


使用Docker和Bitnami镜像快速搭建本地Kafka环境
一、前言
随着即将到来的Kafka 4.0的发布,Zookeeper将会完全淘汰,只有KRaft模式将得到支持。这一重大变化需要项目和开发者双方做好准备工作。
截至目前,最新的Kafka版本是3.6.1,从2022年10月3日发布的3.3.1版本开始,KRaft在生产环境下已经完全支持。
根据当前的发布计划,Kafka 3.7(预计于2024年1月发布)将是最后一个支持Zookeeper的版本。
如果想全面了解KRaft,我建议阅读这篇文章[1]。
在本指南中,我将教你如何使用Docker在本地搭建一个Kafka环境,并提供一个UI工具查看我们的Kafka数据。
注:本文大部分内容参考自 Setting up a Local Kafka Environment in KRaft Mode with Docker-Compose and Bitnami Image, Enhanced by Provectus Kafka-UI[2],侵权删。
二、工具及其地址
Bitnami镜像:https://hub.docker.com/r/bitnami/kafka/
Provectus Kafka UI:https://github.com/provectus/kafka-ui
注意:目前广泛使用的 wurstmeister[3] 镜像仅支持Zookeeper(且目前测试Dockerhub没有该镜像),不支持KRaft,而Bitnami两者都支持!
三、搭建Kafka集群遇到的问题
在搭建Kafka集群的过程中,我遇到了一些问题,可能对你会有所帮助!
问题一:
如果是单机Kafka,则无需指定KAFKA_KRAFT_CLUSTER_ID。与某些教程所建议的相反,Kafka会动态生成一个ID,并将其记录在日志中。如果是集群Kafka,则需要指定,但需注意,一个集群的所有Kafka示例的KAFKA_KRAFT_CLUSTER_ID都是一致的。
问题二:kafka_kafka_1 exited with code 1
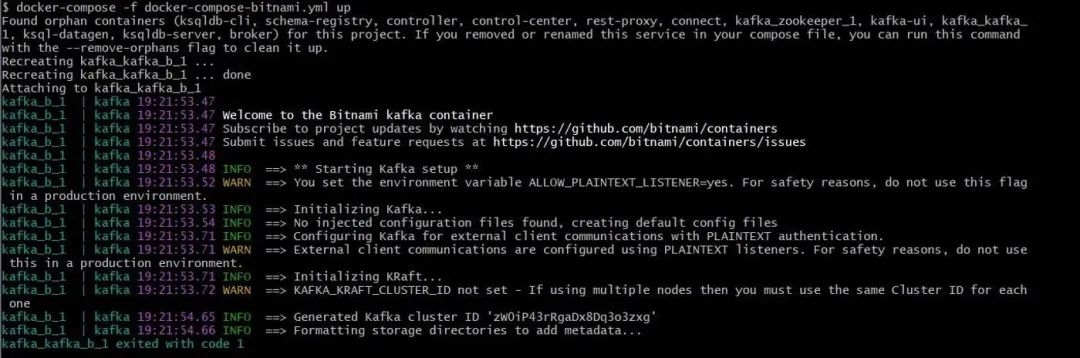
如上图,Kafka可能在没有抛出异常的情况下就失败了,在我的情况下,我复制了一个错误的环境配置,唯一确定真正问题的方法是通过BITNAMI_DEBUG=yes 启用调试日志记录,这使我能够找到问题的根本原因,因此我建议在故障排除时使用此配置。
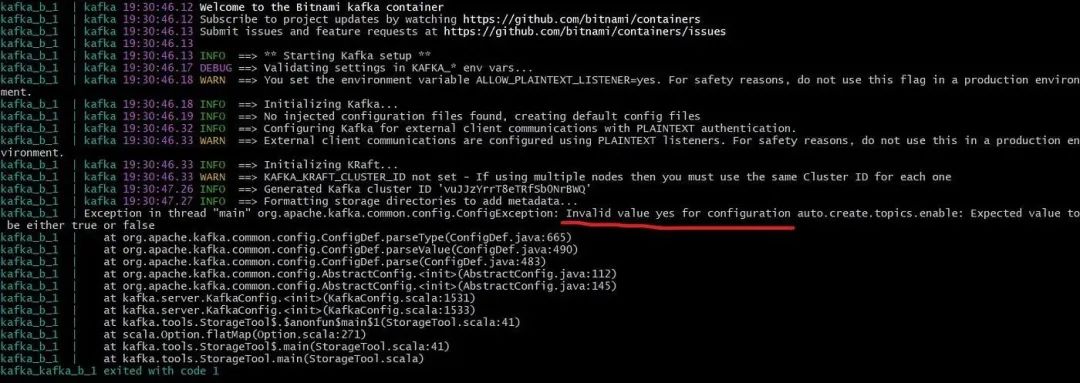
这是我报错的根本原因:
四、搭建单机Kafka的配置
你可以在**这里[4]**找到由Bitnami提供的docker-compose文件,但它并不特别有用,因为您需要单独搜索所需的配置。
# $dir/kafka.yml
version: "3"
services:
kafka_b:
image: docker.io/bitnami/kafka:3.4
hostname: kafka_b
ports:
- "9092:9092"
- "9094:9094"
volumes:
- "kafka_data:/bitnami"
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092,EXTERNAL://kafka_b:9094
- KAFKA_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_NODE_ID=1
