Linux重点
Linux重点
分值与体型

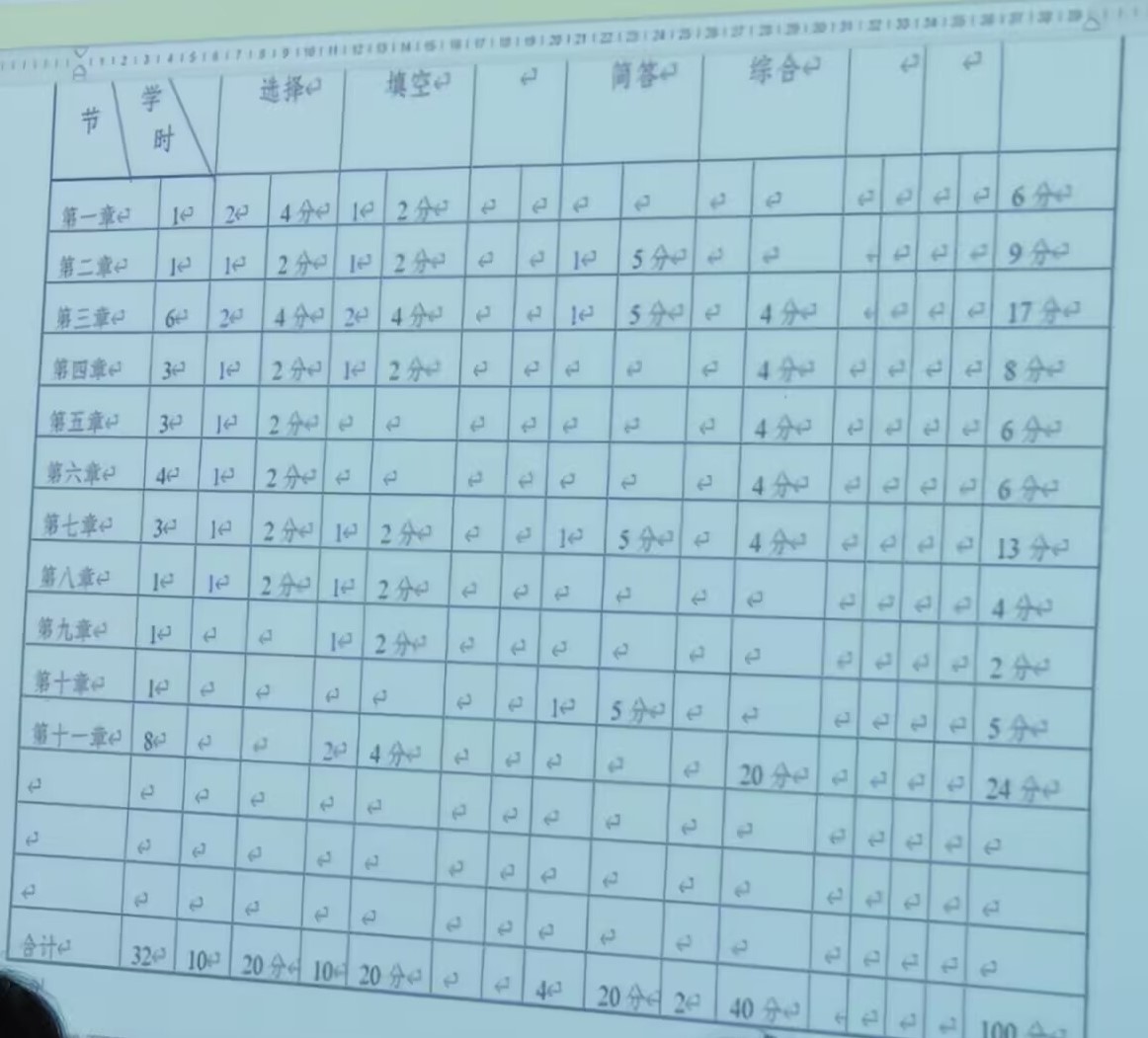
这个↓我也不知道哪来的

第一章
p8,1.2.1Linux的发展历史
两选择,一填空,6分
-
五个重要支柱:UNIX操作系统,MINIX操作系统,GNU计划,POSIX标准(一系列API标准的总称),互联网。
-
内核版本号:
主版本号.次版本号.修正号
次版本中偶数-稳定;奇数-测试
如2.6.25,即主版本号为2.次版本号6,第25次修正。
第二章
一选择,一填空,一简答,9分
p20,2.3.1字符界面下Lnux系统的关闭与重启.
- halt [-f][-p][-reboot]
- -f
- -p关闭系统之后关闭电源
- –reboot
- reboot同上中reboot
- poweroff,同halt -p
↑一经发出开始执行,且不可以反悔↑
-
shutdown:可以安全关闭系统,指令发出到执行之间有一个延迟
shutdown [-krhfFc] time [wall msg]
-r 重启计算机
-h/-H,halt 关机后关闭电源
-k ,Kick。并不真正关机,只是发送警告信号给每位用户
-c 取消目前已经提交的 shutdown 任务。该选项同时使用可有一个用来解释撤销关机的广播信息
time 指定关机时间。可为格式为 hh:mm 的绝对时间,如 1:20,或相对时间(单位为分),如+10 表示 10 分 钟后关机,+0 表示 now。若不指定则默认为+1
wall msg 广播信息。若不指定,系统提供默认信息
#shutdown -r now #立刻重新启动 now相当于+0 #shutdown -h now #立刻关机 #shutdown -k now 'Hey Lets go now.' #发出警告信息,但没有真关机 #shutdown -h 10:42 "系统将在 10:42 关闭, 请届时退出" #10:42 分关机 #shutdown -r +20 '20 分钟后将重启系统,请提前退出' #20 分钟后重启系统 #shutdown -c #撤销已下达的 shutdown 命令 #shutdown now #切换至单用户模式(不加任何选项时)
p22,2.3.2系统的运行级别及切换
- 定义:Linux 系统有 7 个运行级别或运行状态,如下。
0:关闭系统。
1、s、S:单用户模式。 仅允许 root 用户登录,不启动网络服务或守护进程,用于系统维护。
2:多用户模式。但没有不启用网络文件系统(NFS)功能。没图形化界面。
3:完全多用户模式。标准服务器模式,支持多用户登录、网络服务(如 SSH、HTTP),但无图形界面
4:没有使用,用户可自定义。
5:完全多用户模式,在级别 3 基础上启动图形界面,且支持 X-Windows(系统默认运行级)。
6:重新启动。
Q、q:重新加载配置文件
#查询运行状态
#who -r
#runlevel
#查询默认
#systemctl get-default
- 切换
系统内运行着一个叫 init 的进程, 此 init 在引入 systemd 软件包之后叫 systemd,它负责系统的初始化和运行级别的切换。命令 init 或 telinit 的作用是告诉 init 进程进行运行级切换,在使用时,init 和 telinit 可视为同一个 命令
#init LEVEL #LEVEL 为数字,7 个运行级别中的一个
#telinit LEVEL
#init 0 #关机
#init 6 #重新启动
#telinit 1 #切换到单用户
p28,2.5 系统在线帮助与资源
man
man 是 Linux/Unix 系统中用于查看命令、函数、配置文件等帮助手册的核心工具,全称为 manual(手册)
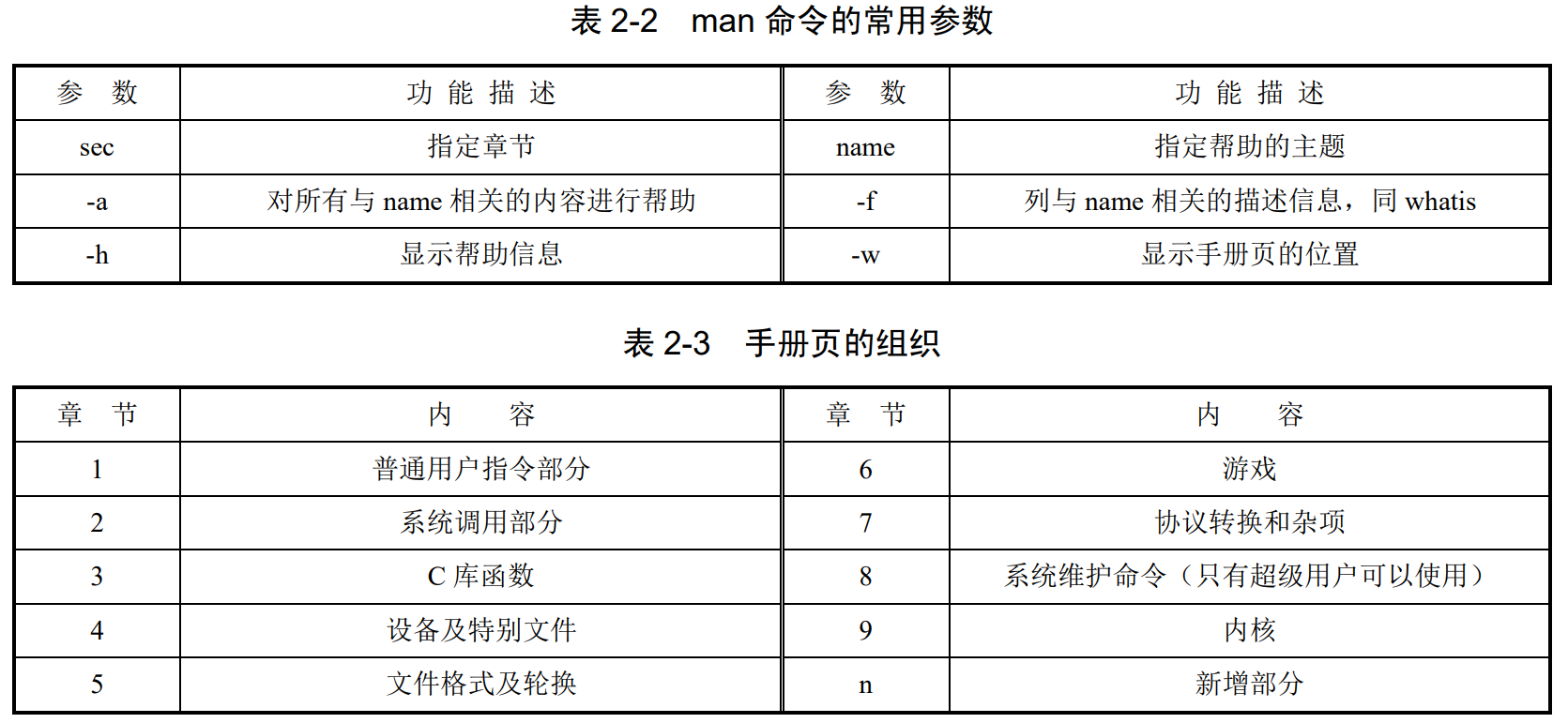
#sec --section
#-f --whatis 简单信息
#-w --where
man [-afhw] [sec] name
#man [命令名] 如 man ls
#man -w passwd #查询首个与 passwd 相关的帮助文件
