Ubuntu24.04环境部署大模型【Ollama+Dify+Xinference】
本篇文章旨在记录Ubuntu24.04下基于Docker运行Dify+Ollama+Xinference部署本地大模型工程,仅供参考。
目录
一、概述
二、部署前操作
2.1 卸载系统自带显卡驱动
2.2 安装显卡驱动
2.3 安装nvidia-container-toolkit服务
编辑
2.4 安装Docker服务
三、安装部署服务
3.1、部署Ollama服务
3.1.1 脚本一键部署
3.1.2 手动部署
3.1.3 Ollama常用命令
3.2 部署Dify服务
3.2.1 下载Dify,使用Docker运行
编辑 3.2.2 添加模型
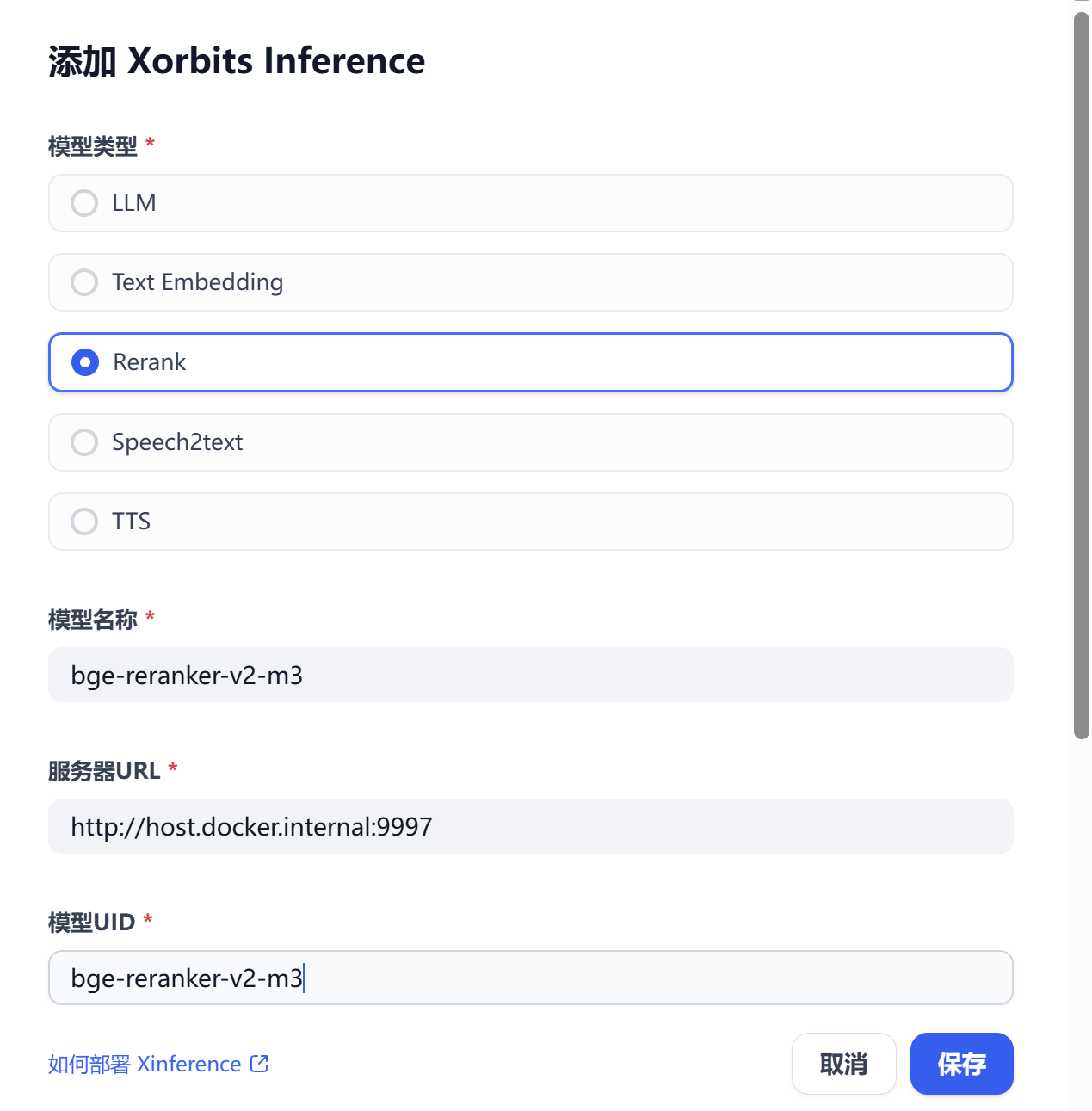
3.3 部署Xinference服务
一、概述
操作系统环境:
cat /etc/os-release
PRETTY_NAME="Ubuntu 24.04.2 LTS"
NAME="Ubuntu"
VERSION_ID="24.04"
VERSION="24.04.2 LTS (Noble Numbat)"
VERSION_CODENAME=noble
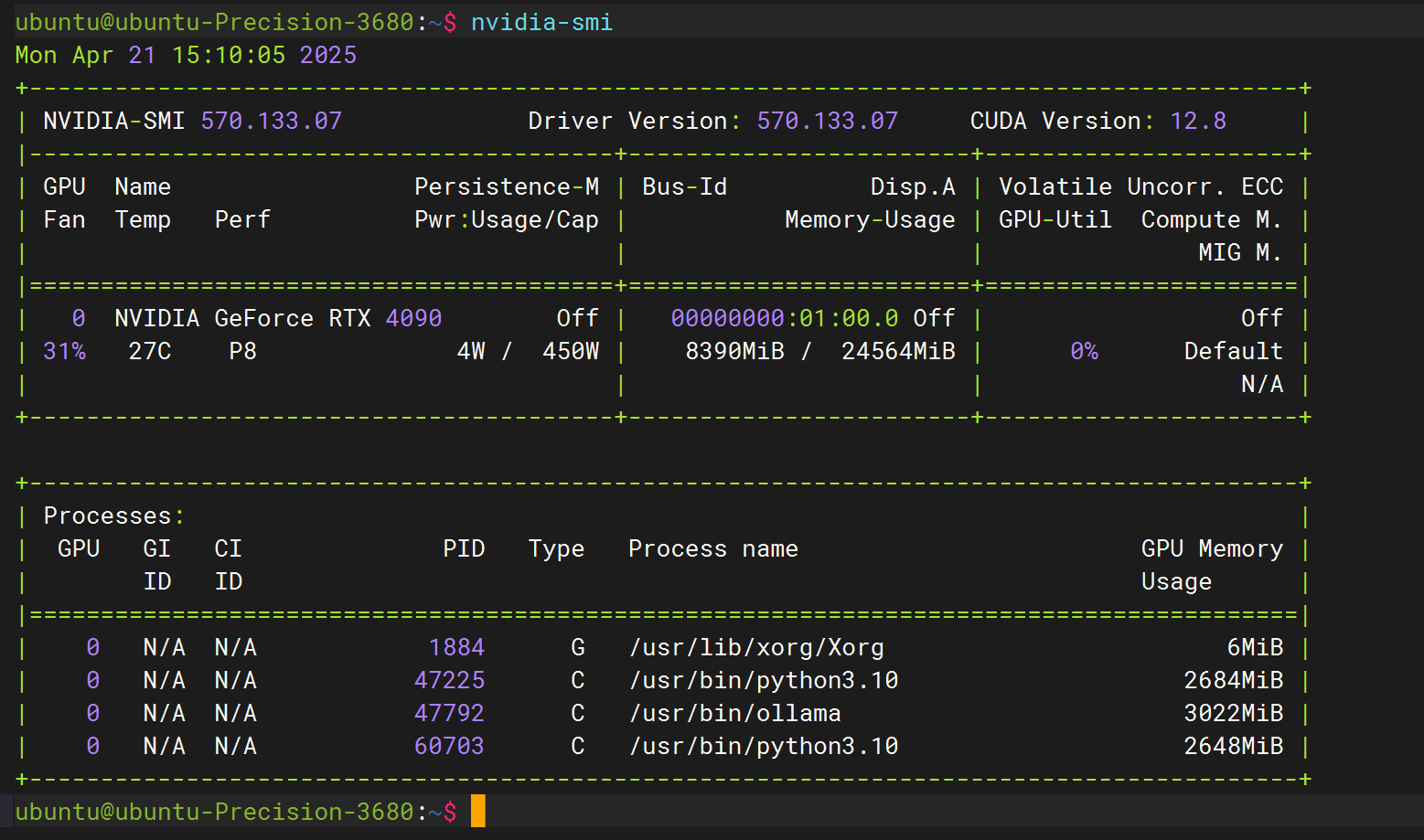
ID=ubuntu显卡:NVIDIA GeForce RTX 4090
Ollama:版本 0.6.5
