【MapReduce入门】深度解析MapReduce:定义、核心特点、优缺点及适用场景
目录
1 什么是MapReduce?
2 MapReduce的核心特点
2.1 分布式处理
2.2 容错机制
3 MapReduce的完整工作流程
4 MapReduce的优缺点分析
4.1 优势
4.2 局限性
5 MapReduce典型应用场景
5.1 适用场景
5.2 不适用场景
6 MapReduce与其他技术的对比
7 总结
1 什么是MapReduce?
MapReduce是一种用于大规模数据集(大于1TB)并行运算的编程模型,由Google在2004年提出,主要用于解决海量数据的分布式计算问题。它将复杂的、运行于大规模集群上的并行计算过程高度抽象为两个函数:Map和Reduce。

- 输入数据:原始数据被分割成多个小块
- Map阶段:并行处理输入数据块,生成中间键值对
- Shuffle阶段:将相同key的中间结果传输到同一个Reducer
- Reduce阶段:对相同key的值进行归约处理
- 输出结果:生成最终计算结果
2 MapReduce的核心特点
2.1 分布式处理
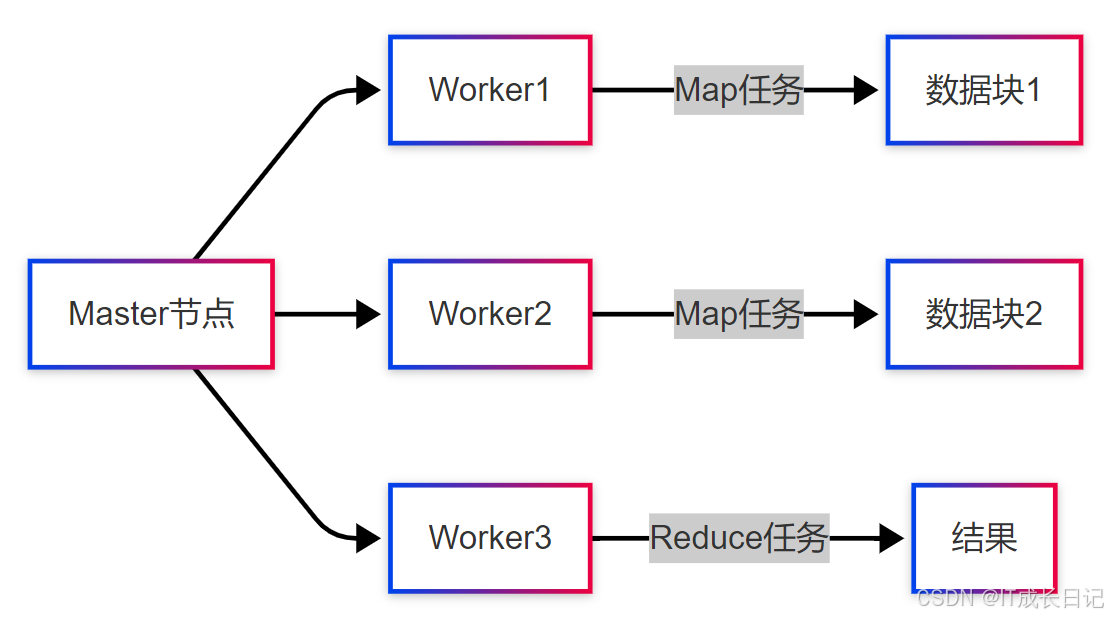
- 主从架构:1个Master节点管理多个Worker节点
- 数据本地化:计算向数据移动,而非数据向计算移动
- 自动并行化:框架自动处理并行执行和任务调度
2.2 容错机制

- 任务失败自动重新调度
- 定期心跳检测Worker节点状态
- 数据多副本存储保证可靠性
3 MapReduce的完整工作流程
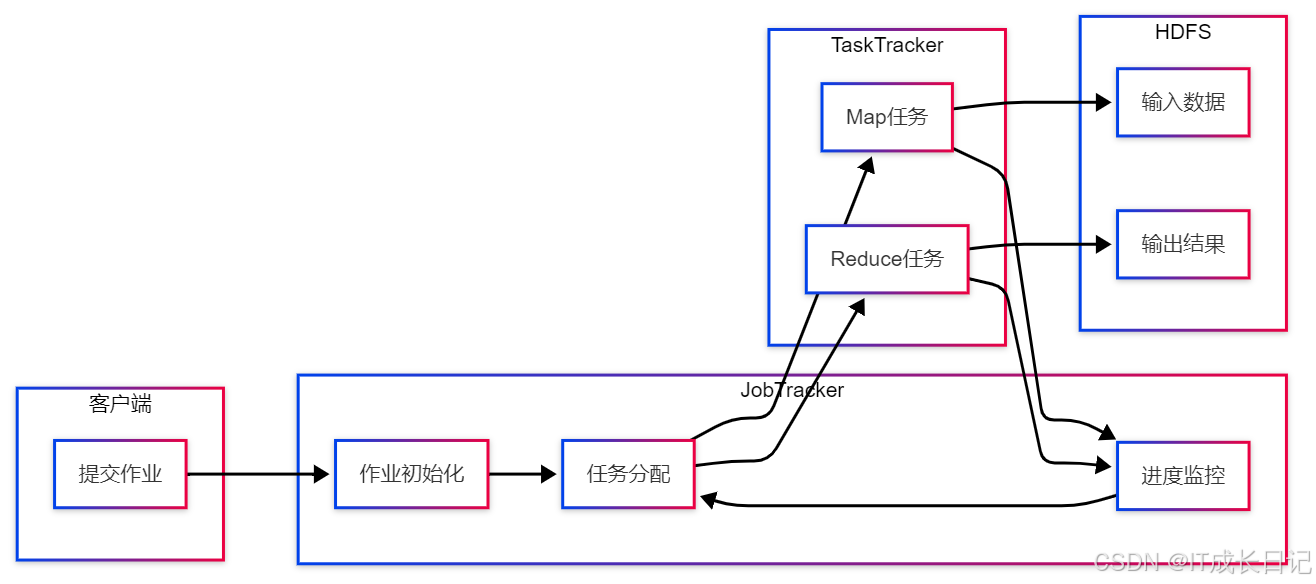
- 作业提交:客户端提交MapReduce作业
- 作业初始化:JobTracker创建作业并分配ID
- 输入分片:计算输入数据的划分方式
- 任务分配:将Map和Reduce任务分配给空闲TaskTracker
- 执行Map阶段:TaskTracker执行Map任务,读取输入数据
- Shuffle阶段:Map输出经过排序、合并后传输给Reducer
