ubuntu20.04配置YOLOV5(非虚拟机)
有的教程会要安装TensorRT或TensorFlow,这个并不是基础依赖项,只有在需要特定导出时才需要安装。
本教程基于纯净的ubuntu20.04进行安装。
目录
一、安装显卡驱动
1、关闭自动更新
2、换源
3、安装显卡驱动
4、问题及解决
二、CUDA安装
三、cuDNN安装
四、安装Anaconda
五、创建虚拟环境
六、安装pytorch
七、下载yolov5
八、运行测试
一、安装显卡驱动
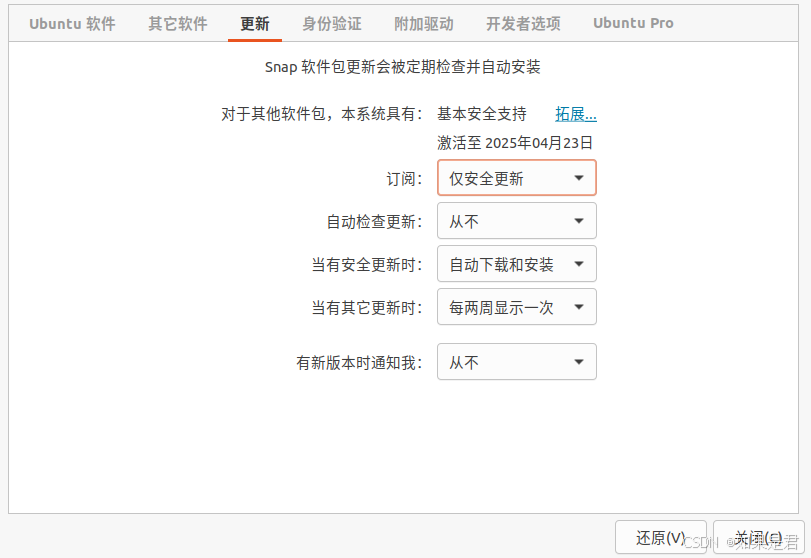
1、关闭自动更新
进入系统后关闭自动更新。按照如下图所示进行设置:
2、换源
打开终端,执行以下命令将源文件做备份:
sudo cp /etc/apt/sources.list /etc/apt/sources_copy.list
终端执行以下命令,会打开一个文件:
sudo gedit /etc/apt/sources.list将打开的文件里面的内容删除,把以下代码复制到打开的文件里面,保存并退出。
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-proposed main restricted universe multiverse终端执行以下命令,更新一下:
sudo apt-get update
千万不要执行以下命令:sudo apt-get upgrade。也不要更新升级系统。
因为升级后会安装新的内核,导致和显卡驱动产生冲突。因此重启后会一直黑屏无法进入图形化界面。
3、安装显卡驱动
