


vllm(docker版)框架,运行Qwen2.5-VL-7B-Instruct图片转文字
前言:
使用ollama运行的大模型接入dify,发现视觉能力未达到预期(可能是找的模型不对、dify配置问题等)。故转入huggingface,寻找相关的大模型库——Qwen2.5-VL-7B-Instruct(使用了在线版,效果还行)
尝试过通过llama.cpp对源模型仓库进行转换,转换成GGUF文件供ollama运行,但是好像转的不对。兜兜转转,最后到了docker上
直接运行huggingface大模型,环境复杂,不同的硬件、操作系统、版本驱动、插件依赖可能都会有影响,为了排除这些因素,使用docker进行安装部署
参考链接:
python运行测试:https://www.aivi.fyi/llms/deploy-Qwen2.5-VL
(↑本来是准备直接搬这个vllm,但是环境太复杂,没走通,就用了python调用的脚本)
docker安装:https://zhuanlan.zhihu.com/p/14946515577
docker运行vllm:
- https://blog.csdn.net/yuanlulu/article/details/145579118
- https://blog.csdn.net/m0_59235945/article/details/146471014
准备工作
操作系统软硬件配置
内存:64G
硬盘:1.5T 挂在至/home目录
显卡:NVIDIA GeForce RTX 4090(24G) x2
操作系统:CentOS 7.9.2009
nvidia 驱动版本:550.142
cuda版本:12.4
Nvidia驱动安装(根据自身系统选择)
https://developer.nvidia.com/cuda-12-4-1-download-archive?target_os=Linux&target_arch=x86_64&Distribution=CentOS&target_version=7&target_type=runfile_local
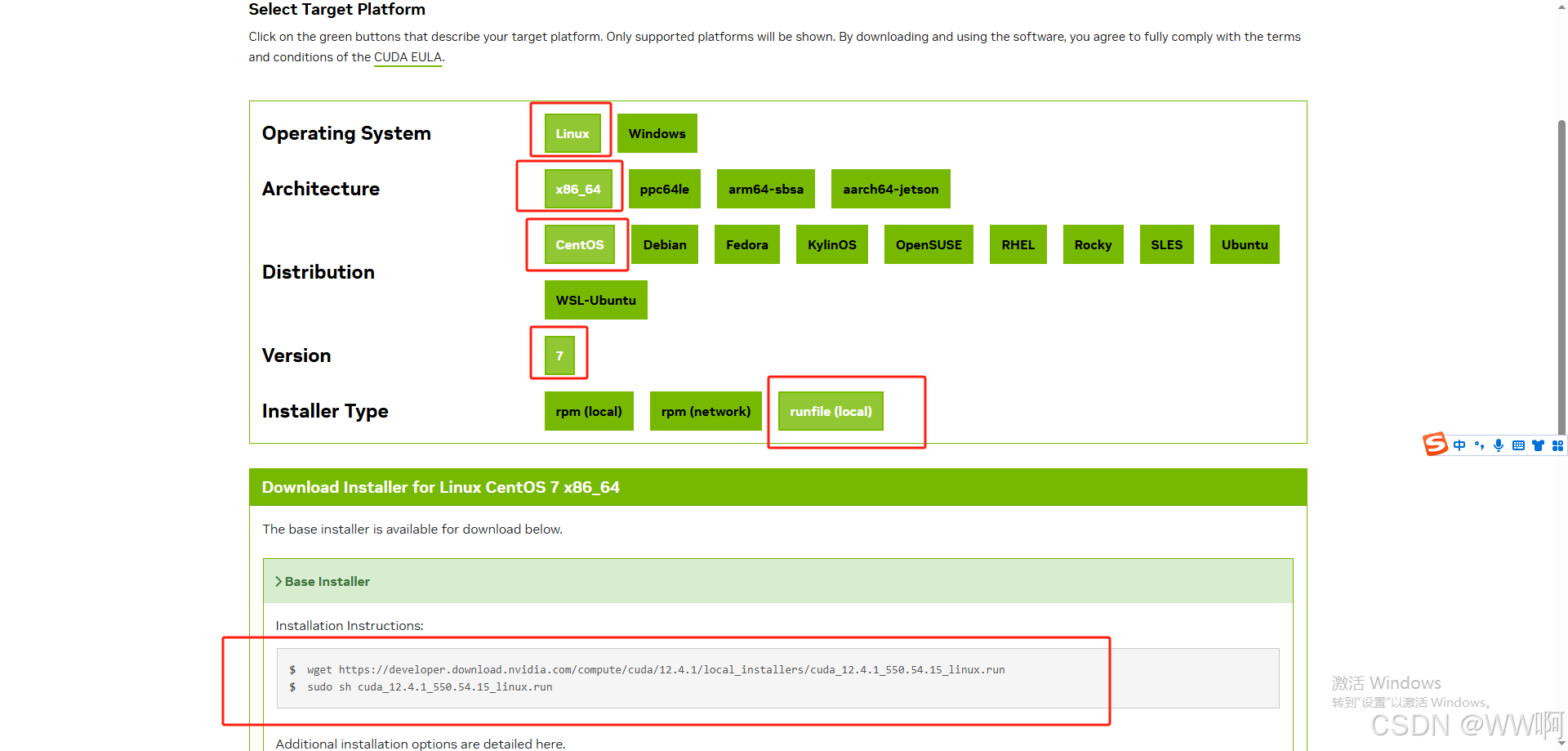
下载完成后,执行脚本,就能安装了(nvidia-smi能执行、nvcc --version不能执行的情况,安装时就装toolkit即可.)
huggingface模型文件拉取
可以用hfd.sh,需要配置,可以另外查询文档
国内镜像地址:https://hf-mirror.com/(也可以去modelscope等其他模型网站)
也可以粗暴地直接用迅雷下载,上传至服务器
二、安装配置docker
sudo yum update
##移除旧版本docker
sudo yum remove docker docker-common docker-selinux docker-engine
##安装Docker所需要的一些工具包
sudo yum install -y yum-utils
##安装docker
sudo yum install docker-ce docker-ce-cli containerd.io
##添加英伟达docker仓库