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=true
- BITNAMI_DEBUG=yes
- KAFKA_CFG_NUM_PARTITIONS=2
volumes:
kafka_data:
driver: local
关于配置,有几个注意点:
1、你可以使用 KAFKA_ENABLE_KRAFT 变量来切换 KRaft/Zookeeper 模式
2、你可以指定 hostname 配置,这样可以便于Kafka-UI工具查看你的数据(如果主机的UI工具,请注意配置下hosts文件)
3、你如果不想使用默认端口9092,则注意要修改 ports 和 KAFKA_CFG_ADVERTISED_LISTENERS 环境变量
4、如果你想允许自动创建Topic,则可以将 KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE 环境变量设置为 true
这里有另外一份配置可以参考下:
version: "2"
services:
kafka:
image: docker.io/bitnami/kafka:3.6
# 指定你的容器名,不然是一串随机字符串
hostname: kafka_b
# networks:
# - kafka_net
ports:
- "9095:9092"
volumes:
- "kafka_data:/bitnami"
environment:
# KRaft settings
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
# 注意这里要同步改成9095
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://:9095
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
# auto create topics
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
volumes:
# data in: /var/lib/docker/volumes/{$network}
kafka_data:
driver: local
#networks:
# kafka_net:
# driver: bridge
注意:搭建集群版Kafka的配置可以在**这里[5]**找到。
五、搭建 Provectus Kafka UI
我测试了几个Kafka-UI工具(Conduktor,Kafka Magic,Offset Explorer等),发现当你需要通过外部名称连接到集群时,它们的行为可能会有所不同,这取决于您的部署策略。例如,使用Kafka Magic,即使没有外部侦听器(因为此UI未通过docker部署),我也能够直接连接到本地主机(127.0.0.1),但我不使用此工具,因为许多有用的功能仅在许可证下可用。
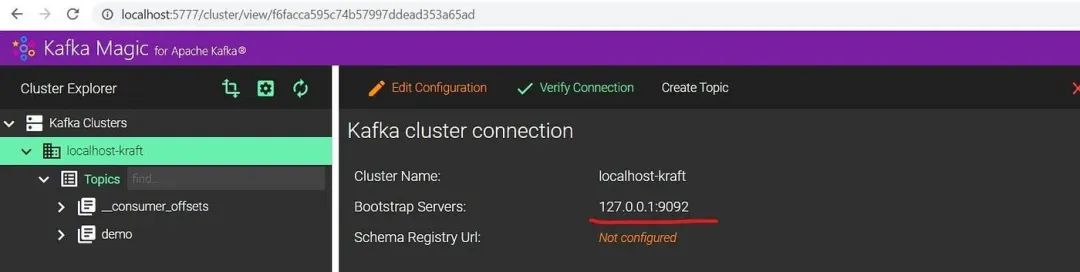
如果您正在寻找一个免费的开源工具,则 Provectus kafka-ui 可能会适合你。通过它的快速开始教程[6],你同样可以使用Docker快速搭建一个Kafka-ui,但需要注意的是,如果是用容器搭建的,此时连接我们前面的Kafka集群时,使用 localhost:9092[7] 的地址将会连接失败!
