


手把手教你:Windows与Linux下Dify+DeepSeek实现ragflow构建企业知识库

一、引言
在当今人工智能飞速发展的时代,大语言模型(LLMs)已经成为众多领域的核心技术驱动力。无论是在智能客服、智能写作,还是在数据分析、决策支持等方面,大语言模型都展现出了强大的能力和潜力。然而,随着数据安全和隐私保护意识的不断提高,越来越多的企业和开发者开始寻求本地化部署大语言模型的解决方案,以确保数据的安全性和可控性。
搭建本地化知识库并实现接口调用,对于企业和开发者来说具有至关重要的意义。在实际应用场景中,企业内部往往拥有大量的业务数据、文档资料等,这些数据蕴含着丰富的知识和信息。通过搭建本地化知识库,企业可以将这些数据进行有效的整合和管理,利用大语言模型的强大能力,实现对知识的快速检索、智能问答和深度分析。这不仅可以提高企业内部的工作效率,还可以为企业的决策提供更加准确和有力的支持。
在众多的技术方案中,Dify + Ollama + DeepSeek 技术栈脱颖而出,成为了搭建本地化知识库和实现接口调用的理想选择。Dify 是一个开源的 LLM 应用开发平台,它提供了丰富的功能和工具,使得开发者可以轻松地构建和部署基于大语言模型的应用程序。Ollama 则是一个简化 LLM 本地部署的工具,它可以让用户在个人计算机或服务器上轻松运行多种开源语言大模型,无需依赖云端服务,也无需复杂的配置。DeepSeek 作为国产大模型的佼佼者,具有千亿参数规模,在中文基准测试中得分高达 91.5%,推理效率比传统架构提升了 5 倍,而且 API 调用成本低至 0.5 元 / 百万 tokens (各家云平台的 DeepSeek 调用要低于官方价格建议采用这种方式:薅!)。这三者的结合,为我们提供了一个高效、安全、低成本的本地化知识库搭建和接口调用解决方案。接下来我会将详细介绍如何在 Windows 和 Linux 两种环境下部署这一套技术栈,并实现知识库的训练和调用以及接口调用。
二、技术栈介绍
(一)Dify
Dify 是一个开源的 LLM 应用开发平台 ,它融合了后端即服务(Backend as Service)和 LLMOps 的理念,旨在帮助开发者,甚至是非技术人员,能够快速搭建和部署生成式 AI 应用程序。Dify 具有以下显著特点和功能:
- 自定义 AI 工作流:支持用户根据自身业务需求,灵活定义和编排 AI 工作流,实现复杂任务的自动化处理。比如在智能客服场景中,可以设置当用户提出特定问题时,自动触发相应的处理流程,调用相关的知识库和模型进行回答。
- RAG 管道:通过强大的检索增强生成(RAG)技术,Dify 能够有效提升文档检索和问答的准确性。它会在生成回答时,结合用户的问题,从知识库中检索相关信息,并将这些信息融入到回答中,使得回答更加准确、全面。
- 多种模型集成管理:Dify 支持多种主流的大语言模型,如 GPT 系列、Claude、Hugging Face 等,同时也支持本地私有化部署的模型,如我们即将使用的 DeepSeek 模型。这为用户提供了丰富的选择,可以根据不同的应用场景和需求,选择最合适的模型。
- 可视化编排:提供直观的 Prompt 模板、工具链等可视化工具,即使是没有深厚技术背景的用户,也能轻松上手,快速构建和部署 AI 应用。用户可以通过简单的拖拽、配置操作,完成应用的开发,大大降低了开发门槛。
- 丰富功能:除了基本的文本生成、对话功能外,Dify 还支持知识库问答、代码生成等多种功能,满足多样化的应用需求。例如,在开发智能编程助手时,Dify 可以根据用户输入的自然语言描述,生成相应的代码。
- 灵活部署:支持云服务和本地部署两种方式,用户可以根据自身的数据安全和隐私需求,选择合适的部署方式。对于对数据安全要求较高的企业和机构,本地部署可以确保数据完全在自己的掌控之下。
- 可观测性:提供丰富的日志和监控功能,便于用户排查问题和优化性能。用户可以通过查看日志,了解应用的运行情况,及时发现和解决问题;同时,监控功能可以实时监测模型的性能指标,为优化提供数据支持。
在搭建知识库和实现接口调用中,Dify 起着关键的作用。它提供了统一的接口和管理平台,使得用户可以方便地将不同的模型和知识库进行集成,实现高效的知识检索和应用开发。通过 Dify,我们可以快速搭建一个功能强大的知识库应用,并且能够轻松地实现接口调用,将知识库的能力集成到其他系统中。
(二)Ollama
Ollama 是一个开源的本地化工具,专门用于简化大型语言模型的本地运行和部署。它的出现,使得用户可以在个人计算机或服务器上轻松运行多种开源语言大模型,无需依赖云端服务,也无需进行复杂的配置。Ollama 具有以下优势:
- 简化部署流程:Ollama 极大地简化了开源大语言模型的安装和配置过程。用户只需通过简单的命令,就可以快速下载和运行各种模型,例如ollama run llama3.2 就可以一键运行 Llama 3.2 模型。相比传统的模型部署方式,大大节省了时间和精力。
- 支持多种模型:Ollama 支持众多主流的开源大语言模型,如 DeepSeek、qwen、Llama 等,并且模型列表还在不断更新和扩展。这使得用户可以根据自己的需求和偏好,选择合适的模型进行使用。
- 本地运行:所有模型都在本地运行,这意味着用户的数据不会被上传到云端,从而保证了数据的安全性和隐私性。对于一些对数据安全要求较高的场景,如企业内部的知识管理、医疗数据处理等,本地运行的优势尤为明显。
- 提供 API 接口:Ollama 提供了 REST API 接口,方便用户将模型集成到自己的应用程序中。通过 API 接口,用户可以在自己的代码中调用模型,实现各种功能,如文本生成、问答系统等。