--/usr/share/man/zh_CN/man1/passwd.1.gz
#whatis passwd #查询对 passwd 的简单说明
#man -f passwd #同上
--
命令 章节 作用
passwd (1) - 更改用户密码
passwd (5) - 密码文件
passwd (1ssl) - OpenSSL application commands
#man 1 passwd #命令用法
#man 5 passwd #文件格式
如果-a 会依次打开所有相关的帮助文件
#man -a passwd :

man 手册页文件存放在/usr/share/man/man?目录下,?是章节数,文件名命名规则为: 手册名称.章节号.gz




textinfo
textinfo 是 Linux 系统提供的另外一种格式的帮助信息。和 man 相比,textinfo 具有更好的交互功能。它支持链接跳转功能。通常使用 info 和 pinfo 命令来阅读 textinfo 文档。
运行 info,可以在 shell 提示符后输入 info(不要参数),它将列出一个文档的清单。
将光标移动到带有“*”的主题菜单上,然后按回车键 进入该主题

在这个界面还可以m [name]进入主题,如:m gcc
也可在shell就指定帮助项目,如 info gcc。
使用“Tab” 将光标移到链接,并按“Enter”进入链接。按“p”返回上一页,按“n”翻到下一页,按“u” 回到文档的上一层,按“q”退出 info。
yelp
(1)在 GNOME 的“系统”菜单上选择“帮助”。
(2)在 CLI 界面执行命令 yelp。
第三章
两选择,两填空,一个简答,一综合(写grep命令),17分
p27,3.1.2字符与保留字
字符
-
白空格
在 UNIX/Linux 系统中,空格和 Tab 称为白空格(White Space),主要用于命令行中命令名、参数及选项的分隔。在特殊情况下,白空格中也可包含回车字符。 -
通配符
通配符用于模式匹配,如文件名匹配、路径名搜索、字符串查找等。常用的通配符有“”、“?”和括在方括号“[]”中的字符序列。用户可以在作为命令参数的文件名*中包含这些通配符,构成“模式串”,在执行过程中进行模式匹配。(1):代表从它所在位置开始的任何字符串,例如,“f”匹配以 f 打头的任意文件。但文件名前的圆点“.”和路径名中的斜线“/”必须显式匹配。例如,“*”不能匹配.file,而“.*”才可以匹配**.file**。
(2)?:代表它所在位置上的任何单个字符。 cd /r?ot 等于 cd root
(3)[ ]:每次只匹配“[]”中字符的一个。方括号中的字符范围可以由直接给出的字符组成,也可以由表示限定范围的起始字符、终止字符及中间的连字符“-”组成。例如,f[a-d]与 f[abcd]的作用相同。[ ]内的第一个字符若为“^”或“!”,表示非运算,意为不匹配[ ]内的任何字符,例如,[!a-d]或[^a-d]表示不匹配方括号内 a-d 的字符集,但匹配[ ]之外的字符集。
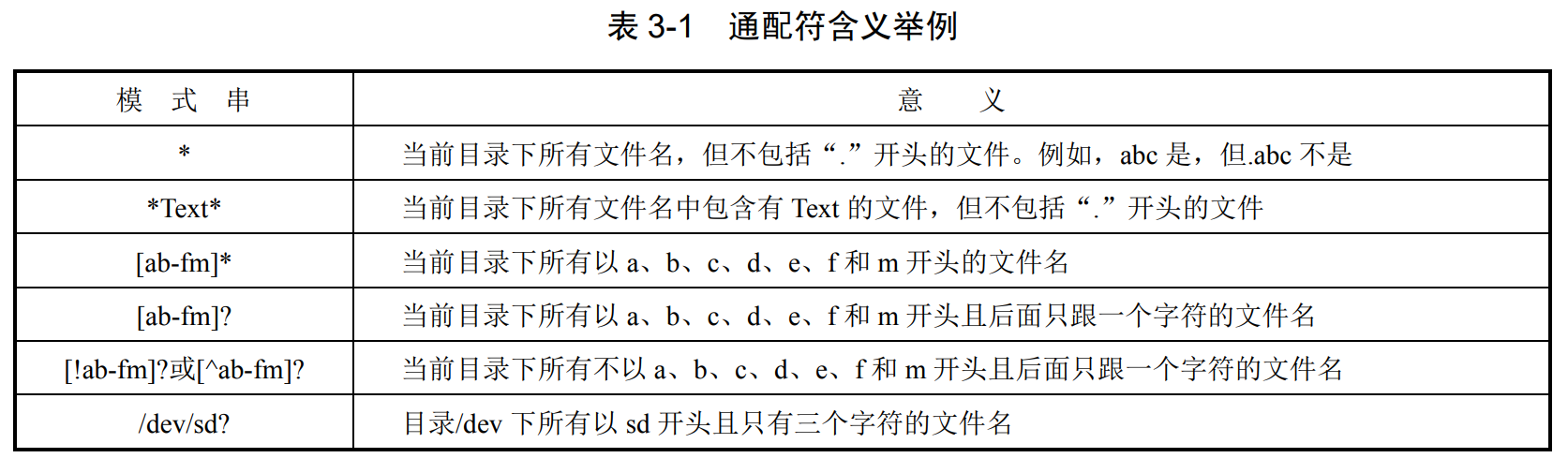
相应的字符有相应的作用域:
连字符“-”仅在方括号内且在中间时有效,表示字符范围;字符“^”和“!”只在方括号内且位于始位置才起“非”的作用,而“*”和“?”只在方括号外面是通配符。
-
注释
从字符“#”开始以后到行末的部分作为注释
1)行首需要使用“#”
2)行中需要使用“#”注释,则“#”前至少要有一个白空格。
-
转义字符
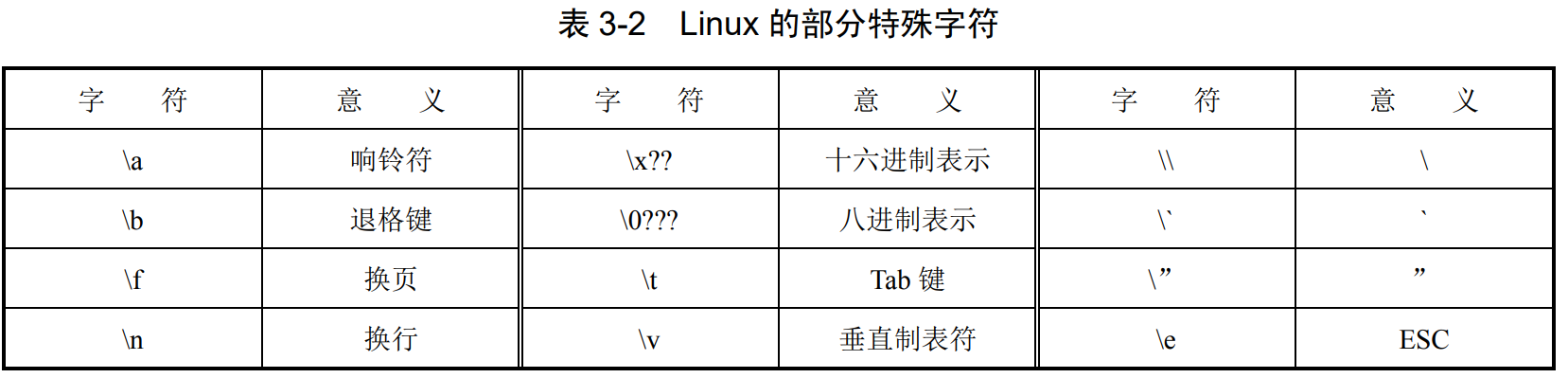
特殊键
保留字
bash 的部分保留字如下: !,[,],(,),{,},break,continue,cd,echo,eval,exec,exit,export,function, getopts,hash,pwd,read,readonly,return,select,set,shift,test,time,trap,type,ulimit, unset,umask,wait,for,do,done,case,in,esac,if,else,elif,fi,while,until。