作用:Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
Dify:版本1.1.3
Dify 是一个开源的大语言模型(LLM)应用开发平台,它致力于为开发者提供一站式、低代码甚至无代码的 AI 应用开发体验。
Xinference: v1.4.0
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。
二、部署前操作
2.1 卸载系统自带显卡驱动
# 卸载系统自带驱动
sudo apt-get --purge remove nvidia*
sudo apt autoremove
# 禁用系统自带的nouveau nvidia驱动
sudo vim /etc/modprobe.d/blacklist.conf
# --------在配置文件最后添加下列参数--------#
blacklist nouveau
options nouveau modeset=0
# 更新系统参数
sudo update-initramfs -u
# 查看系统是否屏蔽成功,如果没有结果返回,即屏蔽成功
lsmod | grep nouveau
2.2 安装显卡驱动
# 方式1:使用系统工具自动安装
# 使用这个方法会安装带有recommended字段的驱动,即推荐的驱动
ubuntu-drivers devices
sudo ubuntu-drivers autoinstall
# 方式2:
# 或者你想要安装特定版本的驱动,你只需要这样
ubuntu-drivers devices
sudo apt install nvidia-driver-550
# 使用apt命令再加上上面"ubuntu-drivers devices"里列表任意一个驱动
# 方式3:手动下载驱动文件,并手动安装
sudo apt install gcc & make
# 驱动下载地址:https://www.nvidia.cn/geforce/drivers/
wget https://cn.download.nvidia.cn/XFree86/Linux-x86_64/570.144/NVIDIA-Linux-x86_64-570.144.run
# 执行安装
sudo chmod a+x NVIDIA-Linux-x86_64-570.133.07.run
sudo ./NVIDIA-Linux-x86_64-570.133.07.run -no-x-check -no-nouveau-check -no-opengl-files
# -no-x-check: 安装时关闭X服务;
# -no-nouveau-check: 安装时禁用nouveau;
# -no-opengl-files: 只安装驱动文件,不安装OpenGL文件。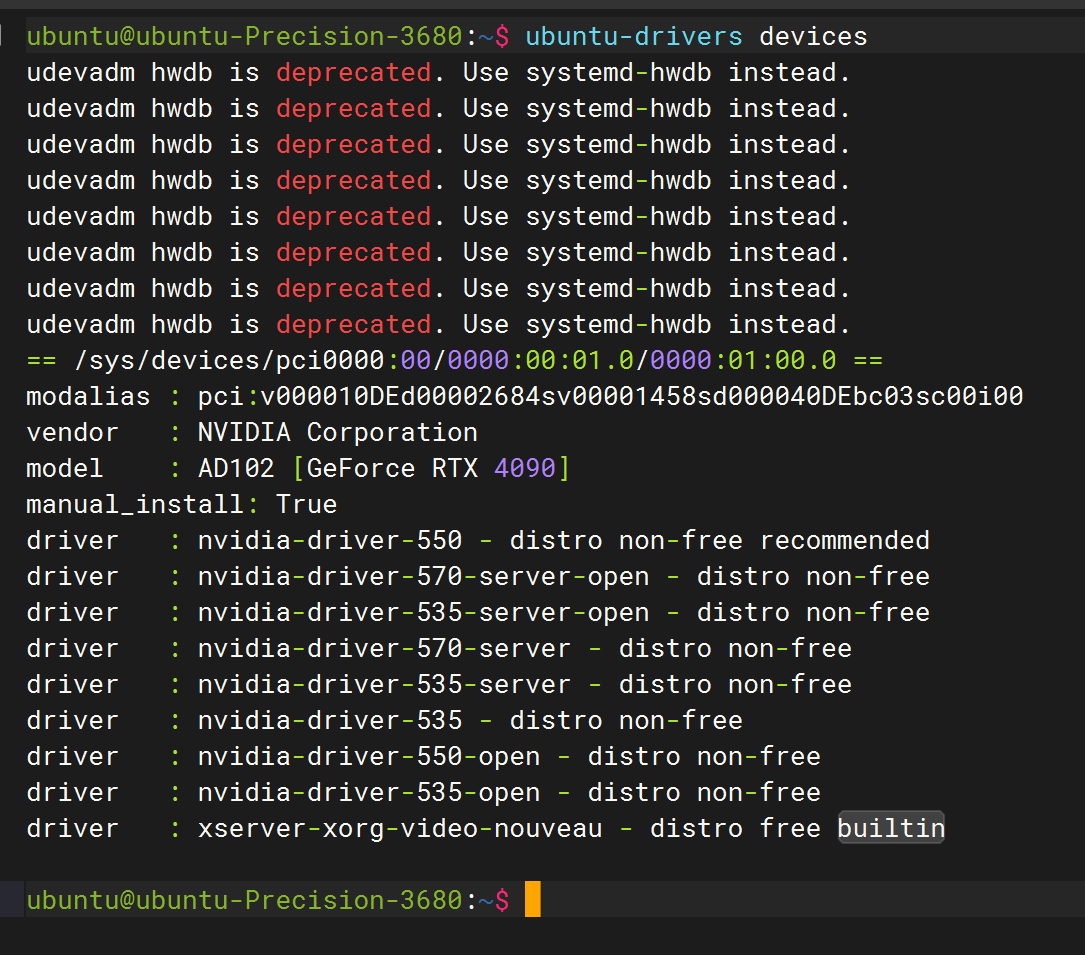
如果遇到报错:NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
