


Apache Jena Fuseki 4.1.0:构建语义网知识图谱服务器
本文还有配套的精品资源,点击获取 
简介:Apache Jena Fuseki 4.1.0是一个开源的Java知识图谱服务器,支持SPARQL协议,用于托管、查询和提供知识存储的Web服务。它提供对RDF、RDFS和OWL等知识表示语言数据的处理能力,并具备高性能、易于配置和部署的特点。新版本可能包括性能优化和对最新标准的支持。该软件允许用户通过Web接口上传、查询和获取知识图谱数据,并可以与多种系统集成,适用于构建和维护大规模语义数据应用。
1. Apache Jena框架介绍
Apache Jena是一个功能强大的开源Java框架,旨在简化语义网和链接数据应用的开发。它提供了一整套工具来创建、管理和查询语义数据模型。Jena框架的核心优势在于其易于使用的API,支持资源描述框架(RDF)、Web本体语言(OWL)以及SPARQL查询语言。在本章中,我们将探索Jena的核心组件,了解它的基本原理和关键功能,以及如何在不同的应用场景中利用Jena强大的功能来构建高效的数据模型和服务。
1.1 Jena框架的主要特点
Apache Jena的主要特点包括:
- RDF支持 :提供对资源描述框架(RDF)的支持,这是构建语义网数据模型的基础。
- OWL推理 :内建的推理引擎支持Web本体语言(OWL),可以用来执行复杂的本体推理。
- SPARQL查询 :Jena包含一个完全符合SPARQL 1.1规范的查询引擎,支持数据的查询、插入、更新和删除。
1.2 Jena框架的应用场景
Apache Jena广泛应用于多个领域,包括:
- 知识管理 :用于组织和检索存储在知识图谱中的信息。
- 数据集成 :处理和集成来自不同来源的结构化数据。
- 语义搜索 :支持对复杂数据结构的深度查询,提供语义搜索能力。
接下来的章节将深入探讨Jena的各个组件,如Fuseki服务器、SPARQL协议支持以及如何部署和优化Jena应用,从而为读者构建一个完整的知识体系。
2. Fuseki服务器功能概述
2.1 Apache Jena的Fuseki组件
2.1.1 Fuseki服务器的定位与作用
Fuseki是一个高性能的SPARQL服务器,它是Apache Jena框架的重要组成部分,提供了一个REST风格的接口来处理基于RDF(Resource Description Framework)的数据。RDF是一种使用Web标准来描述信息的方式,主要用于描述Web资源。Fuseki服务器允许用户构建、查询和更新数据存储。
定位: Fuseki作为数据服务层的核心组件,主要用于解决大规模数据的读写问题,并提供灵活的数据服务接口。在语义网和链接数据的应用中,Fuseki作为中间件,使得数据的存储、查询、推理等操作可以更加高效和方便。
作用: 它的主要作用包括但不限于:
- 提供一个标准的SPARQL协议接口,方便数据的增删改查操作。
- 通过REST API与不同的数据来源进行交互,增强了系统的互操作性。
- 支持在分布式环境中进行高效的查询,通过集群部署实现数据的负载均衡和高可用。
2.1.2 主要功能和特性介绍
Fuseki的主要功能特性包括但不限于:
- SPARQL查询执行: Fuseki能够执行各种类型的SPARQL查询,包括SELECT、ASK、CONSTRUCT和DESCRIBE查询。
- 数据存储与管理: 支持多种存储后端,能够对RDF数据进行高效的存储和管理。
- 性能优化: 内置多种查询优化技术,提高了查询的响应速度。
- 多用户支持: 支持并发访问和处理,允许多个用户同时对数据集进行操作。
- 安全性: 提供基本的用户认证和权限控制机制,保护数据集的安全。
代码块示例: 下面是启动Fuseki服务器的一个简单示例代码。
fuseki-server --mem /ds
逻辑分析和参数说明:
- --mem 参数表示服务器使用内存数据库。
- /ds 指定数据集的标识符,所有基于这个标识符的请求都会由服务器处理。
2.2 Fuseki服务器的架构设计
2.2.1 服务器组件和数据流
Fuseki服务器的架构设计以模块化和解耦为原则,其组件和数据流的设计主要分为以下几个部分:
- 数据存储组件: 负责RDF数据的持久化存储,支持多种存储后端,如内存、文件系统、数据库等。
- 查询处理组件: 处理客户端发来的SPARQL查询请求,并返回结果。
- 服务管理组件: 负责服务器的启动、关闭、配置和状态监控。
- 安全控制组件: 管理访问控制列表(ACLs),实现访问授权和数据保护。
mermaid格式流程图示例:
graph TD
A[客户端] -->|SPARQL查询| B(Fuseki查询处理)
B -->|查询请求| C[数据存储组件]
C -->|RDF数据| B
B -->|查询结果| A
B -->|管理请求| D(服务管理组件)
D -->|配置更新| B
E[管理员] -->|权限设置| D
2.2.2 高可用性与负载均衡策略
为了保证系统的高可用性和伸缩性,Fuseki支持多种高可用性与负载均衡策略,包括但不限于:
- 集群模式: 通过运行多个Fuseki实例来分摊负载,实现高可用。
- 负载均衡: 可以通过外部负载均衡器,如Nginx或HAProxy来分发请求。
- 数据副本: 在多个节点上创建数据副本,提高读取速度和容错能力。
代码块示例: 以下是配置多个Fuseki实例作为集群的简单示例。
// 配置文件示例:config.ttl
@prefix fuseki: .
<#service> a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:serviceQuery "query" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> a fuseki:MemoryDataset .
2.3 Fuseki服务器的运行模式
2.3.1 嵌入式模式与独立运行模式的对比
Fuseki支持两种主要的运行模式:嵌入式模式和独立运行模式。
- 嵌入式模式: 在同一Java虚拟机(JVM)中运行,适合快速开发和测试。
- 独立运行模式: 以单独的服务器进程运行,支持远程访问和多用户交互。
表格对比:
| 运行模式 | 特点 | 使用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 嵌入式模式 | 同一JVM内运行 | 开发和测试 | 简单快捷 | 可伸缩性有限 |
| 独立运行模式 | 单独服务器进程 | 生产环境 | 易于扩展,支持多用户 | 配置相对复杂 |
2.3.2 如何根据应用场景选择运行模式
选择合适的运行模式对于应用的成功至关重要。下面提供一些决策依据:
- 对于小规模应用或开发测试环境, 嵌入式模式足以应对低负载需求,同时也能快速部署和调试。
- 对于需要支持多用户交互的生产环境, 独立运行模式将是更好的选择,因为它提供了更高的可伸缩性和安全性。
代码块示例: 启动独立运行模式的Fuseki服务器,并提供一个数据集。
Dataset dataset = ... // 创建或加载数据集
Server server = FusekiServer.create()
.add("/ds", dataset) // 添加数据集和访问路径
.build();
server.start();
逻辑分析和参数说明:
- 在上面的代码示例中,我们首先创建了一个数据集对象 dataset 。
- 然后使用 FusekiServer.create() 启动一个新的服务器实例。
- 我们通过 .add("/ds", dataset) 添加数据集,并将其绑定到访问路径 /ds 。
