


[实验日志] 将pycharm(本地项目)连接到远程服务器(Linux)上跑起来 —— 使用远程环境 + pycharm运行run.sh + 配置分布式训练的环境变量
目录
0. 前序工作
1. 连接远程虚拟环境 (配置解释器)
2. 理解.sh (shell脚本 - 以Occ为例)
补充shell脚本讲解
3. 配置运行参数 (PyCharm)
值得注意的路径问题:
小结
0. 前序工作
在远程运行虚拟环境之前,得确保已经完成以下几个前置步骤:
1. 在jupyter lab进入终端,远程配好环境,先让项目远程跑起来,先不考虑本地PyCharm
2. 将pycharm本地项目同步到(Linux)服务器上——科研实践(完成文件上的map对应同步)
1. 连接远程虚拟环境 (配置解释器)
- (1)文件 → 设置
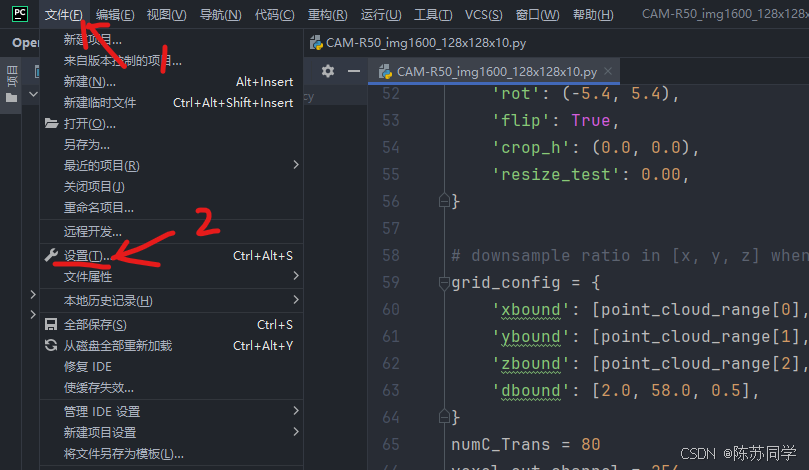
- (2)项目 → python解释器 → 添加解释器 → SSH
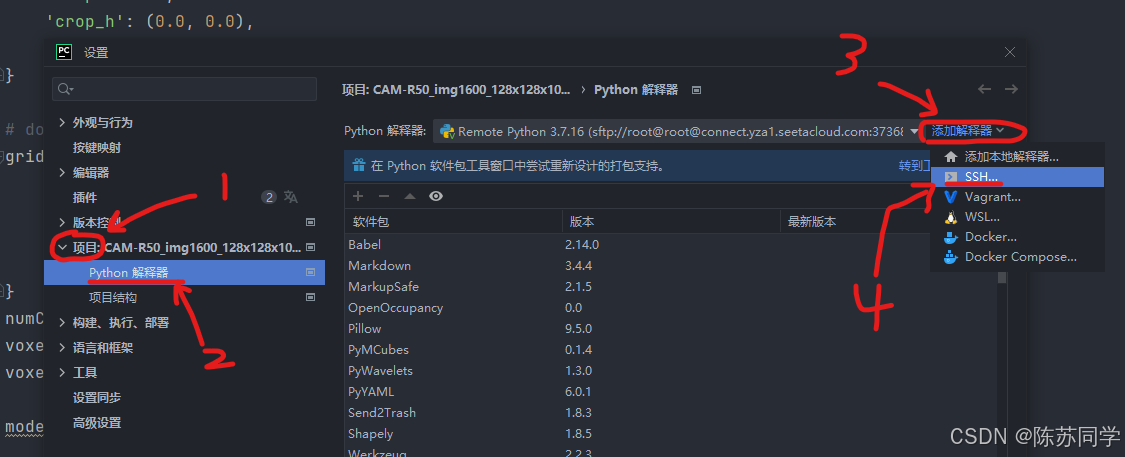
- (3)现有 → SSH服务器右侧下拉菜单 → 选择咱的端口37368 → 下一步
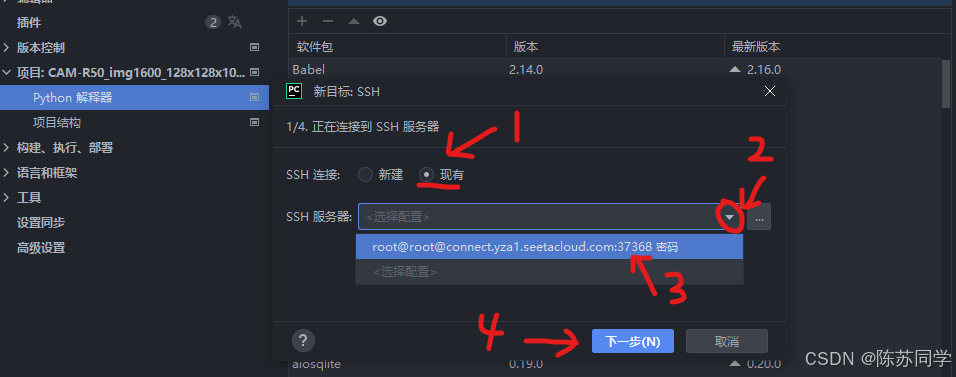