p39,3.1.3 文件类型;
文件名
- 它由字母、数字、下画线和圆点组成
- 长度限制在 255 个字符以内
- 可以有多个原点".",也可以原点为首字符
文件类型
三种基本的文件类型:普通文件、目录文件和设备文件
1)普通文件
普通文件是用于存放数据的文件,它是用户最经常面对的文件,又可分为文本文件和二进制文件。
(1)文本文件:以可阅读的 ASCII 码形式存储在计算机存储器中,大多数情况下,是以 “行”为基本结构的一种信息组织和存储方式。
(2)二进制文件:是一般不能直接读懂的文件,只有通过相应的软件才能对其进行操作。 二进制文件一般是经编译程序编译后生成的可执行程序、图形、图像或声音等。
2)目录文件
目录文件简称为目录或子目录,在图形界面下称为文件夹。它的命名规则与文件命名规则相同。用于存储一组相关的文件项信息或文件说明信息,其中包括文件名及其属性的信息。具体内容是一张映射表,记录了该目录下所有文件和子目录的 文件名 和对应的 inode 编号(索引节点)
#在 ls -l 命令的输出中,目录文件的第一个字符为 d
ls -l
>>
总计 12
drwxrwxr-x 5 ct ct 4096 3月 25 14:04 csapp-lab #目录文件
drwxrwxrwt 3 ct ct 4096 4月 19 15:17 linuxExp #目录文件
-rw-r--r-- 1 root root 10 4月 20 00:44 t1.txt #普通文件
文件项信息数据结构如下:
struct dir_entry {
__u32 inode; //i 节点号,32 位无符号长整数
… … … …
unsigned char name[255]; //文件名,最长为 255
};
当文件系统对文件进行搜索时,首先按名存取,查到文件名后,再由文件名得到对应的 i 节点号,最后通过 i 节点号找到文件属性和位置信息,从而实现对文件的访问。 一个目录文件内至少要有两个文件项:“.”—当前目录;“…” —上级目录。
目录文件的大小只能增加,尽管可以从目录中删除文件或子目录,但不能使目录变小。 使目录变小的方法是删除后重建。
3)设备文件
“设备特别文件”,简称为设备文件
UNIX/Linux 系统把每一个 I/O 设备都看成一个文件。设备文件除了在目录文件和文件说明信息表(i 节点) 中占据相应的位置之外,并不占有实际的物理存储空间。
当用户使用设备文件时,可通过设 备的名称得到其 i 节点,然后通过其中的主、次设备号取得与内核中设备驱动程序的联系, 从而达到访问设备的目的。
通常情况下,设备文件存放在系统的设备目录/dev 下。
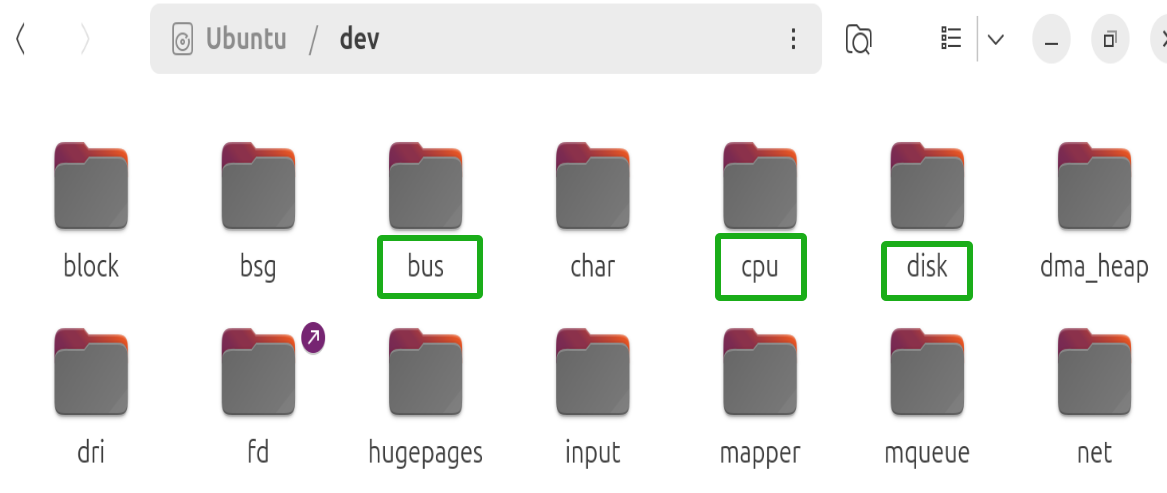
常见设备文件有以下几种。 (括号里是文件类型标识符)
(1)块设备文件(b):以块方式存取的设备,如硬盘、磁盘、磁带等。
(2)字符设备文件(c):以字符方式存取的设备,如字符打印机、显示器等。
(3)符号链接(l):用于通过此文件的内容指向它所链接的文件或资源。 (类似 Windows 的快捷方式)
(4)套接字文件(s):套接字分为文件套接字和网络套接字。文件套接字存在于文件系 统中,让用户以文件的方式访问网络连接。
(5)管道设备文件(p):用于进程之间通信的先进先出(FIFO)“临时文件”。 管道设备有以下两类。(1)无名管道:主要用于有直接继承关系的父子进程之间的通信。当创建无名管道的进程结束后,无名管道自动消失。 (2)命名管道:命令管道是一种特殊的设备文件,在文件系统里以文件形式的存在。由 于是以文件形式存在的,使得有家族关系的进程间可使用其进行通信,不具家族关系的进程 也使用其进行通信。在通信结束后,若不主动删除它,它不会自动消失,而仍以文件的形式 存在于文件系统中。
文件链接也有如下两类。 (1)硬链接(-):两个或多个文件名共用一个文件体,也就是说一个文件可以具有多个 不同的名字,但它们具有相同的 i 节点号。 (2)符号链接(l):与硬链接不同的是,它们不是同一个文件,各有自己的 i 节点,但 可以通过符号链接文件的内容访问被链接文件。符号链接也叫软链接,在 Windows 系统中被 称为快捷方式。
