


docker 环境 部署vllm + deepseek -7B
第一步 先安装docker 这个教程已经很多了,我就不在多赘述了
第二步,下载模型 我在以下网站下载的模型。里边有很多,想用什么下载什么
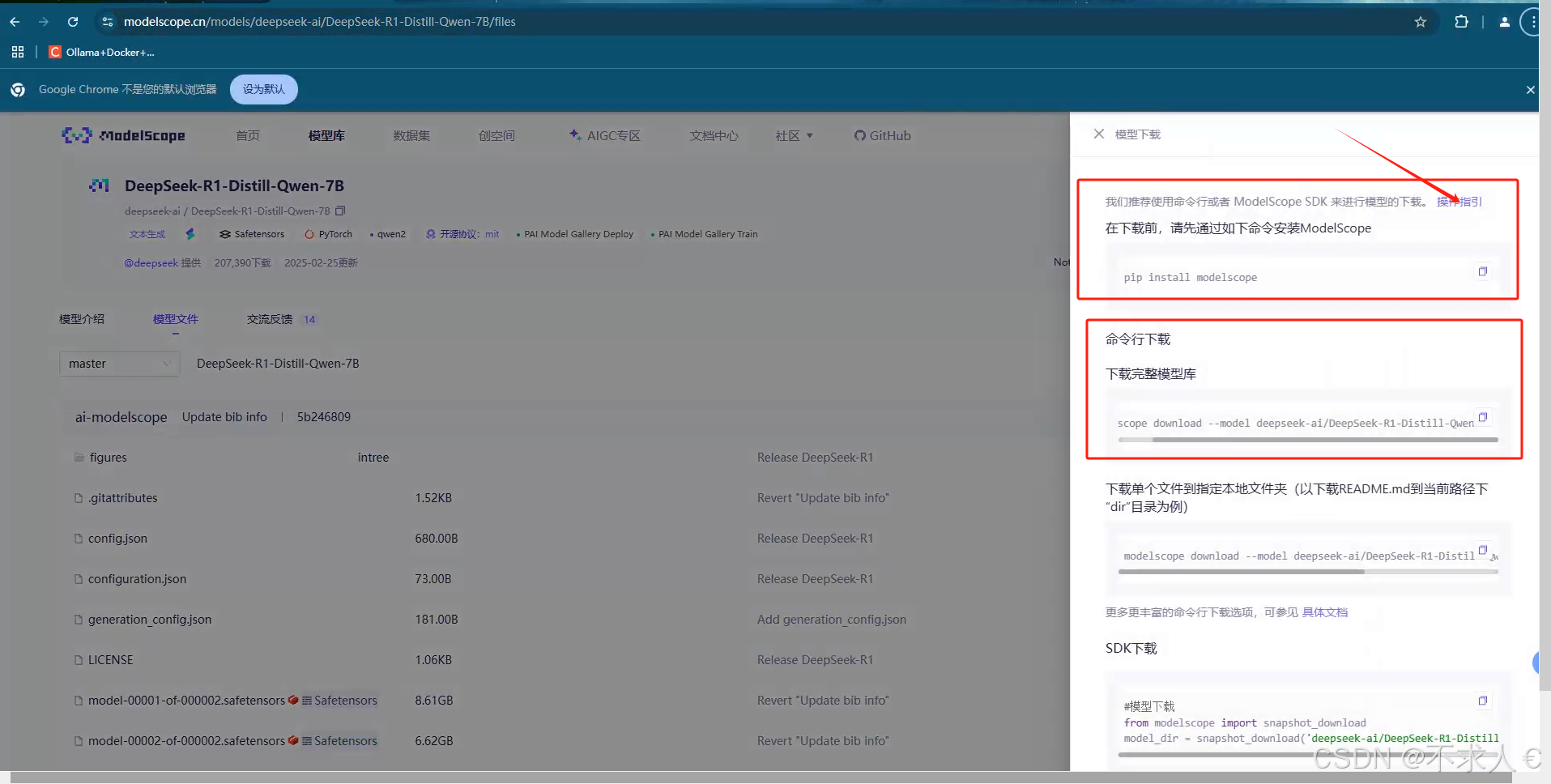
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。![]() https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/files
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/files
在windows 窗口
在安装了python3.8 +的环境下
1.如果只需要通过ModelScope SDK,或者ModelScope命令行工具来下载模型,可以只最轻量化的安装ModelScope的核心hub支持:
在窗口执行 pip install modelscope
2.如果需要更完整的使用ModelScope平台上的一系列框架能力,包括数据集的加载,外部模型的使用等,则推荐使用"framework"的安装选项,也就是
在窗口执行 pip install modelscope[framework]
(这个是在执行了第一个命令后没有办法下载模型,所以执行了第二个命令)
下载模型的命令
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --local_dir D:modelsdeepseek-14b
把模型保存到D:modelsdeepseek-7b 目录,可自定义 最好不要默认 要不然会找不到模型位置,启动vllm的时候需要读取模型
安装vllm
在docker环境下 先安装 vllm
因为docker国外环境的限制,如果有条件可以翻墙 直接下载无条件也可以用国内的镜像
# 国内测试机无法直接下载(试了很多国内加速器都不能正常下载),可以在海外机器下载镜像,然后上传到国内自有库,再从国内自有库下载镜像
# 国内自有库下载镜像
docker pull swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai:latest
Docker运行vllm
