


基于大数据的国家基站整点数据分析系统 | 同样用Python+Java开发,他的国家基站分析系统为什么比别人高级?
💖💖作者:计算机毕业设计江挽
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目
目录
- 基于大数据的国家基站整点数据分析系统介绍
- 基于大数据的国家基站整点数据分析系统演示视频
- 基于大数据的国家基站整点数据分析系统演示图片
- 基于大数据的国家基站整点数据分析系统代码展示
- 基于大数据的国家基站整点数据分析系统文档展示
基于大数据的国家基站整点数据分析系统介绍
《国家基站整点数据分析系统》是一套基于大数据技术构建的专业级数据分析平台,该系统采用Hadoop+Spark大数据框架作为核心技术架构,支持Python和Java双语言开发模式,后端分别基于Django和Spring Boot框架实现,前端采用Vue+ElementUI+Echarts技术栈打造现代化用户界面。系统主要面向国家基站的整点数据进行深度分析处理,通过HDFS分布式文件系统存储海量基站数据,利用Spark SQL进行高效的数据查询和计算,结合Pandas、NumPy等数据科学工具实现复杂的统计分析功能。系统功能涵盖系统首页展示、大屏数据可视化、用户权限管理、国家基站信息综合管理、应用气象专题分析、气象要素关联性分析、气象时间序列趋势分析、风速风向综合分析等十大核心模块,能够为用户提供从数据采集、存储、处理到可视化展示的完整解决方案。通过MySQL数据库管理结构化数据,结合Echarts图表组件实现多维度的数据可视化呈现,系统不仅能够处理基站的基础信息管理,更能深入挖掘气象数据背后的规律和关联性,为相关决策提供科学的数据支撑,是一套集大数据处理、数据分析、可视化展示于一体的综合性分析平台。
基于大数据的国家基站整点数据分析系统演示视频
基于大数据的国家基站整点数据分析系统 | 同样用Python+Java开发,他的国家基站分析系统为什么比别人高级?
基于大数据的国家基站整点数据分析系统演示图片


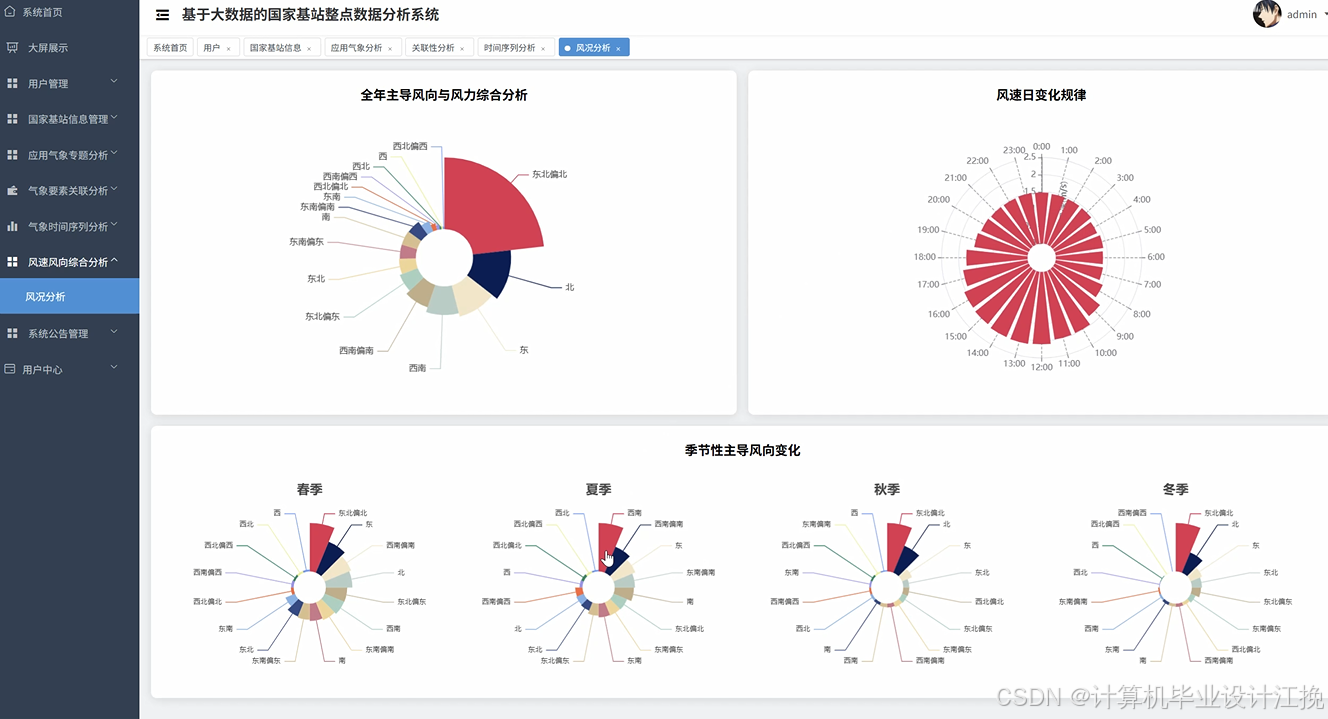
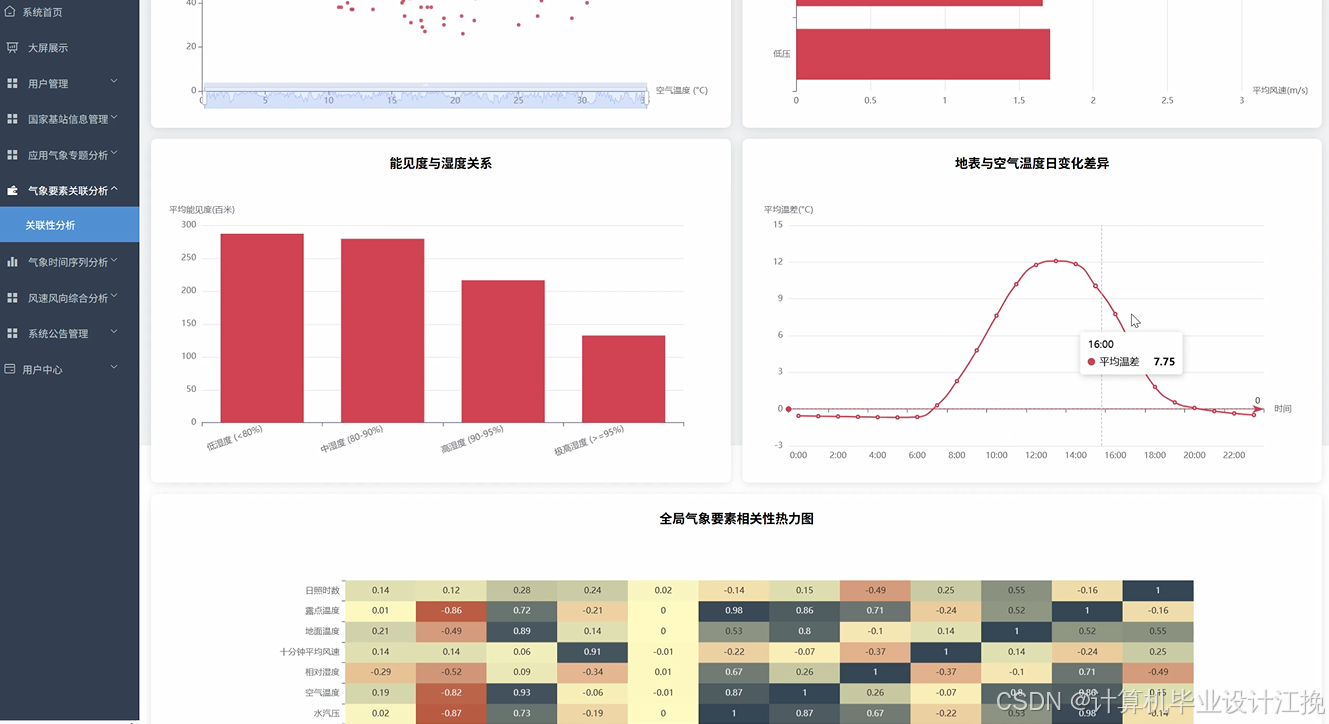

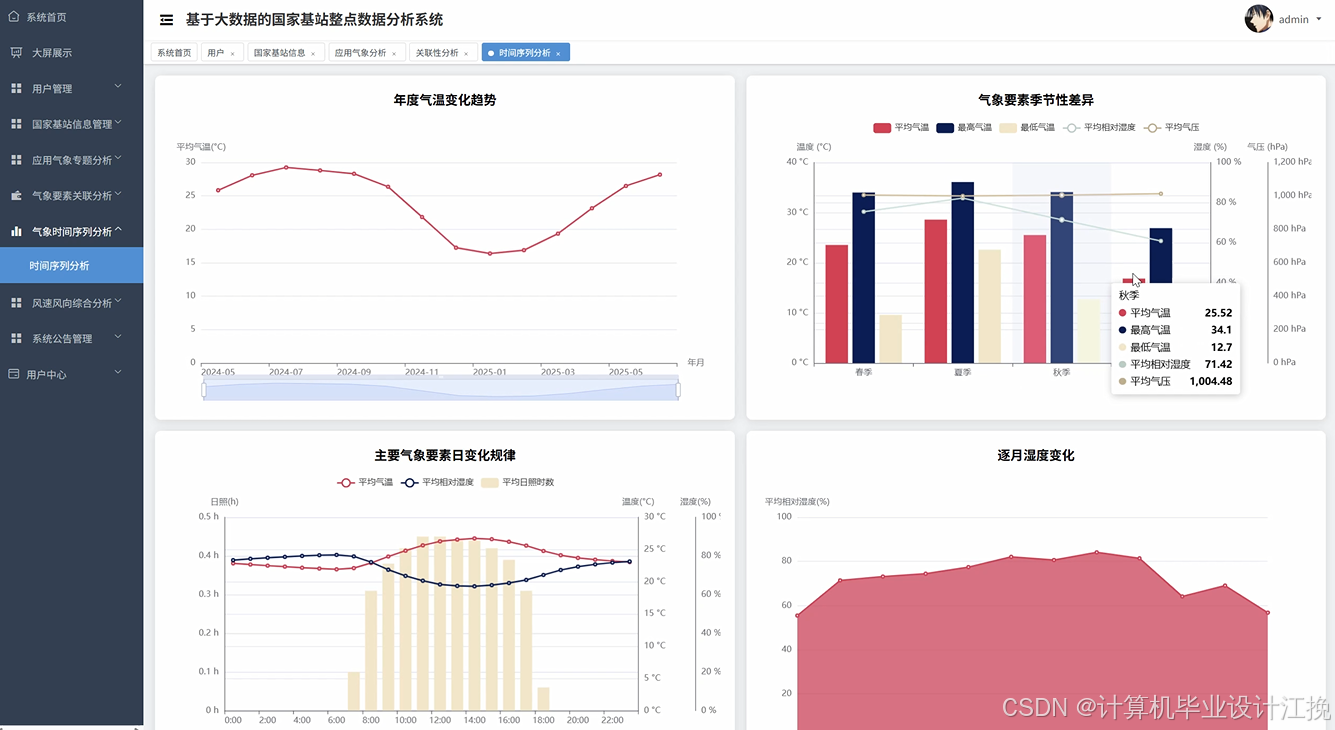
基于大数据的国家基站整点数据分析系统代码展示