硬链接直接指向文件的 inode(索引节点),由于不同文件系统的 inode 编号独立,故不能实现跨越文件系统的链接。符号链接存储目标文件的路径字符串,可以跨文件系统链接,可以指向网络资源、可以指向一个不存在的资源或位置
p45 3.1.6标准流与I/O重定向
标准流
当执行一个命令时,shell 通常会自动为其打开三个标准流(文件)
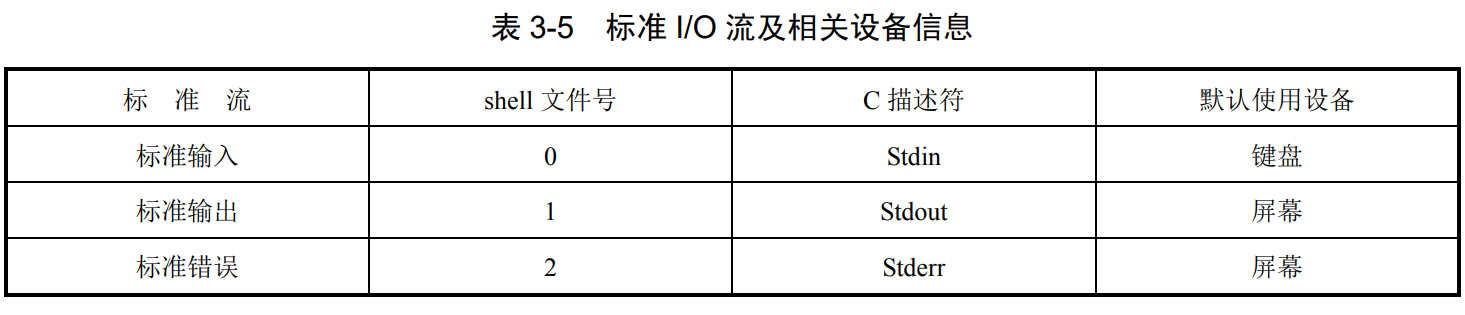
直接使用标准流存在以下问题:
(1)输入数据从终端输入时,用户输入的数据只能用一次,易出错且修改不便。
(2)输出到终端屏幕上的信息只能看,不便使用。
I/O重定向
实验二
(1)<:标准输入重定向。
#命令 wc 可用于统计指定文件包含的行数、单词数和字符数。
#wc < /etc/passwd #标准输入重定向
(2)>:覆盖方式标准输出重定向。若文件不存在则创建之,否则覆盖之。
(3)>>:追加方式标准输出重定向。若文件不存在则创建之,否则在其尾部追加。
#> 与>>的默认文件号为1,即标准输出
#ls > /tmp/dir.out
#覆盖方式,将当前目录信息重定向到文件/tmp/dir.out
#ls /usr >> /tmp/dir.out
#追加方式,将/usr 信息重定向追加到/tmp/dir.out
#对标准错误改道时要使用文件号 2,在 2 和>之间不能有空格。
$ ls -l /home/w-w-w 2> /tmp/err.out
#将标准错误重定向到文件/tmp/err.out
$ cat /home/w-w-w 2>> /tmp/err.out
#将标准错误追加到文件/tmp/err.out
#也可以对一个指令进行不同的重定向,将 stdout 与 stderr 分别存到 list_right 和 list_error 文件中
cat /home/noFile > list_right 2> list_error
(4)&>:标准输出和标准错误同时重定向。
(5)&>>:标准输出和标准错误同时重定向追加。
使用方法同上喇。
标准输出的重定向有副作用:一是它可能覆盖已经存在的文件,二是它可能会在一个具有完整意义的文件后面追加一些外来或无意义的信息。
p53,3.2.1 目录操作基本命令
ls

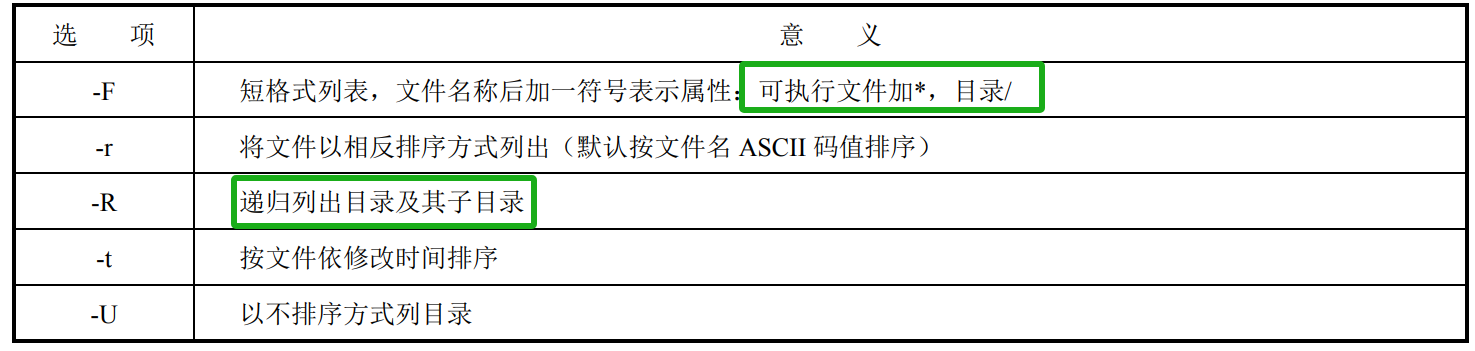
#ls -ltr s* #列出当前目录下所有名字以 s 开头的文件,按修改时间倒排序
#ls -lR /bin #递归列/bin 目录及其子目录
#ls -ad .* #列所有文件名为.开头的文件
#ls -AF #列当前目录,在目录名后加/,可执行文件名后加*
#ls -lid /usr/bin/ls /dev/sda /etc #以长格式列文件且列出文件和 I 节点号

各域的意义是:①I 节点号;②文件类型;③权限;④链接数;⑤主;⑥组;⑦普通文 件为长度,特别文件为主次设备号;⑧最后修改时间;⑨文件名。
mkdir与rmdir
mkdir [-p] [-m MODE] dirs
#mkdir temp #在工作目录下,建立一个名为 temp 的子目录
#mkdir temp2 temp3 temp4 #一次创建多个目录
#mkdir –p temp5/child #在子目录 temp5 下创建子目录 child,若父目录不存在
#则一同创建之。若不使用-p 参数,在父目录不存在时,将导致子目录创建失败
rmdir [-p] dirs
使用-p 参数,rmdir 在删除一个目录时,若其子目录也是空的,则一并删除。
#rmdir temp #删除子目录 temp,若非空则报错
#rmdir -p a/b/c #删除目录时一同删除其空子目录
##注:若 a 只有子目录 b,b 只有子目录 c,则以上命令等同于:
#rmdir a/b/c;rmdir a/b;rm a
cd命令
cd [dir]
它需要一个目的目录作为参数,若不指定,则默认切换到用户的家目录$HOME
#cd /tmp #切换到目录/tmp
#cd ~- #切换到刚离开的目录。相当于 cd $OLDPWD