解决方法:重启进入BIOS,关闭secure boot
2.3 安装nvidia-container-toolkit服务
# 1. 配置源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# (可选)配置存储库以使用实验包:
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 2. 更新列表
sudo apt-get update
# 3. 安装
sudo apt-get install -y nvidia-container-toolkit
#安装完成后重启服务器
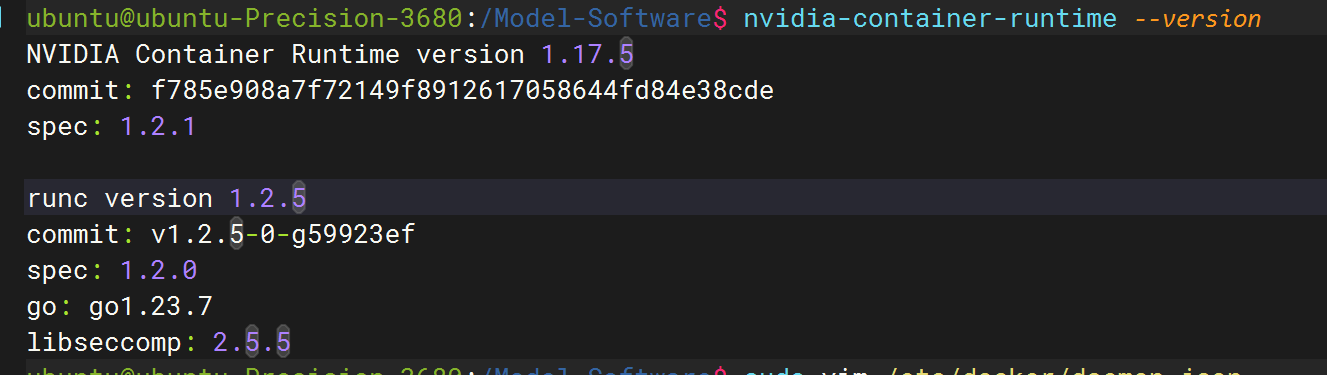
2.4 安装Docker服务
#安装依赖包
sudo apt-get install ca-certificates curl gnupg lsb-release
##安装docker官方秘钥
sudo curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
#添加docker源
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
#安装docker