# 核心功能1:气象要素关联分析
def weather_correlation_analysis(station_data, start_date, end_date, elements=['temperature', 'humidity', 'pressure', 'wind_speed']):
# 数据预处理和清洗
filtered_data = station_data[(station_data['datetime'] >= start_date) & (station_data['datetime'] <= end_date)]
cleaned_data = filtered_data.dropna(subset=elements)
# 使用Spark SQL进行数据聚合
correlation_matrix = {}
for i, element1 in enumerate(elements):
correlation_matrix[element1] = {}
for j, element2 in enumerate(elements):
if i != j:
# 计算皮尔逊相关系数
correlation_coeff = cleaned_data[element1].corr(cleaned_data[element2])
correlation_matrix[element1][element2] = round(correlation_coeff, 4)
# 计算统计显著性
n = len(cleaned_data)
t_stat = correlation_coeff * np.sqrt((n-2)/(1-correlation_coeff**2))
p_value = 2 * (1 - stats.t.cdf(abs(t_stat), n-2))
correlation_matrix[element1][element2 + '_pvalue'] = round(p_value, 4)
# 识别强相关关系
strong_correlations = []
for element1 in elements:
for element2 in elements:
if element1 != element2 and abs(correlation_matrix[element1].get(element2, 0)) > 0.7:
strong_correlations.append({
'element1': element1,
'element2': element2,
'correlation': correlation_matrix[element1][element2],
