上智院第三界世界科学智能大赛-新能源复赛提交docker经验
笔者也是第一次参加比赛,docker不熟练,这次顺利提交了,给大家分享下提交经验!
1. docker 环境下载安装构建上传
参考天池大赛的步骤:天池大赛从0开始docker提交_天池技术圈-阿里云天池
第一、二步跟着天池教程操作。
第三步我们参考官方给的镜像打包程序。
1.1 修改Dockerfile
# 原始加载镜像
FROM registry.cn-shanghai.aliyuncs.com/tcc-public/pytorch:1.12-py3.9.12-cuda11.3.1-u20.04
# 新的加载镜像
FROM sais-public-registry.cn-shanghai.cr.aliyuncs.com/sais-public/pytorch:2.0.0-py3.9.12-cuda11.8.0-u22.041.2 构建镜像并上传
# 构建镜像
bash build.sh
# 以下命令为示例,实际使用时请修改为自己的镜像地址
# push镜像
docker push registry.cn-shanghai.aliyuncs.com/xxxx/test:0.1注:我首次提交时`bash build.sh` 出错了,具体错误忘了记录,大概意思是docker构建方法太旧,使用如下方法解决,供参考。
docker buildx install
sudo apt-get install docker-buildx2. 数据加载
因容器系统特殊,直接用xr读取nc数据可能存在文件锁定问题导致报错NetCDF: HDF error
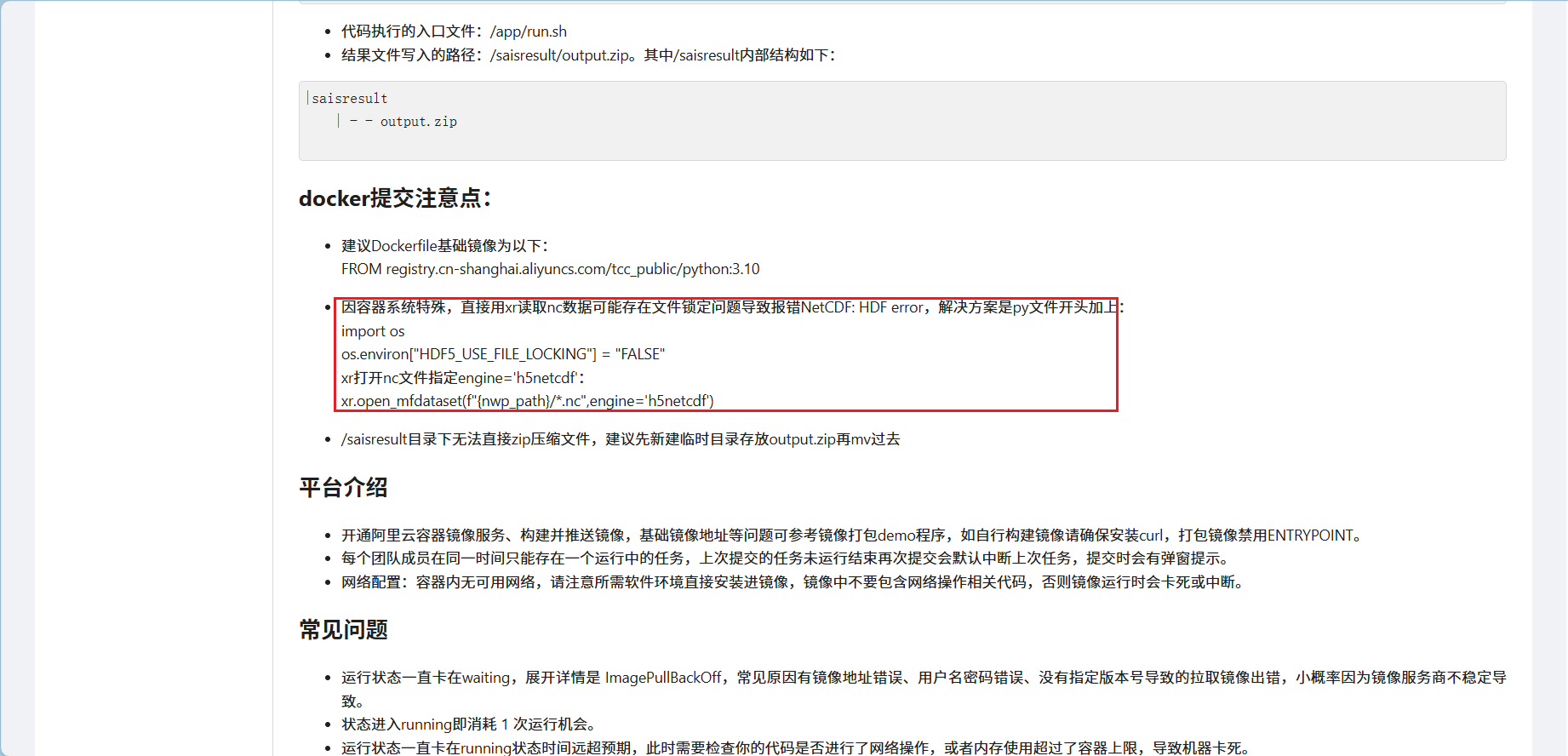
官方没有给出完整代码,可能也是在考察选手的代码处理能力,下面的代码供参考。
# 原数据加载方式
from netCDF4 import Dataset
with Dataset(file_path, mode='r') as ds:
data = ds.variables["data"][:].astype(np.float32)[0]
# 新数据加载方式
import xarray as xr
import os
os.environ["HDF5_USE_FILE_LOCKING"] = "FALSE"
ds = xr.open_mfdataset(
paths=file_path,
engine='h5netcdf',
parallel=True
)
data = ds.variables["data"][:].astype(np.float32)[0]
# 附 路径地址
# 训练集特征
/saisdata/train/POWER_TRAIN_ENV/1/NWP_1/20240101.nc
# 训练集标签
/saisdata/train/power_train/1_normalization_train.csv
# 测试集特征
/saisdata/test/POWER_TEST_ENV/1/NWP_1/20250101.nc3. torch 、 CUDA、dask、h5netcdf问题
问题1:使用GPU报如下错误,缺少了一些文件
Could not load library libcudnn_cnn_infer.so.8. Error: libnvrtc.so: cannot open shared object file: No such file or directory
run.sh: line 5: 19 Aborted
参考解决方法:docker中下载下面的文件,可直接参考最后的完整Dockerfile
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
dpkg -i cuda-keyring_1.1-1_all.deb
apt-get update &&
apt-get install -y --no-install-recommends
cuda-toolkit-12-4 &&
apt-get clean &&
rm -rf /var/lib/apt/lists/*
问题2:缺少dask、h5netcdf包
ImportError: chunk manager 'dask' is not available. Please make sure 'dask' is installed and importable.