- (4)内省完成 → 下一步 (2/3. 正在内省 SSH服务器) 窗口
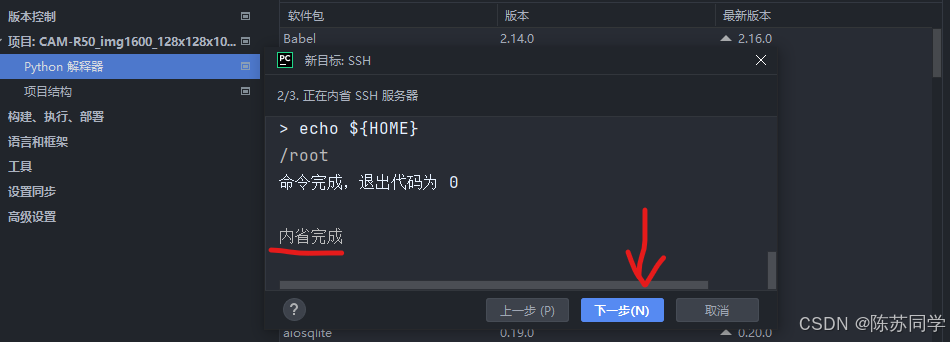
下一步后会自动弹出“新目标: SSH”的 (3/3. 项目目录和 Python 运行时配置) 窗口
- (5)Virtualenv 环境(不要选Conda,亲测不太行)→ 现有 → 取消勾选“自动上传到服务器” → 选择“远程路径”文件夹
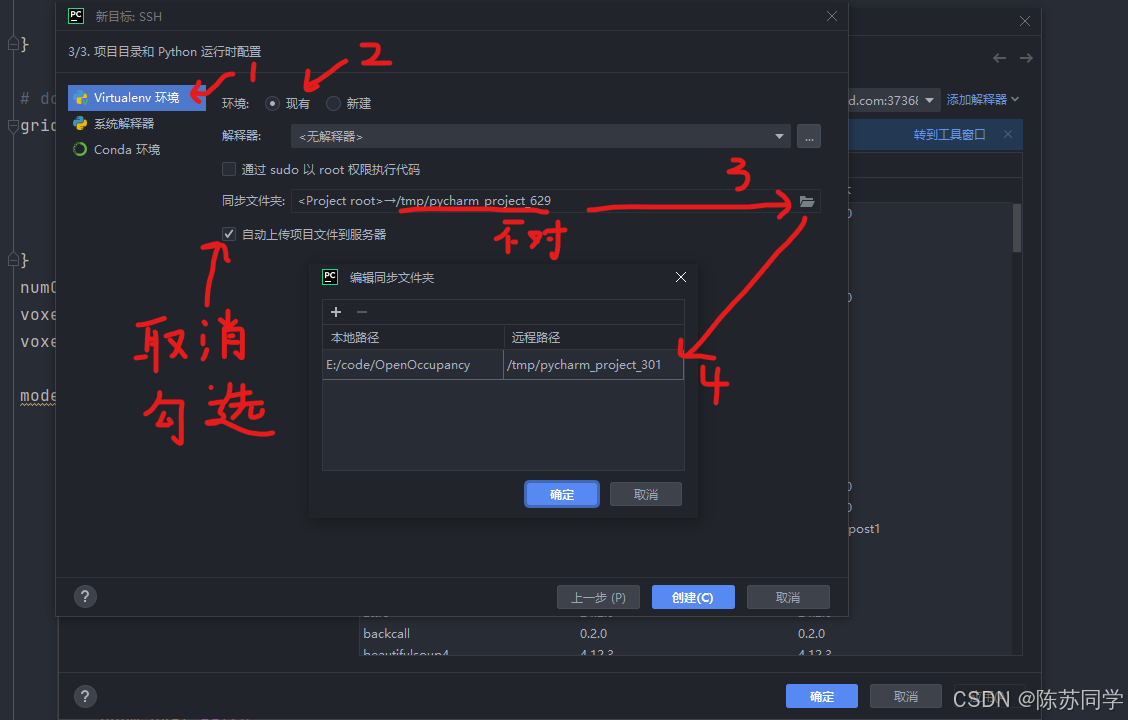
- 下面是对应上的远程路径
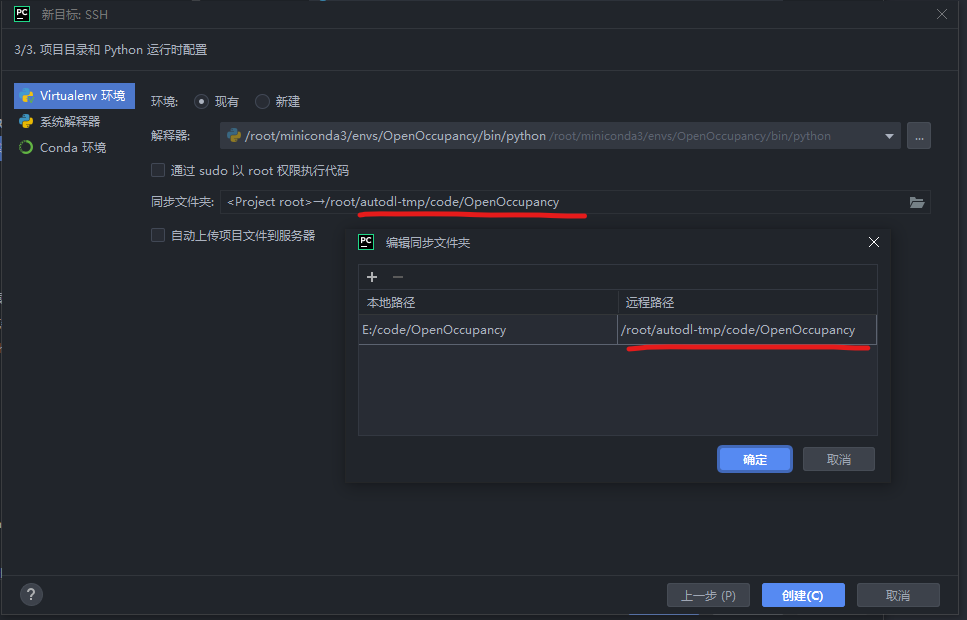
(6)中的选择解释器步骤,可以放在(5)选择“远程路径”文件夹之前操作,没问题的
- (6)解释器:显示: <无解释器>,还得咱自己勾选一下,选中咱虚拟环境中的python,确定→创建→确定
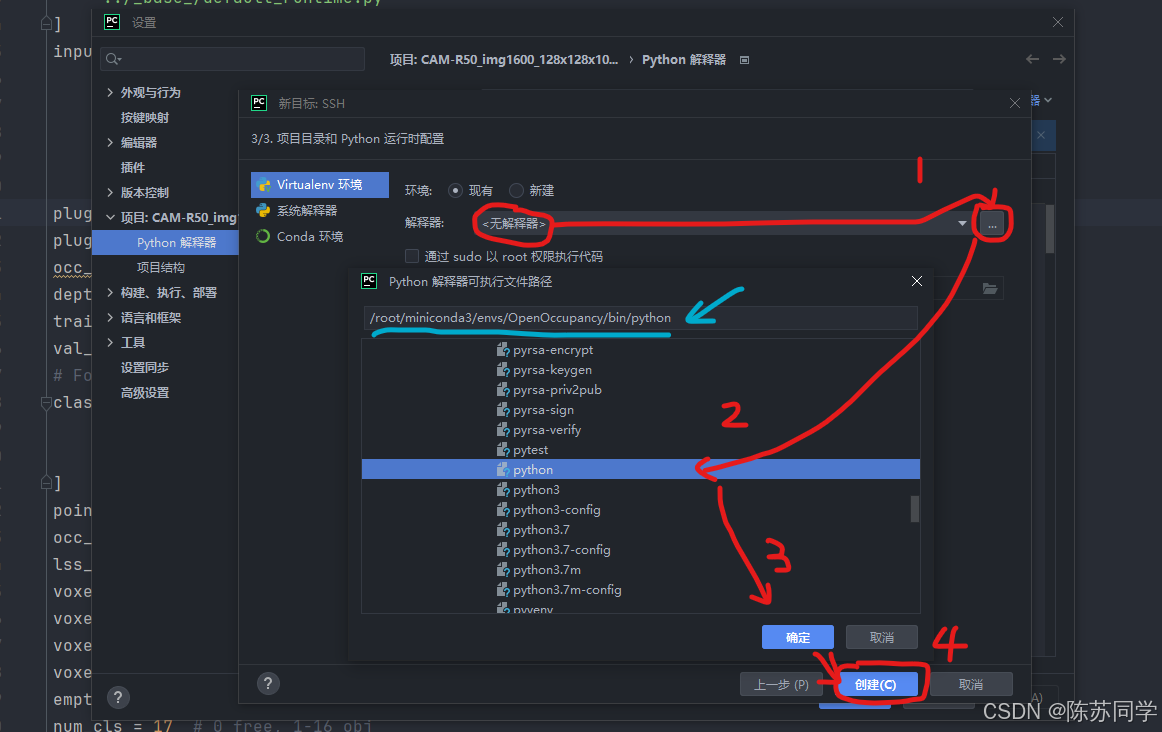
然后需要等待20s左右,就能成功连上虚拟环境啦
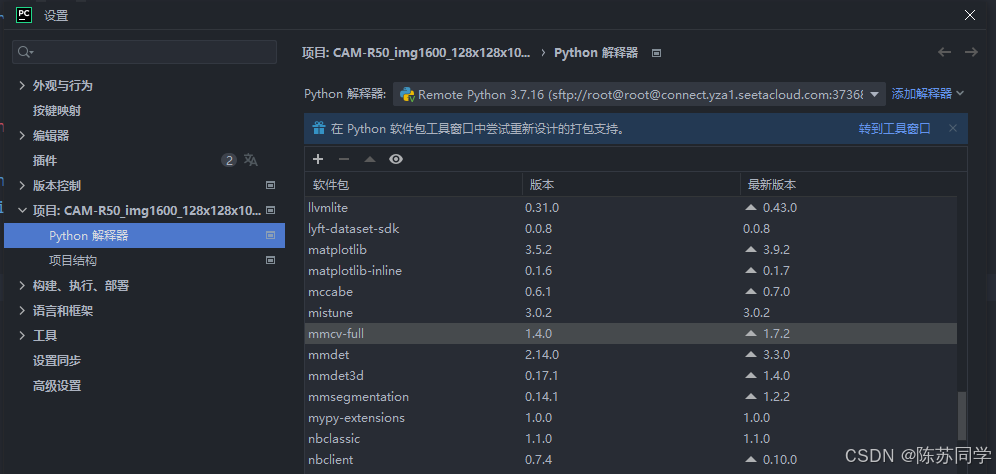
可以看到之前已经初始化好了的环境,本人在PyCharm远程连接服务器前,已经成功跑起来了,这是前序工作(当然配好环境的工作量不小)
2. 理解.sh (shell脚本 - 以Occ为例)
