分子蛋白):Docking > Macromolecule > Set Rigid Filename…(导入后页面没有什么变化是正常的) -
导入
Ligand(即小分子配体):
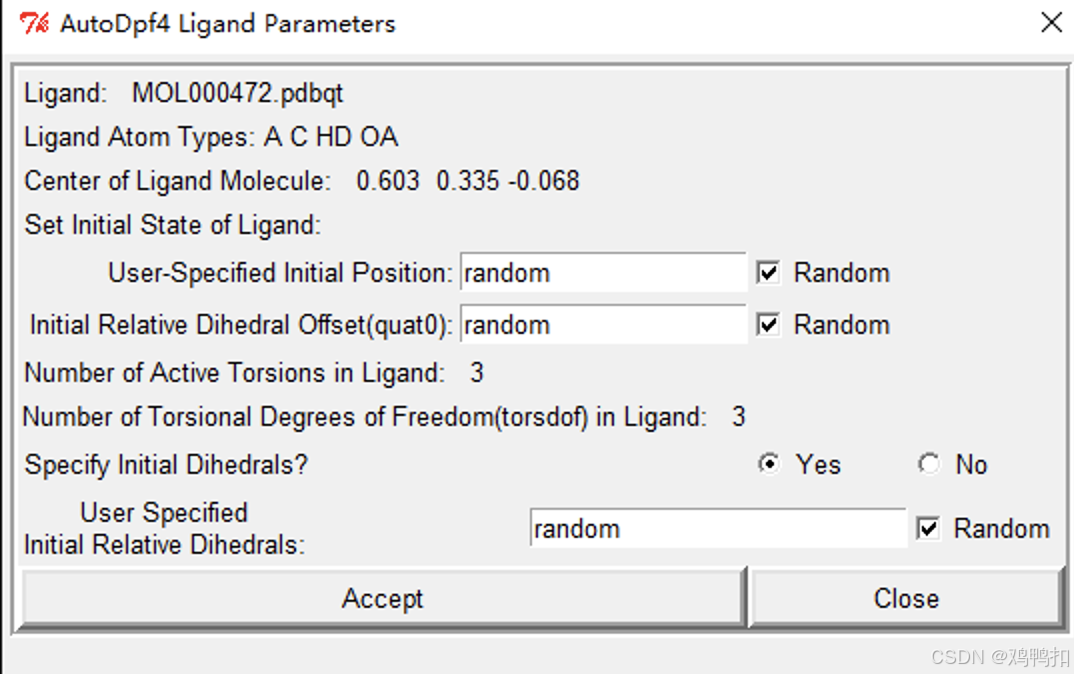
同样的,如果你是刚刚根据上文用autodock tools处理小分子配体为pdbqt格式文件的话,选择Docking > Ligand > Choose...导入小分子配体的pdbqt格式文件
如果你是之前就处理好了小分子配体的pdbqt格式文件的话,选择Docking > Ligand > Open...。选择后,对话框显示如下,选择Accept。
设置算法
一般算法选择:Docking > Search Parameters > Genetic Algorithm,默认设置,点击Accept。
但是如果你对于准确度要求不是很高,可以选择Docking > Search Parameters > Local Search Parameters,这样会快一些。
导出DPF文件
设置对接参数。ADT菜单栏:Docking > Docking Parameters…,默认设置,点击Accept。
保存算法:Docking > Output > Lamarckian GA (4.2)…。
(如果你在设置算法一步选择了Local Search Parameters,那么这里选择Local Search(4.2))
注意文件名需要手动加上后缀名.dpf。
我一般文件名命名为蛋白质PUB ID_小分子配体MOL ID后四位.dpf的格式,譬如这里的7xvy_0472.dpf
运行Dock
运行:Run > Run AutoDock,和运行Grid一样的注意事项。
如下,点击Launch后等待弹窗的任务完成,弹窗会自动消失(会比运行Grid快一些),对接完成。