在我们的技术栈中,Ollama 主要负责在本地运行 DeepSeek 模型,并为 Dify 提供模型服务。通过 Ollama,Dify 可以方便地调用本地的 DeepSeek 模型,实现知识库的训练和调用。同时,Ollama 的本地运行特性,也保证了我们的数据安全和隐私,避免了数据在传输和存储过程中的风险。
(三)DeepSeek
DeepSeek 是国产大模型中的佼佼者,具有千亿参数规模,在自然语言处理任务中展现出了卓越的性能。它具有以下突出优势:
- 低成本:DeepSeek 以较低的成本训练出了千亿参数的大模型,其 API 调用成本低至 0.5 元 / 百万 tokens ,相比其他同类模型,具有更高的性价比。这使得企业和开发者在使用大模型时,可以大大降低成本,提高经济效益。
- 高得分:在中文基准测试中,DeepSeek 得分高达 91.5%,展现出了强大的语言理解和生成能力。尤其在处理中文语境下的任务时,DeepSeek 能够更加准确地理解用户的意图,生成高质量的回答。
- 高推理效率:推理效率比传统架构提升了 5 倍,能够快速响应用户的请求,提供即时的服务。这对于一些对响应速度要求较高的应用场景,如实时聊天、智能客服等,具有重要的意义。
- 创新技术架构:采用了创新的架构,将传统的串行计算方式转变为类似快递分拣中心的辐射状计算方式,先对数据进行分类打包,再分不同路线同时进行计算,大大提高了计算速度和效率,同时降低了能耗。
- 数据策略优化:通过创新的数据蒸馏技术,有针对性地筛选高质量数据,自动识别高价值数据片段,相比随机采样训练效率提升 3.2 倍。同时,通过对抗训练生成合成数据,将高质量代码数据获取成本从每 100 个 tokens 的 0.8 元降低至 0.12 元。
在本地知识库训练和调用中,DeepSeek 作为核心模型,为整个系统提供了强大的语言理解和生成能力。它能够对知识库中的数据进行深入分析和理解,当用户提出问题时,能够快速准确地从知识库中检索相关信息,并生成高质量的回答。其高推理效率和低成本的特点,使得我们可以在本地环境中高效地运行知识库系统,为用户提供优质的服务。
三、Windows 环境部署
(一)安装前准备
在 Windows 系统下进行部署,首先需要确保系统满足一定的要求。对于 CPU,建议使用英特尔酷睿 i5 及以上或 AMD Ryzen 5 及以上的处理器,以保证有足够的计算能力来运行模型和相关服务。内存方面,至少需要 16GB,若要运行参数规模较大的 DeepSeek 模型,如 32b 版本,则最好拥有 32GB 及以上的内存,避免在运行过程中出现内存不足的情况。硬盘空间也需要预留足够,至少 50GB 用于安装各种软件和存储模型文件,如果要存储多个不同版本的 DeepSeek 模型,建议预留 100GB 以上的空间。
接下来,需要下载一些必要的软件。Docker Desktop 是用于容器化部署 Dify 的工具,可从Docker 官网下载 Windows 版本的安装程序 。Ollama 可从其官方网站下载对应 Windows 系统的安装包。Git 是用于下载 Dify 项目代码的工具,可从Git 官网下载安装程序。在安装这些软件时,要注意安装路径的选择,尽量选择磁盘空间充足且路径简洁的位置,避免因路径过长或包含特殊字符导致安装失败或后续运行出现问题。同时,在安装 Docker Desktop 时,需要确保系统开启了虚拟化技术,如 Hyper - V,可在 BIOS 中进行相关设置。如果安装过程中提示需要安装其他依赖项,务必按照提示进行安装,以确保软件能够正常运行。
(二)安装 Ollama
- 下载安装包:访问 Ollama 官方网站(Ollama),在下载页面中找到适用于 Windows 系统的安装包,点击下载按钮进行下载。由于网络环境的不同,下载速度可能会有所差异,耐心等待下载完成。

- 运行安装程序:下载完成后,找到下载的安装包文件,通常是一个.exe 后缀的文件,双击运行它。在安装向导界面中,按照提示进行操作,一般保持默认设置即可,点击 “Next”(下一步)、“Install”(安装)等按钮,等待安装程序将 Ollama 安装到系统中。安装过程中可能会出现一些提示信息,如询问是否创建桌面快捷方式等,根据个人需求进行选择。
- 验证安装:安装完成后,需要验证 Ollama 是否成功安装。可以通过命令行来进行验证,右键点击 Windows 开始菜单 ,选择 “终端 (管理员)”,在弹出的终端界面中输入 “ollama --version” 命令,然后回车。如果安装成功,终端会显示 Ollama 的版本信息,例如 “ollama version 0.1.25” ,这表明 Ollama 已经正确安装在系统中,可以正常使用。
C:UsersAdministrator>ollama --version
ollama version is 0.5.7
(三)下载并运行 DeepSeek 模型
- 选择合适的模型版本:DeepSeek 模型有多个版本可供选择,如 1.5b、7b、8B 、14b、32b 等,不同版本的模型在参数规模、性能和硬件要求上有所不同。在选择模型版本时,需要根据本地硬件配置来决定。如果显卡显存为 8GB,可以选择 7B 或 8B 版本的 DeepSeek;如果显卡显存为 16GB,可以选择 14B 版本;显存 24GB 以上则可以考虑 32B 版本。例如,如果你的电脑配备了 NVIDIA RTX 3060 显卡,显存为 12GB,那么选择 14b 版本的 DeepSeek 模型可能是一个比较合适的选择,既能充分发挥硬件性能,又能保证模型的运行效果。