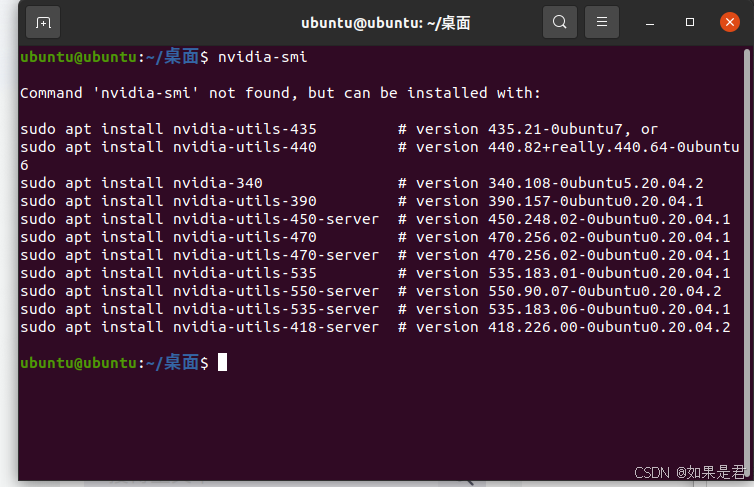
终端执行以下命令,查看显卡驱动:
nvidia-smi由于此时还没安装显卡驱动,出现的应该是以下画面:
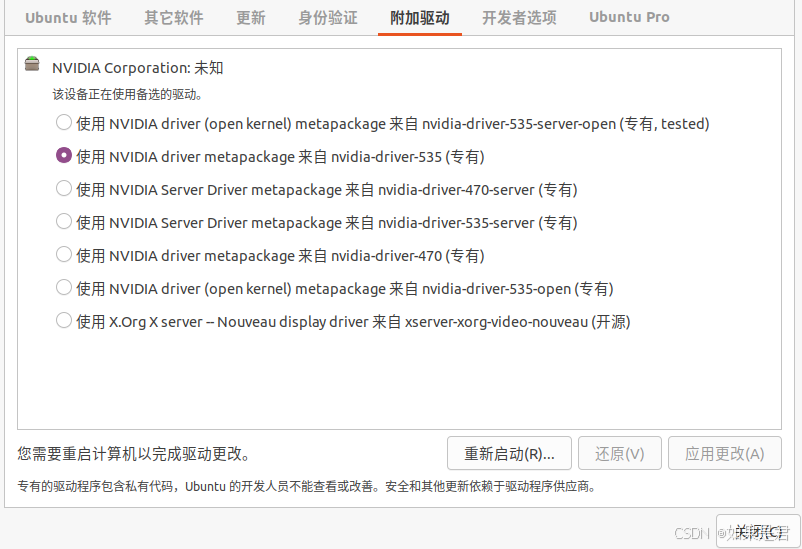
打开软件和更新,在附加驱动里找到适合自己的显卡驱动,我这里选择的是nvidia-driver-535。(如果附加驱动里没有显示,可以在终端执行sudo apt-get update这条命令,再查看附加驱动。)
重启后,在终端输入以下命令:
nvidia-smi出现以下画面,即说明显卡驱动安装成功:
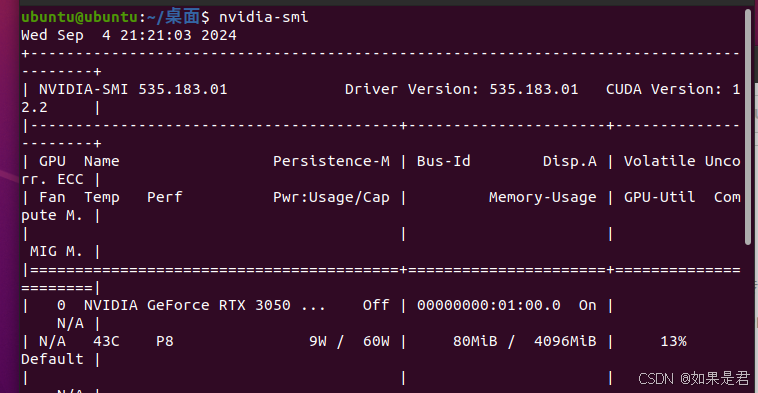
4、问题及解决
驱动安装完成后,终端执行以下命令:
nvidia-smi出现如下画面:

并且重启后会发现界面一直是黑屏状态。
原因:升级系统后会安装新的内核,导致和显卡驱动产生冲突。重启后会一直黑屏无法进入图形化界面。
(若是连接扩展屏,重启后一直黑屏无法进入图形界面。把扩展屏断开连接后,重启就可解决。)
关于用扩展屏经常会出现问题,建议还是不要用扩展屏。
重启进入修复模式,在root下执行以下代码:
sudo apt-get purge nvidia*执行完成后,关机。
再次开机,即可正常进入系统。
如果一直无法解决,建议重装ubuntu系统后,一步一步按照上述操作进行,即可解决。
二、CUDA安装
终端执行以下命令,查看和驱动版本相对应的CUDA版本。这里推荐的CUDA版本是12.2。