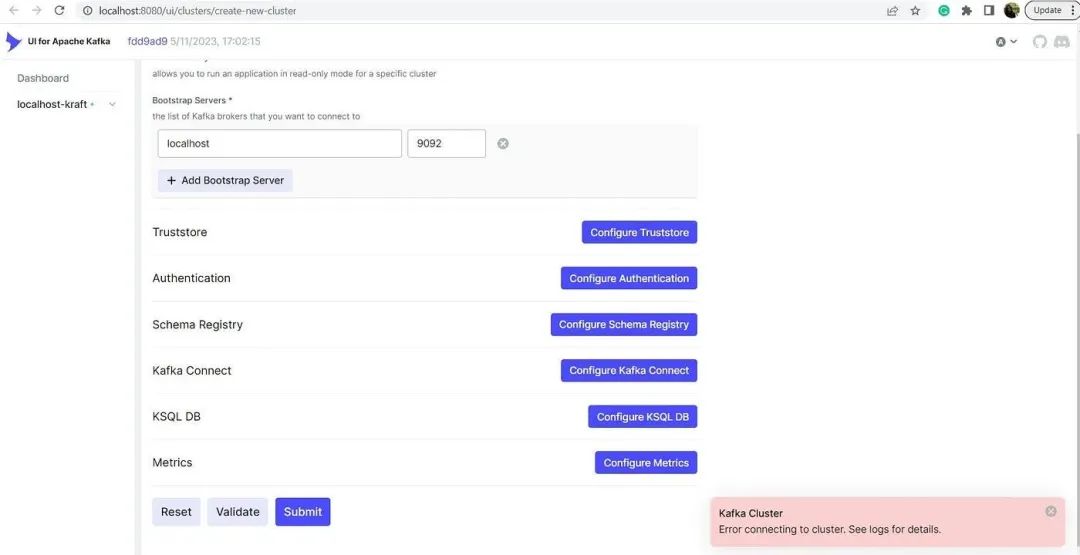
为了成功连接到我们前面搭建的本地Kafka,我们需要指定正确的主机名和端口,这些配置在我们的Kafka自身的docker-compose文件中已经设置(注意是 kafka_b:9094,9094是暴露给外部使用的端口,9092是内部使用的端口)。
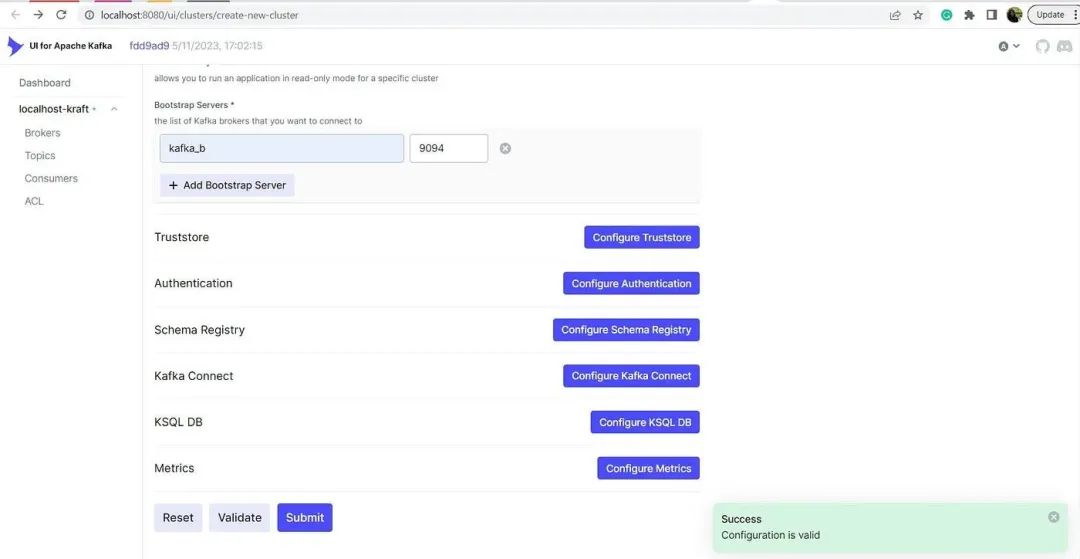
这是 Provectus kafka-ui 对应的配置
# $dir/kafka-ui.yml
services:
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: 'true'
LOGGING_LEVEL_ROOT: 'DEBUG'
# volumes:
# - /c/tools/kafka/kui/config.yml:/etc/kafkaui/dynamic_config.yaml
LOGGING_LEVEL_ROOT 配置用于故障排除,但实际上并不需要。