- 使用 Ollama 下载并运行模型:打开命令行终端,输入相应的命令来下载并运行 DeepSeek 模型。以下载 14b 版本的 DeepSeek 模型为例,在终端中输入 “ollama run deepseek-r1:8b” 命令,然后回车。Ollama 会自动从远程仓库下载该版本的 DeepSeek 模型文件到本地,并启动模型服务。下载过程的速度取决于网络状况,可能需要一些时间,请耐心等待。下载完成后,模型会在本地运行,此时可以在命令行中与模型进行交互,输入问题,模型会返回相应的回答。
C:UsersAdministrator>ollama run deepseek-r1:8b
C:UsersAdministrator>ollama list #查看是否安装成功
NAME ID SIZE MODIFIED
bge-m3:latest 790764642607 1.2 GB 3 days ago
mxbai-embed-large:latest 468836162de7 669 MB 3 days ago
deepseek-r1:8b 28f8fd6cdc67 4.9 GB 4 days ago #安装成功
qwen2.5:latest 845dbda0ea48 4.7 GB 4 days ago
llama3.2:3b a80c4f17acd5 2.0 GB 5 days ago
nomic-embed-text:latest 0a109f422b47 274 MB 5 days ago- 模型测试:模型下载并运行成功后,需要对其进行测试,以确保模型能够正常工作。在命令行中输入一些简单的问题,如 “你是什么模型?”,如果模型能够正确理解问题并给出有逻辑、有价值的回答,说明模型运行正常。如果模型出现错误提示,需要检查安装过程是否有误,或者尝试重新下载和运行模型。
# 因为没有联网,此步骤只为验证模型已成功运行
C:UsersAdministrator>ollama run deepseek-r1:8b
>>> 你是什么模型
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。
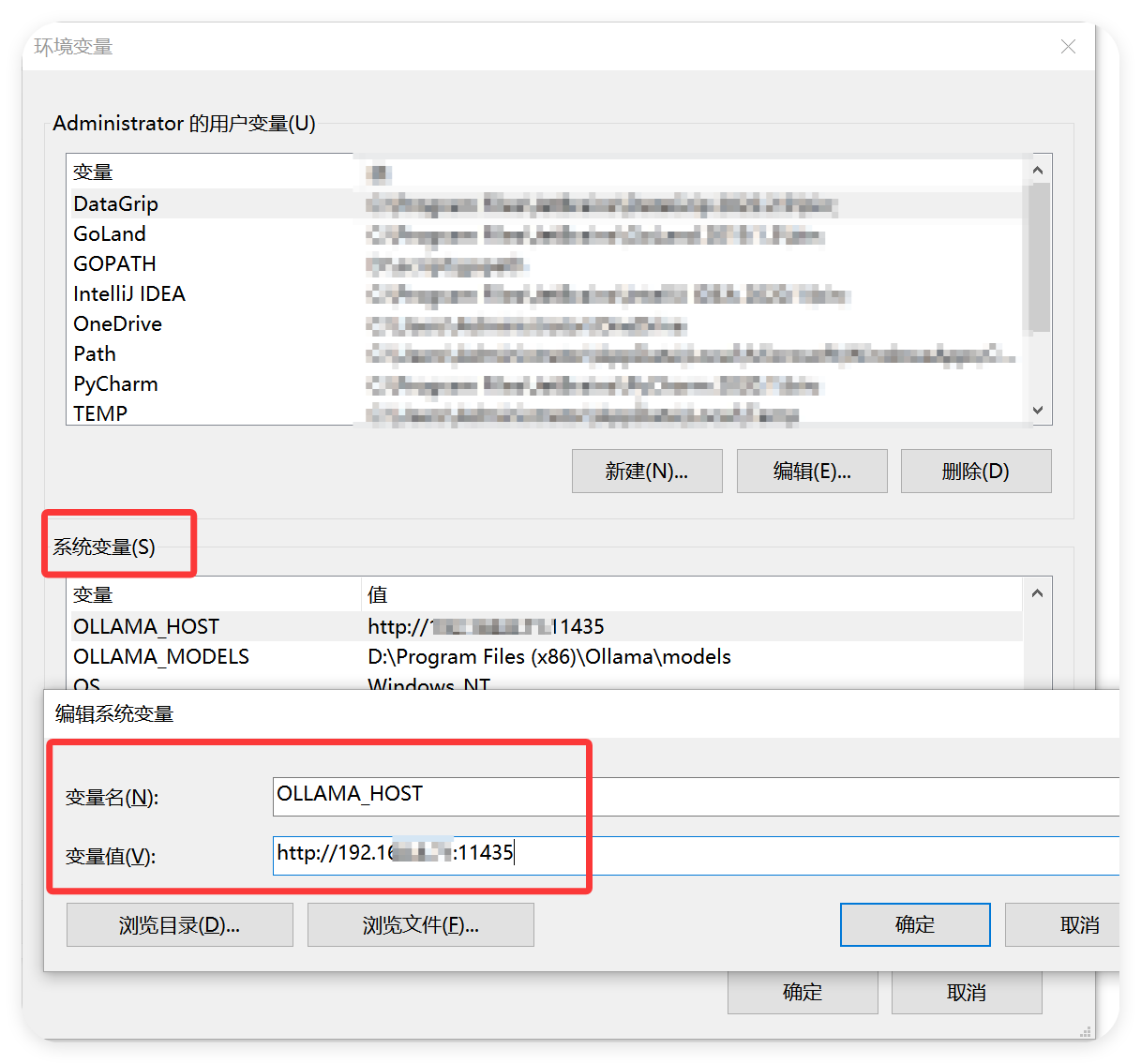
>>>tip:建议修改 ollama 的默认端口访问,确保安全,在系统环境变量中,增加OLLAMA_HOST=0.0.0.0:11435,0.0.0.0 建议替换成你的私有 ip,进一步确保安全。
(四)安装 Docker
- 下载安装包:前往 Docker 官网的下载页面(Pricing | Docker),根据系统版本选择对应的 Docker Desktop 安装包,对于 Windows 系统,一般选择 “Download for Windows - AMD64”(如果是 ARM64 架构的 Windows 系统,则选择相应的 ARM 版本) ,点击下载按钮开始下载。
- 安装 Docker Desktop:下载完成后,找到下载的安装包文件,双击运行它。在安装向导中,按照提示逐步进行安装。在安装过程中,会出现一些选项,如是否添加环境变量、是否启动 Docker 服务等,建议保持默认设置,直接点击 “Next”(下一步)和 “Install”(安装)按钮即可。安装程序会自动下载并安装 Docker 所需的组件和依赖项,这个过程可能需要一些时间,取决于网络速度和计算机性能。
- 启动服务:安装完成后,Docker 服务会自动启动。可以在系统托盘区找到 Docker 图标,右键点击它,选择 “Settings”(设置),进入 Docker 的设置界面。在设置界面中,可以对 Docker 的一些参数进行配置,如镜像存储位置、资源分配等。例如,为了避免占用系统盘空间,可以将镜像存储位置设置到其他磁盘分区。如果已经运行正常,不建议执行后面操作,此操作适合 wsl 运行异常情况:在 “Resources”(资源)选项卡中,选择 “Advanced”(高级),在 “Disk image location”(磁盘镜像位置)中指定新的存储路径,如 “D:DockerDockerDesktopWSL” (较为关键)。然后点击 “Apply & restart”(应用并重启)按钮,使设置生效。
- 可能遇到的问题及解决方法:在安装 Docker 过程中,可能会遇到一些问题。例如,系统提示虚拟化技术未开启,这是因为 Docker 依赖于虚拟化技术,如 Hyper - V。此时,需要进入 BIOS 设置界面,找到虚拟化相关的选项(通常在 “Advanced” 或 “Security” 选项卡中),将其设置为 “Enabled”(启用) 。不同主板的 BIOS 设置界面可能有所不同,可以参考主板的说明书或在网上搜索相关教程进行设置。另外,如果在安装过程中出现网络连接问题,导致无法下载所需组件,可以检查网络连接是否正常,尝试更换网络环境或使用代理服务器进行下载。
(五)部署 Dify
- 下载 Dify 项目代码:打开浏览器,访问 Dify 的 GitHub 项目页面(https://github.com/langgenius/dify) ,在页面中找到 “Code” 按钮,点击它,在弹出的菜单中选择 “Download ZIP”,将 Dify 项目的代码以压缩包的形式下载到本地。
- 解压到本地:找到下载的压缩包文件,将其解压到合适的位置,例如 “D:dify” 。解压完成后,进入解压后的文件夹,会看到 Dify 项目的源代码和相关文件。
- 进入项目根目录的 docker 文件夹:在解压后的 Dify 项目文件夹中,找到 “docker” 文件夹,进入该文件夹。这个文件夹中包含了用于部署 Dify 的 Docker 相关配置文件。
- 重命名.env.example 文件:在 “docker” 文件夹中,找到 “.env.example” 文件,复制出新文件名为 “.env” 。这个文件是 Dify 的环境配置文件,通过修改其中的参数,可以配置 Dify 的运行环境。