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
##安装nvidia-docker
sudo yum install -y nvidia-docker2
##新建文件夹存储docker数据
mkdir -p /home/docker-data
##查看配置
cat /etc/docker/daemon.json
##添加容器镜像加速、容器nvidia支持
vim /etc/docker/daemon.json
Docker daemon.json配置参考
{
"registry-mirrors": [
"https://registry.docker-cn.com",
......
],
"data-root": "/home/docker-data",
"dns": [
"8.8.8.8",
"8.8.4.4"
],
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
三、运行vllm/vllm-openai:latest()
##镜像比较大16G多,还是先拉下来再运行
docker pull vllm/vllm-openai:latest
##大概需要16g内存
docker run --runtime nvidia --gpus all --name vllm-qwen2.5-vl-7b
-v /home/models:/home/models
-p 8001:8000
--ipc=host
-d
vllm/vllm-openai:latest
--model /home/models/Qwen2.5-VL-7B-Instruct
--served-model-name "Qwen2.5-VL-7B-Instruct"
--max-num-batched-tokens 8192
--max-num-seqs 256
--tensor-parallel-size 2 ##根据显卡数量
--max_model_len 16384
四、Python脚本测试Qwen2.5-VL-7B-Instruct
import base64
from openai import OpenAI
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# 初始化 OpenAI 客户端
client = OpenAI(
base_url="http://localhost:8001/v1",
api_key="NOT_NEED"
)
# 本地图片路径
image_path = "/home/test.png"
# 编码图片
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="Qwen2.5-VL-7B-Instruct",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "图片描述了哪些内容,请帮我全部详细的列出具体内容?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
max_tokens=8096,
)
print(response.choices[0])









