【网络】应用层协议-http协议
文章目录
- 1.Http协议
-
- 1.1什么是http协议
- 1.2认识URL
- 1.3urlencode和urldecode
- 1.4HTTP请求协议格式
- 1.5HTTP响应协议格式
- 1.6HTTP常见的Header
- 1.7HTTP常见状态码
- 1.8HTTP的方法
- 1.8根据url调取对应的服务
- 2.cookie和session
-
- 2.1cookie
- 2.2session
- 3.HTTPS协议
-
- 3.1对称加密
- 3.2非对称加密
- 3.3数字指纹(数字摘要)
- 3.4HTTPS的工作过程
-
- 3.4.1方案一:只使用对称加密
- 3.4.2方案二:只使用非对称加密
- 3.4.3方案三:双方都使用非对称加密
- 3.4.4方案四:非对称加密+对称加密
- 3.4.5签名
- 3.4.6CA认证
- 3.4.7方案五:非对称加密+对称加密+证书认证
1.Http协议
1.1什么是http协议
在编写网络通信代码时,我们可以自己进行协议的定制,但实际有很多优秀的工程师早就已经写出了许多非常成熟的应用层协议,其中最典型的就是HTTP协议。
在互联网世界中, HTTP(HyperText Transfer Protocol, 超文本传输协议) 是一个至关重要的协议。 它定义了客户端(如浏览器) 与服务器之间如何通信, 以交换或传输超文本(如 HTML 文档) 。
HTTP 协议是客户端与服务器之间通信的基础。 客户端通过 HTTP 协议向服务器发送请求, 服务器收到请求后处理并返回响应。 HTTP 协议是一个无连接、 无状态的协议, 即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息。
1.2认识URL
URL(Uniform Resource Lacator)叫做统一资源定位符,也就是我们通常所说的网址,是因特网的万维网服务程序上用于指定信息位置的表示方法。
一个URL大致由如下几部分构成:

(1)协议方案名
http://表示的是协议名称,表示请求时需要使用的协议,通常使用的是HTTP协议或安全协议HTTPS。