# 进入dify下的docker目录,执行如下操作
PS C:WINDOWSsystem32> cp .env.example .env- 启动 Dify 服务:打开命令行终端,确保当前目录为 “docker” 文件夹,然后在终端中运行命令 “docker compose up -d” 。这个命令会根据 “docker-compose.yml” 文件中的配置,下载所需的 Docker 镜像,并启动 Dify 服务。由于镜像文件较大,下载过程可能需要一些时间,并且下载源服务器在国外,网络状况可能会影响下载速度。如果下载速度过慢,可以考虑使用国内的镜像源,在 “docker-compose.yml” 文件中添加镜像源地址,例如:
version: '3'
services:
api:
image: langgenius/dify-api:0.15.3
# 添加镜像源地址
build:
context:.
dockerfile: Dockerfile
args:
- REGISTRY_MIRROR=https://registry.docker-cn.com修改完成后,重新运行 “docker compose up -d” 命令即可。在启动过程中,如果出现错误提示,需要仔细查看错误信息,根据具体情况进行解决。例如,如果提示某个端口被占用,可以修改 “docker-compose.yml” 文件中相应服务的端口配置,避免端口冲突。
或者,执行如下方式安装 docker-compose 和运行 dify:
PS C:WINDOWSsystem32> Start-BitsTransfer -Source "https://github.com/docker/compose/releases/download/v2.32.4/docker-compose-windows-x86_64.exe" -Destination $Env:ProgramFilesDockerdocker-compose.exe
PS C:WINDOWSsystem32> docker-compose --version
Docker Compose version v2.31.0-desktop.2
PS C:WINDOWSsystem32> docker compose up -d(六)将 DeepSeek 接入 Dify
- 配置.env 文件:使用文本编辑器打开 “docker” 文件夹中的 “.env” 文件,在文件末尾添加以下配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定Ollama的API地址(根据部署环境调整IP)
OLLAMA_API_BASE_URL=your ip:11435添加完成后,保存文件。这里的 “OLLAMA_API_BASE_URL” 配置项指定了 Ollama 的 API 地址,Dify 通过这个地址与 Ollama 进行通信,从而调用 DeepSeek 模型。
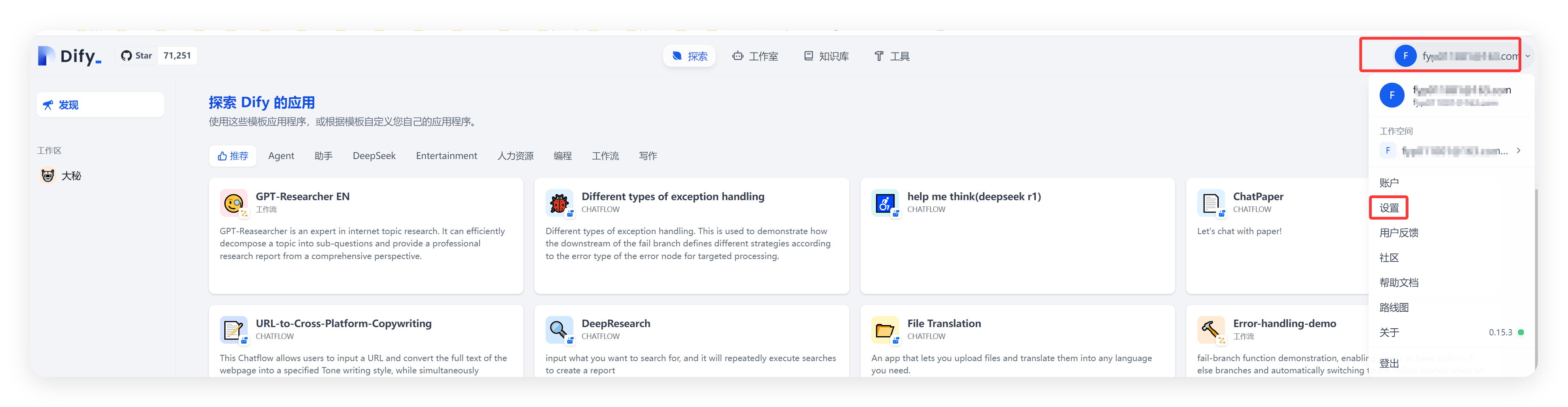
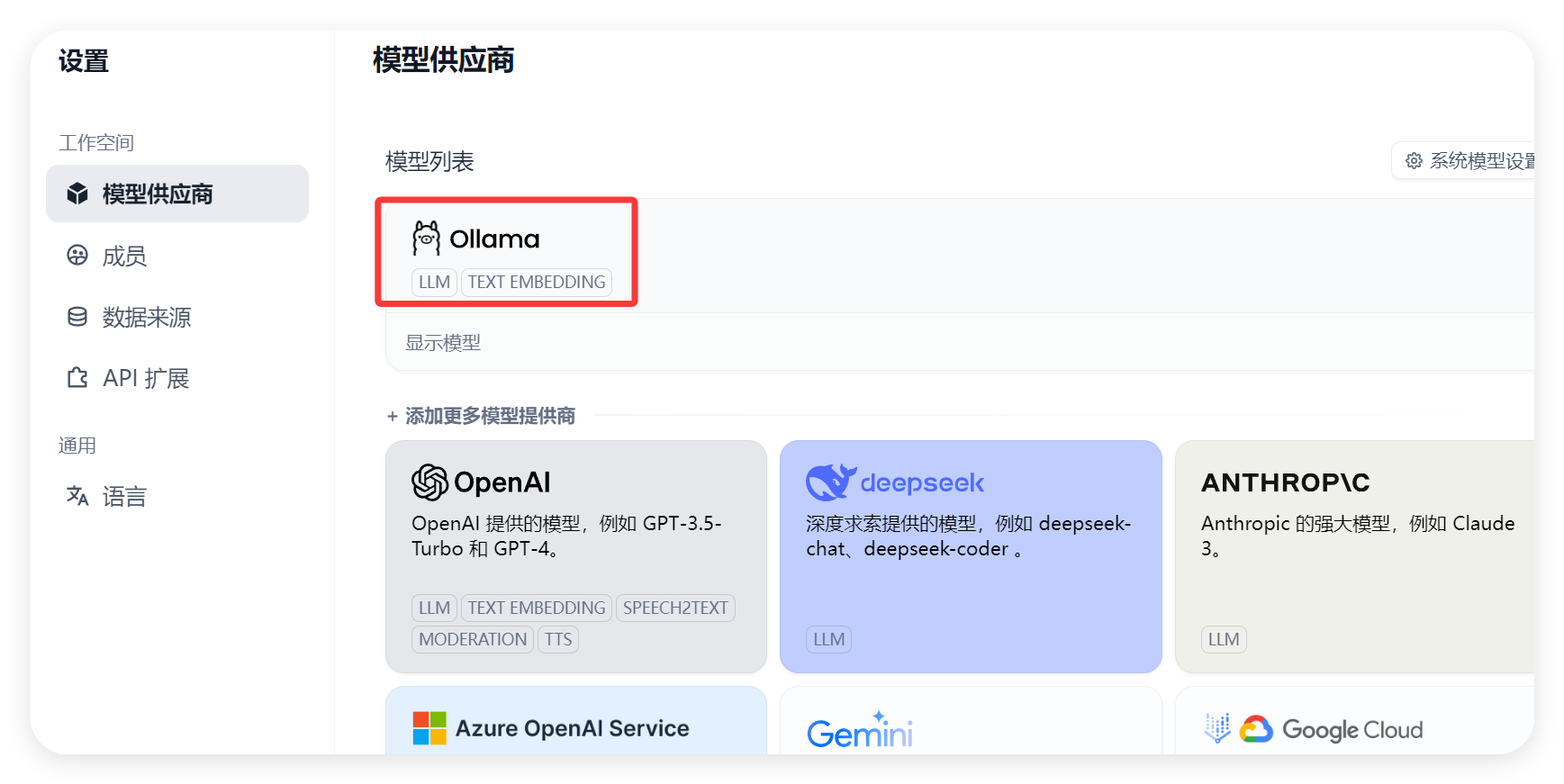
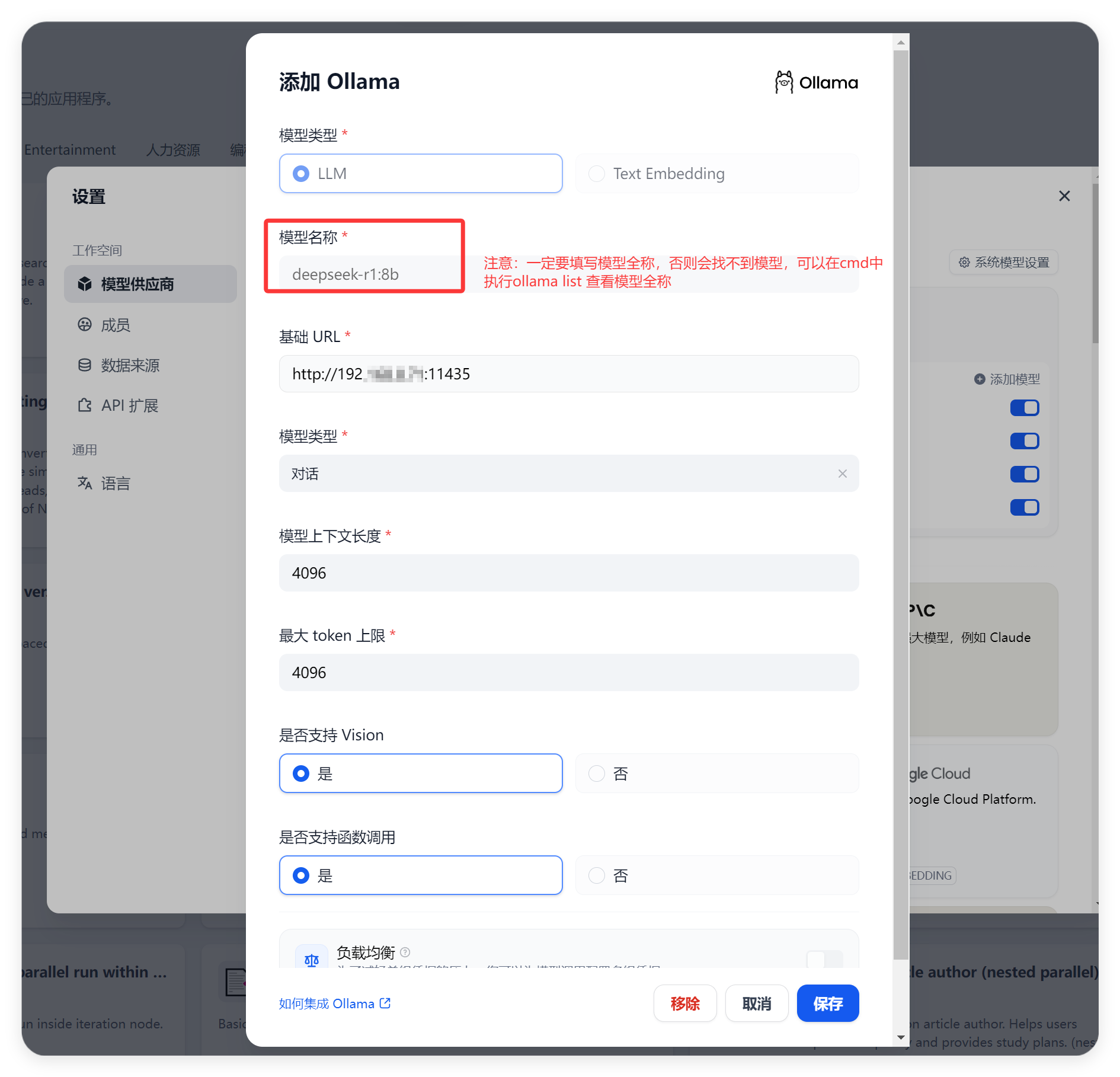
2. 登录 Dify 平台并配置模型:打开浏览器,访问 Dify 的本地地址,通常是 “http://127.0.0.1:80”(如果在 “docker-compose.yml” 文件中修改了端口配置,需要使用修改后的端口) ,进入 Dify 的登录页面。输入之前设置的管理员账号和密码,登录 Dify 平台。登录成功后,在 Dify 的界面中找到 “设置” 选项,进入设置页面,选择 “模型供应商”。在模型供应商列表中,找到 “Ollama”,点击 “添加模型”。在弹出的添加模型对话框中,填写模型名称(例如 “deepseek-r1:8b”,与之前在 Ollama 中运行的模型名称一致)、基础 URL(http://your ip:11435)、模型类型等信息,其他选项保持默认设置,然后点击 “保存” 按钮。这样,就成功将 DeepSeek 模型接入到了 Dify 平台中,后续就可以在 Dify 中使用 DeepSeek 模型进行知识库的训练和调用了,操作方法如下:
四、Linux 环境部署
(一)安装前准备
在 Linux 系统下进行部署,需要确保系统满足一定的硬件和软件要求。对于 CPU,建议使用具有多核的高性能处理器,如英特尔至强系列或 AMD 霄龙系列,以提供足够的计算能力来运行模型和相关服务。内存方面,至少需要 16GB,若要运行参数规模较大的 DeepSeek 模型,如 32b 版本,则最好拥有 32GB 及以上的内存,以避免在运行过程中出现内存不足的情况。硬盘空间也需要预留足够,至少 50GB 用于安装各种软件和存储模型文件,如果要存储多个不同版本的 DeepSeek 模型,建议预留 100GB 以上的空间。同时,确保系统的内核版本符合要求,例如对于 Ubuntu 系统,建议使用 20.04 及以上版本,对于 CentOS 系统,建议使用 7.9 及以上版本。
在软件安装方面,首先需要安装 Docker,它是用于容器化部署 Dify 的工具。可以通过官方提供的安装脚本来进行安装,在终端中运行以下命令:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh安装完成后,需要将当前用户添加到 docker 组,以便无需使用 sudo 即可运行 docker 命令,运行以下命令:
sudo usermod -aG docker $USER然后重新登录系统,使更改生效。