nvidia-smi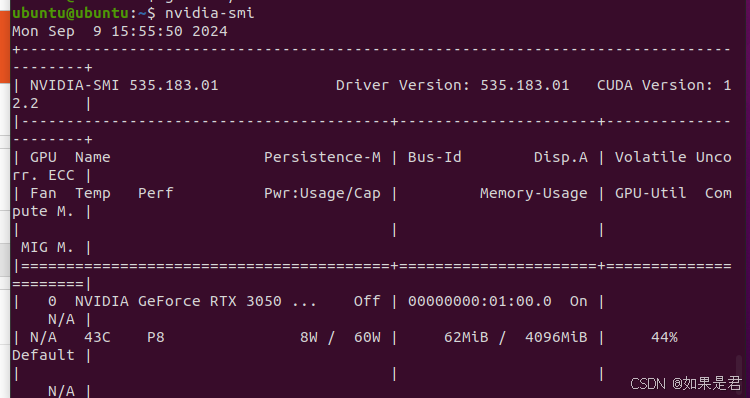
终端执行以下命令,查看系统架构,这里是X86架构:
uname -a

以下链接可以查看 CUDA 版本与驱动版本对应关系:
1. CUDA 12.8 Update 1 Release Notes — Release Notes 12.8 documentation

通过以下链接,下载CUDA对应的版本,这里下载的是12.2:
https://developer.nvidia.com/cuda-toolkit-archive
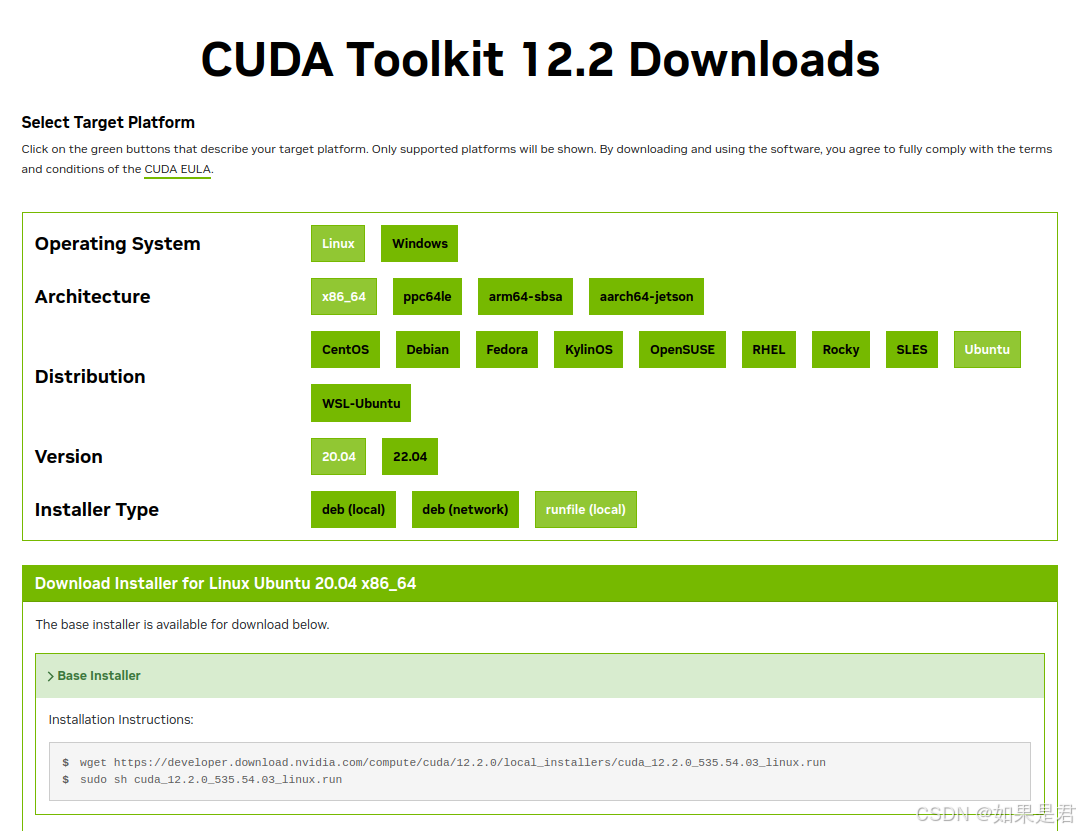
选择对应的类型,推荐用runfile安装。
下载界面提供了下载安装执行的命令行。
终端执行以下命令,下载安装包:
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run在文件下载的位置,打开终端执行以下命令进行安装:
sudo sh cuda_12.2.0_535.54.03_linux.run在出现的界面选择Continue,回车确定。
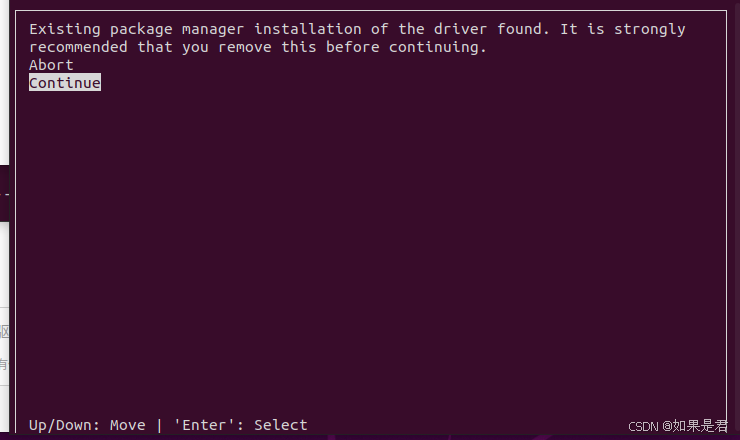
输入accept,回车确定。
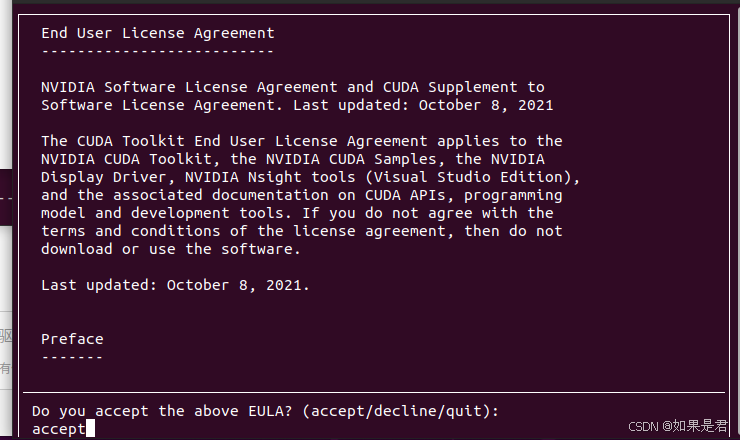
回车或空格选择要安装的项目。由于驱动已经安装过了,一定要取消选择,不然可能会发生冲突,一直黑屏,无法进入图形界面。选择Install进行安装。
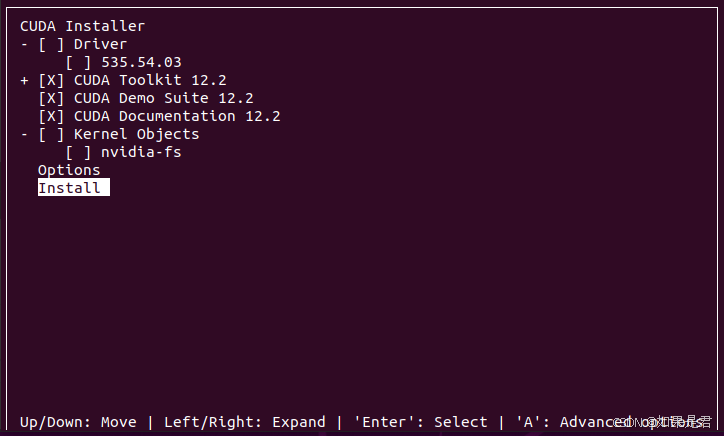
安装成功会出现如下界面:
