最新Ktransformers v0.24(Docker)并发部署DeepSeek-V3-0324模型
一、介绍
KTransformers v0.2.4
发布说明
我们非常高兴地宣布,期待已久的
KTransformers v0.2.4
现已正式发布!在这个版本中,我们对整 体架构进行了重大重构,更新了超过 1
万行代码,为社区带来了备受期待的多并发支持。
本次重构借鉴了
sglang
的优秀架构,在
C++
中实现了高性能的异步并发调度机制,支持如
连续批
处理
、
分块预填充(
chunked prefill
)
等特性。由于支持并发场景下的
GPU
资源共享,整体吞吐量也 在一定程度上得到了提升。
1.
多并发支持
新增对多个并发推理请求的处理能力,支持同时接收和执行多个任务。 我们基于高性能且灵活的算子库 flashinfer
实现了自定义的
custom_flashinfer
,并实现了
可变
批大小(
variable batch size
)
的
CUDA Graph
,这在提升灵活性的同时,减少了内存和
padding的开销。 在我们的基准测试中,4 路并发下的整体吞吐量提升了约
130%
。 在英特尔的支持下,我们在最新的 Xeon6 + MRDIMM-8800
平台上测试了
KTransformers v0.2.4。通过提高并发度,模型的总输出吞吐量从
17 tokens/s
提升到了
40 tokens/s
。我们观察到当前瓶颈已转移至 GPU
,使用高于
4090D
的显卡预计还可以进一步提升性能。
2.
引擎架构优化
借鉴
sglang
的调度框架,我们通过更新约
11,000
行代码
,将
KTransformers
重构为一个更清晰的 三层架构,并全面支持多并发:
Server
(服务层)