docker run -d --gpus all -p 8000:8000 -v D:modelsdeepseek-7b:/app/model --name deepseek vllm/vllm-openai:latest --model /app/model --port 8000 --max-model-len 12048 --gpu-memory-utilization 0.95 --served-model-name deepseek-7B
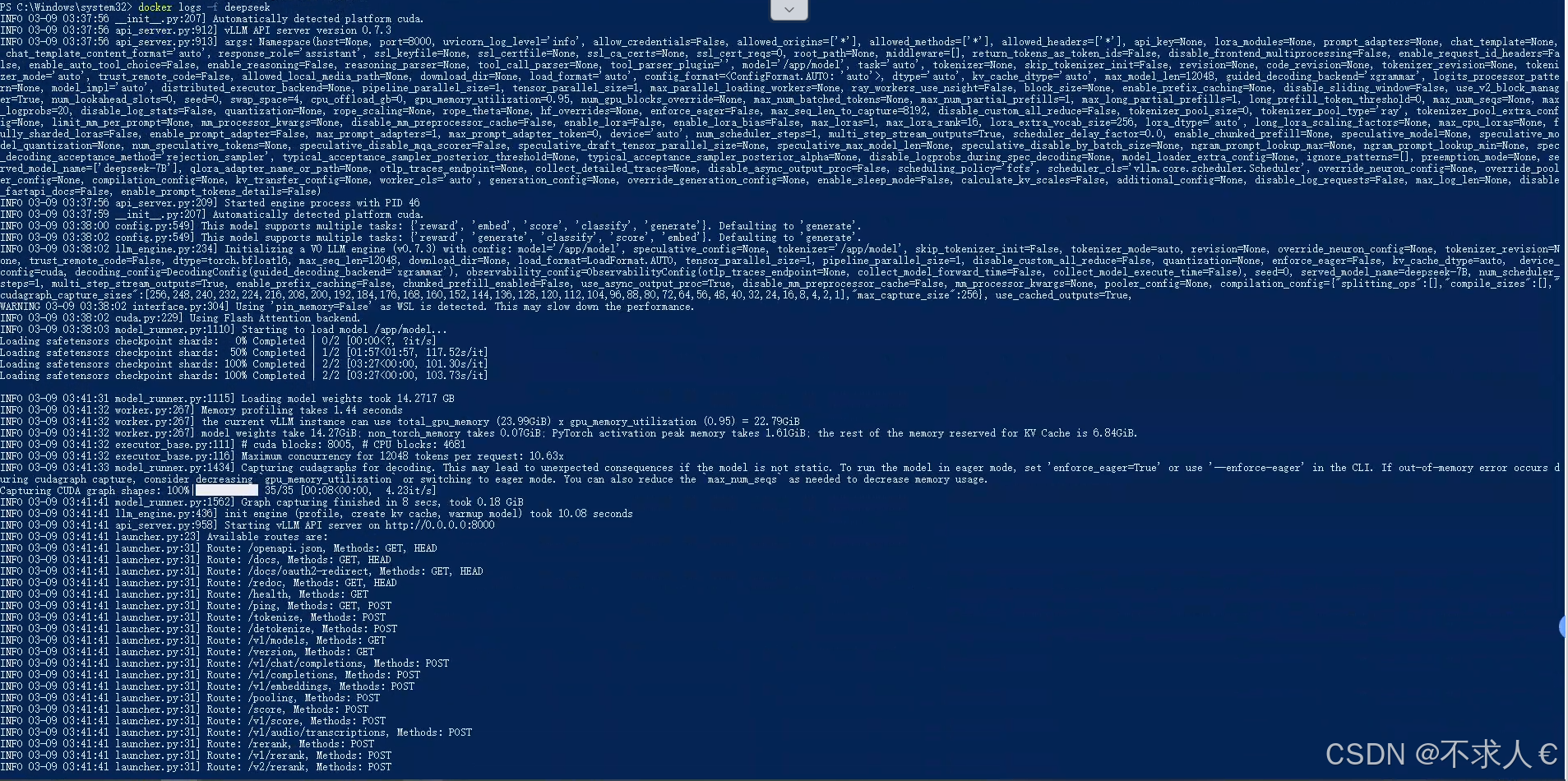
以下是一些参数的解释,我这个是4090显卡24g显存,只能运行7B的模型。如果运行14B的就 需要更好的显卡,或者主板支持显卡集火的。
( 这里只是个笔记 可以忽略。这段是先启动容器,然后再容器中在读取模型。开始用的后来感觉不用这么麻烦。直接启动容器就好了,
7B
docker run -it --gpus all --shm-size 15.24g -v D:modelsdeepseek-7b:/app/model -p 8000:8000 --ipc=host --name deepseek7 --entrypoint /bin/bash vllm/vllm-openai:latest
python3 -m vllm.entrypoints.openai.api_server --model /app/model/ --port 8000 --tensor-parallel-size 1 --served-model-name DeepSeek-7B --gpu_memory_utilization 0.95 --max-model-len 8192 --trust-remote-code --enforce_eager
14B
docker run -it --gpus all --shm-size 15.24g -v D:modelsdeepseek-14b:/app/model -p 8000:8000 --ipc=host --name deepseek14 --entrypoint /bin/bash vllm/vllm-openai:latest