终端执行以下命令,添加一下环境变量:
gedit ~/.bashrc在打开的文件末尾加入如下代码:
注意:路径要根据自己的实际路径来。
export PATH=/usr/local/cuda-12.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}点击保存退出,然后刷新一下环境。
source ~/.bashrc
环境变量配置完成后,在终端输入以下命令:
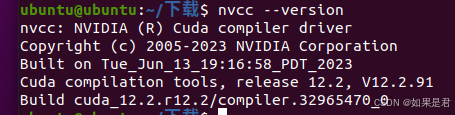
nvcc --version
出现如下画面,则代表安装成功:
三、cuDNN安装
打开以下链接:
https://developer.nvidia.com/rdp/cudnn-archive
根据CUDA 12.2选择对应的cuDNN版本。
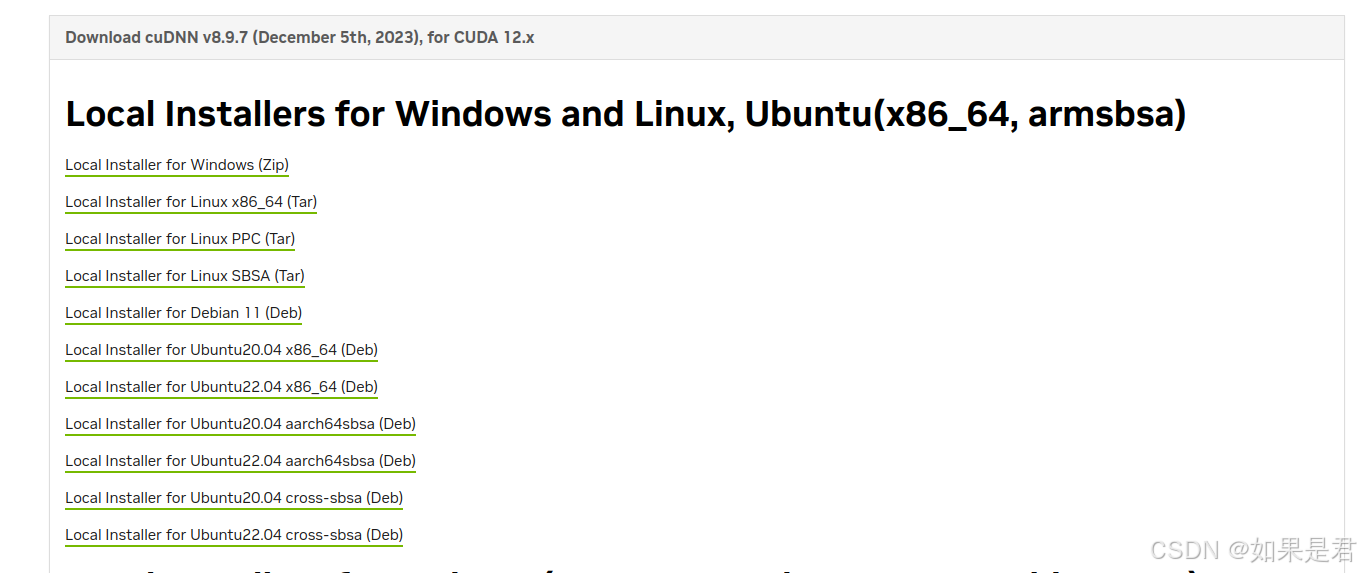
这里选择的是cuDNN v8.9.7。点击Local Install for Linux x86_64(Tar),进行下载。
在下载的安装包目录下执行以下命令,解压缩:
tar -xf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz将文件重命名为cudnn,然后在cudnn所在位置打开终端,执行以下命令,将文件复制到相对应的路径下:
sudo cp cudnn/include/cudnn*.h /usr/local/cuda-12.2/include/
sudo cp cudnn/lib/libcudnn* /usr/local/cuda-12.2/lib64/
