服务器本地微调Ministral-8B模型进行NLI任务
主要流程
1. 前期准备
硬件方面需要一个较高配置的GPU,我这里使用的是A100,80G显存
(由于服务器连不上huggingface,我将模型下载好并上传到服务器进行本地训练)
模型下载
模型地址:https://huggingface.co/mistralai/Ministral-8B-Instruct-2410
下载模型之前需要先申请一下权限,通过之后,在Files and versions中下载模型相关文件,我直接下载了所有的文件。
下载好模型之后,可以通过scp指令上传到服务器中,比如我上传到服务器上的位置为:/home/user_m/models/Ministral-8B-Instruct-2410
数据集下载
与模型一样,由于无法连接到huggingface,我选择将数据集下载并上传到服务器中,我这里使用的数据集为 e-SNLI: https://huggingface.co/datasets/esnli/esnli
同样,将Files and versions中的文件下载并通过scp指令上传到服务器,我的数据集在服务器中的位置为:/home/user_m/DataSet/esnil
下面是数据集中一条数据的示例:
{
"explanation_1": "A woman must be present to smile.",
"explanation_2": "A woman smiling implies that she is present.",
"explanation_3": "A smiling woman is also present.",
"hypothesis": "A woman is present.",
"label": 0,
"premise": "A woman smiles at the child."
}数据集内容:
- 前提(premise):一个给定的句子,作为推理的基础。
- 假设(hypothesis):需要根据前提进行推断的句子。
- 关系标签(label):
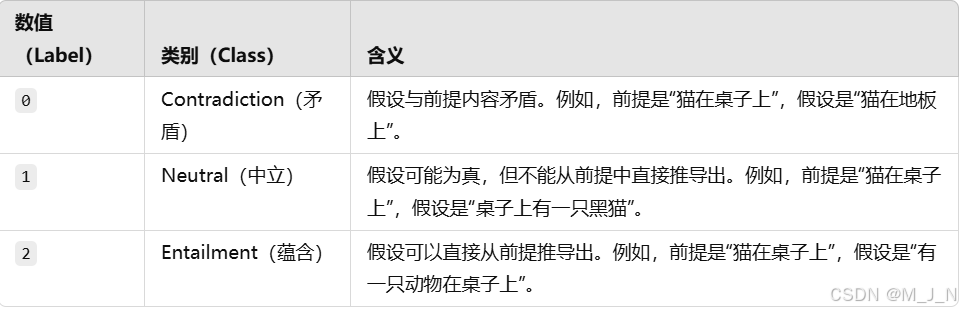
- 解释(explanation):
- 对上述推理过程的自然语言解释,帮助模型理解推理的原因。
- 解释的形式为人工标注,保证质量和清晰度
2. 使用peft进行微调
peft地址:https://huggingface.co/docs/peft/index
微调代码如下:
from copy import deepcopy
from argparse import ArgumentParser
from datasets import load_from_disk,load_dataset
import evaluate
import numpy as np
from peft import get_peft_model, LoraConfig, TaskType
from transformers import AutoTokenizer, DataCollatorWithPadding
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer, TrainerCallback
import torch
POS_WEIGHT, NEG_WEIGHT, NATURAL_WEIGHT = (1.1637114032405993, 0.8766697374481806, 1.0)
def get_args():
parser = ArgumentParser(description="Fine-tune an LLM model with PEFT")
parser.add_argument(
"--data_path",
type=str,
default='/home/user_m/DataSet/esnil/esnli.py',
required=True,
help="Path to Huggingface pre-processed dataset",
)
parser.add_argument(
"--output_path",
type=str,
default='/home/user_m/output',
required=True,
help="Path to store the fine-tuned model",
)
parser.add_argument(
"--model_name",
type=str,
default='/home/user_m/models/Ministral-8B-Instruct-2410',
required=True,
help="Name of the pre-trained LLM to fine-tune",
)
parser.add_argument(
"--max_length",
type=int,
default=128,
required=False,
help="Maximum length of the input sequences",
)
parser.add_argument(
"--set_pad_id",
action="store_true",
help="Set the id for the padding token, needed by models such as Mistral-7B",
)
parser.add_argument(
"--lr", type=float, default=2e-4, help="Learning rate for training"
)
parser.add_argument(
"--train_batch_size", type=int, default=64, help="Train batch size"
)
parser.add_argument(
"--eval_batch_size", type=int, default=64, help="Eval batch size"
)
parser.add_argument(
"--num_epochs", type=int, default=2, help="Number of epochs"
)
parser.add_argument(
"--weight_decay", type=float, default=0.1, help="Weight decay"
)
parser.add_argument(
"--lora_rank", type=int, default=4, help="Lora rank"
)
parser.add_argument(
"--lora_alpha", type=float, default=0.0, help="Lora alpha"
)
parser.add_argument(
"--lora_dropout", type=float, default=0.2, help="Lora dropout"
)
parser.add_argument(
"--lora_bias",
type=str,
default='none',
choices={"lora_only", "none", 'all'},
help="Layers to add learnable bias"
)
arguments = parser.parse_args()
return arguments
def compute_metrics(eval_pred):
precision_metric = evaluate.load("/home/user_m/evaluate/metrics/precision")
recall_metric = evaluate.load("/home/user_m/evaluate/metrics/recall")
f1_metric = evaluate.load("/home/user_m/evaluate/metrics/f1")
accuracy_metric = evaluate.load("/home/user_m/evaluate/metrics/accuracy")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
precision = precision_metric.compute(predictions=predictions, references=labels,average='macro')["precision"]
recall = recall_metric.compute(predictions=predictions, references=labels,average='macro')["recall"]
f1 = f1_metric.compute(predictions=predictions, references=labels,average='macro')["f1"]
accuracy = accuracy_metric.compute(predictions=predictions, references=labels)["accuracy"]