- .build() 构建服务器对象,并使用 .start() 方法启动服务器。
3. SPARQL协议支持
3.1 SPARQL查询语言介绍
3.1.1 SPARQL的基本语法结构
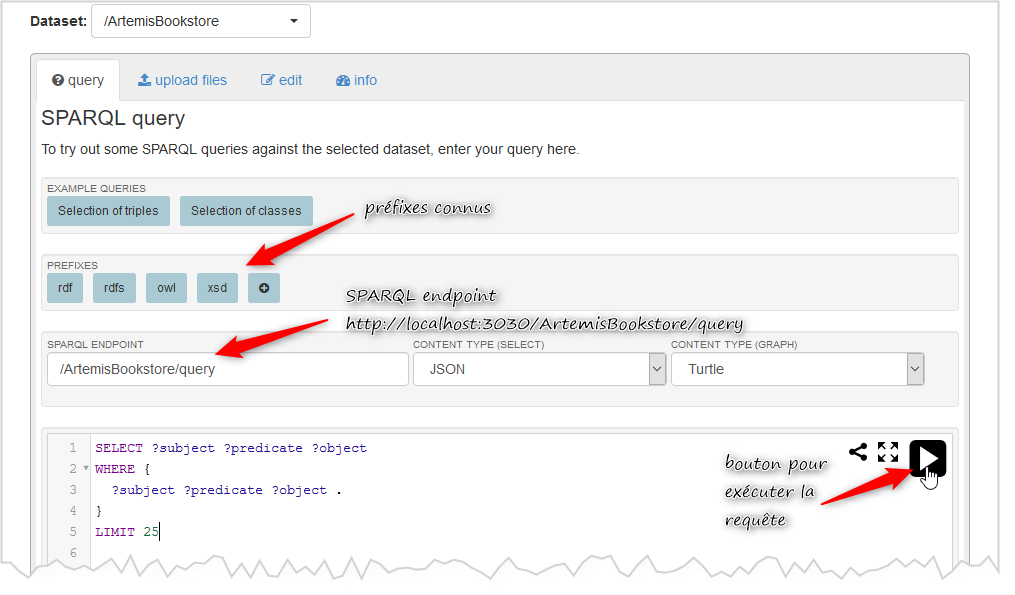
SPARQL(SPARQL Protocol and RDF Query Language)是一种专门用于查询RDF(Resource Description Framework)数据的语言,它允许用户以声明性的方式检索和操作网络中的资源。SPARQL查询通常包括以下几个基本组成部分:
- 前缀声明(Prefix declarations):定义查询中使用的命名空间的缩写。
- 选择块(SELECT clause):指定需要从数据集中检索的变量。
- 图模式(Graph pattern):由三部分构成——三元组模式、过滤器和路径表达式,用于匹配数据集中的模式。
- WHERE子句(WHERE clause):包含一个或多个图模式,用于定义查询的核心逻辑。
- 过滤器(Filters):用于对查询结果进行条件过滤。
- 限定词(Modifiers):如
ORDER BY,LIMIT,OFFSET等,用于对查询结果进行排序、限制输出数量等操作。
下面是一个基本的SPARQL查询示例:
PREFIX rdf:
PREFIX foaf: 这个查询旨在找出所有人及其电子邮件地址。
3.1.2 数据查询、更新、删除操作
SPARQL不仅仅能够进行数据查询操作,它还支持数据的更新和删除。这使得SPARQL成为一个功能完备的RDF数据管理语言。
- 查询(SELECT):如上节所示,用于检索满足特定模式的数据。
- 构造(CONSTRUCT):允许用户通过RDF图模式构建新的RDF图。
- 描述(DESCRIBE):提供一种获取资源描述的方法。
- ASK:用于检查是否存在满足模式的数据,返回布尔值。
更新操作包括:
- 插入(INSERT):将新的RDF数据添加到存储中。
- 删除(DELETE):从存储中删除特定的RDF数据。
- 删除/插入(DELETE/INSERT):结合了删除和插入操作,用于修改数据。
在实际操作中,更新通常通过SPARQL协议的更新(SPARQL Update)进行,它提供了标准的方式来对存储的数据进行增删改操作。
3.2 Fuseki中的SPARQL处理
3.2.1 查询执行引擎的原理
Apache Jena Fuseki是一个SPARQL终端服务器,它提供了一个执行引擎来处理SPARQL查询。执行引擎的工作原理基于以下几个步骤:
- 解析:首先解析SPARQL查询,生成查询的内部表示。
- 查询优化:然后进行查询计划的优化,选择最优的数据访问路径和索引。
- 执行:通过优化后的查询计划来执行查询,对数据集进行检索。
- 结果处理:处理查询执行的结果,按需排序或格式化,并返回给客户端。
Fuseki查询执行引擎通过优化操作,能够处理大规模的RDF数据,并提供高效的数据查询服务。
3.2.2 查询优化和性能调优
查询性能的优化是 Fuseki 服务器中一个关键的方面,涉及如下几个环节:
- 查询计划 :生成一个高效执行的查询计划,对可能的索引和数据存储路径进行评估。
- 索引使用 :利用RDF索引来加速查询,包括三元组索引、属性索引等。
- 数据分割 :根据特定的属性将数据分割成多个片段(shards),可以并行处理以提高查询效率。
- 缓存策略 :对频繁访问的数据实施缓存策略,以减少对底层数据存储的访问次数。
Fuseki 还提供了性能监控工具和日志记录功能,帮助用户识别性能瓶颈并进行调优。
3.3 SPARQL协议的扩展与实践
3.3.1 特殊数据类型的处理