sudo chmod a+r /usr/local/cuda-12.2/include/cudnn*.h
sudo chmod a+r /usr/local/cuda-12.2/lib64/libcudnn*终端执行以下命令:
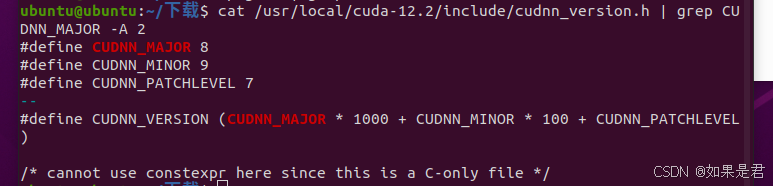
cat /usr/local/cuda-12.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
出现以下画面,安装成功。
四、安装Anaconda
打开以下链接:
https://repo.anaconda.com/archive/
下载和自己系统匹配的安装包。这里下载的是Anaconda3-2024.02-1-Linux-x86_64.sh。
在下载安装包的目录下打开终端,执行以下命令进行安装。
bash Anaconda3-2024.02-1-Linux-x86_64.sh出现以下画面,按提示进行回车:

一直按回车,或按q直接跳过,直到出现“Do you accept the license terms”, 输入“yes” 。
默认位置已经足够,按ENTER确认安装位置。
出现是否要运行conda init,输入yes。
出现以下画面,Anaconda安装成功:
安装好后,source一下环境或者重新打开一个终端。
source ~/.bashrc 会多一个(base)的前缀。

附:如果希望 conda 的基础环境在启动终端时不被激活,将 auto_activate_base 参数设置为 false:
conda config --set auto_activate_base false
后面想要再进入conda的base环境,只需要使用conda指令激活base环境
conda activate base
或将 auto_activate_base 参数设置为 true:
conda config --set auto_activate_base true五、创建虚拟环境
终端执行以下命令,创建一个python3.8的名称为yolo的环境。
conda create -n yolo python=3.8
按照提示输入y,回车。
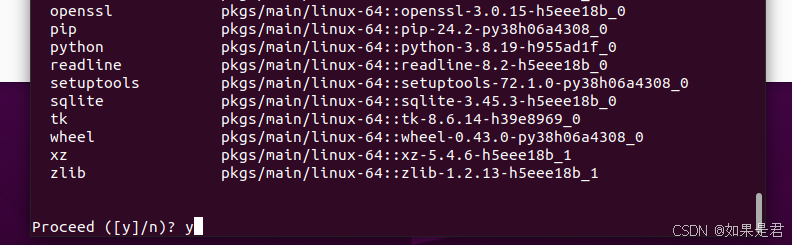
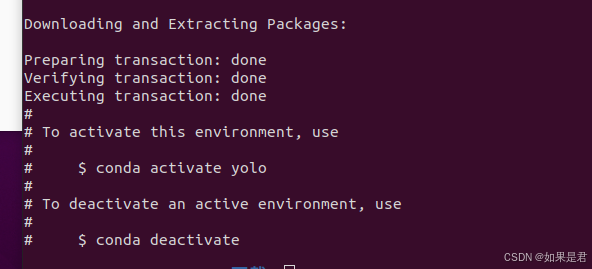
出现如下,创建成功:
终端执行以下命令,打开创建的yolo虚拟环境:
conda activate yolo

终端执行以下命令,退出创建的yolo虚拟环境:
conda deactivate
六、安装pytorch
一定要在刚刚创建的yolo虚拟环境下安装。
终端执行以下命令,打开创建的yolo虚拟环境:
conda activate yolo
在安装pytorch之前要先安装comet-ml,不然后续可能无法导入comet-ml库。
终端执行以下命令安装comet-ml库:
pip install comet-ml若确实是先安装pytorch再安装comet-ml,通过运行Python解释器再导入comet-ml库。