return {"precision": precision, "recall": recall, "f1-score": f1, 'accuracy': accuracy}
class CustomCallback(TrainerCallback):
def __init__(self, trainer) -> None:
super().__init__()
self._trainer = trainer
def on_epoch_end(self, args, state, control, **kwargs):
if control.should_evaluate:
control_copy = deepcopy(control)
self._trainer.evaluate(eval_dataset=self._trainer.train_dataset, metric_key_prefix="train")
return control_copy
def get_dataset_and_collator(
data_path,
model_checkpoints,
# add_prefix_space=True,
max_length=128,
truncation=True,
set_pad_id=False
):
"""
Load the preprocessed HF dataset with train, valid and test objects
Paramters:
---------
data_path: str
Path to the pre-processed HuggingFace dataset
model_checkpoints:
Name of the pre-trained model to use for tokenization
"""
data = load_dataset(data_path)
tokenizer = AutoTokenizer.from_pretrained(
model_checkpoints,
# add_prefix_space=add_prefix_space
)
print("Tokenizer loaded successfully")
tokenizer.pad_token = tokenizer.eos_token
def _preprocesscing_function(examples):
return tokenizer(examples["premise"],examples["hypothesis"], truncation=True, padding="max_length", max_length=max_length)
col_to_delete = ['explanation_1', 'explanation_2','explanation_3', 'premise','hypothesis']
tokenized_datasets = data.map(_preprocesscing_function, batched=False)
tokenized_datasets = tokenized_datasets.remove_columns(col_to_delete)
tokenized_datasets.set_format("torch")
padding_collator = DataCollatorWithPadding(tokenizer=tokenizer)
return tokenized_datasets, padding_collator
def get_lora_model(model_checkpoints, num_labels=3, rank=4, alpha=16, lora_dropout=0.1, bias='none'):
"""
TODO
"""
model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=model_checkpoints,
num_labels=num_labels,
device_map="auto",
offload_folder="offload",
trust_remote_code=True,
)
model.config.pad_token_id = model.config.eos_token_id
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=rank, lora_alpha=alpha, lora_dropout=lora_dropout, bias=bias,
target_modules=[
"q_proj",
"v_proj",
# "score"
],
)
model = get_peft_model(model, peft_config)
print(model.print_trainable_parameters())
return model
def get_weighted_trainer(pos_weight, neg_weight,neutral_weight=1.0):
class _WeightedBCELossTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False,num_items_in_batch=None):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = torch.nn.CrossEntropyLoss(weight=torch.tensor([neg_weight, pos_weight, neutral_weight], device=labels.device, dtype=logits.dtype))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
return _WeightedBCELossTrainer
def main(args):
"""
Training function
"""
dataset, collator = get_dataset_and_collator(
args.data_path,
args.model_name,
max_length=args.max_length,
set_pad_id=args.set_pad_id,
# add_prefix_space=True,
truncation=True,
)
training_args = TrainingArguments(
output_dir=args.output_path,
learning_rate=args.lr,
lr_scheduler_type= "cosine",
warmup_ratio= 0.1,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
num_train_epochs=args.num_epochs,
weight_decay=args.weight_decay,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
gradient_checkpointing=True,
fp16=True,
max_grad_norm= 0.3,
)
model = get_lora_model(
args.model_name,
rank=args.lora_rank,
alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
bias=args.lora_bias
)
if args.set_pad_id:
model.config.pad_token_id = model.config.eos_token_id
# move model to GPU device
if model.device.type != 'cuda':
model=model.to('cuda')
weighted_trainer = get_weighted_trainer(POS_WEIGHT, NEG_WEIGHT,NATURAL_WEIGHT)
trainer = weighted_trainer(
model=model,
args=training_args,
train_dataset=dataset['train'],
eval_dataset=dataset["validation"],
data_collator=collator,
compute_metrics=compute_metrics
)
trainer.add_callback(CustomCallback(trainer))
trainer.train()
if __name__ == "__main__":
args = get_args()
main(args)3.整个过程中遇到的问题
3.1 raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
ValueError: Cannot handle batch sizes > 1 if no padding token is defined.