:处理用户请求,并提供兼容
OpenAI
的
API
。
Inference Engine
(推理引擎)
:负责模型推理,支持分块预填充。
Scheduler
(调度器)
:管理任务调度与请求编排。通过
FCFS
(先来先服务)方式组织排队请求, 打包为批次并发送至推理引擎,从而支持连续批处理。
3.
项目结构重组
所有
C/C++
代码现已统一归类至
/csrc
目录下。
4.
参数调整
我们移除了一些遗留和已弃用的启动参数,简化了配置流程。未来版本中,我们计划提供完整的参数列表和详细文档,以便用户更灵活地进行配置与调试。
二、安装Ktransformers
1.下载docker镜像与启动
# 拉镜像
docker pull approachingai/ktransformers:v0.2.4-AVX512
# 启动
docker run -it --gpus all --privileged --shm-size 64g --name kt --network=host -v /data:/data approachingai/ktransformers:v0.2.4-AVX512 /bin/bash
# 打开一个新终端
docker exec -it kt bash
2.通过魔搭社区下载模型
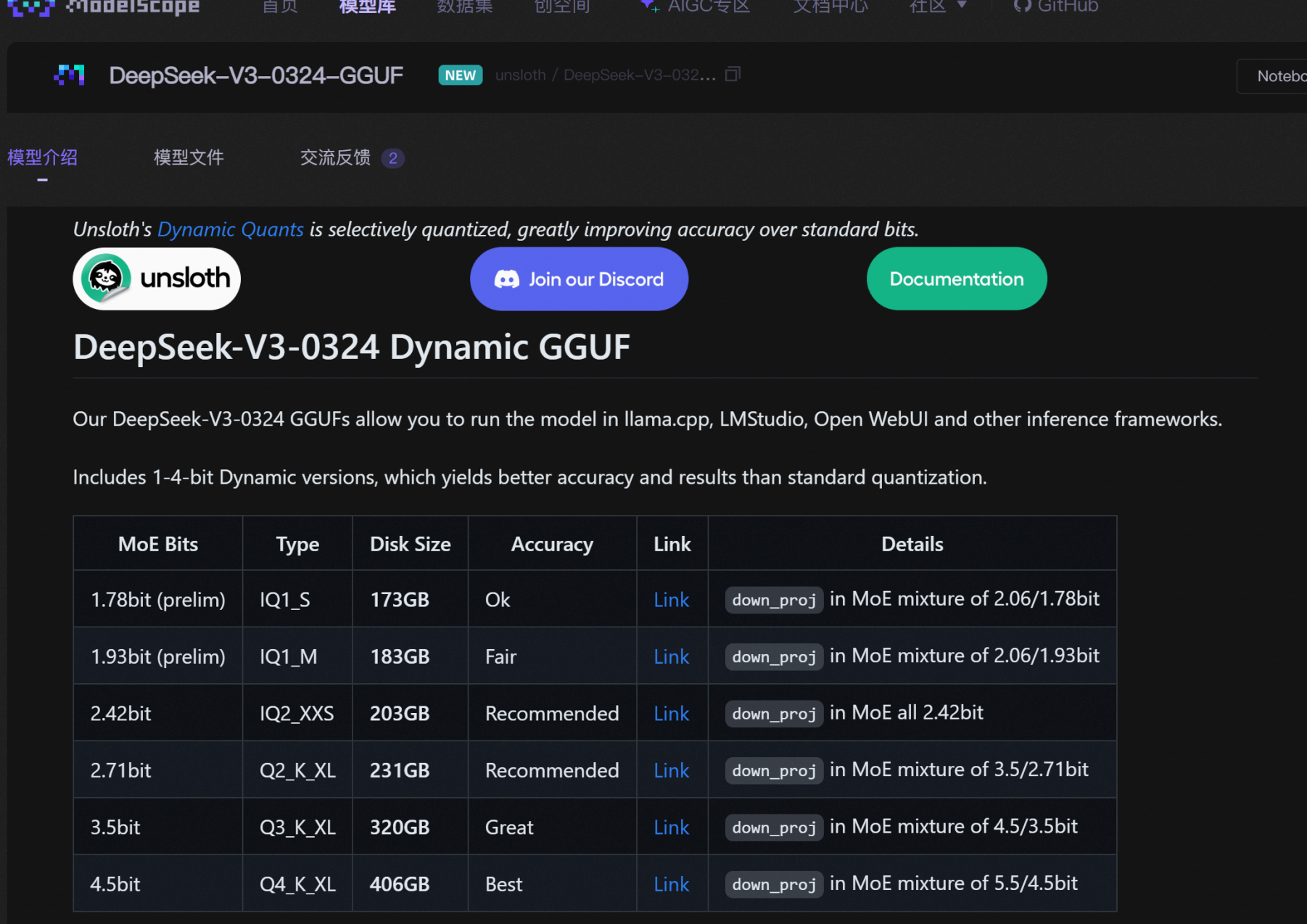
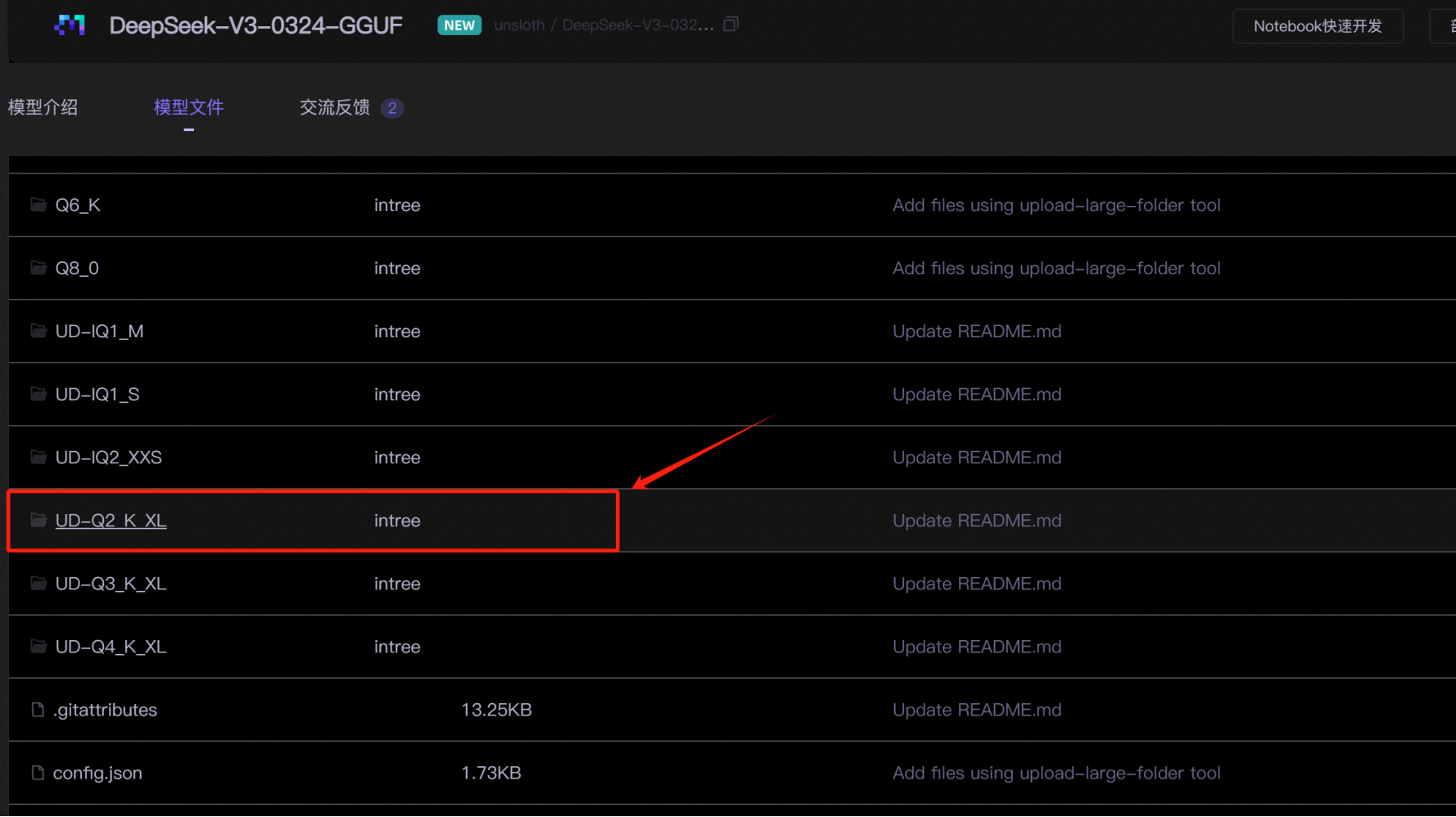
本次实验使用官方推荐的
DeepSeek-V3-0324 Q2_K_XL
(
1.58bit
模型目前不太稳定)模型,该模型也是目前最稳定的动态量化模型,需要14G
显存
+170G
内存即可调用。
魔搭社区下载地址:
https://www.modelscope.cn/models/unsloth/DeepSeek-V3-0324-GGUF/su
mmary
mkdir ./DeepSeek-V3-0324-GGUF
# 下载模型
modelscope download --model unsloth/DeepSeek-V3-0324-GGUF --include
'**Q2_K_XL**' --local_dir /data/model/DeepSeek-V3-0324-GGUF/
mkdir ./DeepSeek-V3-0324
# 下载模型配置文件
modelscope download --model deepseek-ai/DeepSeek-V3-0324 --exclude
'*.safetensors' --local_dir /data/model/DeepSeek-V3-0324/
三、利用Ktransformers启动模型
在安装完成了
KTransformer v0.24
,并下载好了模型权重和相应的模型配置之后,接下来即可尝试进行调用了。KTransformer v0.24
支持两种调用方法,分别借助
local_chat.py
进行命令行本地对话,以及实用 server/main.py
开启服务,然后在默认
10002
端口进行
OpenAI
风格的
API
调用。这里我们重点尝试使用后端服务模式调用DeepSeek
模型。
# 进去docker容器
docker exec -it kt /bin/bash
# 启动模型
python ktransformers/server/main.py
--port 10002
--model_path /data/model/DeepSeek-V3-0324
--gguf_path /data/model/DeepSeek-V3-0324-GGUF/UD-Q2_K_XL