首先打开官方文档,看看当时执行train的逻辑(每个项目都会有细微差别,但知识点相同)
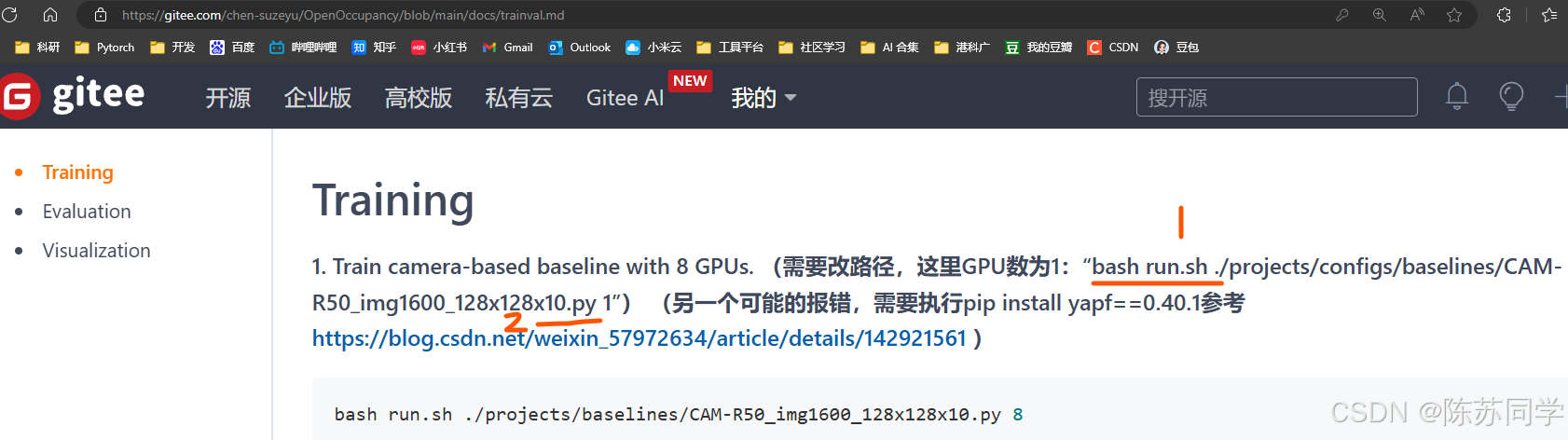
说明在执行“CAM-R50_img1600_128x128x10.py”文件前,需要执行Linux的bash文件,python解释器不理解Linux语法,怎么办呢?不慌,咱细看这个shell脚本文件~
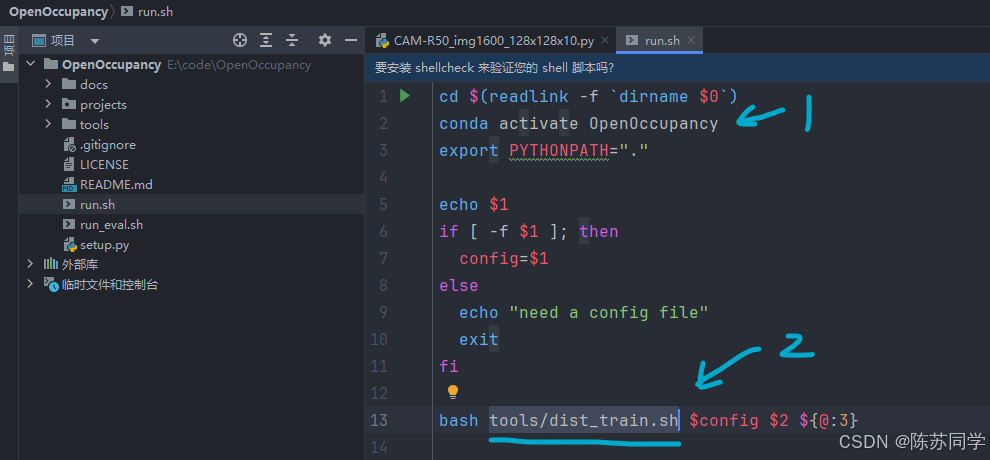
补充shell脚本讲解
cd $(readlink -fdirname $0):
dirname $0获取当前脚本文件所在的目录路径。readlink -f获取当前脚本所在目录的绝对路径。cd命令切换到这个绝对路径下,使得后续操作在该目录中进行。激活名为 “OpenOccupancy” 的 Conda 环境,以便在特定的环境中执行后续命令。
conda activate OpenOccupancy:设置 Python 的模块搜索路径为当前目录(
export PYTHONPATH=".":.表示当前目录),这样在运行 Python 程序时可以方便地找到当前目录下的模块。打印第一个命令行参数的值,这里是查看传入的参数。
echo $1:检查第一个命令行参数是否为一个文件。