原因:
在加载tokenizer时,使用了padding
tokenizer.pad_token = tokenizer.eos_token
tokenizer(examples["premise"],examples["hypothesis"], truncation=True, padding="max_length", max_length=max_length)虽然指定了tokenizer的pad_token,但是这个模型本身并没有默认的pad_token_id,导致模型认不出这个pad_token所以出现了报错.
解决办法:
在加载完模型之后,指定pad_token_id:
model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=model_checkpoints,
num_labels=num_labels,
device_map="auto",
offload_folder="offload",
trust_remote_code=True,
)
model.config.pad_token_id = model.config.eos_token_id这样模型就知道使用了eos_token作为pad_token
3.2 训练后评估accuracy很低
评估微调之后模型推理的accuracy时,发现正确率只有0.3多一点,对于三分类问题来说,这个准确率和瞎猜没有什么区别。。。我分析了我最开始进行训练的代码,发现了如下问题:
最初我进行训练的代码如下:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
from peft import get_peft_model, LoraConfig
from transformers import Trainer, TrainingArguments
import os
model_path = "/home/user_m/models/Ministral-8B-Instruct-2410"
tokenizer = AutoTokenizer.from_pretrained(model_path)
print(tokenizer.pad_token_id)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
# 加载 ESNLI 数据集
dataset = load_dataset("/home/user_m/DataSet/esnil/esnli.py",trust_remote_code=True)
def preprocess_function(examples):
# print(examples["label"]) # 打印标签查看
return tokenizer(examples["premise"], examples["hypothesis"], padding='max_length' ,max_length = 128, truncation=True)
# return tokenizer(examples["premise"], examples["hypothesis"])
encoded_dataset = dataset.map(preprocess_function, batched=True)
print(encoded_dataset)
# 使用Peft微调模型
# 设置 LoRA 配置
model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=3) # ESNLI 是三分类问题
model.config.pad_token_id = model.config.eos_token_id
lora_config = LoraConfig(
r=8, # LoRA的低秩大小
lora_alpha=16, # 标量
lora_dropout=0.1,
target_modules=["q_proj", "k_proj", "v_proj"], # LoRA适用于的模块
)
# 获取 PEFT 模型
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters()
# 设置训练参数
training_args = TrainingArguments(
output_dir="/home/user_m/output/round2",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=1e-6,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