HTTPS是以安全为目标的HTTP通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。
常见的应用层协议:
- DNS(Domain Name System)协议:域名系统。
- FTP(File Transfer Protocol)协议:文件传输协议。
- TELNET(Telnet)协议:远程终端协议。
- HTTP(Hyper Text Transfer Protocol)协议:超文本传输协议。
- HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer)协议:安全数据传输协议。
- SMTP(Simple Mail Transfer Protocol)协议:电子邮件传输协议。
- POP3(Post Office Protocol - Version 3)协议:邮件读取协议。
- SNMP(Simple Network Management Protocol)协议:简单网络管理协议。
- TFTP(Trivial File Transfer Protocol)协议:简单文件传输协议。
(2)登录信息
usr:pass表示的是登录认证信息,包括登录用户的用户名和密码。
虽然登录认证信息可以在URL中体现出来,但绝大多数URL的这个字段都是被省略的,因为登录信息可以通过其他方案交付给服务器。
(3)服务器地址
www.example.jp表示的是服务器地址,也叫做域名,比如www.alibaba.com,www.qq.com,www.baidu.com。
需要注意的是,我们用IP地址标识公网内的一台主机,但IP地址本身并不适合给用户看。实际我们可以认为域名和IP地址是等价的,在计算机当中使用的时候既可以使用域名,也可以使用IP地址。但URL呈现出来是可以让用户看到的,因此URL当中是以域名的形式表示服务器地址的。
(4)服务器端口号
80表示的是服务器端口号。HTTP协议和套接字编程一样都是位于应用层的,在进行套接字编程时我们需要给服务器绑定对应的IP和端口,而这里的应用层协议也同样需要有明确的端口号。