接下来安装 Ollama,它是用于本地运行 DeepSeek 模型的工具。在终端中运行以下命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,可以通过运行 “ollama --version” 命令来验证是否安装成功。
还需要安装 Git,用于下载 Dify 项目代码。在 Ubuntu 系统中,可以使用以下命令进行安装:
sudo apt update
sudo apt install git在 CentOS 系统中,可以使用以下命令进行安装:
sudo yum install git(二)安装 Ollama
- 使用 curl 命令安装:在 Linux 系统(如 Ubuntu/Debian)下,打开终端,输入以下命令进行 Ollama 的安装:
curl -fsSL https://ollama.com/install.sh | sh这个命令会从 Ollama 官方网站下载安装脚本,并自动执行安装过程。在安装过程中,脚本会自动检测系统环境,下载并安装 Ollama 的相关组件和依赖项。
2. 添加用户权限:安装完成后,为了确保当前用户能够正常使用 Ollama,需要将用户添加到 Ollama 的运行组中。运行以下命令:
usermod -aG ollama $USER这将把当前用户添加到 ollama 组中,使得用户可以在不使用 sudo 权限的情况下运行 Ollama 命令。添加完成后,需要重新登录系统,使权限更改生效。
3. 启动服务:在终端中输入 “ollama serve” 命令,启动 Ollama 服务。启动过程中,Ollama 会自动创建一个公钥和私钥,并监听本地的 11434 端口,等待接收模型运行和交互的请求,同样建议修改默认端口,在环境变量中添加OLLAMA_HOST=0.0.0.0:11435。
4. 验证安装:在终端中输入 “ollama --version” 命令,如果安装成功,会显示 Ollama 的版本信息,例如 “ollama version 0.5.11” ,这表明 Ollama 已经正确安装在系统中,可以正常使用。也可以通过访问 “http://localhost:11435” ,如果看到提示 “Ollama is running”,同样说明安装成功。
(三)下载并运行 DeepSeek 模型
- 参考上面 windows 中 deepseek 安装方法,命令都是一样的。
(四)安装 Docker
- 使用 curl 命令安装:在 Linux 系统中,打开终端,运行以下命令来安装最新版的 Docker 和 docker-compose:
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
apt-get install docker-compose这个命令会从 Docker 官方网站下载安装脚本,并自动执行安装过程。安装脚本会自动检测系统环境,下载并安装 Docker 的相关组件和依赖项。
2. 将当前用户加入 docker 组:安装完成后,为了让当前用户能够直接运行 Docker 命令,而无需每次都使用 sudo 权限,需要将用户添加到 docker 组中。运行以下命令:
usermod -aG docker $USER这将把当前用户添加到 docker 组中,使得用户可以在不使用 sudo 权限的情况下运行 Docker 命令。添加完成后,需要重新登录系统,使权限更改生效。
3. 可能遇到的问题及解决方法:在安装 Docker 过程中,可能会遇到一些问题。例如,在某些系统中,可能会提示缺少一些依赖包。此时,需要根据提示信息,使用系统的包管理工具(如 apt-get 或 yum)来安装缺少的依赖包。另外,如果在安装过程中出现网络连接问题,导致无法下载所需组件,可以检查网络连接是否正常,尝试更换网络环境或使用代理服务器进行下载。在安装完成后,如果运行 Docker 命令时出现权限问题,如提示 “permission denied”,可以检查用户是否已经成功添加到 docker 组中,或者尝试重新登录系统。
(五)部署 Dify
- 克隆 Dify 源代码到本地:打开终端,运行以下命令将 Dify 的源代码克隆到本地指定目录,例如 “/home/user/dify” :
git clone https://github.com/langgenius/dify.git /data这个命令会从 Dify 的 GitHub 仓库下载最新的源代码到指定目录。克隆过程的速度取决于网络状况,可能需要一些时间,请耐心等待。
2. 进入 Docker 目录:克隆完成后,进入 Dify 项目的 docker 目录,运行以下命令:
cd /data/dify/docker这个目录中包含了用于部署 Dify 的 Docker 相关配置文件。
3. 复制环境配置文件:在 docker 目录中,找到 “.env.example” 文件,将其复制并重命名为 “.env” ,运行以下命令:
cp.env.example .env这个文件是 Dify 的环境配置文件,通过修改其中的参数,可以配置 Dify 的运行环境。
4. 启动 Dify 服务:在终端中运行 “docker compose up -d” 命令,启动 Dify 服务。这个命令会根据 “docker-compose.yml” 文件中的配置,下载所需的 Docker 镜像,并启动 Dify 服务。由于镜像文件较大,下载过程可能需要一些时间,并且下载源服务器在国外,网络状况可能会影响下载速度。如果下载速度过慢,可以考虑使用国内的镜像源,在 “docker-compose.yml” 文件中添加镜像源地址,例如:
version: '3'
services:
api:
image: langgenius/dify-api:0.15.3
# 添加镜像源地址
build:
context:.
