【深度学习】多目标融合算法(三):混合专家网络MOE(Mixture-of-Experts)
目录
一、引言
1.1 本篇文章侧重点
1.2 技术洞察—MoE(Mixture-of-Experts,混合专家网络)
二、MoE(Mixture-of-Experts,混合专家网络)
2.1 技术原理
2.2 技术优缺点
2.3 业务代码实践
2.3.1 业务场景与建模
2.3.2 模型代码实现
2.3.3 模型训练与推理测试
2.3.4 打印模型结构
三、总结
一、引言
经历了大模型2024一整年度的兵荒马乱,从年初的Sora文生视频到MiniMax顿悟后的开源,要说年度最大赢家,当属deepseek莫属:年中,deepseek-v2以其1/100的售价,横扫包括gpt4、qwen、百度等一系列商用模型;年底,deepseek-v3发布,以MoE为核心的专家网络技术,让其以极低的推理成本,获得了媲美gpt-4o的效果。

1.1 本篇文章侧重点
本篇文章作为年度技术洞察类文章,今天的重点不是deepseek的训练与推理,如果对训练和推理感兴趣,我在年中写过一篇训练与推理的实战,其中详细讲述了DeepSeek-V2大模型的训练和推理,详细可点击:AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战(只需将V2替换为V3,即可体验最新版本deepseek)。今天的重点是更深一个层次,带大家代码级认识MoE混合专家网络技术。
1.2 技术洞察—MoE(Mixture-of-Experts,混合专家网络)
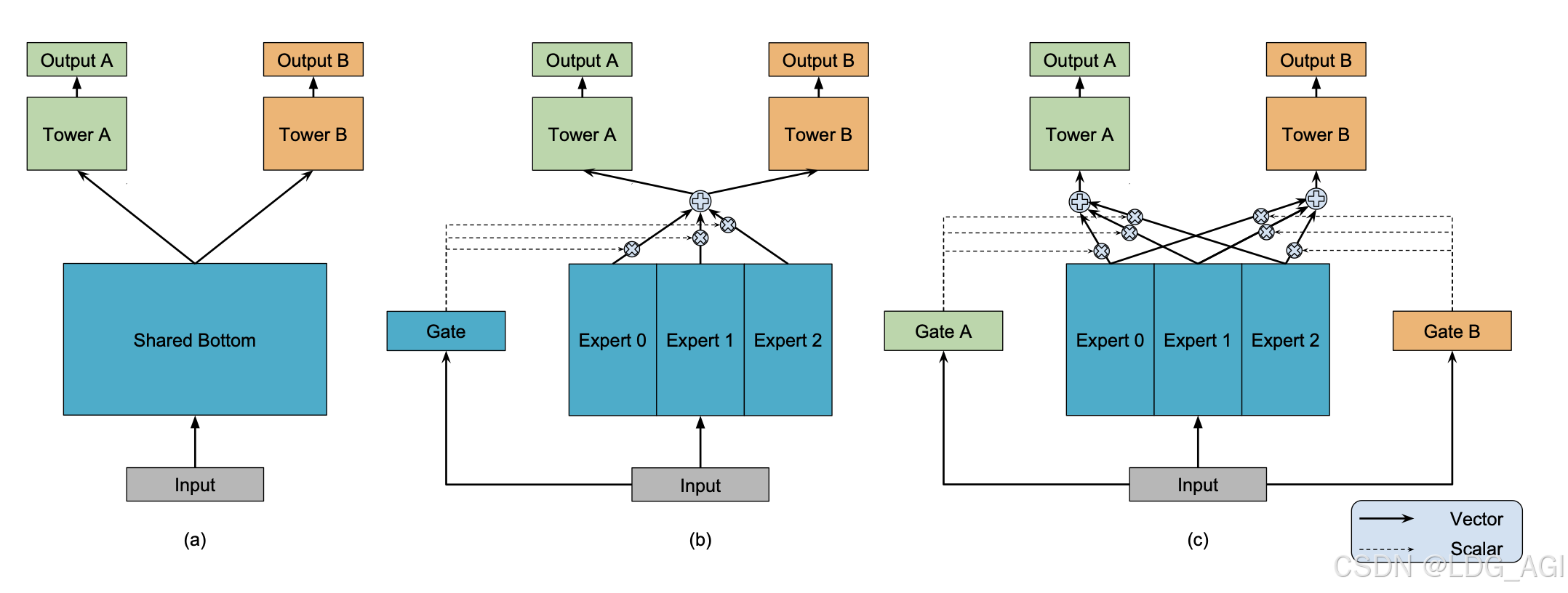
MoE(Mixture-of-Experts) 并不是一个新词,近7-8年间,在我做推荐系统精排模型过程中,业界将MoE技术应用于推荐系统多任务学习,以MMoE(2018,google)、PLE(2020,腾讯)为基石,通过门控网络为多个专家网络加权平均,定义每个专家的重要性,解决多目标、多场景、多任务等问题。近1-2年间,基于MoE思想构建的大模型层出不穷,通过路由网络对多个专家网络进行选择,提升推理效率,经典模型有DeepSeekMoE、Mixtral 8x7B、Flan-MoE等。
万丈高楼平地起,今天我们不聊空中楼阁,而是带大家实现一个MoE网络,了解MoE代码是怎么构建的,大家可以以此代码为基础,继续垒砖,根据自己的业务场景,创新性的构建自己的专家网络。
二、MoE(Mixture-of-Experts,混合专家网络)
2.1 技术原理
MoE(Mixture-of-Experts)全称为混合专家网络,主要由多个专家网络、多个任务塔、门控网络构成。核心原理:样本数据分别输入num_experts个专家网络进行推理,每个专家网络实际上是一个前馈神经网络(MLP),输入维度为x,输出维度为output_experts_dim;同时,样本数据输入门控网络,门控网络也是一个MLP(可以为多层,也可以为一层),输出为num_experts个experts专家的概率分布,维度为num_experts(菜用softmax将输出归一化,各个维度加起来和为1);将每个专家网络的输出,基于gate门控网络的softmax加权平均,作为Task的输入,所以Task的输入统一维度均为output_experts_dim。在每次反向传播迭代时,对Gate和num_experts个专家参数进行更新,Gate和专家网络的参数受任务Task A、B共同影响