'significance': 'significant' if correlation_matrix[element1].get(element2 + '_pvalue', 1) < 0.05 else 'not_significant'
})
# 生成分析报告数据
analysis_result = {
'correlation_matrix': correlation_matrix,
'strong_correlations': strong_correlations,
'data_quality': {
'total_records': len(station_data),
'valid_records': len(cleaned_data),
'missing_rate': round((len(station_data) - len(cleaned_data)) / len(station_data) * 100, 2)
}
}
return analysis_result
# 核心功能2:气象时间序列分析
def weather_timeseries_analysis(station_id, weather_element, analysis_period='monthly'):
# 查询指定基站的历史数据
spark_session = SparkSession.builder.appName("WeatherTimeSeries").getOrCreate()
query_sql = f"""
SELECT datetime, {weather_element}, station_id
FROM weather_data
WHERE station_id = '{station_id}'
AND datetime >= date_sub(current_date(), 365)
ORDER BY datetime
"""
raw_data = spark_session.sql(query_sql).toPandas()
raw_data['datetime'] = pd.to_datetime(raw_data['datetime'])
raw_data.set_index('datetime', inplace=True)
基于大数据的国家基站整点数据分析系统文档展示

💖💖作者:计算机毕业设计江挽
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
网站实战项目
安卓/小程序实战项目
大数据实战项目
深度学习实战项目