点击Edit/Delete/Delete All Molecules清空软件页面
结果分析
打开.dlg文件:Analyze > Dockings > Open...。(可能有warning弹窗,直接选择ok就好)
显示 Receptor大分子蛋白:Analyze > Macromolecule > Open...,显示窗口自动导入 Receptor。
查看分子对接结果:Analyze > Conformations > Play, ranked by energy...。
- 查看第一个结合点位。因为是按照能量大小的绝对值来排序的,绝对值越大的放在越前面,说明分子对接的效果越好。所以一般我们看第一个就行了。
- 点击倒数第二个图标显示
Set Play Options面板 - 点击
Show Info图标显示Conformation 1 info面板。其中我们最关注的就是binding_energy的值,这里它= -7.71 - 点击
Build H-bonds图标显示Hydrogen Bonds面板 - 点击
Write Complex图标保存成pdbqt格式文件。需要加上.pdbqt后缀,我一般命名为7xvy_0472.pdbqt
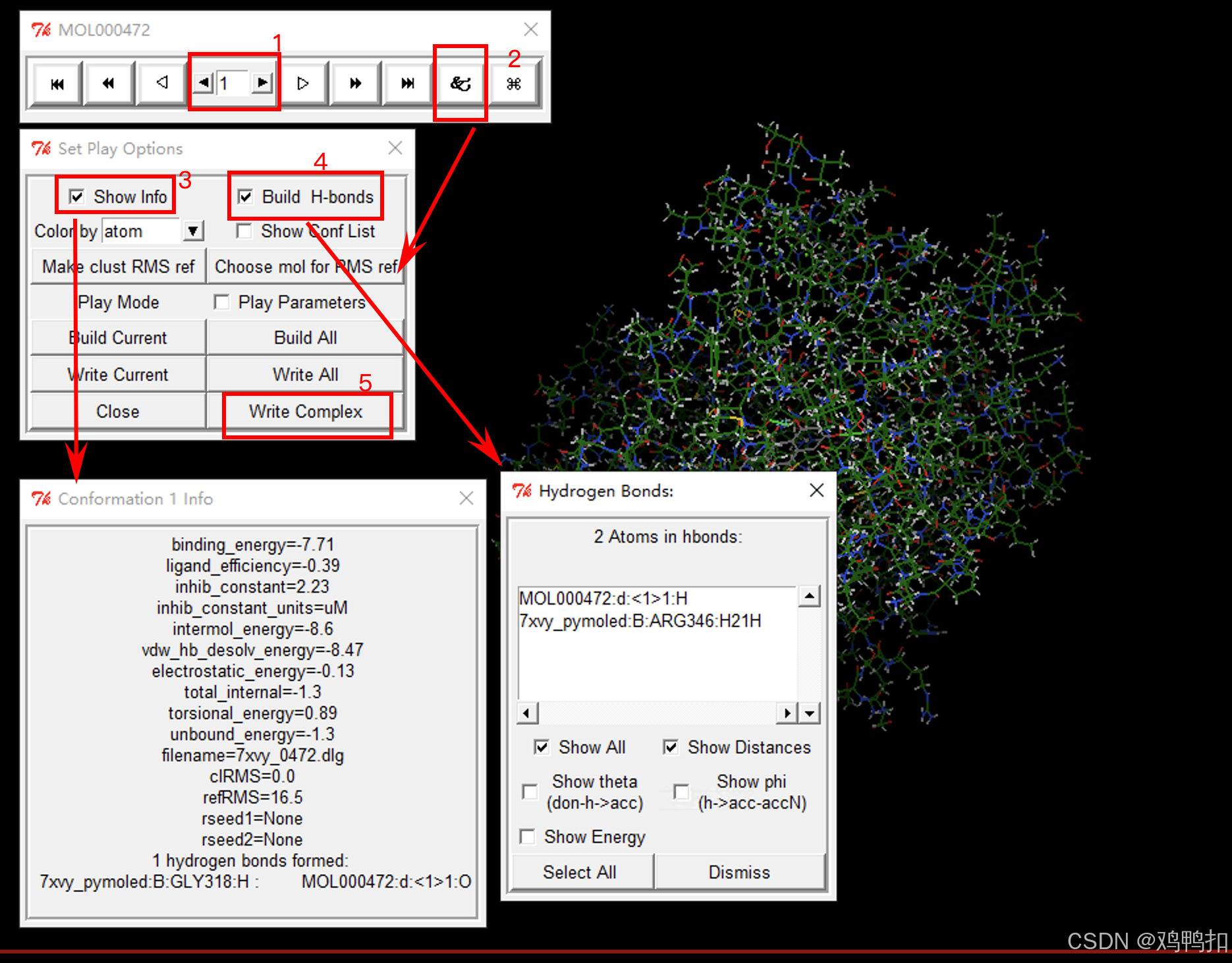
(图中数字表示第几步骤,箭头表示点击后显示什么面板。
结合能(键能)补充知识
结合能(键能):将1摩尔气态分子完全离解为气态原子所吸收的能量,单
位通常为千焦每摩尔(KJ/mol),反映了形成或断裂一个化学键所需要或释放
的能量大小,因此是化学键强度的直接体现。
结合能排序:
离子键 > 共价键 > 金属键 >> 氢键 ≈ π-cation键 > π-π堆积 > 范德华力
其中离子键、共价键、金属键属于化学键。氢键及以后属于次级键。

本文地址:https://www.vps345.com/8209.html