python3 -m vllm.entrypoints.openai.api_server --model /app/model/ --port 8000 --tensor-parallel-size 1 --served-model-name DeepSeek-14B --gpu_memory_utilization 0.98 --max-model-len 18192 --trust-remote-code --enforce_eager
)D:modelsdeepseek-7b 启动命令中这个是模型的下载位置。
--served-model-name deepseek-7B 这个参数请求的时候需要用的。务必加上。
参数说明(可以先不看):
-it(等价于 -i -t)
-i(--interactive)
保持容器的标准输入(STDIN)开放,允许用户与容器交互(如输入命令)。
-t(--tty)
为容器分配一个伪终端(pseudo-TTY),使容器的输出格式化为终端友好的形式(如支持颜色、光标移动)。
-d(--detach)
让容器在后台运行(守护进程模式),不占用当前终端
--restart always
让容器自启动,因意外中断可自行重启
--name
指定容器名为vllm_ds32
-v
本地目录与容器内目录进行映射,如上命令将本地/data/chuangchuang/LLM_stores路径与容器内/data路径映射
-p
端口映射,18005:8000 ,本地18005端口和容器内8000端口映射
--gpus '"device=1,4"'
指定使用本地服务器某几张显卡
--dtype
指定模型参数类型,可选项为 auto (自行根据情况加载) 、float32、bfloat16、float16等,可自行查阅部署模型可选参数类型有哪些,不知道的情况可选 auto 。若模型支持bfloat16,建议选择此项,同时兼具保证模型性能良好和显存消耗降低。
--served-model-name
为部署模型自定义名称
--gpu-memory-utilization
控制 GPU显存的利用率,范围在 0~1 之间。默认值:0.9(即占用 90% 的可用显存)。
当多卡部署时,默认每张卡都会占用相同比例显存,若某张卡显存不足,可能导致失败
--model
容器内模型所在路径地址
--tensor-parallel-size
多卡部署,指定所需卡数,其需要和--gpus参数所设置显卡数量保持一致
可选参数:
--max-model-len 16384