dockerfile: Dockerfile
args:
- REGISTRY_MIRROR=https://registry.docker-cn.com修改完成后,重新运行 “docker compose up -d” 命令即可。在启动过程中,如果出现错误提示,需要仔细查看错误信息,根据具体情况进行解决。例如,如果提示某个端口被占用,可以修改 “docker-compose.yml” 文件中相应服务的端口配置,避免端口冲突。
(六)将 DeepSeek 接入 Dify
- 配置.env 文件:使用文本编辑器打开 “docker” 文件夹中的 “.env” 文件,在文件末尾添加以下配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定Ollama的API地址(根据部署环境调整IP)
OLLAMA_API_BASE_URL=localhost:11435添加完成后,保存文件。这里的 “OLLAMA_API_BASE_URL” 配置项指定了 Ollama 的 API 地址,Dify 通过这个地址与 Ollama 进行通信,从而调用 DeepSeek 模型。
2. 登录 Dify 平台并配置模型:打开浏览器,访问 Dify 的本地地址,通常是 “http://your ip:80”(如果在 “docker-compose.yml” 文件中修改了端口配置,需要使用修改后的端口) ,进入 Dify 的登录页面。输入之前设置的管理员账号和密码,登录 Dify 平台。登录成功后,在 Dify 的界面中找到 “设置” 选项,进入设置页面,选择 “模型供应商”。在模型供应商列表中,找到 “Ollama”,点击 “添加模型”。在弹出的添加模型对话框中,填写模型名称(例如 “deepseek-r1:8b”,与之前在 Ollama 中运行的模型名称一致)、基础 URL(http://your ip:11435)、模型类型等信息,其他选项保持默认设置,然后点击 “保存” 按钮。这样,就成功将 DeepSeek 模型接入到了 Dify 平台中,后续就可以在 Dify 中使用 DeepSeek 模型进行知识库的训练和调用了。
启动 docker 时如果遇到如下报错:
ERROR: Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
可修改 docker 镜像源
vim /etc/docker/daemon.json
添加如下内容
{
"registry-mirrors": [
"https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://your_preferred_mirror",
"https://dockerhub.icu",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}
# 重启docker环境
systemctl daemon-reload
systemctl restart docker五、知识库训练
(一)添加 Embedding 模型
Embedding 模型在知识库训练中扮演着极为关键的角色。在自然语言处理领域,文本数据本质上是离散的、非结构化的信息,计算机难以直接对其进行处理和理解。而 Embedding 模型的作用就是将这些文本数据转换为数值向量,也就是将文本嵌入到一个低维的向量空间中。通过这种转换,语义相似的文本在向量空间中的距离会比较接近,这样计算机就能够通过计算向量之间的相似度来衡量文本之间的语义关系。
在实际应用中,比如在知识库的检索场景下,当用户输入一个问题时,Embedding 模型会将问题和知识库中的文本都转换为向量,然后通过计算向量之间的相似度,就可以快速找到与问题语义最相关的文本段落,从而为后续的回答提供准确的信息支持。这大大提高了知识库检索的效率和准确性,使得我们能够从海量的文本数据中快速获取有价值的信息。(后期详细讲 embedding 原理和模型应用)