SPARQL协议在处理特殊数据类型时,比如日期、时间、数值等,提供了内建的函数和数据类型。例如,SPARQL有日期和时间的比较函数,对于数值类型数据,提供了数学运算函数等。处理这些特殊数据类型的查询会通过Jena的内置函数或用户自定义的函数来完成。这些函数可以作为查询的一部分进行声明,并用于过滤或者在结果处理中生成新的值。
3.3.2 复杂查询案例分析
复杂的查询案例通常涉及多个数据源的联合查询,以及需要经过多步处理才能得到最终结果的场景。例如,可能会需要进行数据的连接操作、使用子查询,以及处理多重条件等。
下面是一个稍微复杂的SPARQL查询示例,它通过连接两个数据源来查询具有相同电子邮件地址的所有人:
PREFIX rdf:
PREFIX foaf:
SELECT DISTINCT ?name1 ?name2 ?mbox
WHERE {
{
?person1 rdf:type foaf:Person .
?person1 foaf:name ?name1 .
?person1 ex:related ?person2 .
}
{
?person2 rdf:type foaf:Person .
?person2 foaf:name ?name2 .
?person2 foaf:mbox ?mbox .
}
}
在这个查询中,我们首先定义了两个查询块来表示两个数据源,然后通过共享变量 ?person2 实现它们之间的连接。
本章节介绍了SPARQL协议支持的各个方面,从基础的查询语言到复杂查询的实践案例,以及查询优化和性能调优的细节。这些知识对于理解和运用Apache Jena-Fuseki进行知识图谱构建和数据服务是至关重要的。
4. 文件结构与部署
4.1 Apache Jena-Fuseki的文件组织
4.1.1 ZIP包内容解析
Apache Jena-Fuseki以ZIP格式提供,便于用户下载、解压和部署。ZIP包中包含了所有运行Jena-Fuseki服务器所需的文件和目录结构。解压后,用户会发现以下几个关键组件:
- bin/ :包含用于启动和停止服务器的脚本文件。
- config/ :存放服务器的配置文件,例如
tdb.ttl和web.xml。 - data/ :用于存储持久化数据,例如TDB数据库文件。
- lib/ :包含了运行Jena-Fuseki所需的全部Java库文件。
- webapp/ :存放服务器的web应用资源,包括静态文件和JSP页面。
通过仔细分析这些目录结构,我们可以更好地理解如何配置和运行Jena-Fuseki服务器。
4.1.2 如何解压和配置环境
在解压和配置Jena-Fuseki之前,需要确保系统已安装Java运行环境(JRE)或Java开发工具包(JDK),因为Jena-Fuseki是基于Java开发的。以下是解压和配置环境的基本步骤:
- 下载Apache Jena-Fuseki的ZIP包。
- 选择一个目录进行解压,例如
/opt/jena-fuseki。 - 配置Java环境变量,确保
JAVA_HOME指向JRE/JDK的安装路径,并将$JAVA_HOME/bin添加到系统的PATH变量中。 - 根据需要修改
config/tdb.ttl配置文件,调整存储位置或TDB数据库的参数。 - (可选)修改
web.xml或其他配置文件,以自定义服务器行为。
代码块展示了如何在Linux环境下解压Jena-Fuseki ZIP包,并设置环境变量:
# 下载Apache Jena-Fuseki的ZIP包
wget [Jena-Fuseki下载链接]
# 解压到指定目录
unzip jena-fuseki-[版本号].zip -d /opt/jena-fuseki
# 设置环境变量
export JAVA_HOME=/path/to/java/home
export PATH=$JAVA_HOME/bin:$PATH
# 验证Java是否安装成功
java -version
通过这些步骤,我们可以确保Jena-Fuseki环境配置正确,并准备进入部署阶段。