终端执行python打开解释器,然后输入import comet_ml导入库。若没有报错,输入exit()退出即可。

打开以下链接:
Previous PyTorch Versions | PyTorch
选择合适的版本下载,这里下载的是v2.1.2版本。
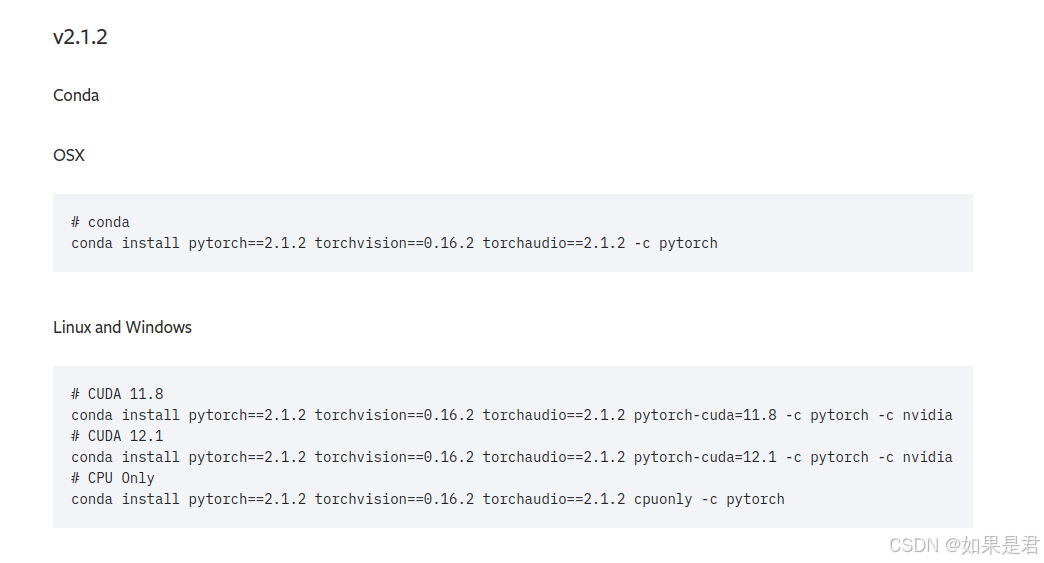
选择CUDA12.1版本(没有12.2版本,安装12.1也行)。在终端执行网页提供的,对应版本的命令行。
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia出现如下画面,输入y:
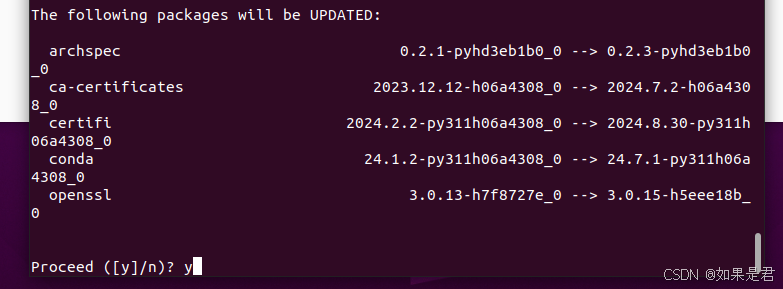
建议下载工程中,使用科学上网工具连接,更容易成功,安装成功界面如下:
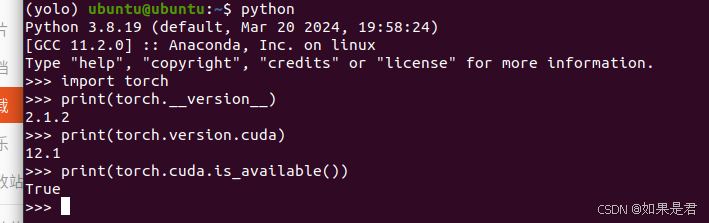
安装完后,依次执行以下命令进行验证:
python
import torch
print(torch.__version__) # pytorch版本
print(torch.version.cuda) # cuda版本
print(torch.cuda.is_available()) # 查看cuda是否可用
出现如下界面:
执行以下命令退出虚拟环境:
exit() #退出python
conda deactivate #退出虚拟环境七、下载yolov5
终端执行以下命令,下载yolov5源码:
git clone https://github.com/ultralytics/yolov5.git