if [ -f $1 ]; then:-f是一个条件判断,用于判断参数所代表的路径是否指向一个常规文件。
config=$1:
- 如果第一个参数是一个文件,将其赋值给变量
config,后续用于指定配置文件。
bash tools/dist_train.sh $config $2 ${@:3}:
- 调用
tools目录下的dist_train.sh脚本进行分布式训练。- 将前面确定的配置文件(
$config)、第二个命令行参数($2)以及第三个及以后的所有参数(${@:3})传递给这个脚本。
执行命令: “bash run.sh./projects/configs/baselines/CAM-R50_img1600_128x128x10.py 1” 时, 对应关系如下:
./projects/configs/baselines/CAM-R50_img1600_128x128x10.py对应代码中的$1。在代码中,首先检查这个参数所代表的路径是否是一个文件,如果是,则将其赋值给config变量,后续用于指定配置文件进行分布式训练。- “1” 对应代码中的
$2。这个参数指的是用几个gpu训练,会在最后被传递给dist_train.sh脚本进行分布式训练。
这里又嵌套了一层tools/dist_train.sh,咱来看看这个shell脚本写了什么:(在tools目录下)
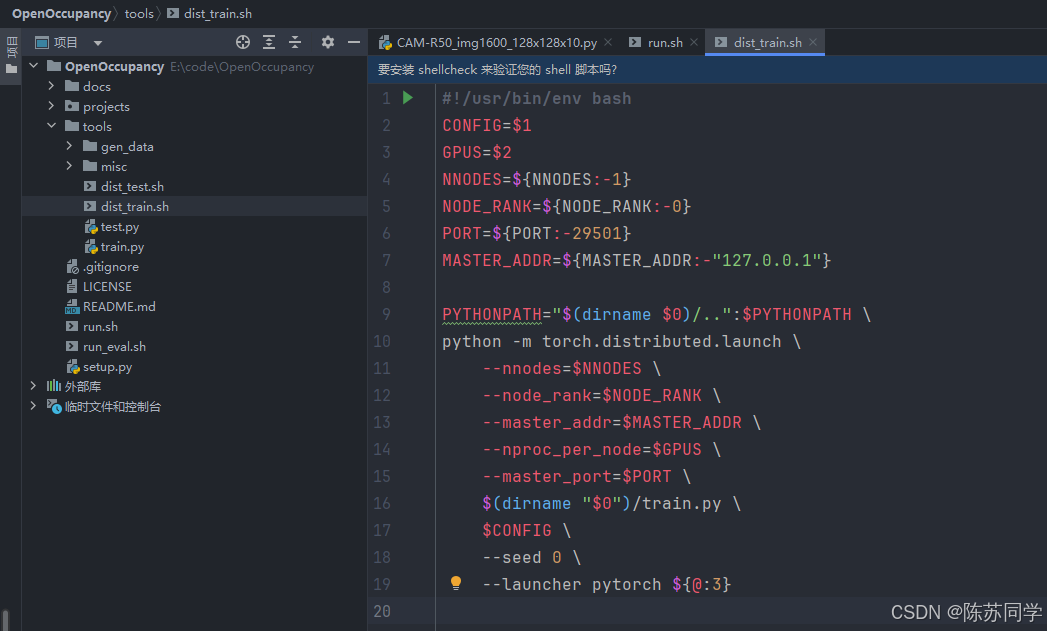
#!/usr/bin/env bash
# 配置文件路径,由脚本的第一个参数传入,就是上面的.py文件
CONFIG=$1
# GPU 数量,由脚本的第二个参数传入
GPUS=$2
# 如果环境变量 NNODES 未设置,则默认为 1,表示分布式训练中的节点数量
NNODES=${NNODES:-1}
# 如果环境变量 NODE_RANK 未设置,则默认为 0,表示当前节点在分布式训练中的排名
NODE_RANK=${NODE_RANK:-0}
# 如果环境变量 PORT 未设置,则默认为 29501,通常用于分布式训练中的节点间通信
PORT=${PORT:-29501}
# 如果环境变量 MASTER_ADDR 未设置,则默认为"127.0.0.1",通常是分布式训练中的主节点地址
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
# 将当前脚本所在目录的上级目录添加到 PYTHONPATH 环境变量中
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
# 使用 PyTorch 的分布式启动模块启动训练程序
python -m torch.distributed.launch
# 设置分布式训练的节点数量
--nnodes=$NNODES
# 设置当前节点的排名
--node_rank=$NODE_RANK
# 设置主节点的地址
--master_addr=$MASTER_ADDR
# 设置每个节点上的进程数量(通常对应 GPU 数量)
--nproc_per_node=$GPUS
# 设置用于节点间通信的端口
--master_port=$PORT
# 启动分布式训练的 Python 程序 train.py,使用当前脚本所在目录的路径来找到这个程序
$(dirname "$0")/train.py
# 将配置文件路径传递给 train.py;在本例中,CONFIG参数就是这个路径: CAM-R50_img1600_128x128x10.py
$CONFIG
# 设置随机种子为 0,可能是为了保证实验的可重复性
--seed 0
# 设置启动器为 PyTorch,并将脚本的第三个及以后的参数传递给 train.py;这里咱暂时还用不上
--launcher pytorch ${@:3}要想在PyCharm里运行这个训练脚本(bash run.sh./projects/configs/baselines/CAM-R50_img1600_128x128x10.py 1),需要配置运行参数!