sudo apt-get install docker-ce docker-ce-cli containerd.io
# 设置开机启动和启动服务
sudo systemctl enable docker & sudo systemctl start docker 三、安装部署服务
3.1、部署Ollama服务
3.1.1 脚本一键部署
sudo curl -fsSL https://ollama.com/install.sh | sh3.1.2 手动部署
#下载并解压与操作系统匹配的安装包
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
#启动 Ollama并验证
sudo ollama serve
# 查看版本
sudo ollama -v
# 将 Ollama 添加为自启动服务(推荐)
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
# 在该位置:/etc/systemd/system/ollama.service 创建服务文件
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH" #修改成你想要存储的位置
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target
# 加载服务
sudo systemctl daemon-reload
# 设置成开机启动
sudo systemctl enable ollama & sudo systemctl start ollama3.1.3 Ollama常用命令
| 可用命令 | 解释 | 可用命令 | 解释 |
| serve | 启动 ollama 服务。 | stop | 停止一个正在运行的模型。 |
| create | 根据一个 Modelfile 创建一个模型。 | pull | 从一个模型仓库(registry)拉取一个模型。 |
| show | 显示某个模型的详细信息。 | push | 将一个模型推送到一个模型仓库。 |
| run | 运行一个模型。 | list | 列出所有模型。 |
| ps | 列出所有正在运行的模型。 | rm | 删除一个模型。 |
| cp | 复制一个模型。 | help | 获取关于任何命令的帮助信息。 |
Ollama 指定源拉取模型,以魔塔社区为例
ollama run modelscope.cn/Qwen/QwQ-32B-GGUF:q4_k_m查看模型详细内容,使用命令ollama show 模型名称
ubuntu@ubuntu:~$ ollama show deepseek-r1:14b
Model
architecture qwen2 # 模型架构
parameters 14.8B # 参数量
context length 131072 # 上下文长度
embedding length 5120 # 嵌入维度