#cd .. #切换到上级目录
#cd #切换到家目录$HOME。相当于 cd $HOME
PWD
print working directory
pwd [-P] [-L] 选项-P、-L 分别用于显示当前目录的物理和逻辑位置,默认为后者。
p63,3.2.4 文本文件编辑与操作
正则表达式
一个正则表达式包含以下内容:
(1)字符集:在指定位置上匹配的一个或多个字符;
(2)计数:指定其前面的字符重复的次数,比如“*”、“?”、“+”;
(3)位置字符:特殊字符集,用于标明位置,比如行首、行末等;
(4)具有特殊意义的字符。
在有些 UNIX 系统中 awk,egrep 使用 ERE,而grep, sed 和 vi使用 BRE
在BRE中 ?、+、|、()、{}需用反斜杠转义(如 ?、+)才能启用特殊含义
(1)字符集
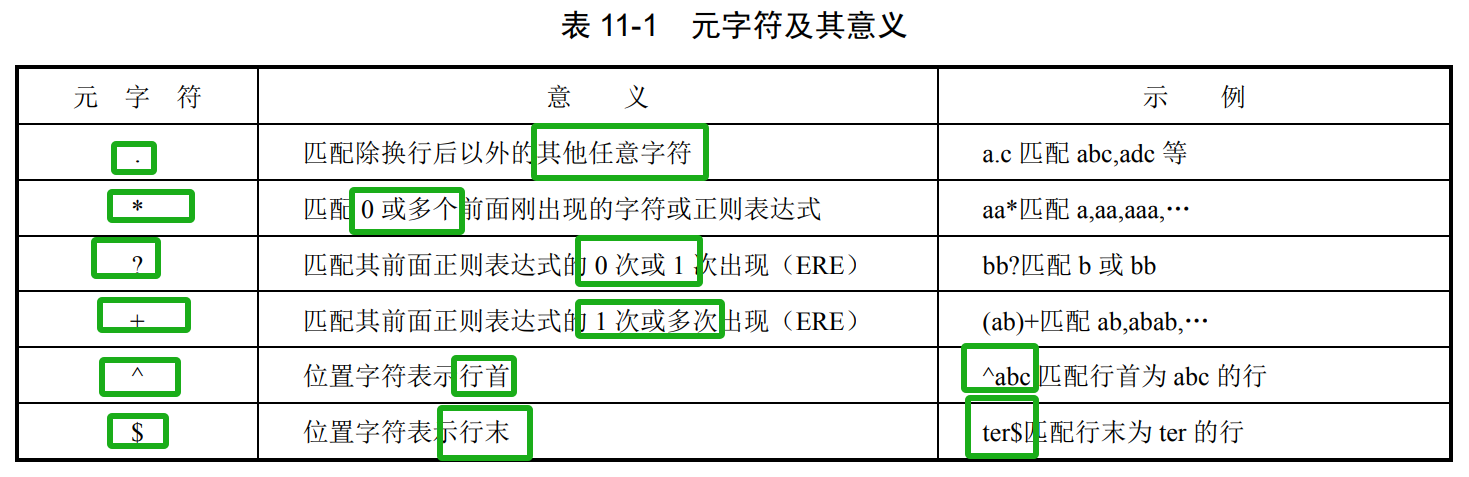
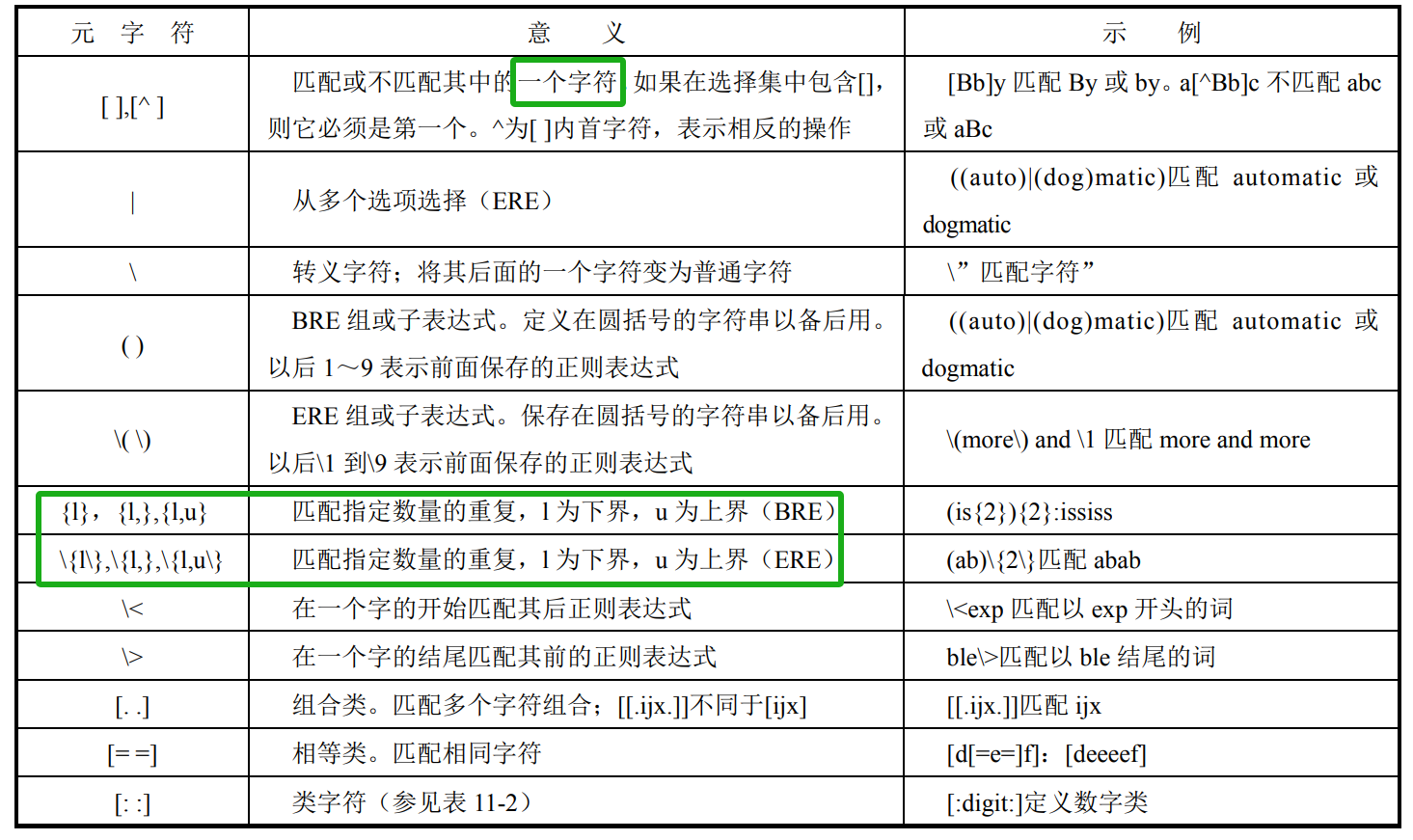
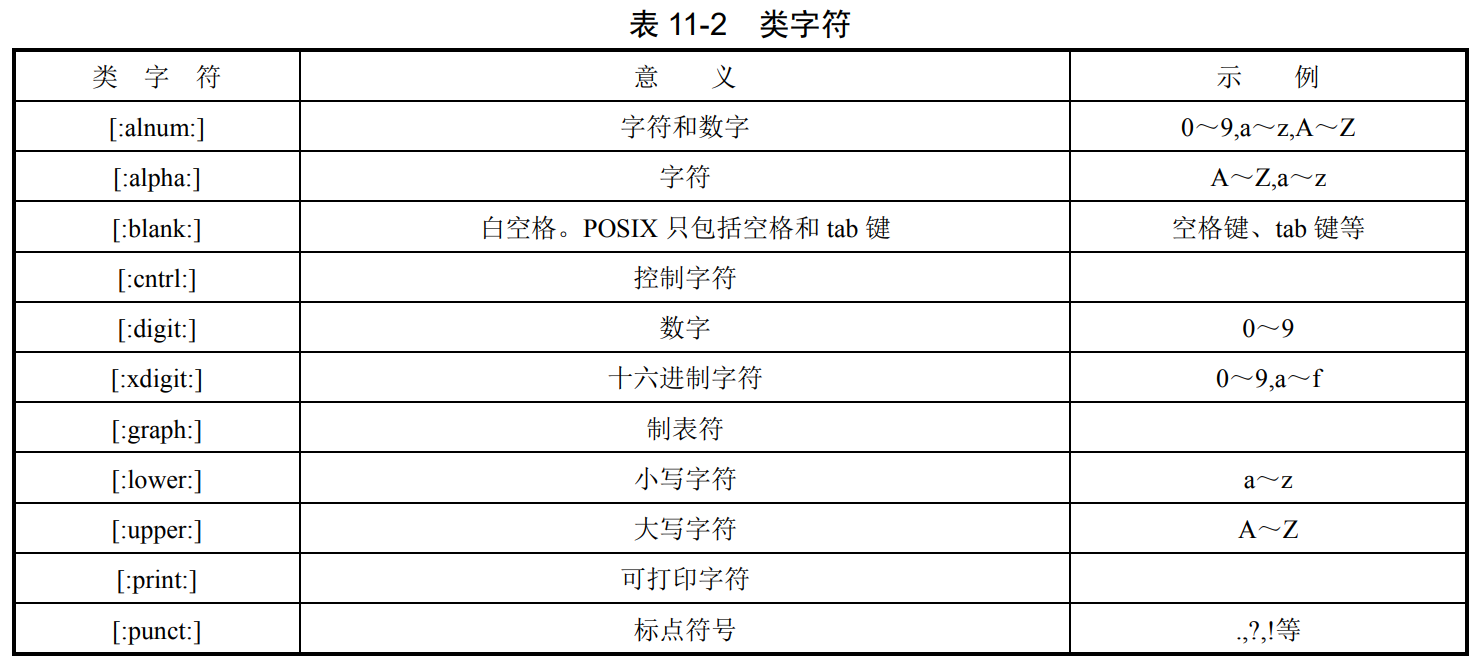
去11章
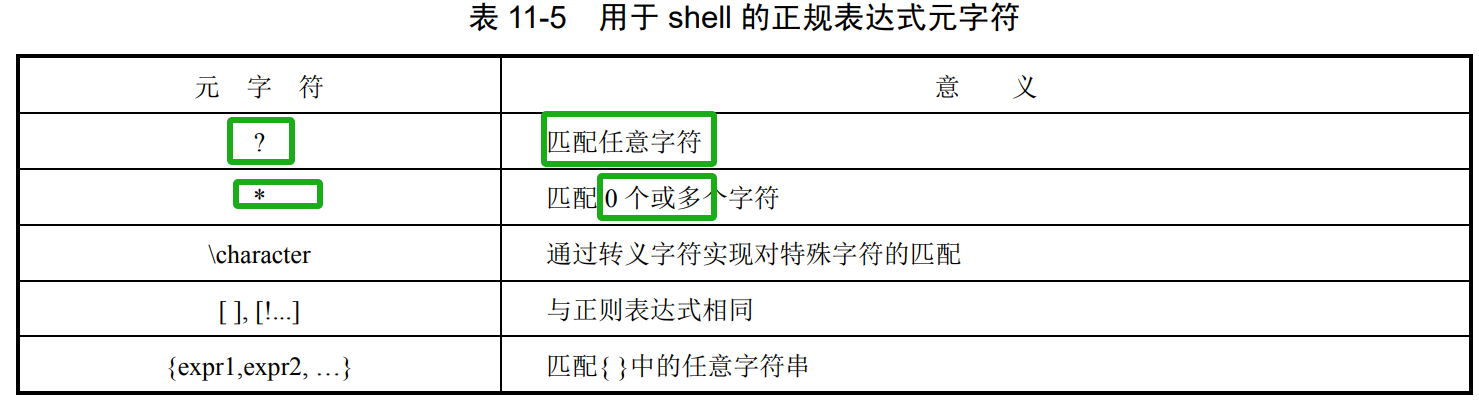
shell 正则表达式
用于 shell 的正规表达式元字符如表 11-5 所示
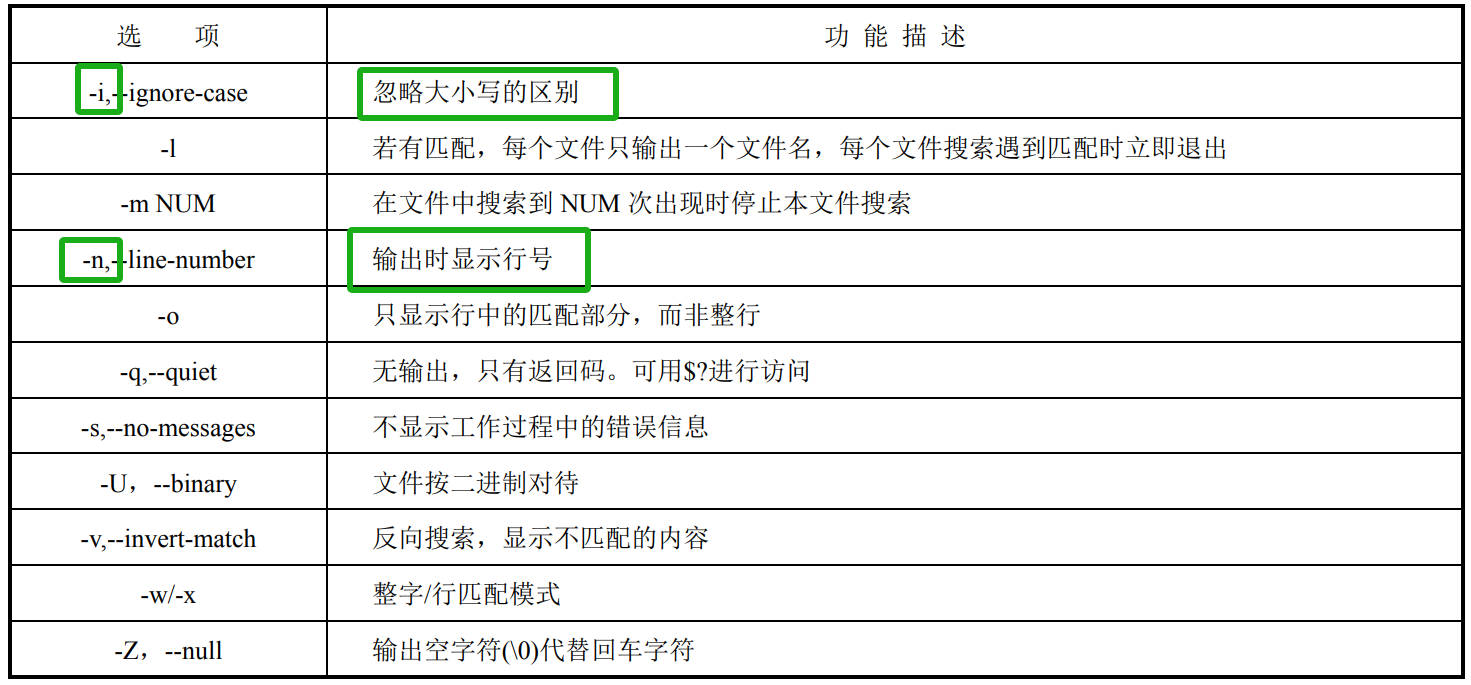
字符串过滤(grep)
去11章
Global Regular Expression Print(全局正则表达式打印)
它主要用于在文件或输入流中快速查找、过滤和提取符合特定模式的文本行
grep 使用标准正则表达式,egrep 使用扩展正则表达式,fgrep 则使用固定的字符串。
以 grep 为例,它的用法为:
grep [options] pattern [files]
grep [options] [-e pattern | -f patternfile] [files] 若不指定搜索的文件,则默认为标准输入。

用以下内容做测试:
//testgrep.txt
popq %rax (%rax = 0x59b997fa) (location: 0x4019ab)
retq (jmp location: 0x4019c5)
movq %rax,%rdi (location: 0x4019c5)
retq (jmp location: touch2 4017ec)
$ grep "retq" testgrep.txt #搜索包含 retq 的行
retq (jmp location: 0x4019c5)
retq (jmp location: touch2 4017ec)
$ grep -A2 "movq" testgrep.txt #显示匹配 movq 的行及其后2行
movq %rax,%rdi (location: 0x4019c5)
retq (jmp location: touch2 4017ec)
$ grep -o "0x[0-9a-f]{6}" testgrep.txt #仅仅匹配文本,而非整行
0x59b997
0x4019ab
0x4019c5
$ grep -c "retq" testgrep.txt #统计次数
2
$ grep "^popq" testgrep.txt #匹配开头
popq %rax (%rax = 0x59b997fa) (location: 0x4019ab)
$grep -E "0x[0-9a-f]{6}" testgrep.txt
$ grep "0x[0-9a-f]{6}" testgrep.txt
#-E 就不用转义,不然就要转义
$grep "0x[0-9a-f]{6}" testgrep.txt #匹配0-9或者a-f,匹配6次,因为BRE,所以转义{}
popq %rax (%rax = 0x59b997fa) (location: 0x4019ab)
retq (jmp location: 0x4019c5)
movq %rax,%rdi (location: 0x4019c5)
书上的案例:
(1)使用扩展正则表达式在 file 文件内搜索 someone、Someone、Anyone 或 anyone:
#grep -E '([Ss]ome)|([Aa]ny)one' file
(2)使用扩展正则表达式在 file 文件内搜索 henry、Henry、henrietta 或 Henrietta:
#grep -E '[Hh]enr(y)|(ietta)' file
(3)使用固定表达式在/etc/passwd 内搜索 root 用户:
#grep -F root /etc/passwd
(4)多文搜索。使用一般正则表达式在 a*、b*和 c*中搜索 mytext:
#grep mytext [abc]*
(5)流搜索。在目录/dev 内搜索文件名中含字符串 sda 者:
#ls /dev | grep 'sda' #|(管道),将 ls /dev 的输出作为输入传递给 grep 命令。
(6)反向搜索,显示不匹配的内容。即在文件/etc/inittab 中搜索非注释行(行首字符不为#的行):
#grep -v "^#" /etc/inittab
vi编辑器
vi 一次可以编辑多个文件,若 vi 启动时没有指定文件名,则 vi 将创建一个无名的工作 文件,待用户保存时由用户指定文件名。
若用户指定的文件不存在,则 vi 就创建一个新文件。 若用户对文件的修改不保存,则原文件不发生作用。
设 vi 编辑的文件为 file,则 vi 在工作时,在与被编辑文件相同的目录内创建一个名 为.file.swp 的临时文件,若没有指定文件名,则在当前目录下创建.swp 临时文件.
vi 结束对当前文件编辑后,对应的临时文件被自动删除,但当 vi 非正常退出时,此临时文件就会被残留下来,在下次再编辑此文件时会出现错误信息。Vi 的整个 工作过程和被编辑的文件无关,只是在保存的时候才修改被编辑的文件。
工作模式
vi 有三种工作模式:命令模式、编辑模式和命令项模式.
(1)命令模式:当进入 vi 时,它处在命令模式。在这种模式下,用户可通过 vi 的命令 对文件内容进行处理,如删除、移动、复制等,也可通过插入命令进入编辑模式。
(2)编辑模式:用户可在命令模式下通过 o,O,a,A,i,I 等命令使 vi 进入编辑模式。 在编辑模式下,用户能在光标处输入内容,或通过光标键移动光标,也可通过按 Esc 键返回 命令模式。
(3)命令项模式或叫底行模式:在**命令项模式下用户输入冒号“:”**后,光标会跳到底行, 输入相关命令后可完成指定操作。
rpm
红帽系列的系统都以 rpm 和 yum/dnf 作为软件包管理工具,Ubuntu 的软件包管理工具为 dpkg 和 apt 相关的工具,它们都将在系统安装时被自动安装。
1.概述
(Red Hat Package Manager)
基于 GPL 。它最初用于 Red Hat Linux 系统。
2.分类
- 可执行的二进制包
- 源程序和用于生成二进制可执行程序的源代码包。
3.文件名格式
pkgname-version.type.rpm
以 bash 包 bash-4.3.42-7.fc24.i686 为例说明如下。
(1)pkgnam 软件包名,bash。
(2)version:版本号,bash-4.3.42-7.fc24。
(3)type:i686。
可能类型有 alpha(alpha 平台)、i[3456]86(Intel x86 平台)、sparc(sparc 平台)、src(源代码)和 noarch(通用,不分平台)。
(4)rpm:扩展名,不可变。(这里省略了)
4.命令
(1)rpm {-q | --query} [options] #查询
(2)rpm {-i | --install} [options] packages #安装
(3)rpm {-e | --erase} [options] packages #删除
(4)rpm {-U | --upgrade} [options] packages #升级安装
(5)rpm {-F | --fresh} [options] packages #重新安装
(6)rpm {-V | --verify} [options] #校验
① rpm 用于查询的常用形式有:
