


部署mineru docker流程以及踩的坑
linux部署mineru docker流程以及踩的坑
1.部署流程(基本是按照Mineru的web_api docker部署文档一步步走的)
拉取项目源码
git clone https://github.com/opendatalab/MinerU.git
cd MinerU/projects/web_api
在build之前做一些修改工作:
1)修改download_models.py,直接替换
#!/usr/bin/env python
from modelscope import snapshot_download
if __name__ == "__main__":
mineru_patterns = [
# "models/Layout/LayoutLMv3/*",
"models/Layout/YOLO/*",
"models/MFD/YOLO/*",
"models/MFR/unimernet_hf_small_2503/*",
"models/OCR/paddleocr_torch/*",
# "models/TabRec/TableMaster/*",
# "models/TabRec/StructEqTable/*",
]
model_dir = snapshot_download(
"opendatalab/PDF-Extract-Kit-1.0",
allow_patterns=mineru_patterns,
local_dir="/opt/",
)
layoutreader_pattern = [
"*.json",
"*.safetensors",
]
layoutreader_model_dir = snapshot_download(
"ppaanngggg/layoutreader",
allow_patterns=layoutreader_pattern,
local_dir="/opt/layoutreader/",
)
model_dir = model_dir + "/models"
print(f"model_dir is: {model_dir}")
print(f"layoutreader_model_dir is: {layoutreader_model_dir}")
2)在requirements.txt 中加一行modelscope,用于模型下载。
此处有一个坑,很有可能你的layoutreader模型下不完,猜测原因是比较大,几百M,或者别的原因导致docker内layoutreader文件夹是空的,这时候可以在docker外运行download_models.py,注意设置模型保存位置,改两行代码,再通过mv命令移动到docker内的/opt/layoutreader/目录下(这是后话)
from modelscope import snapshot_download
layoutreader_model_dir = snapshot_download('ppaanngggg/layoutreader', cache_dir = "your model path")
3)如果想在docker外方便查看mineru的结果,在app.py中的output的路径进行个人的设置:
async def file_parse(
file: UploadFile = None,
file_path: str = None,
parse_method: str = "auto",
is_json_md_dump: bool = True,
output_dir: str = "workspace/MinerU/projects/web_api/output",# 这里进行修改
return_layout: bool = True,
return_info: bool = True,
return_content_list: bool = True,
return_images: bool = True,
):