常见协议对应的端口号:
| 协议名称 | 对应端口号 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| SSH | 22 |
当我们使用某种协议时,该协议实际就是在为我们提供服务,现在这些常用的服务与端口号之间的对应关系都是明确的,所以我们在使用某种协议时实际是不需要指明该协议对应的端口号的,因此在URL当中,服务器的端口号一般也是被省略的。
(5)带层次的文件路径
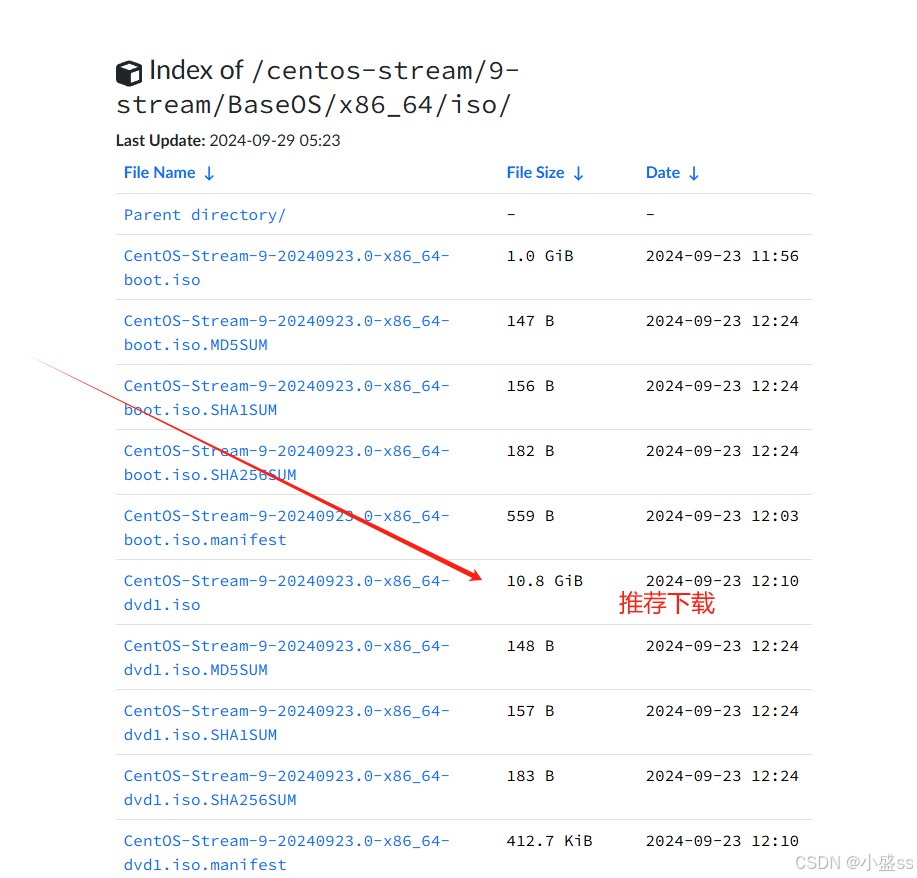
/dir/index.htm表示的是要访问的资源所在的路径。访问服务器的目的是获取服务器上的某种资源,通过前面的域名和端口已经能够找到对应的服务器进程了,此时要做的就是指明该资源所在的路径。
比如我们打开浏览器输入CSDN的域名后,此时浏览器就帮我们获取到了CSDN的首页。

当我们发起网页请求时,本质是获得了这样的一张网页信息(html),然后浏览器对这张网页信息进行解释,最后就呈现出了对应的网页。
我们可以将这种资源称为网页资源,此外我们还会向服务器请求视频、音频、网页、图片等资源。HTTP之所以叫做超文本传输协议,即超过文本,就是因为有很多资源实际并不是普通的文本资源。
因此在URL当中就有这样一个字段,用于表示要访问的资源所在的路径。此外我们可以看到,这里的路径分隔符是/,而不是,这也就证明了实际很多服务都是部署在Linux上的。
(6)查询字符串
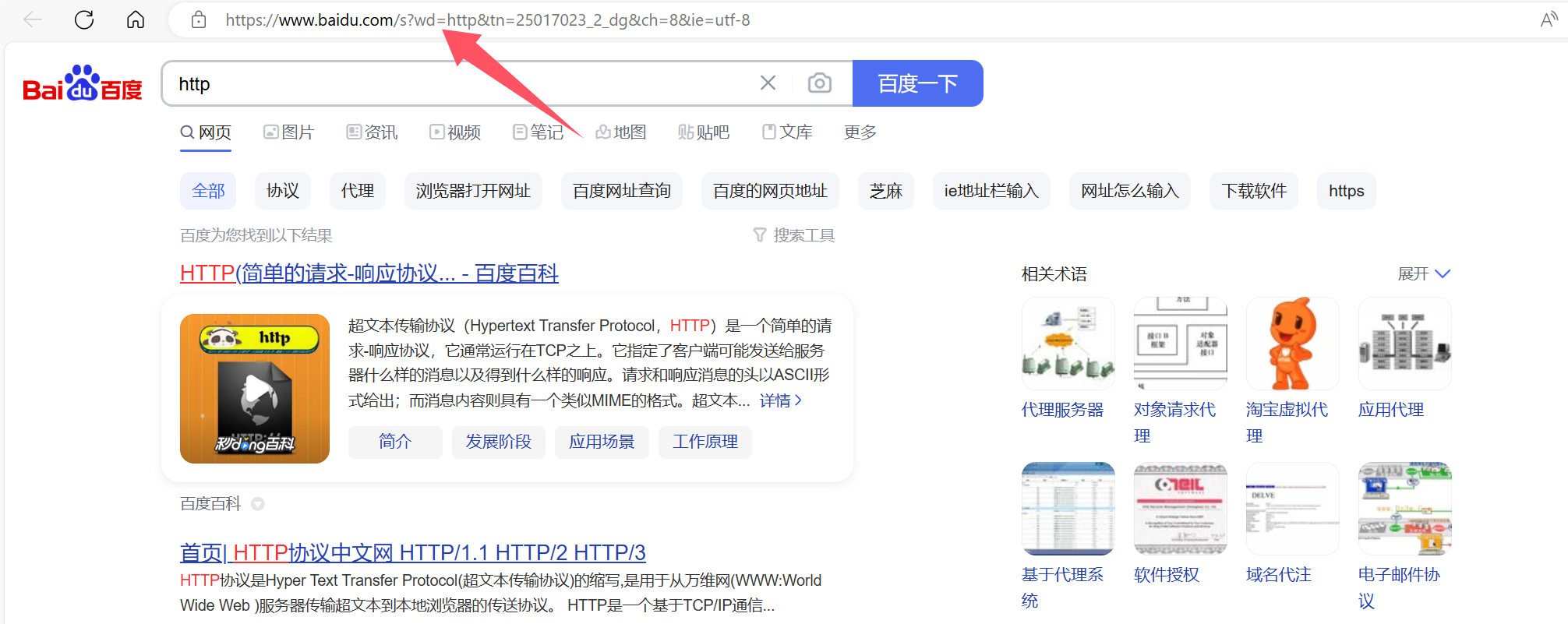
uid=1表示的是请求时提供的额外的参数,这些参数是以键值对的形式,通过&符号分隔开的。
比如我们在百度上面搜索HTTP,此时可以看到URL中有很多参数,而在这众多的参数当中有一个参数wd(word),表示的就是我们搜索时的搜索关键字wd=HTTP。
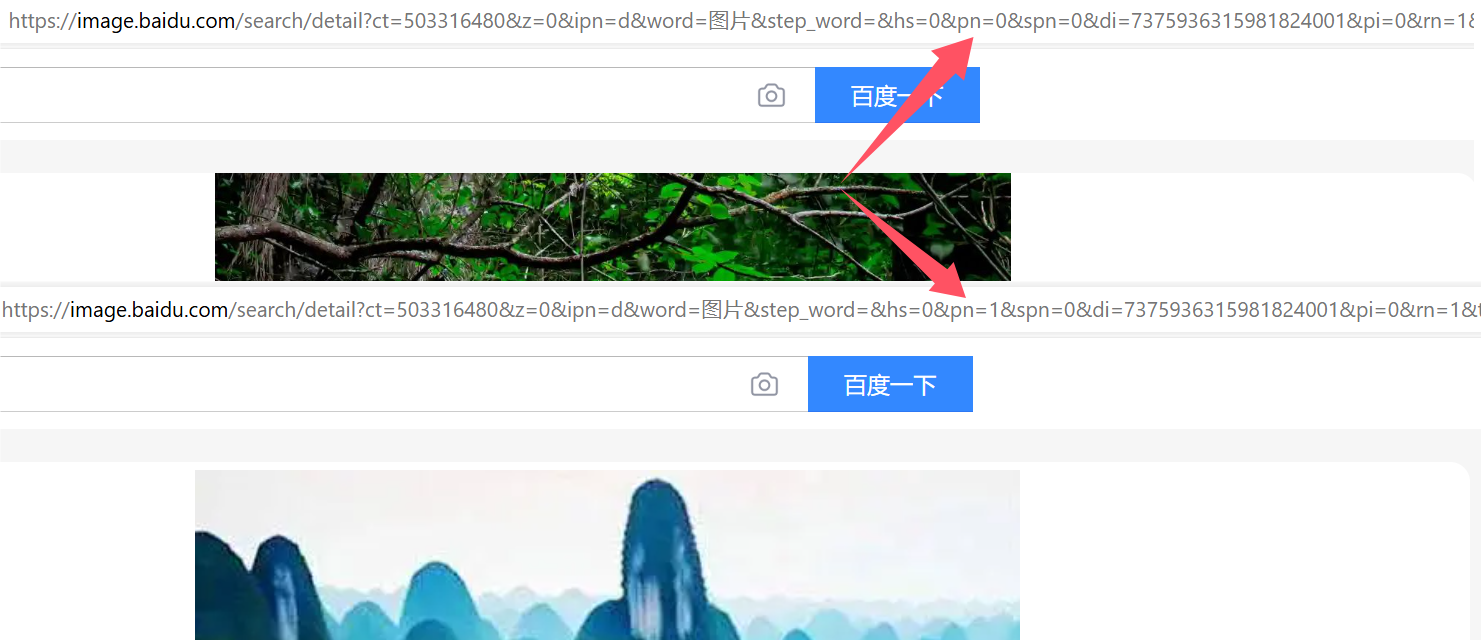
(7)片段标识符
ch1表示的是片段标识符,是对资源的部分补充。
比如我们在看组图的时候,URL当中就会出现片段标识符。
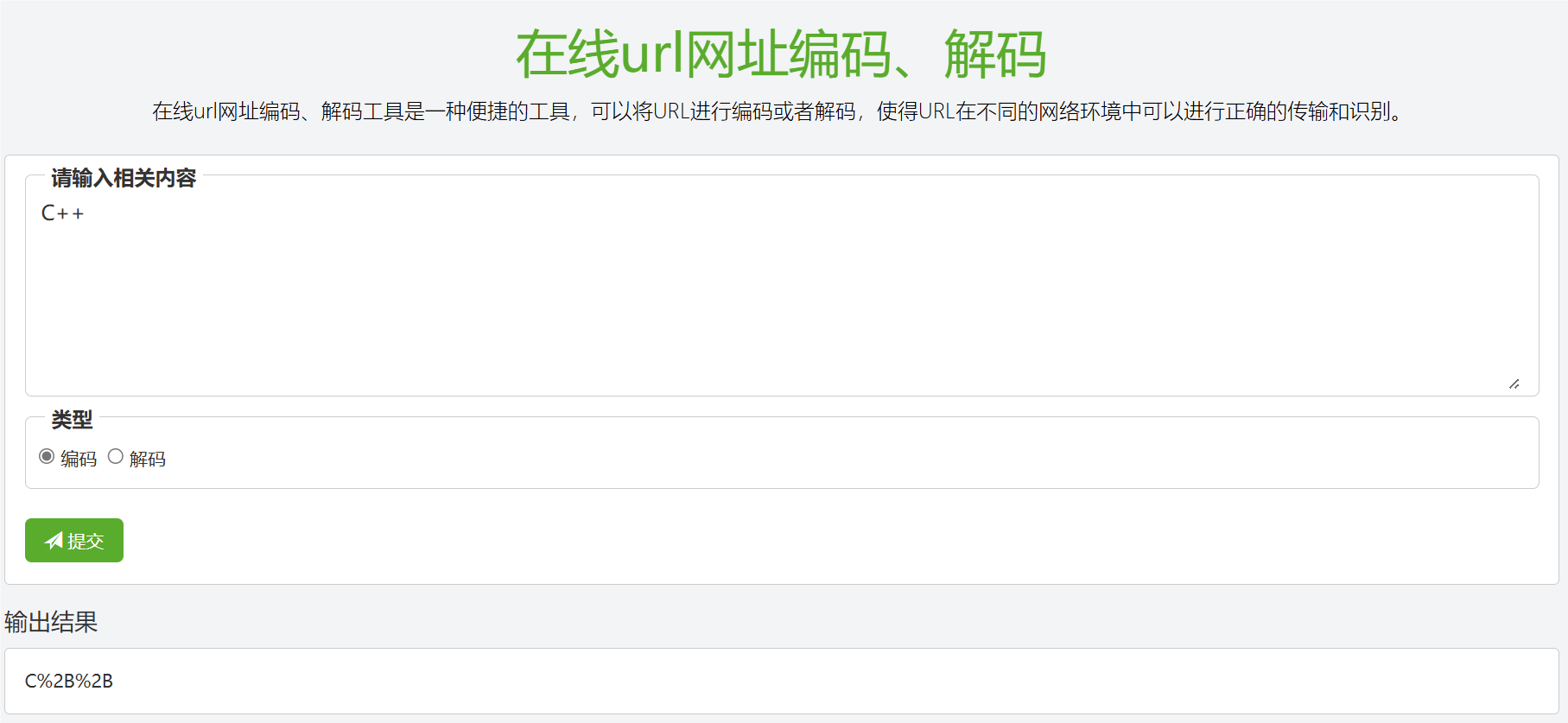