- 执行Reduce阶段:处理中间结果,生成最终输出
- 作业完成:JobTracker收到所有任务完成通知后标记作业成功
4 MapReduce的优缺点分析
4.1 优势
| 优点 | 说明 |
| 易于编程 | 只需关注业务逻辑,无需处理并行细节 |
| 良好扩展性 | 可线性扩展到数千节点 |
| 高容错性 | 自动处理节点失败 |
| 高吞吐量 | 适合批处理海量数据 |
4.2 局限性
- 不适合低延迟场景:批处理模型导致较高延迟
- 中间结果写磁盘:Shuffle阶段产生大量I/O开销
- 表达能力有限:复杂算法难以用MapReduce表达
- 资源利用率低:Map和Reduce阶段资源无法动态调整
5 MapReduce典型应用场景
5.1 适用场景
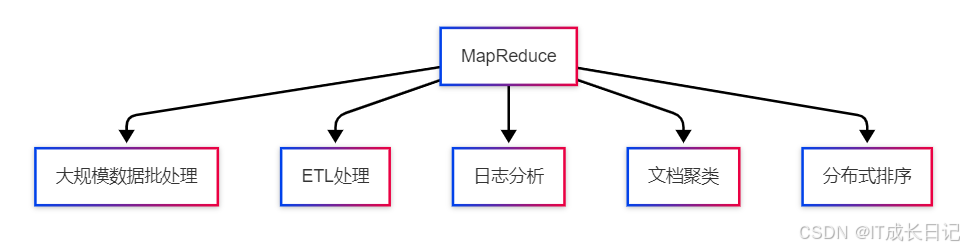
- 海量数据批处理:如网站日志分析、数据仓库ETL
- 分布式排序:如搜索引擎倒排索引构建
- 机器学习:如PageRank算法实现
- 数据挖掘:如关联规则挖掘
5.2 不适用场景
- 实时计算(考虑Storm/Flink)
- 迭代计算(考虑Spark)
- 流式计算(考虑Spark Streaming/Flink)
- 交互式查询(考虑Hive/Impala)
6 MapReduce与其他技术的对比
| 技术 | 处理模型 | 延迟 | 适用场景 |
| MapReduce | 批处理 | 高 | 离线大规模数据处理 |
| Spark | 微批/内存计算 | 中 | 迭代计算、机器学习 |
| Flink | 流处理 | 低 | 实时计算、事件驱动 |
| Storm | 流处理 | 极低 | 实时消息处理 |
7 总结
MapReduce作为大数据处理的基石技术,虽然在某些场景下已被更先进的计算框架取代,但其设计思想和编程模型仍然深刻影响着大数据生态系统。理解MapReduce的原理和特点,对于学习后续的大数据技术如Spark、Flink等具有重要意义。
本文地址:https://www.vps345.com/10439.html
上一篇:Node和npm初学