默认yolov5源码里面不包含预训练模型,还需自行下载,放在yolov5目录下。
通过以下链接下载:
ONNX > CoreML > TFLite">GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
找到预训练权重模型。
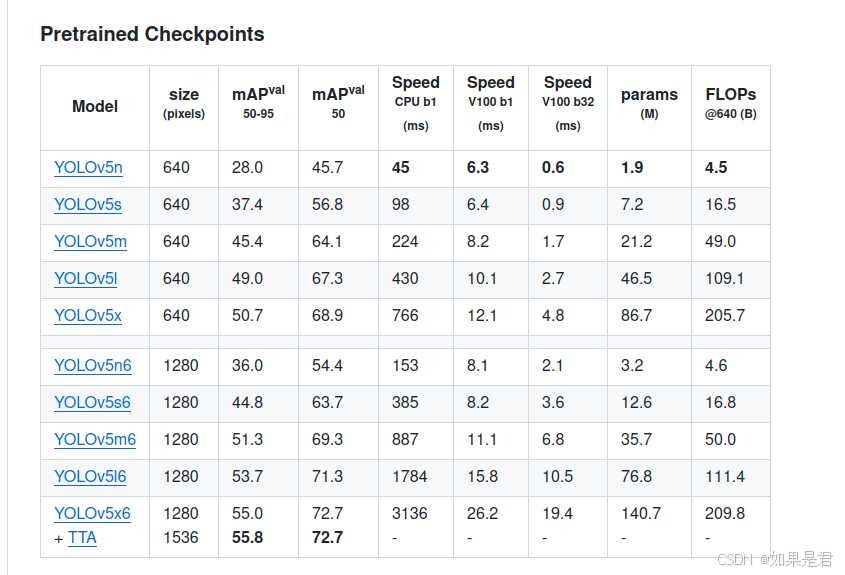
将下载好的预训练权重模型放在yolov5目录下,这里下载的是YOLOv5s(不用解压缩)。
在yolov5文件夹下,打开终端并执行以下命令,打开创建的yolo虚拟环境:
conda activate yolo终端执行以下命令:
pip3 install -U -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple会自动下载所需要的依赖。
若出现报错,根据报错信息安装缺少的依赖。然后再次执行上述命令。
八、运行测试
在yolov5文件夹下,打开终端并执行以下命令,打开创建的yolo虚拟环境:
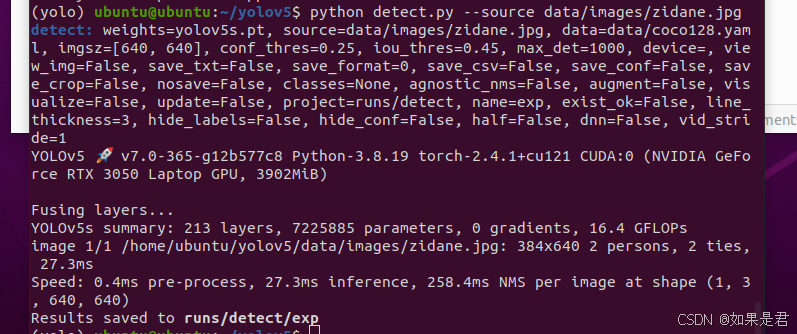
conda activate yolo终端执行以下命令,运行测试:
python detect.py --source data/images/zidane.jpg或以下命令:
python detect.py --source "data/images/bus.jpg" --weights="yolov5s.pt"
出现如下画面,运行成功:
通过路径yolov5/runs/detect/exp查看保存的文件。