4.2 部署Apache Jena-Fuseki服务器
4.2.1 单机部署步骤与配置说明
部署Jena-Fuseki到单个节点相对简单,以下是在单机环境下部署Jena-Fuseki的详细步骤:
- 解压Jena-Fuseki包到目标目录(如上节所示)。
- 进入
bin/目录。 - 执行启动脚本。在Unix/Linux/Mac系统中使用
./fuseki-server,在Windows系统中使用fuseki-server.bat。 - 默认情况下,服务器将在本地的
3030端口上运行。可以通过在启动时添加参数来更改端口,例如./fuseki-server --port=8080。
对于进一步的配置和优化,可以编辑 config/fuseki.conf 文件,该文件控制着服务器的高级设置。如果需要进行HTTP访问控制,可以编辑 config/shiro.ini 文件。
4.2.2 多节点集群部署方案
部署Jena-Fuseki到多节点集群可以提供更好的可伸缩性和容错性。以下是部署到多节点集群的步骤:
- 配置每个节点的Jena-Fuseki实例,确保它们的配置文件(如
tdb.ttl)和数据目录(data/)是隔离的。 - 配置网络,以便各个节点可以通过内部网络互相通信。
- 在每个节点上启动Jena-Fuseki实例。
- 使用支持负载均衡的代理服务器(如Apache httpd,Nginx)来分发请求到各个节点。
具体的配置可能需要在集群的管理节点上设置一个负载均衡器,将请求分配给集群中的不同实例,以实现高可用性和负载均衡。这通常涉及到网络层面的配置,以及可能的硬件设备(如交换机、路由器)设置。
4.3 部署后的测试与验证
4.3.1 功能测试和性能测试
一旦Jena-Fuseki部署完成,必须进行一系列的测试来验证其功能和性能。功能测试通常包括:
- 确保服务器能够正常启动和停止。
- 通过浏览器或命令行工具访问Jena-Fuseki的管理界面。
- 使用SPARQL查询验证数据的查询、插入、更新和删除操作。
性能测试则更加关注服务器的响应时间和处理能力,可以使用Apache JMeter等工具进行。测试应包括:
- 同时执行多个并发查询,评估响应时间。
- 对服务器执行长时间的查询负载,监控服务器资源使用情况。
- 评估大量数据加载到服务器后,性能的变化情况。
4.3.2 故障排查与问题定位
当Jena-Fuseki部署完成后,可能会遇到各种问题。故障排查和问题定位是确保系统稳定运行的关键步骤。以下是一些基本的故障排查技巧:
- 查看服务器日志文件。通常位于
logs/目录下。日志中会记录错误信息和警告信息,是故障排查的首要参考。 - 使用
jstack等工具检查Java进程的状态,以确定是否有死锁或线程资源竞争问题。 - 检查网络连接,确保服务端口没有被防火墙阻止。
- 使用JMX(Java Management Extensions)监控Jena-Fuseki的运行时性能指标。
- 如果有错误信息指向特定的配置文件,仔细检查配置文件的语法和参数设置是否正确。
表-1展示了常见的Jena-Fuseki故障排查方法:
| 故障情况 | 排查方法 | 解决措施 |
|---|---|---|
| 服务器无法启动 | 查看日志文件 | 确保 web.xml 和 tdb.ttl 配置正确 |
| 查询响应慢 | 性能测试 | 增加服务器资源或优化查询 |
| 线程死锁 | 使用 jstack 分析 | 优化代码逻辑或资源分配 |
通过这些步骤和技巧,可以高效地对Jena-Fuseki进行故障排查和问题定位,确保系统的稳定运行。
5. 知识图谱与数据服务
5.1 知识图谱的概念与应用
知识图谱是一种语义网络,它以图形的方式组织信息,使得数据之间的关系更加直观和易于理解。它由节点(实体)和边(关系)组成,每个节点和边都携带了丰富且结构化的元数据信息。
5.1.1 知识图谱的基本原理