4)在build这一步,如果docker没有更改过配置源,90%会报错,这里给一个临时的解决办法,在Dockerfile里第一行改成(这里以我当时拉取的项目版本为例)
FROM swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/python:3.10-slim-bookworm AS base
5)完成以上步骤就可以运行命令:
docker build -t mineru-api .
接下来要做的就是等待,如果中间报错,80%都是因为docker源的问题,解决不掉就老实配源吧
测试部署的api
在docker部署完成后,执行docker ps 命令,结果如下则证明部署成功。

打开http://localhost:8000/提示{“detail”:“Not Found”},别急,后边加个docs,返回页面:
http://localhost:8000/docs
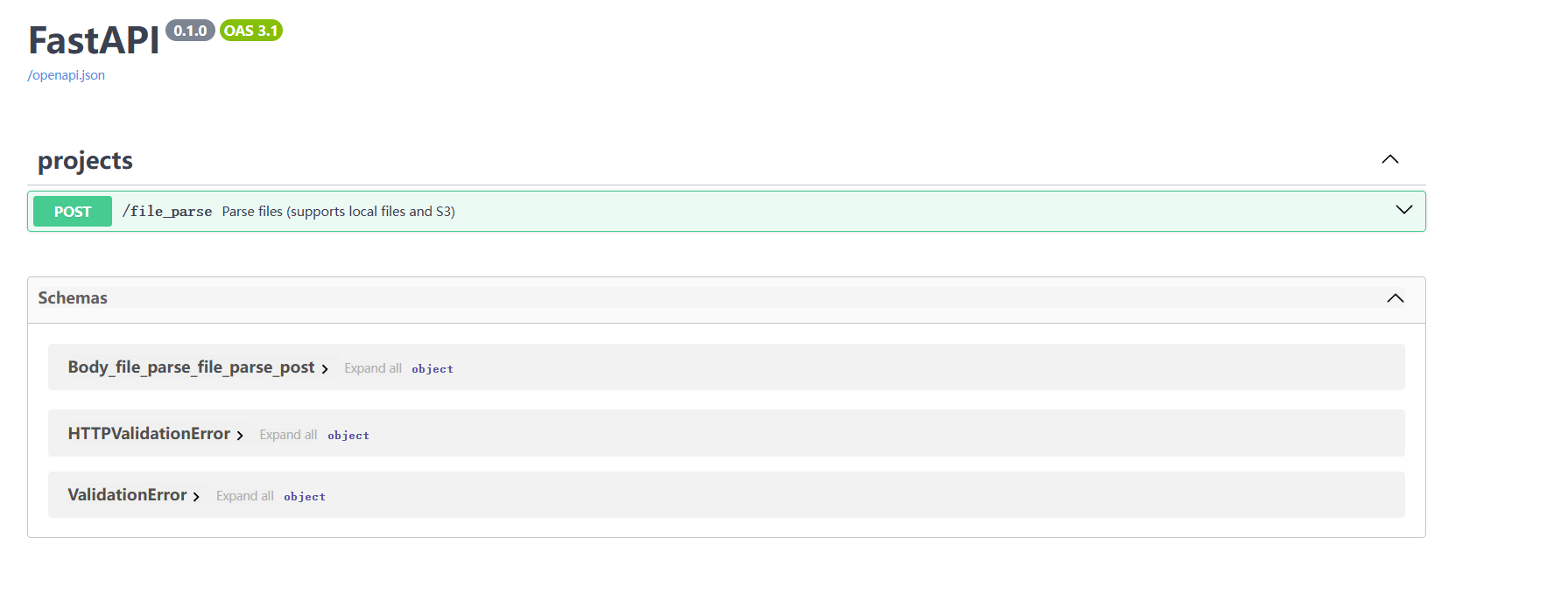
说明大功告成,可以点开手动上传测试文件进行测试,运行完后可以在前面设置的output文件夹下看到结果,结果结构如下:
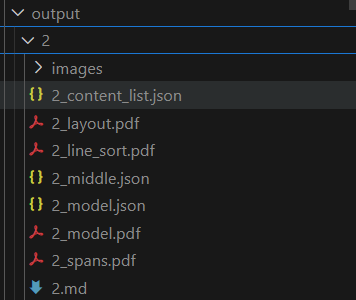
一般来说都是对.md文件进行后续处理
接下来给一段远程调用mineru_api的代码:
import requests
import json
# API配置
url = "http://localhost:8888/file_parse"
params = {
"parse_method": "auto",
"is_json_md_dump": "true",
"return_layout": "true",
"return_info": "true",
"return_content_list": "true",
"return_images": "true"
}
# 文件配置
file_path = "/2.pdf" # 确保文件存在当前目录
headers = {
"accept": "application/json"
}
try:
with open(file_path, "rb") as f:
files = {
"file": (file_path, f, "application/pdf")
}
response = requests.post(
url,
params=params,
headers=headers,
files=files
)
# 处理响应
print(f"Status Code: {response.status_code}")
if response.status_code == 200:
result = response.json()
# 保存结果到文件
# with open("api_response.json", "w") as f:
# json.dump(result, f, indent=2)
md_content = result.get("md_content", "")
with open("md_content_.txt", "w", encoding="utf-8") as f:
f.write(md_content)
print("MD内容已保存到 md_content.txt")
# 打印关键信息
print(f"MD内容长度: {len(result.get('md_content', ''))} 字符")
print(f"解析图片数量: {len(result.get('images', {}))}")
print(f"内容列表条目: {len(result.get('content_list', []))}")
else:
print(f"请求失败: {response.text}")
except FileNotFoundError:
print(f"错误:文件 {file_path} 不存在")
except Exception as e:
print(f"发生异常: {str(e)}")