1.3urlencode和urldecode
如果在搜索关键字当中出现了像/?:这样的字符,由于这些字符已经被URL当作特殊意义理解了,因此URL在呈现时会对这些特殊字符进行转义。
转义的规则:将需要转码的字符转为十六进制,然后从右到左,取4位(不足4位直接处理),每两位做一位,前面加上%,编码成%XY格式,对中文也会进行编码。
在线url网址编码、解码 - 记灵工具 (remeins.com)
接下来我们就一起来学习下http协议的请求响应格式。
1.4HTTP请求协议格式
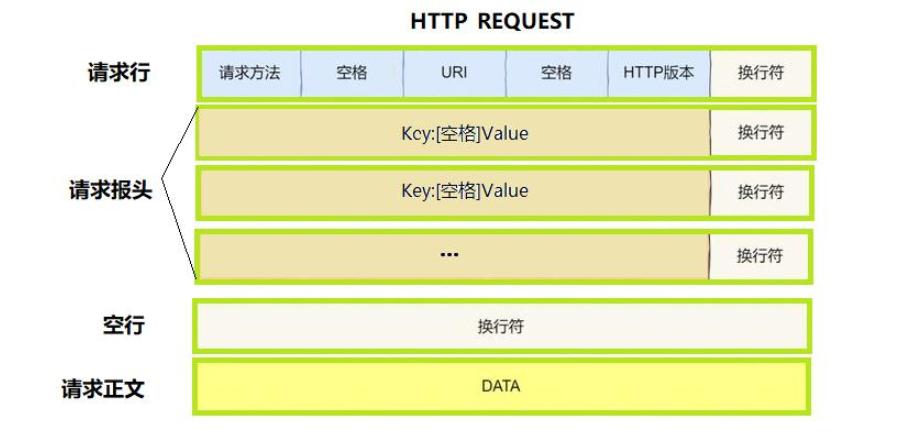
HTTP请求由以下四部分组成:
- 请求行:[请求方法]+[url]+[http版本]
- 请求报头:请求的属性,这些属性都是以key: value的形式按行陈列的。
- 空行:遇到空行表示请求报头结束( )。
- 请求正文:请求正文允许为空字符串,如果请求正文存在,则在请求报头中会有一个Content-Length属性来标识请求正文的长度。
其中,前面三部分是一般是HTTP协议自带的,是由HTTP协议自行设置的,而请求正文一般是用户的相关信息或数据,如果用户在请求时没有信息要上传给服务器,此时请求正文就为空字符串。
- url当中的
/不能称之为我们云服务器上根目录,这个/表示的是web根目录(wwwroot/),该目录下存储的是网站静态资源(网页html、css等),这个web根目录可以是你的机器上的任何一个目录,这个是可以自己指定的,不一定就是Linux的根目录,当url的值为/时,http协议会默认拼接上该站点的首页(index.html)。
站在程序员角度:网站就是一堆特定目录和文件构成的目录结构。
根据以上格式,我们可以模拟实现下http协议请求的反序列化,序列化不用实现,因为我们不考虑客户端,只考虑服务器对请求的反序列化工作以便分析请求即可。
反序列化即将请求字符串的内容解析出来,分别赋给结构化数据的字段。
设计思路如下:
首先我们先将请求行、请求报头、以及请求正文提取出来,然后对他们进一步分析得到具体的字段数据,比如请求行中的请求方法、URL等。