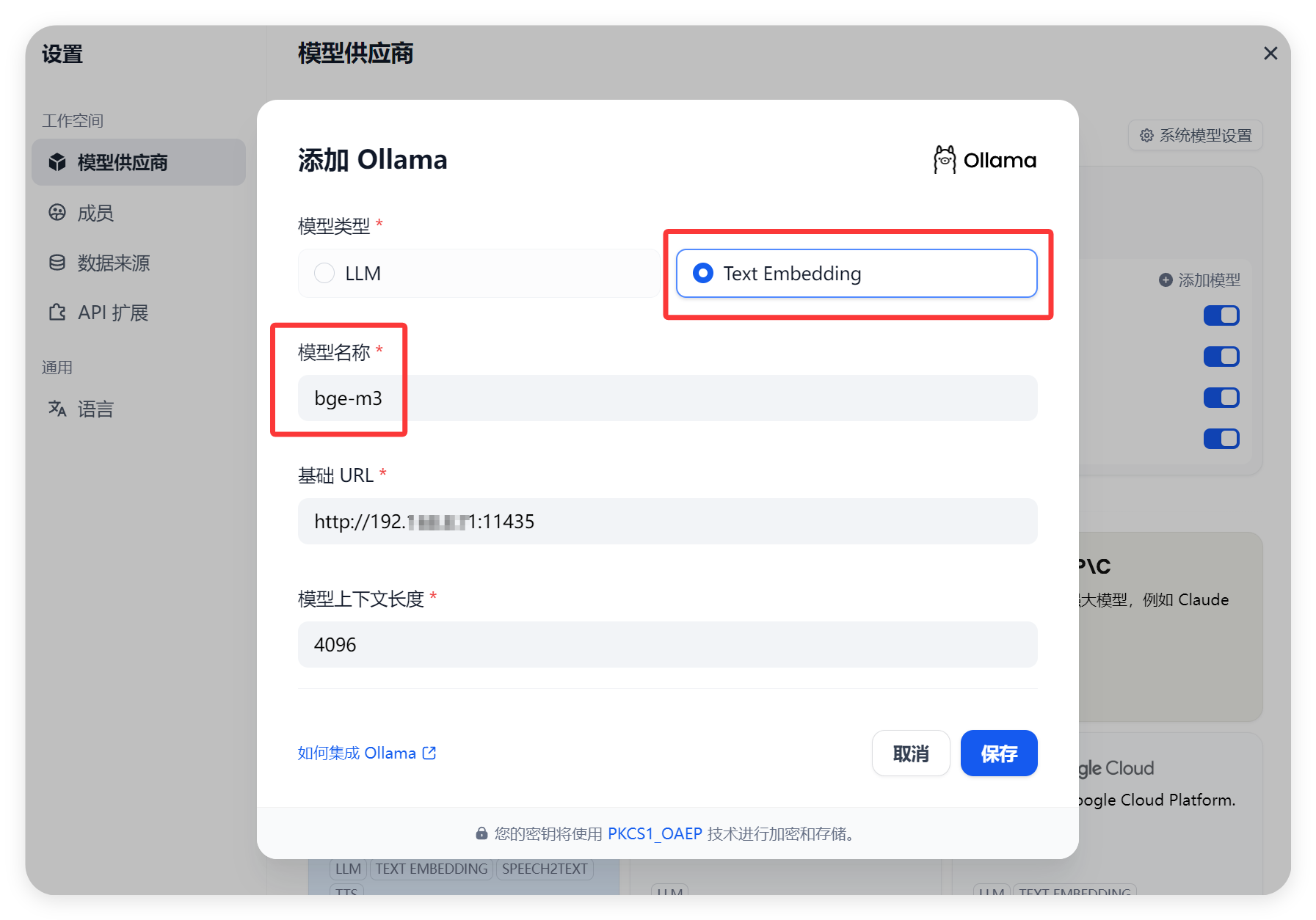
在 Ollama 中添加 Embedding 模型,以添加 bge - m3 模型为例,操作步骤如下:打开命令行终端,在 Windows 系统下,通过开始菜单搜索 “命令提示符” 并打开;在 Linux 系统下,直接打开终端应用。在终端中输入以下命令来下载 bge - m3 模型:ollama pull bge-m3 。Ollama 会自动从指定的仓库中下载 bge - m3 模型文件到本地,并将其添加到模型列表中。下载完成后,可以通过输入 “ollama list” 命令来查看已下载的模型列表,确认 bge - m3 模型是否已成功添加。如果在下载过程中遇到网络问题,导致下载速度过慢或失败,可以检查网络连接是否正常,尝试更换网络环境,或者使用代理服务器进行下载。同时,确保 Ollama 的版本是最新的,以避免因版本问题导致的兼容性问题。
C:UsersAdministrator>ollama pull bge-m3
pulling manifest
pulling daec91ffb5dd... 100% ▕████████████████▏ 1.2 GB
pulling a406579cd136... 100% ▕████████████████▏ 1.1 KB
pulling 0c4c9c2a325f... 100% ▕████████████████▏ 337 B
verifying sha256 digest
writing manifest
success
C:UsersAdministrator>ollama list
NAME ID SIZE MODIFIED
bge-m3:latest 790764642607 1.2 GB 4 seconds ago
mxbai-embed-large:latest 468836162de7 669 MB 3 days ago
deepseek-r1:8b 28f8fd6cdc67 4.9 GB 4 days ago
qwen2.5:latest 845dbda0ea48 4.7 GB 4 days ago
llama3.2:3b a80c4f17acd5 2.0 GB 5 days ago
nomic-embed-text:latest 0a109f422b47 274 MB 5 days agodify 上添加 text embedding 模型:
(二)创建本地知识库
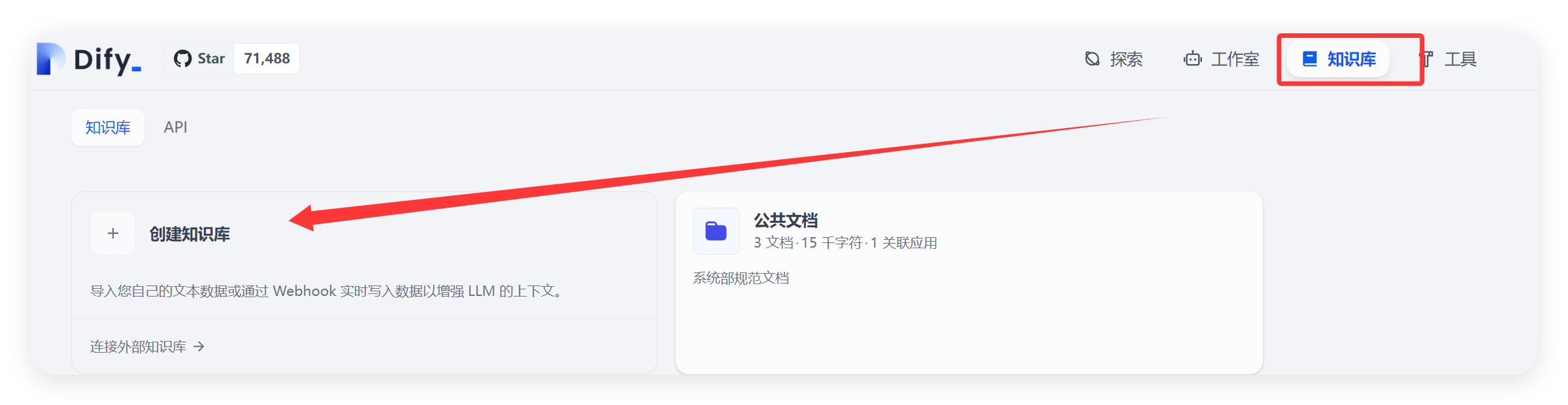
在 Dify 平台中创建本地知识库,具体操作步骤如下:登录 Dify 平台后,在平台的主界面中找到并点击 “知识库” 选项卡,进入知识库管理页面。在知识库管理页面中,点击 “创建知识库” 按钮,会弹出创建知识库的对话框,知识库内容后期将单独出内容讲解实现原理和注意事项,此处只讲基本使用方法。
创建知识库有两种方式,第一种是先创建一个空的知识库,然后再上传文件。在对话框中输入知识库的名称,名称应简洁明了且能够准确反映知识库的内容,例如 “公司产品知识库”“技术文档知识库” 等,名称长度一般限制在 1 到 40 个字符之间。还可以根据需要输入知识库的描述信息,对知识库的内容、用途等进行简要说明,方便后续管理和使用。输入完成后,点击 “创建” 按钮,即可创建一个空的知识库。
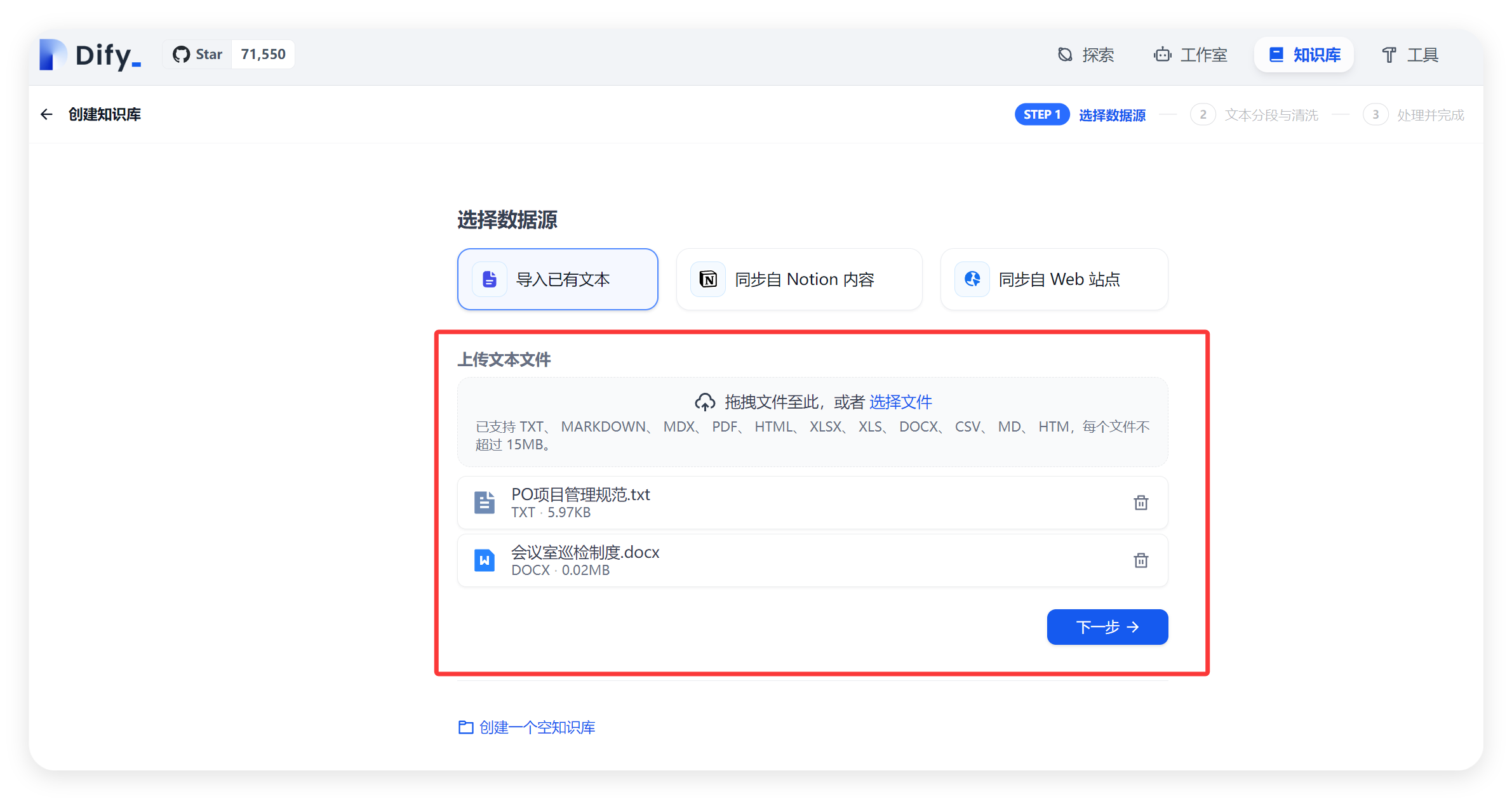