fp16=True,
num_train_epochs=1,
weight_decay=0.01,
logging_dir='/home/user_m/logs',
logging_steps=10,
)
# 使用 Trainer 进行微调
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
tokenizer = tokenizer,
)
# 开始训练
trainer.train()
# 使用 Trainer 进行评估
results = trainer.evaluate()
然后每次加载完模型之后会出现以下信息:
Some weights of the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 were not used when initializing MistralForSequenceClassification: ['lm_head.weight']
Some weights of MistralForSequenceClassification were not initialized from the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 and are newly initialized: ['score.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
问题解决:
首先在代码开头加入如下内容:
from transformers import logging
logging.set_verbosity_info()这行指令可以使得终端输出的信息更为详细,再次运行代码,加载完模型之后原本的信息变为:
大致意思是说,加载模型时,没有使用lm_head_weight这个权重,这是因为我们使用模型进行了其他的任务。并且加载模型时score.weight这个权重没有从模型的checkpoint中找到,所以模型对这一部分的权重重新进行了随机初始化。
我们加载完模型之后查看模型的config:
print("model.config: ",model.config)可以得到如下输出信息:
Model config MistralConfig {
"_name_or_path": "/home/user_m/models/Ministral-8B-Instruct-2410",
"architectures": [
"MistralForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 4096,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"initializer_range": 0.02,
"intermediate_size": 12288,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"max_position_embeddings": 32768,
"model_type": "mistral",
"num_attention_heads": 32,
"num_hidden_layers": 36,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-05,
"rope_theta": 100000000.0,
"sliding_window": 32768,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.46.3",
"use_cache": true,
"vocab_size": 131072
}重点关注"architectures": ["MistralForCausalLM"],说明模型本身是用于进行LM任务的。
我们再使用AutoModelForCausalLM加载并查看模型:
model = AutoModelForCausalLM.from_pretrained(model_name)
print(model)这次我们不再得到Some weights of the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 were not used when initializing MistralForSequenceClassification: ['lm_head.weight']这样的信息。