值得注意的是请求报头的数据明显是key-value结构,所以我们可以采用hash结构来存储。
另外有关响应的Content-Type属性,是由请求的文件后缀自动识别的,所以我们还需要设定一个文件后缀属性,以便响应中填充Content-Type属性,还有状态码描述,我们同样的根据不同的状态码对应到状态描述。
当然我们这里实现的是一个不成熟不完整的http协议请求,目的以学习为主。
static const std::string sep = "
";
static const std::string header_sep = ": ";
static const std::string wwwroot = "wwwroot"; // web根目录
static const std::string homepage = "index.html"; // 当访问的是/时,默认拼接上index.html
static const std::string httpversion = "HTTP/1.0"; // http版本
static const std::string space = " ";
static const std::string filesuffixsep = "."; // 后缀分隔符
class HttpRequest
{
private:
std::string ParseLine(std::string &reqstr)
{
if (reqstr.empty())
return reqstr;
auto pos = reqstr.find(sep);
if (pos == std::string::npos)
return std::string();
std::string line = reqstr.substr(0, pos); // 获取一行
reqstr.erase(0, pos + sep.size()); // 将提取到的一行移除
return line.empty() ? sep : line; // 如果截取到的行为空,证明此时读取到的是空行,我们返回
}
bool ParseHeaderHelper(const std::string &line, std::string *k, std::string *v)
{
auto pos = line.find(header_sep);
if (pos == std::string::npos)
return false;
*k = line.substr(0, pos);
*v = line.substr(pos + header_sep.size());
return true;
}
public:
HttpRequest() : _blank_line(sep), _path(wwwroot)
{
}
void Serialize() {} // 无需实现,因为对请求序列化是客户端要考虑的
void Deserialize(std::string &reqstr)
{
_req_line = ParseLine(reqstr);
while (true)
{
std::string line = ParseLine(reqstr);
if (line.empty())
break;
else if (line == sep) // 说明此时报头已经读完,该读正文了
{
_req_text = reqstr;
break;
}
else
{
_req_header.emplace_back(line);
}
}
ParseReqLine();
ParseHeader();
}
void Print()
{
std::cout << "===" << _req_line << std::endl;
for (auto &header : _req_header)
{
std::cout << "***" << header << std::endl;
}
std::cout << _blank_line;
std::cout << _req_text << std::endl;
std::cout << "method ### " << _method << std::endl;
std::cout << "url ### " << _url << std::endl;
std::cout << "path ### " <