第二种方式是直接上传文件来创建默认知识库。在创建知识库的对话框中,点击 “上传文件” 按钮,选择本地已经准备好的文本文件,Dify 支持多种文件格式,如 TXT、PDF、HTML、XLSX、XLS、DOCX、CSV 等 。选择好文件后,系统会自动根据文件内容创建一个默认知识库,并以文件名为知识库名称,同时可以对知识库名称和描述进行修改。
在创建知识库时,还需要设置一些关键参数。在 “索引技术” 选项中,选择合适的索引方式,常见的索引方式有语义搜索(semantic_search)等,不同的索引方式会影响知识库的检索效率和准确性。对于文本较长的文档,可以选择 “父子分段” 方式,并设置合适的子分段长度,例如 1000 个字符左右,这样可以将长文档分割成多个小段,提高检索的精度。同时,还可以选择是否启用重排序(reranking_enable)功能,如果启用,需要选择相应的重排序模型(reranking_model)。在 “嵌入模型” 选项中,选择之前在 Ollama 中下载的 Embedding 模型,如 bge-m3,以确保文本能够正确地转换为向量进行存储和检索。
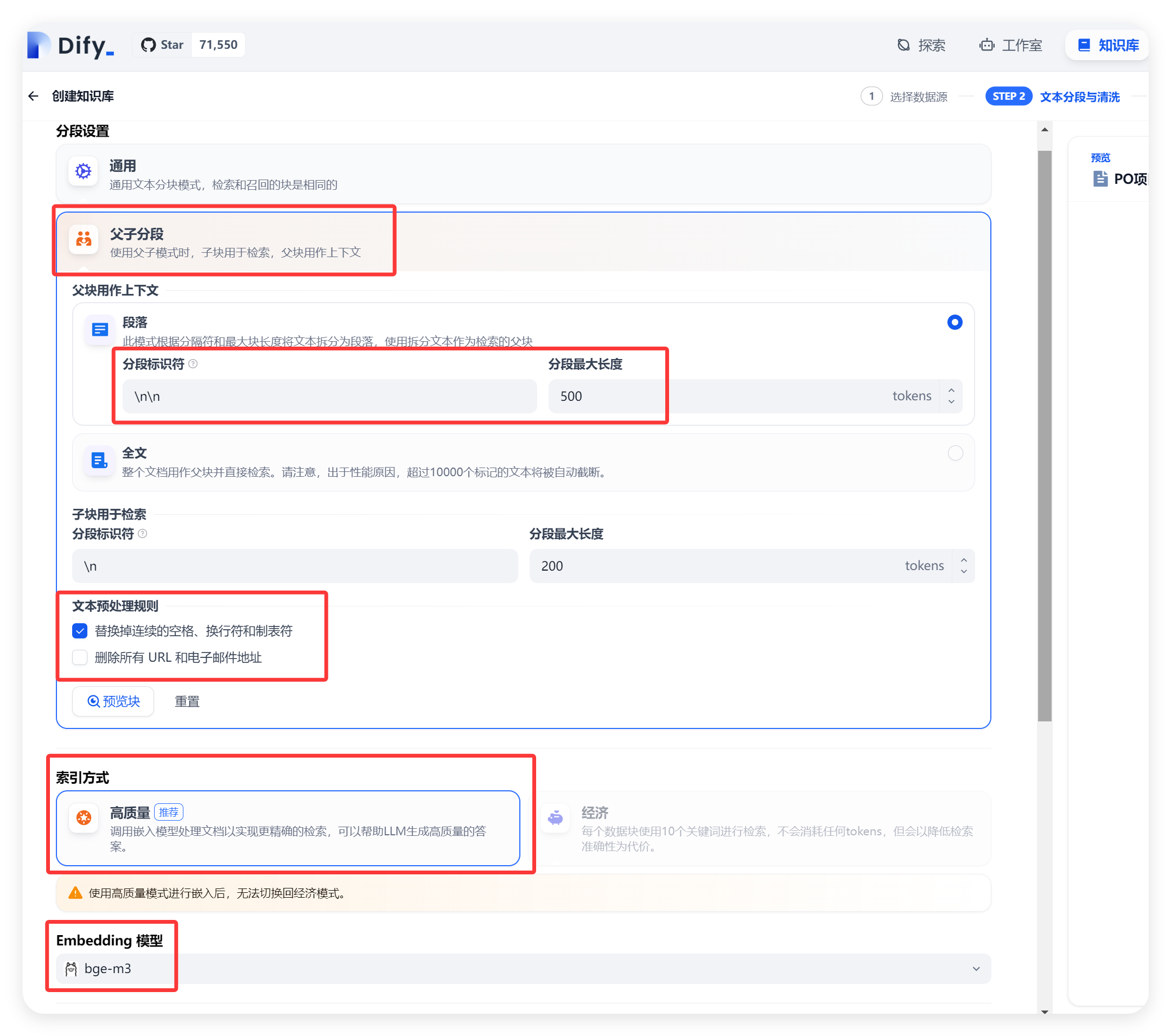
在创建过程中,可能会遇到一些问题。如果上传的文件格式不支持,系统会提示错误信息,此时需要将文件转换为支持的格式后再进行上传。如果创建的知识库名称已存在,会提示 “数据集名称重复” 错误,需要重新输入一个唯一的名称。另外,如果在设置参数时选择了不支持的选项,也会导致创建失败,需要仔细检查参数设置,确保其符合要求。

六、接口调用实现
(一)Dify 平台配置
在 Dify 平台中,我们可以通过创建应用来实现与本地知识库的交互和接口调用。以创建一个聊天助手应用为例,详细步骤如下:
- 创建应用:登录 Dify 平台后,在主界面中找到 “工作室” 选项,点击进入工作室页面。在工作室页面中,点击 “创建空白应用” 按钮,会弹出创建应用的对话框。在对话框中,首先选择应用类型为 “聊天助手”,这是因为我们要创建的是一个用于对话交互的应用,能够根据用户的提问从本地知识库中获取答案并回复。然后输入应用名称,例如 “我的知识库聊天助手”,名称要简洁明了,能够准确反映应用的功能。还可以根据需要输入应用描述,对应用的功能、用途等进行简要说明,方便后续管理和使用。完成后,点击 “创建” 按钮,即可创建一个聊天助手应用。

- 配置大模型:参考上面讲述的将 DeepSeek 接入 dify 的章节。
- 设置上下文关联本地知识库:接着,在左侧菜单栏中点击 “编排” 选项,进入编排页面。在编排页面中,找到 “上下文” 部分,点击 “添加知识库” 按钮,在弹出的知识库列表中,选择之前创建好的本地知识库,例如 “公司产品知识库”。通过这样的设置,聊天助手在回答用户问题时,就会结合本地知识库中的内容进行回答,提高回答的准确性和针对性。

(二)接口调用测试
- 在应用页调试聊天助手,在 Dify 平台中测试接口调用,操作方法如下:在聊天助手应用的页面中,会有一个对话框,用户可以在对话框中输入问题,例如 “规范有哪些?”,然后点击发送按钮。此时,Dify 会将用户的问题发送给 DeepSeek 模型,模型会根据本地知识库中的内容进行分析和处理,生成回答并返回。在回答区域,用户可以看到模型返回的回答,并且如果设置了相关参数,还可以看到回答中引用的知识库文档来源,以方便用户进行验证和进一步查询。
- 生成 API 密钥,登录 Dify 平台,进入你的应用管理界面,在界面中找到 API 相关设置区域,通常可以在应用的设置或者开发者选项中找到,生成并获取你的 API 密钥,这个密钥是调用应用接口的重要凭证,请妥善保管,不要泄露。

创建 api 密钥:

最新技术分享会在公众号:朗清水 第一时间发布。
其他在部署过程中遇到问题,都可以留言或私信我帮你解决。
以上内容,在于告知基于 dify 做一套知识库训练的基本流程,后续会专门针对企业化知识库内容做拆分讲解。