rpm -qa #查询所有已安装的包
rpm -q pkgname #查询指定包
rpm -qi pkgname #查询已安装包的详细信息
rpm -ql pkgname #查询已安装包中的内容
rpm -qf filename #查询指定文件的归属包
rpm -q -provides pkgname #查询软件包功能信息
rpm -qR pkgname #查询包的最低依赖要求
rpm -qp rpmfile #查询 rpm 包文件中的内容
② 查询示例。
#rpm -q dhcp #查询是否安装了软件包 dhcp
#rpm -qa | grep sysstat #查询是否安装了软件包 sysstat
#rpm -qi dhcp #查询软件包 dhcp 的详细说明信息
#rpm -ql dhcp #查询 dhcp 软件包的内容
#rpm -qf `which bash` #查询 bash 命令的归属包
(2)安装。
① rpm 用于安装软件包的常用形式为:
rpm -ivh package #安装软件包 package
#-v(--verbose)
#作用:启用详细(verbose)模式,显示安装过程中的详细信息,包括解压、配置和文件复制等步骤
#-h(--hash)
#作用:以哈希标记(#)的形式显示安装进度条(hash marks),提供更直观的安装进度反馈
② 安装示例。
#rpm -ivh sysstat* #安装软件包 sysstat,需先下载到本地
#rpm -qa | grep sysstat #查询安装结果
(3)升级。
对指定软件包的升级可以使用以下形式的 rpm 命令:
rpm -Uvh packages
(4)删除。
对指定软件包的删除可以使用以下形式的 rpm 命令:
rpm -e packages
(5)验证
rpm -Va 验证所有已经安装的包
rpm -V pkgname 验证已安装包包
rpm -Vf filename 验证包含指定文件的包
rpm -Vp rpmfile 验证未安装的rpm 包文件,


dpkg
命名
ubuntu 采用了 Debian 的软件包管理机制,文件的后缀为**.deb**
两种类型的软件 包:二进制软件包(.deb)和源码包(.dsc)
-
filename_version_reversion_architechture.deb
-
filename_version_reversion_architechture.dsc
filename 为软件包名;version:为版本号;reversion 为修订版本号;architechture 为体系结构或类型;.deb 为扩展名。
管理
软件包管理的工具是 dpkg 和 apt 两个软件包,其中包含的常用工具有 dpkg、apt-get 和 apt-cache 等
dpkg 用于本地软件包的管理,其用法为:
dpkg [option…] action
#常用功能如下。
-i, --install package-file ...:安装
--unpack package-file ...:解包
-V, --verify [package-name ...]:校验
-l, --list package-name-pattern ...:列出已经安装的包,类似 rpm -qa
-L, --listfiles package-name ...:列出已经安装软件包的内容,类似 rpm -ql
-r, --remove package ...:删除软件包
-P, --purge package ...:清理已经安装或被删除的软件包(包括配置文件)
-S, --search filename-search-pattern ...:显示文件归属的软件包。类似 rpm -qf
-s, --status package-name ...:报告软件包的状态信息
| 命令 | 作用 | 是否删除配置文件 |
|---|---|---|
dpkg -r | 卸载软件包 | 否 |
dpkg -P / --purge | 卸载并删除配置文件 | 是 |
$ dpkg -L bash #列出 bash 包的内容
>>
/.