3. 配置运行参数 (PyCharm)
(1)在 PyCharm 顶部菜单栏中,选择 “Run”(运行)>“Edit Configurations”(编辑配置)

(2)设为“module”(不要选script)→ 输入"PyTorch 的分布式启动模块启动"的命令 → 展开后把环境变量粘贴过来
补充:“module”和“script”
a. 选script的情况
如果执行的linux命令是
python tools/train.py projects/configs/flashocc/flashocc-r50-M0.py执行的事一个.py的脚本,就得选择“script”,类似于这样:
b. 选module的情况
如果执行的linux命令是运行一个.sh文件,则如下文操作:
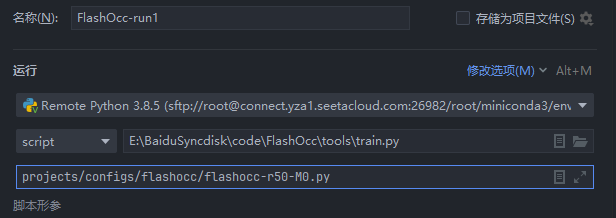
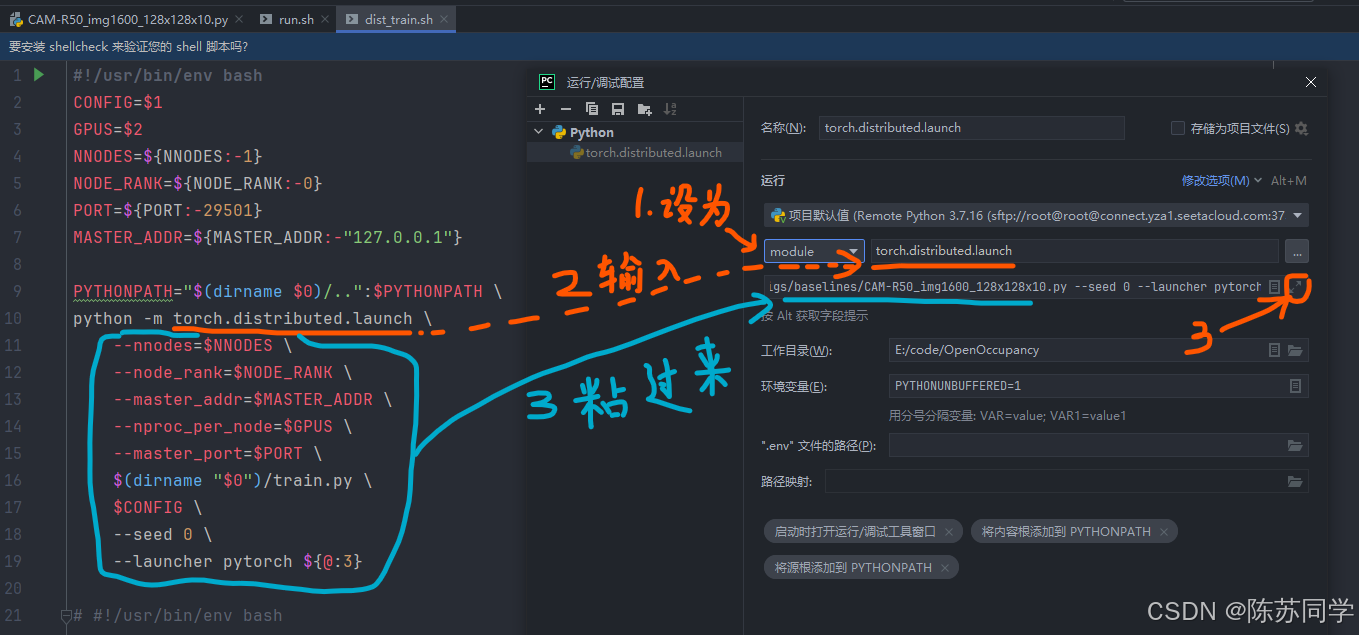
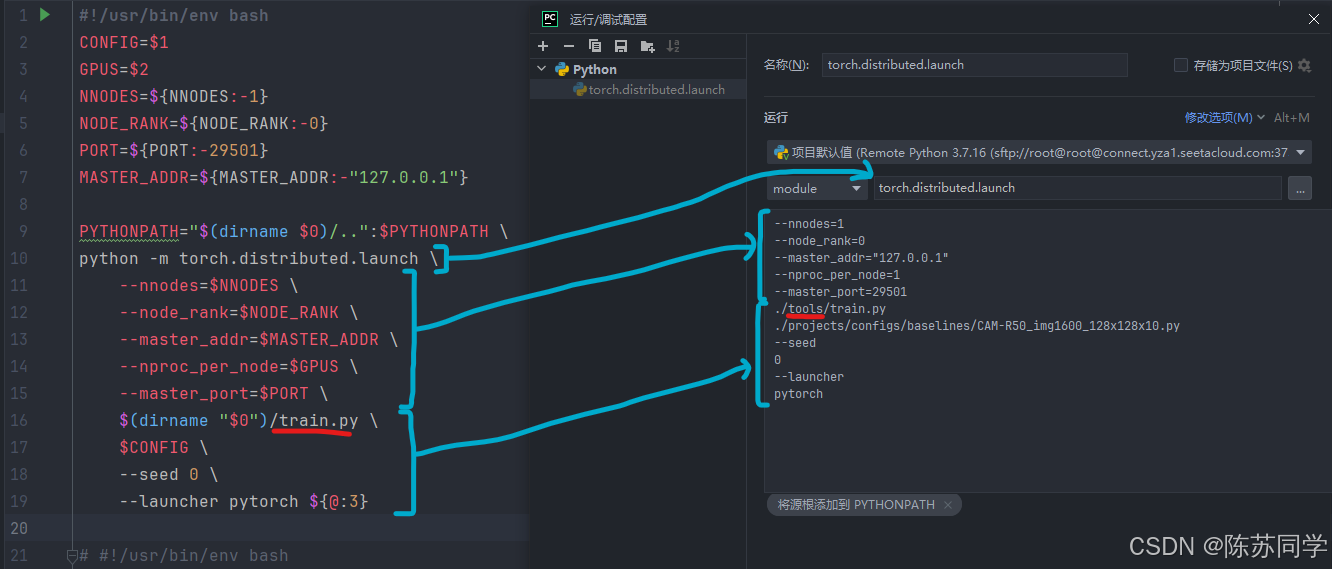
--nnodes=1
--node_rank=0
--master_addr="127.0.0.1"
--nproc_per_node=1
--master_port=29501
./tools/train.py