--max_new_tokens 1024
--cache_lens 32768
--chunk_size 256
--max_batch_size 4
--backend_type balance_serve
四、客户端调用
1. linux curl调用
curl -X POST http://localhost:10002/v1/chat/completions
-H "accept: application/json"
-H "Content-Type: application/json"
-d '{
"messages": [
{"role": "user", "content": "你好,好久不见"}
],
"model": "DeepSeek-V3-0324",
"temperature": 0.3,
"top_p": 1.0,
"stream": true
}' 
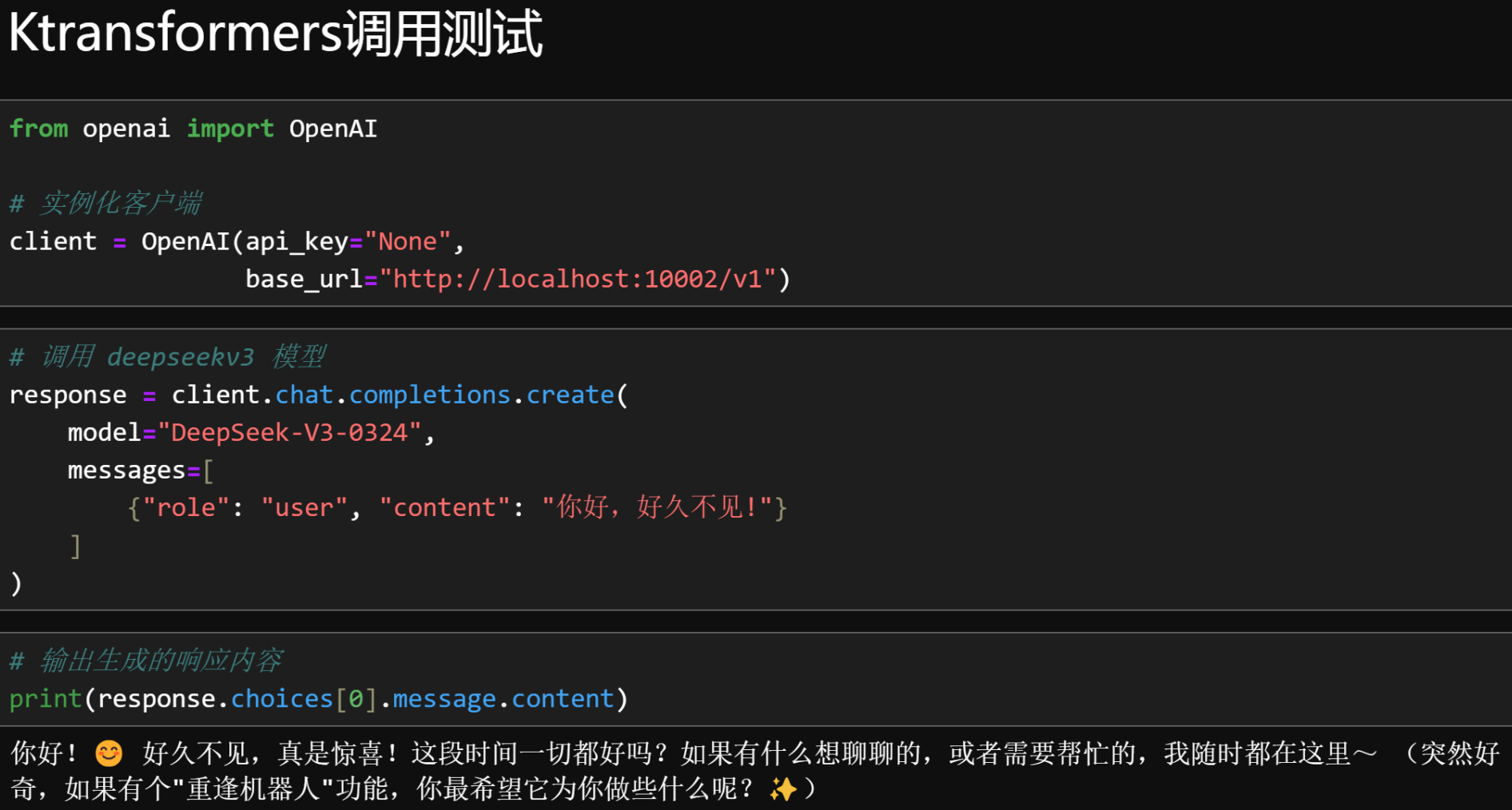
2.代码调用
from openai import OpenAI
# 实例化客户端
client = OpenAI(api_key="None",
base_url="http://localhost:10002/v1")
# 调用 deepseekv3 模型
response = client.chat.completions.create(
model="DeepSeek-V3-0324",
messages=[
{"role": "user", "content": "你好,好久不见!"}
]
)
# 输出生成的响应内容
print(response.choices[0].message.content)