ValueError: unrecognized engine 'h5netcdf' must be one of your download engines: ['scipy', 'store'].
参考解决方法:安装缺少的dask包,可直接参考最后的完整Dockerfile
pip3 install dask h5netcdf --index-url=http://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com以下完整Dockerfile供参考
FROM sais-public-registry.cn-shanghai.cr.aliyuncs.com/sais-public/pytorch:2.0.0-py3.9.12-cuda11.8.0-u22.04
# 如有安装其他软件的需求
#RUN apt-get update && apt-get install curl
RUN wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
RUN dpkg -i cuda-keyring_1.1-1_all.deb
RUN apt-get update &&
apt-get install -y --no-install-recommends
cuda-toolkit-12-4 &&
apt-get clean &&
rm -rf /var/lib/apt/lists/*
# 如果安装其他python包的情况
RUN pip3 install numpy pandas scikit-learn xarray dask h5netcdf --index-url=http://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
# 复制代码到镜像仓库
COPY app /app
# 指定工作目录
WORKDIR /app
# 容器启动运行命令
CMD ["bash", "run.sh"]4. xarray读数据慢解决方案
1)仍然使用netCDF4 读取数据,添加HDF5_USE_FILE_LOCKING为False。
import os
os.environ["HDF5_USE_FILE_LOCKING"] = "FALSE"
# 数据加载方式
from netCDF4 import Dataset
with Dataset(file_path, mode='r') as ds:
data = ds.variables["data"][:].astype(np.float32)[0]
# 附 路径地址
# 训练集特征
/saisdata/train/POWER_TRAIN_ENV/1/NWP_1/20240101.nc
# 训练集标签
/saisdata/train/power_train/1_normalization_train.csv
# 测试集特征
/saisdata/test/POWER_TEST_ENV/1/NWP_1/20250101.nc2) 安装一些环境,以下完整Dockerfile供参考
FROM sais-public-registry.cn-shanghai.cr.aliyuncs.com/sais-public/pytorch:2.0.0-py3.9.12-cuda11.8.0-u22.04
# 如有安装其他软件的需求
#RUN apt-get update && apt-get install curl
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list &&
sed -i 's/security.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
RUN apt-get update -y &&
apt-get install -y --fix-missing libnetcdf-dev libhdf5-dev
ENV CPPFLAGS="-I/usr/include/hdf5/serial"
ENV LDFLAGS="-L/usr/lib/x86_64-linux-gnu/hdf5/serial"
RUN pip3 install numpy pandas scikit-learn h5py xarray --index-url=http://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
RUN pip3 install netCDF4==1.7.2 --no-binary=netCDF4 --index-url=http://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
RUN wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
RUN dpkg -i cuda-keyring_1.1-1_all.deb
RUN apt-get update &&
apt-get install -y --no-install-recommends
cuda-toolkit-12-4 &&
apt-get clean &&
rm -rf /var/lib/apt/lists/*
# 复制代码到镜像仓库
COPY app /app
# 指定工作目录
WORKDIR /app
# 容器启动运行命令
CMD ["bash", "run.sh"]5. 数据提交格式
复赛的预测时间与初赛不同,因此需要创建新的模板。
import pandas as pd
# 假设原始DataFrame为df
# 创建示例数据
for index_index in range(1,11):
df = pd.read_csv(f"output/output{index_index}.csv")
date_range = pd.date_range("2025/1/1 00:00", "2025/2/28 23:45", freq="15min")
df = pd.DataFrame(df["power"].tolist(), index=date_range)
# 创建新日期范围
new_dates = pd.date_range("2025/3/1 00:00", "2025/4/30 23:45", freq="15min")
# 计算需要复制的天数
days_to_copy = len(df) # 59天(1/1-2/28)
last_two_days = df.iloc[-2:].values # 最后两天的数据
# 创建新数据
new_data = []
for i in range(len(new_dates)):
if i < days_to_copy:
# 前59天复制1/1-2/28的数据
new_data.append(df.iloc[i % days_to_copy].values[0])
else:
# 后2天复制最后两天的数据
new_data.append(last_two_days[(i - days_to_copy) % 2][0])
# 创建新DataFrame
new_df = pd.DataFrame({'power': new_data}, index=new_dates)
new_df.index = new_df.index.strftime("%Y/%-m/%-d %H:%M:%S")
new_df.to_csv(f"output2/output{index_index}.csv")文件压缩与移动,由于提交文件要求output.zip,并且不可以有多余的目录,因此建议先cd到output同级目录下进行压缩,这样就能避免zip压缩包的多级目录问题。下面是参考的run.sh。
echo "program start..."
python3 training_code/main.py
echo "program end..."
cd training_code
zip -r output.zip output
mv output.zip /saisresult/