并且会得到以下输出信息: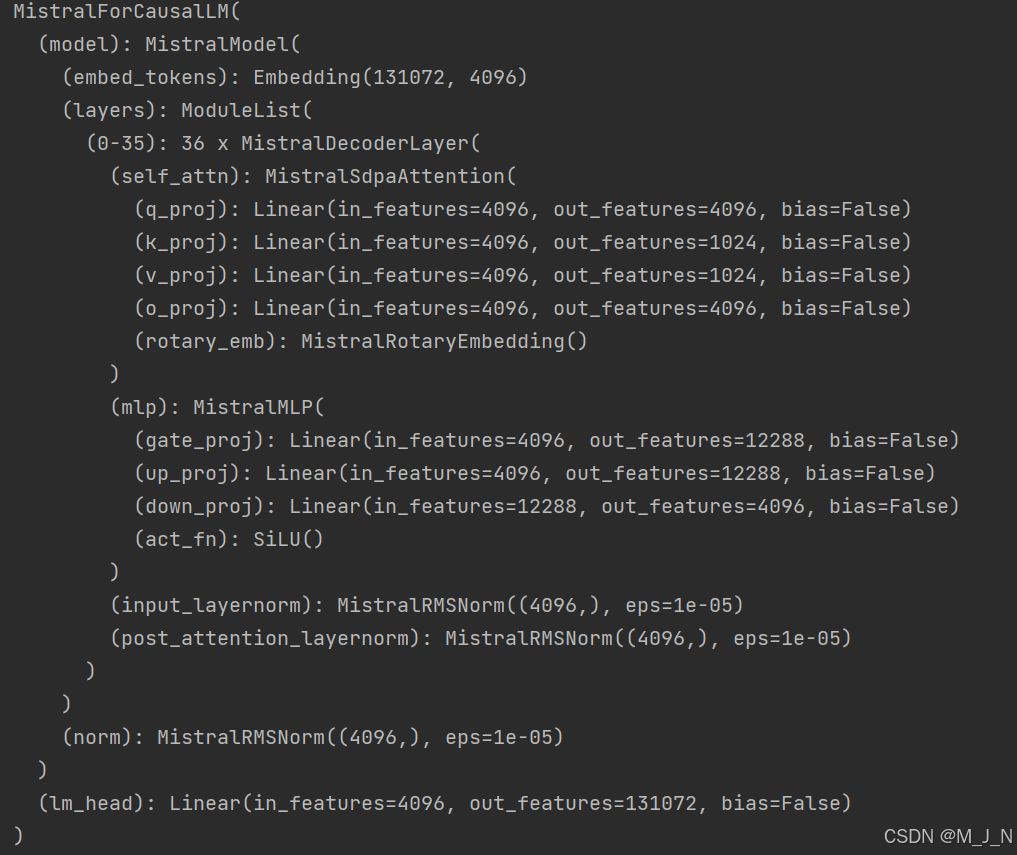
可以看到模型的最后一层是一个lm_head线性层,这一层其实就是对应模型进行LM任务用的头,当我们使用AutoModelForCausalLM加载模型时,与原本模型任务一致,不会出现问题。
但是当我们使用AutoModelForSequenceClassification加载模型,并输出模型结构信息时:
model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=model_checkpoints,
num_labels=num_labels,
device_map="auto",
offload_folder="offload",
trust_remote_code=True,
)
print(model)就会出现Some weights of the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 were not used when initializing MistralForSequenceClassification: ['lm_head.weight']信息,且模型结构如下: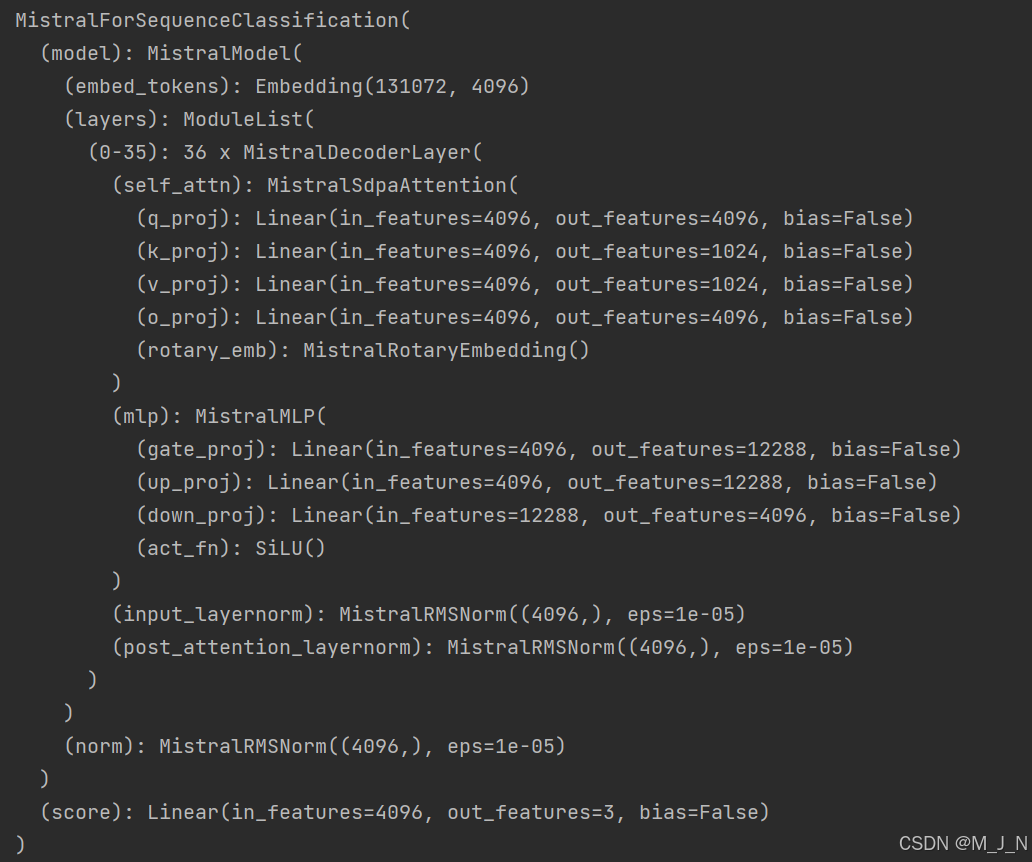
注意,可以看到模型最后一层由lm_head变成了score,这是因为使用AutoModelForSequenceClassification时,会自动给模型适配score分类头用于分类任务,所以再来分析提示信息:
Some weights of the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 were not used when initializing MistralForSequenceClassification: ['lm_head.weight']
Some weights of MistralForSequenceClassification were not initialized from the model checkpoint at /home/user_m/models/Ministral-8B-Instruct-2410 and are newly initialized: ['score.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
由于我们将模型用于SequenceClassification任务,原本的lm_head层被替换成了score层,这样使得原本checkpoint中lm_head相关权重没法加载,并且checkpoint中原本就并不存在score权重,所以才会出现上述信息提示。由于从新初始化了score层,所以当模型计算到score层时,利用这个未经训练的分类头做最后一步输出,得到的结果类似于随机选择也并不奇怪。。。
问题解决:
在分析了代码后,我认为问题出在peft_config这里,这里需要指定任务类型task_type=TaskType.SEQ_CLS
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=rank, lora_alpha=alpha, lora_dropout=lora_dropout, bias=bias,
target_modules=[
"q_proj",
"v_proj",
# "score"
],
)这样训练之后,再次使用AutoModelForSequenceClassification加载模型时虽然还是会出现提示信息,但是这个信息是由于加载baseline模型出现的,在加载完baseline之后,会再加载peft相关权重信息,而score权重信息会由peft进行保存,所以进行评估时:
发现accuracy达到0.86,是一个合理的值,说明微调成功,问题解决!
总结来说,模型其实是包含两个部分,主体模型+处理相关任务的下游模型(比如lm_head、score等),将本来用于任务A的模型应用于任务B时,其实是会将处理A的下游模型替换为处理B的下游模型,所以如果我们希望模型能有良好的表现,就需要确保替换后的下游模型也是经过良好训练而不是随机初始化的,这一步需要在微调模型或训练模型时格外注意。