./projects/configs/Cascade-Occupancy-Network/CAM-R50_img_trans_sp.py
--seed
0
--launcher
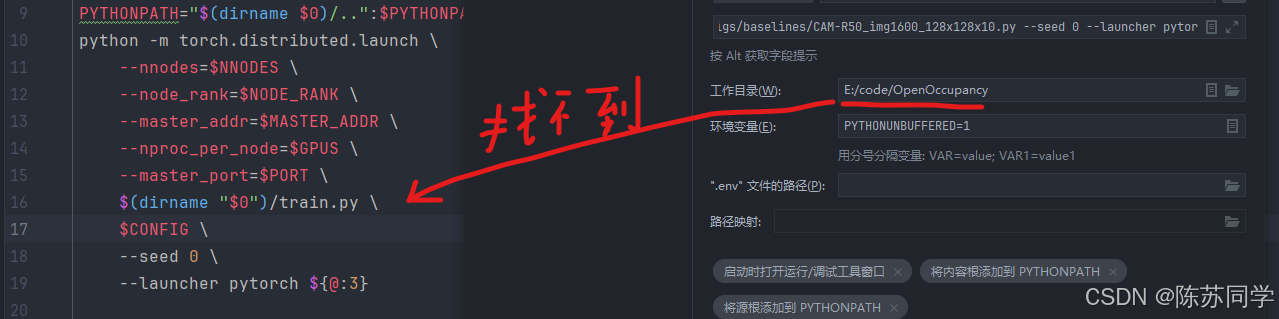
pytorch值得注意的路径问题:
$(dirname "$0")/train.py → ./tools/train.py
- 是因为train.py在OpenOccupancy/tools里,而我们要执行的“OpenOccupancy/projects/configs/baselines/CAM-R50_img1600_128x128x10.py”并不在OpenOccupancy/tools路径下
- 而同时需要用到的train.py却在“OpenOccupancy/tools”路径下,两个文件的路径不一样
- 因此把工作目录: “E:/code/OpenOccupancy/tools”→“E:/code/OpenOccupancy”
- 的同时,需要改粘贴过来的配置文件路径: train.py → ./tools/train.py
路径映射(推荐)
没有路径映射可能会出问题

小结
- 这下点击确定后重新执行,就不会再报错啦(以上的每一步,都是建立在运行后报错,找原因,改进后的实践经验总结)
- 运行剩下的不同的训练脚本,修改的方法都大同小异