quantization Q4_K_M # 量化方式
3.2 部署Dify服务
3.2.1 下载Dify,使用Docker运行
#下载dify
https://github.com/langgenius/dify
#修改.env文件
cp .env.example .env
#执行启动命令
docker compose -f docker-compose.yaml -p dify up -d
 3.2.2 添加模型
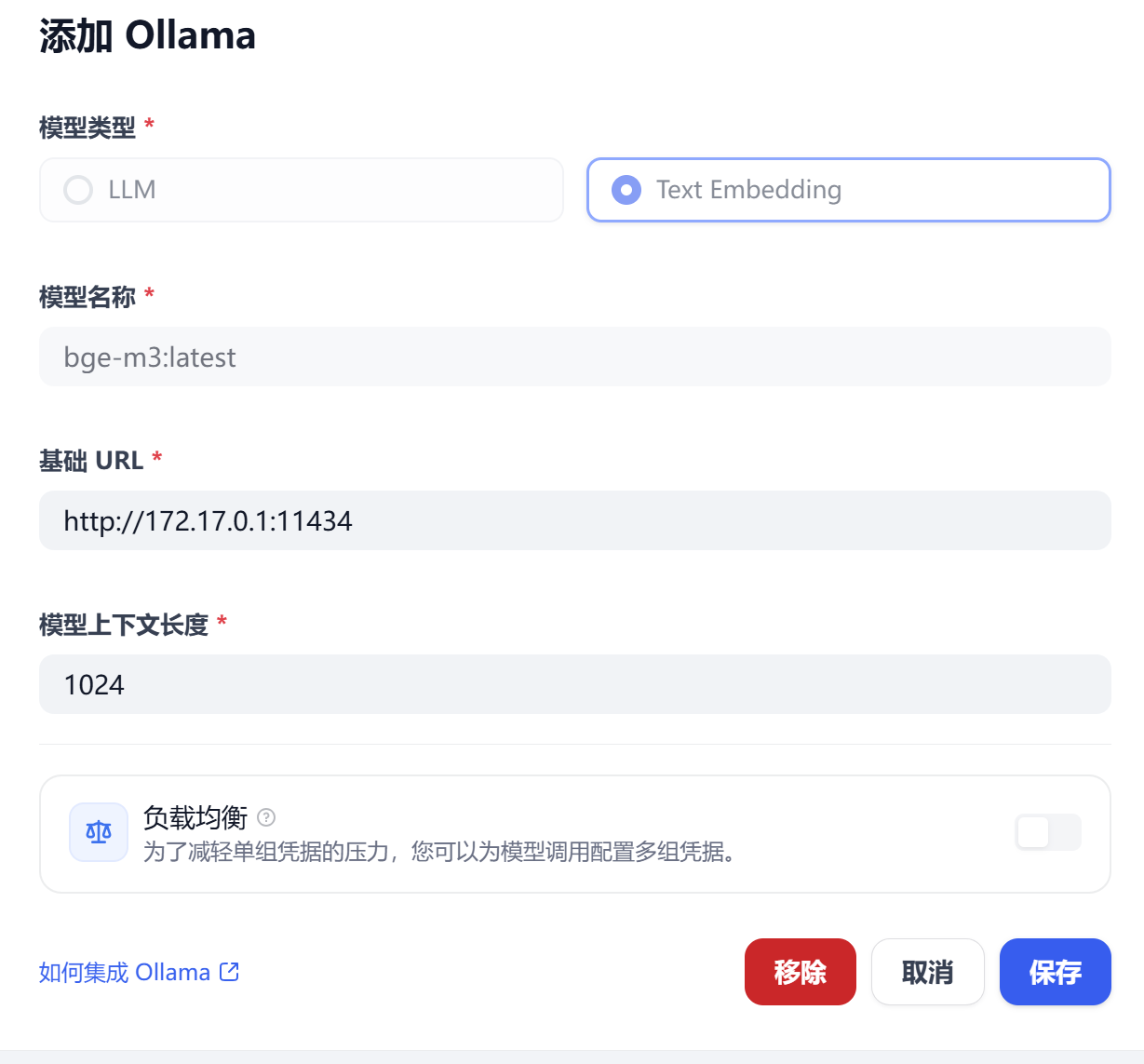
3.2.2 添加模型
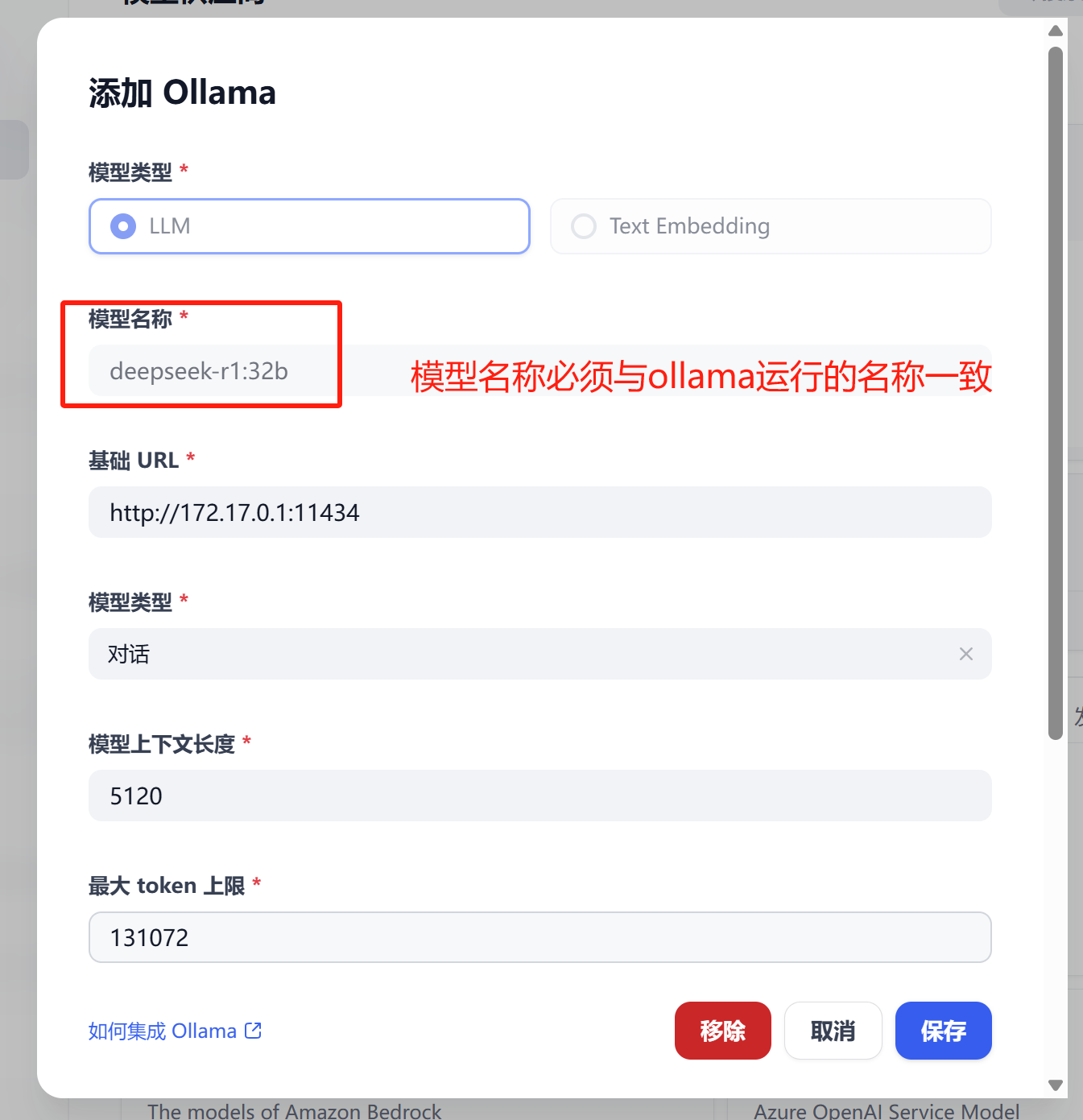
Dify添加模型时,模型名称必须与Ollama模型名称一致,不然会无法添加。查看模型名称可以使用命令:ollama list
3.3 部署Xinference服务
本次部署Xinference服务,是用于运行Rerank模型,以增加知识库检索和召回能力。,
# 下载容器
docker pull xprobe/xinference
# 运行容器
sudo docker run -d --name xinference --gpus all
-v /Model-Software/Xinference/models:/root/models
-v /Model-Software/Xinference/.xinference:/root/.xinference