设置模型处理的最大上下文长度(token数)。默认行为从模型配置(如 config.json 的 max_position_embeddings)自动推断。Deepseek-32B模型默认为131072,7B类型的模型一般为3万多,具体视情况而定
--enforce-eager
强制使用 PyTorch Eager 模式,禁用 CUDA 图优化。默认行为:混合使用 CUDA 图和 Eager 模式以优化性能。启用场景:调试兼容性问题(如内核不兼容报错);避免 CUDA 图内存泄漏(长期运行服务);性能影响:可能降低推理速度 10%~30%。
--privileged(Docker 参数)
作用:赋予容器 特权模式,允许访问宿主机设备(如 GPU、NVIDIA 驱动)。
必要性:在容器内使用 GPU 时通常需启用,否则无法调用 CUDA 接口
--enable-auto-tool-choice
启用模型的自动工具选择能力,允许模型根据用户输入和预定义的工具列表,自动决定是否需要调用工具以及选择具体的工具。默认行为:若未启用该参数,模型可能仅生成文本回复,而不会触发工具调用逻辑。
--tool-call-parser hermes
指定模型工具调用响应的解析器风格,hermes 表示使用与 Hermes 模型兼容的解析格式。
Hermes 格式特点:工具调用结果以 JSON 形式嵌套在 tool_calls 字段中。
每个工具调用包含 id、function.name(工具名称)和 function.arguments(参数) 。
其他可选解析器:default:vLLM 原生格式(可能兼容性较差)。自定义解析器(需扩展 vLLM 代码)。
更多可选参数可查阅:
https://vllm.hyper.ai/docs/models/engine-arguments/
请求验证可以用postman
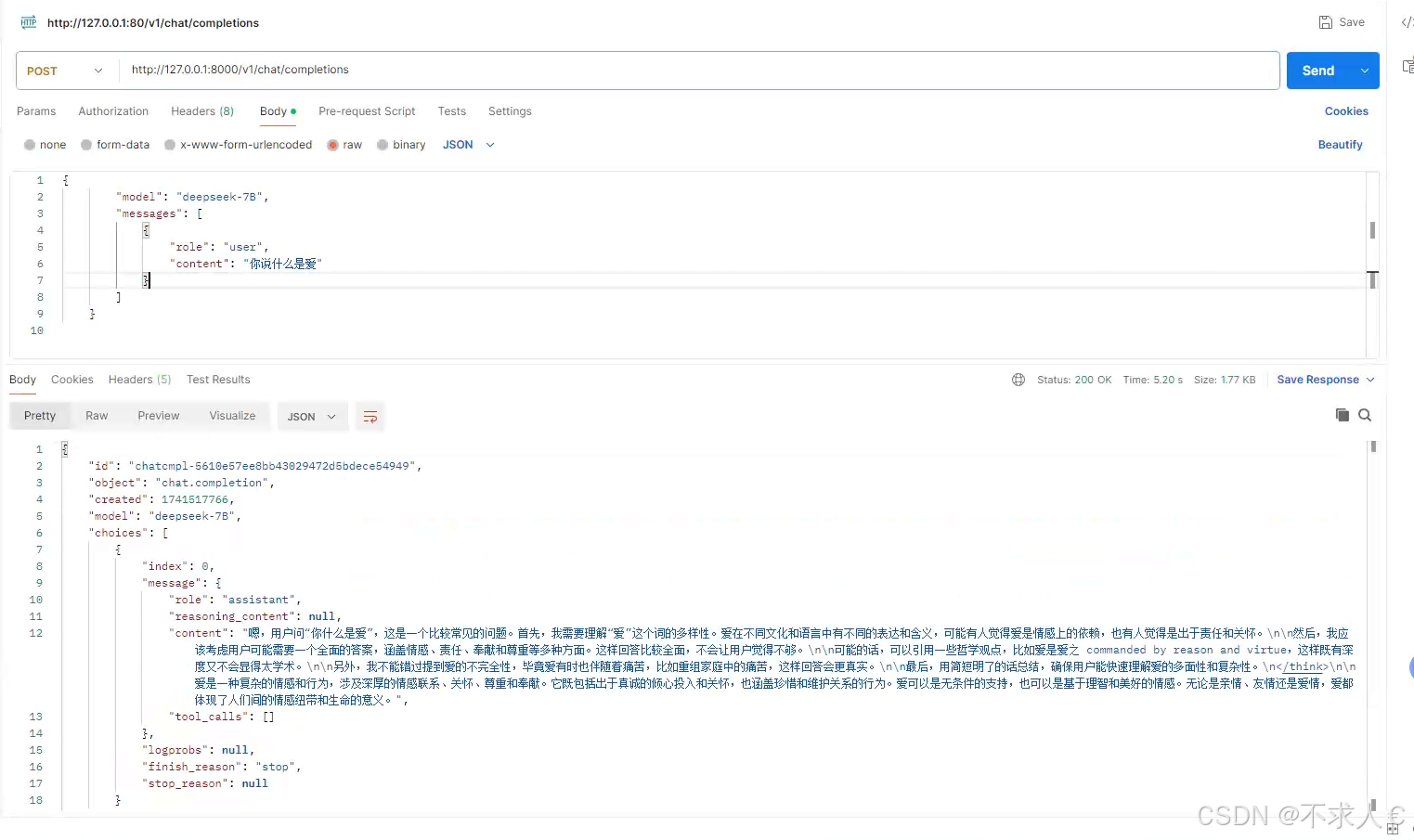
参数如下
{
"model": "deepseek-7B",
"messages": [
{
"role": "user",
"content": "你说什么是爱"
}
]
}
"model": "deepseek-7B",和vllm启动时的 --served-model-name 值保持一致。
完工撒花撒花!!!!