在启动之后,我们可以在kafka-ui中的相应主题中查看我们的消息。
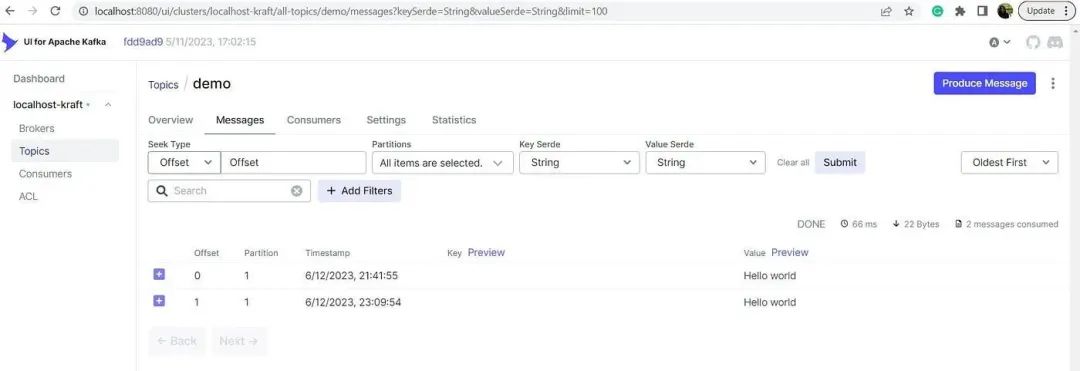
如果走到这一步,那么恭喜!您的环境现在已经完全设置好并可以使用了。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。
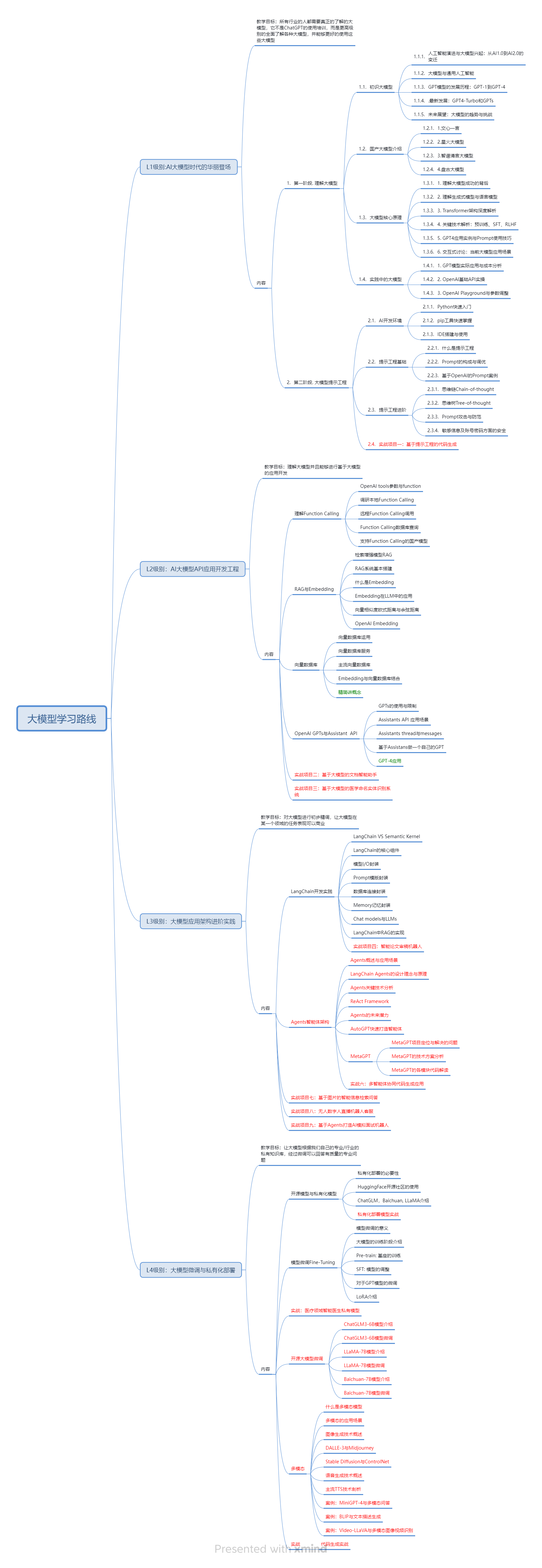
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。
二、AI大模型视频教程
三、AI大模型各大学习书籍!

四、AI大模型各大场景实战案例

五、AI大模型面试题库

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。