-v /Model-Software/Xinference/.cache/huggingface:/root/.cache/huggingface
-e XINFERENCE_HOME=/root/models -p 9997:9997
--restart=always xinference:latest xinference-local -H 0.0.0.0
# -v /Model-Software/Xinference/models:/root/models 将宿主机目录挂载到宿主机,目录路径和名称可以按照自己的环境去定义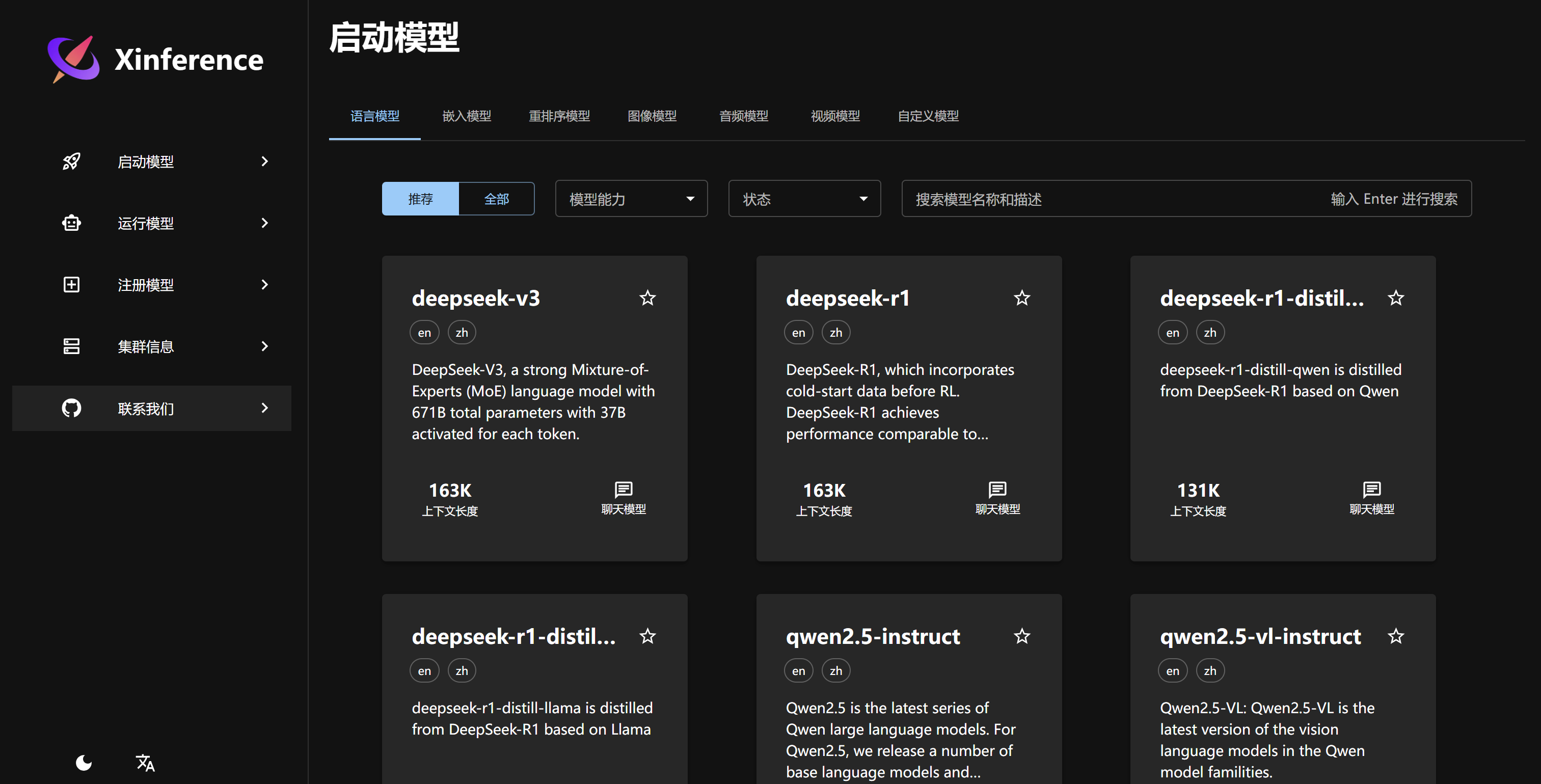
下载模型可以选择国内的魔塔社区,Huggingface需要科学上网才可以下载。点击下载后不要刷新页面,可以通过一下命令观察下载进度。
docker logs -f # 你的容器名称
docker logs -f xinference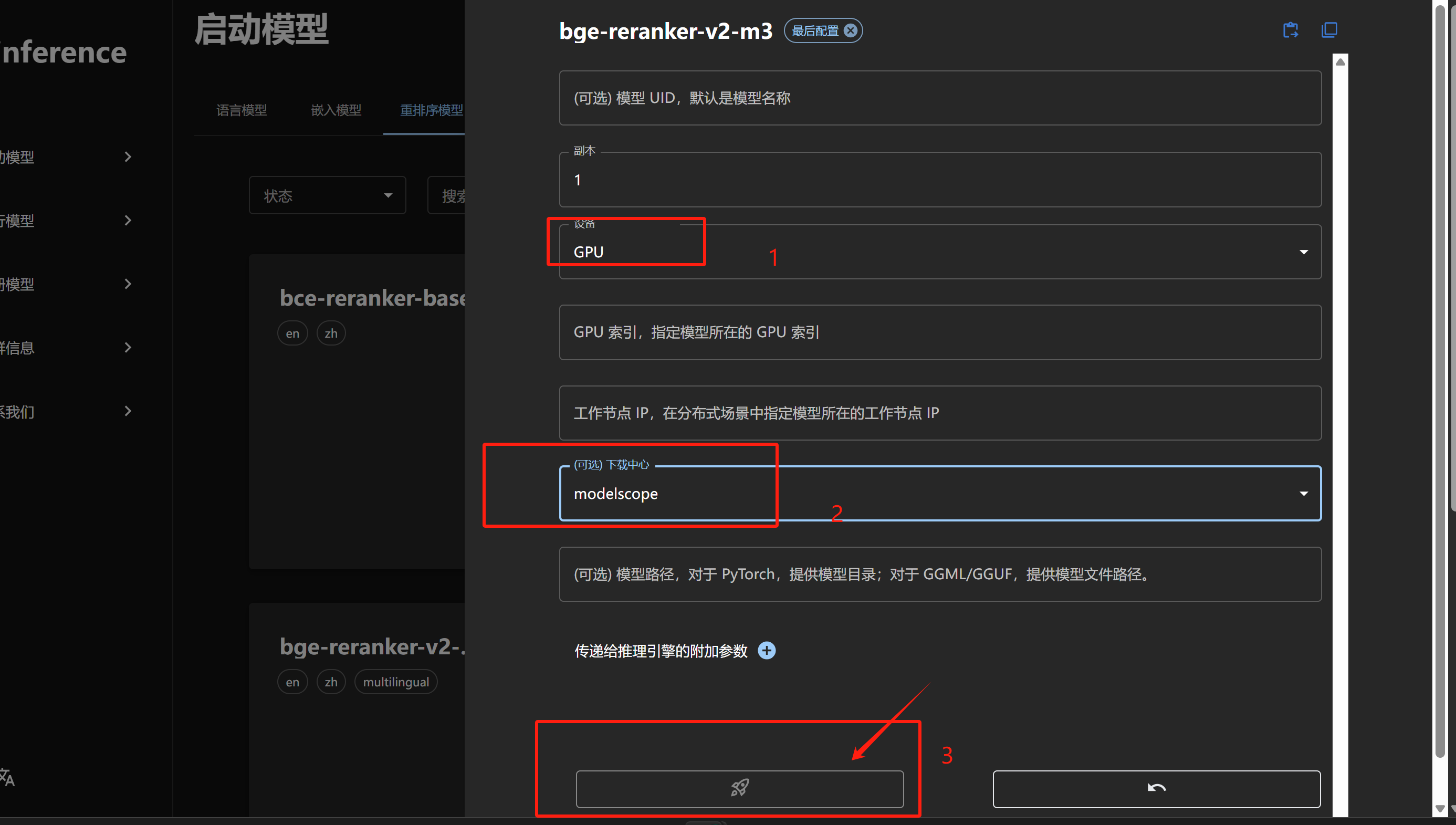

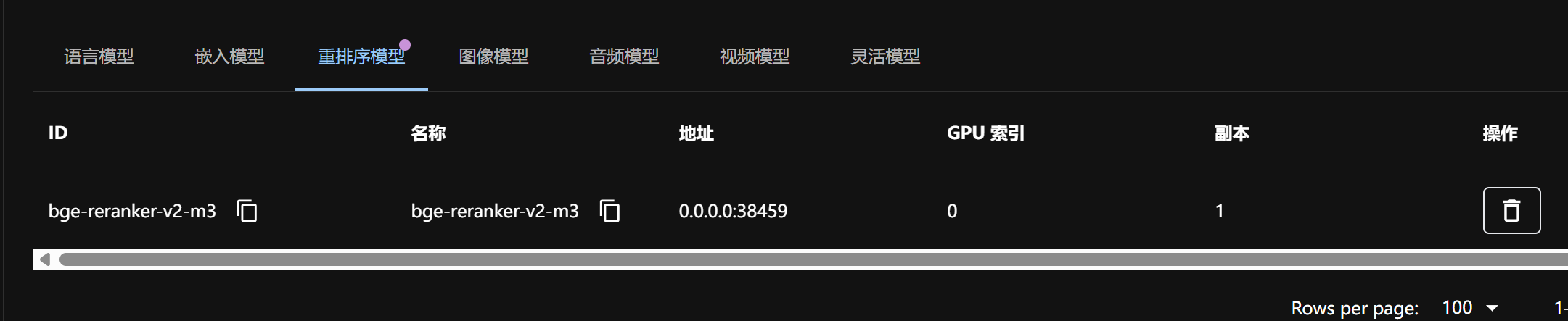
每次重启Docker或者系统后,Xinference都需要登录Web页面手动启动模型。当前此问题我查了很多文章,暂时没发现有什么好的解决办法。如果大家有方法解决这个问题,麻烦也告诉我一下。感谢。
Dify添加Xinference模型