知识图谱的设计借鉴了人类的思考方式,模拟了人类知识的存储结构。在知识图谱中,每个实体都是一个节点,节点之间的连线表示它们之间的关系。这种结构不仅有助于存储大规模知识,还可以通过图的算法快速检索信息。
5.1.2 知识图谱在数据服务中的角色
在数据服务领域,知识图谱可以提升数据处理的智能化水平。它可以用于搜索引擎、推荐系统、自然语言处理等多个方面,通过链接不同数据源,增强数据的互操作性和查询效率。
5.2 Apache Jena-Fuseki的知识图谱实践
Apache Jena-Fuseki提供了构建知识图谱所需的所有工具,包括数据模型的构建、管理以及图谱的查询和推理等功能。
5.2.1 数据模型构建与管理
数据模型是知识图谱的基础,Jena-Fuseki提供了TDB、RDFox等多种存储引擎用于知识图谱的数据模型构建。使用Jena API可以对知识图谱中的数据进行增删改查操作,同时,还可以使用RDF Schema和OWL语言定义图谱的结构和约束。
// 示例代码:使用Apache Jena创建一个简单的知识图谱数据模型
Model model = ModelFactory.createDefaultModel();
Resource book = model.createResource("http://example.org/book1");
Property hasAuthor = model.createProperty("http://purl.org/dc/elements/1.1/creator");
Literal authorName = model.createTypedLiteral("John Doe");
model.add(book, hasAuthor, authorName);
model.write(System.out, "RDF/XML");
5.2.2 知识推理与图谱查询实例
知识推理是知识图谱的重要组成部分。Jena-Fuseki内置了推理引擎,可以进行基于规则的推理。它还支持SPARQL,允许用户通过查询语言访问图谱数据。
# 示例SPARQL查询:查询图书及其作者
PREFIX rdf:
PREFIX dc: 5.3 面向领域的数据服务解决方案
不同的业务场景对知识图谱的要求也不同。领域特定的数据集构建要求我们对领域知识有深刻的理解,并能够将这些知识有效地组织到图谱中。
5.3.1 领域特定的数据集构建
针对特定的业务领域,比如医疗、金融或零售,需要收集相关的数据,定义领域特有的实体类型和关系,构建符合领域需求的数据集。这个过程需要领域专家和数据工程师的紧密合作。
5.3.2 基于Jena-Fuseki的数据服务案例分析
以零售业为例,可以构建一个商品知识图谱,其中包含商品、供应商、客户、订单等实体,以及它们之间的关系,如“购买”、“销售”等。通过这种方式,不仅可以提高产品推荐的准确性,还能优化库存管理。
通过上述章节内容,我们可以看到,知识图谱的构建和应用是一个复杂但又充满机会的领域。Apache Jena-Fuseki为这一领域的实践提供了强大的技术支持,无论是在数据模型的构建、知识推理、还是在实际业务场景中的应用,Jena-Fuseki都显示出了其灵活性和能力。未来,我们可以期待知识图谱在更多领域发挥作用,进一步促进数据服务的发展和创新。
本文还有配套的精品资源,点击获取
简介:Apache Jena Fuseki 4.1.0是一个开源的Java知识图谱服务器,支持SPARQL协议,用于托管、查询和提供知识存储的Web服务。它提供对RDF、RDFS和OWL等知识表示语言数据的处理能力,并具备高性能、易于配置和部署的特点。新版本可能包括性能优化和对最新标准的支持。该软件允许用户通过Web接口上传、查询和获取知识图谱数据,并可以与多种系统集成,适用于构建和维护大规模语义数据应用。
本文还有配套的精品资源,点击获取