/etc
/etc/bash.bashrc
/etc/skel
/etc/skel/.bash_logout
/etc/skel/.bashrc
/etc/skel/.profile
$ dpkg -S `which bash`
>>
bash: /usr/bin/bash
$ dpkg -s bash
>>
Package: bash
Essential: yes
Status: install ok installed
Priority: required
...
apt-get 命令的用法为: apt-get [options] [action]
常用选项如下。
-d, --download-only:只下载
-f, --fix-broken:试图修复已破坏的依赖关系
-m, --ignore-missing:忽略丢失包
-q, --quiet:安静工作
-s, --simulate, --just-print, --dry-run, --recon, --no-act:仅模拟而不真正工作
-y, --yes, --assume-yes:默认为 yes
--assume-no:默认为 no
-u, --show-upgraded:显示被升级的包信息
--no-upgrade:安装时不升级
--only-upgrade:只升级
--show-progress:显示进度
-h, --help:帮助
--reinstall:重新安装最新版本
--purge:删除包时使用 purge,remove --purge 等同 purge
常用功能如下。
install:安装
update:更新包索引
upgrade:更新软件包
dist-upgrade:将系统升级到新版本
remove:删除
purge:删除并清理
source:获取源代码包
check:检查,更新缓存,检查可调整关系
download:下载包
autoclean:将已经删除了的软件包的.deb 安装文件从硬盘中清除
clean:删除包缓存中的所有包
autoremove:删除为了满足其他软件包的依赖而安装的、但现在不再需要的软件包
使用示例如下。
apt-get update:更新包索引。在修改源后需运行该命令,或运行该命令以确保包索引是
最新的
apt-get upgrade:更新所有软件包
apt-get dist-upgrade:将系统升级到新版本
apt-get install vsftpd:安装 vsftpd 服务器
apt-get source vsftpd:下载 vsftpd 源代码。需要在 sources.list 中至少指定一个 URIs
第四章
一选择,一填空,一综合(写命令),8分
p119,4.2.1/etc/passwd
/etc/passwd 是系统用户数据库文件,它包括系统内所有已经注册用户的信息。该文件是 一个文本文件,它的每一行描述一个用户的信息,为由“:”分隔的 7 个字段。结构为:
username:[password]:uid:gid:[comment]:dir:[shell]
username:用户名,必须以字符开始,不要使用大写字母。
password:密码。在 Linux 系统中此项一般设置为“x”,用于表示使用影子密码,此时 密码在/etc/shadow 文件中。
uid:用户标识号。不同的 UNIX/Linux 系统,该项的取值范围可能不同,在 Linux 系统 中该项的取值范围在/etc/login.defs 文件中定义。一般用户 uid 满足条件:UID_MIN≤uid≤ UID_MAX。
gid:组标识号。说明同 uid。
comment:说明域。一般包括用户详细说明信息,如用户全称、住址、电话号码等,此 项内容中不能包含冒号,但可以为空。
dir:用户家目录($HOME),即用户登录成功后所在的工作目录。
shell:用户登录成功后所使用的 shell 程序,也可是用户实用程序,当为空时,系统默认 /bin/sh。如果想让用户登录后直接执行某个程序,如/usr/bin/my_shell,则可修改此项内容为 /usr/bin/my_shell。若此项设置为一个不存在或不可执行的文件,则用户不能成功登录。
cat /etc/passwd
>>
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
有的是真实用户,可以用来登录系统,而有的则不能,但可以它的身份完 成指定任务。这种被称为伪用户,伪用户的登录 shell 一般为 nolgin。例如, bin 用户拥有可执行的命令文件;daemon 用户拥有系统服务进程;lp 用户被打印机子系统使用。
p122,4.3.1用户创建命令
实验四
增加用户(useradd)
useradd [options] user #添加用户
useradd -D #显示默认值
useradd -D [options] #设置默认值

(1)若不带选项运行 useradd,如 useradd newuser,则使用默认方式创建 newuser。若在 创建用户时没有创建家目录,则为保证 newuser 创建后可以登录还必须手工创建 newuser 的 家目录,并修改家目录归属关系和存取权限。
(2)创建用户时,是否创建用户家目录,默认情况下取决于/etc/login.defs 中变量 CREATE_HOME 的值,但可以使用-m 强制创建,也可以使用-M 强制不创建。不创建用户家 目录也是常见的,当多个用户共用一个家目录时,只要第一个用户创建时创建了家目录就可 以,而以后用户直接使用已经存在的目录。这时应该注意目录的存取权限问题,必要时可将 这类用户放在一个组中,但要求目录及内容能被同组人按特定权限访问。
(3)若未指定密码,则在一切准备好后,还必须经超级用户为新建用户设置或修改密码 后才能正常登录和使用。
(4)Linux 默认,在创建新用户时,按新用户名创建一个新组,该组为新用户的归属组, 或称为基本组。如果想让新建用户使用一个已经存在的组,则可使用-g 参数;如果同时还想 让新建用户也归属到其他组,则可以使用-G 参数。
示例
useradd test1
#名为 test2 的用户,且为其创建家目录/usr/test2
useradd –d /usr/test2 –m test2
#用户 test4,让其与 test1 具有相同的 UID、家目录和组
useradd -u `id -u test1` -o -g test1 -d /home/test1 test4
#删除
userdel -r test1 #-r同时删除家目录。
p126,4.5.2密码管理命令
passwd [-k] [-l] [-u [-f]] [-d] [-n mindays] [-x maxdays] [-w warndays][-i inactivedays] [-S] [username]

| -i | 用户密码过期后,账户仍可登录的宽限天数 |
|---|---|
| -n | 最短使用期限,即用户必须等待多少天后才能再次修改密码 |
| -x | 多少天后必须修改 |
除root修改密码,系统将提示用户先输入旧密码
密码在到期前是有效的,若在 有限时间内没有设置或修改密码,则到期后的下一次必须修改密码;一
一个用户可被上锁,上锁后的用户一经退出将不能再登录。
示例
passwd #为用户自己修改密码
passwd test1 #为用户 test1 修改密码
passwd -d test1 #为用户 test1 删除密码
passwd -l user #对用户 user 上锁。上锁后用户不能再登录系统
usermod -L user #同上
passwd -u user #对用户 user 解锁。解锁后用户可以再次登录系统
usermod -U user #同上
passwd -x 2 test2 #设置用户 test2 密码最长有效期为 2 天
p132,4.7.9sudo
su 变换用户,或以其他用户的身份工作。sudo 也允许用户以超级用户或其他用户的身份执行命令。
sudo -h|-k|-K|-V
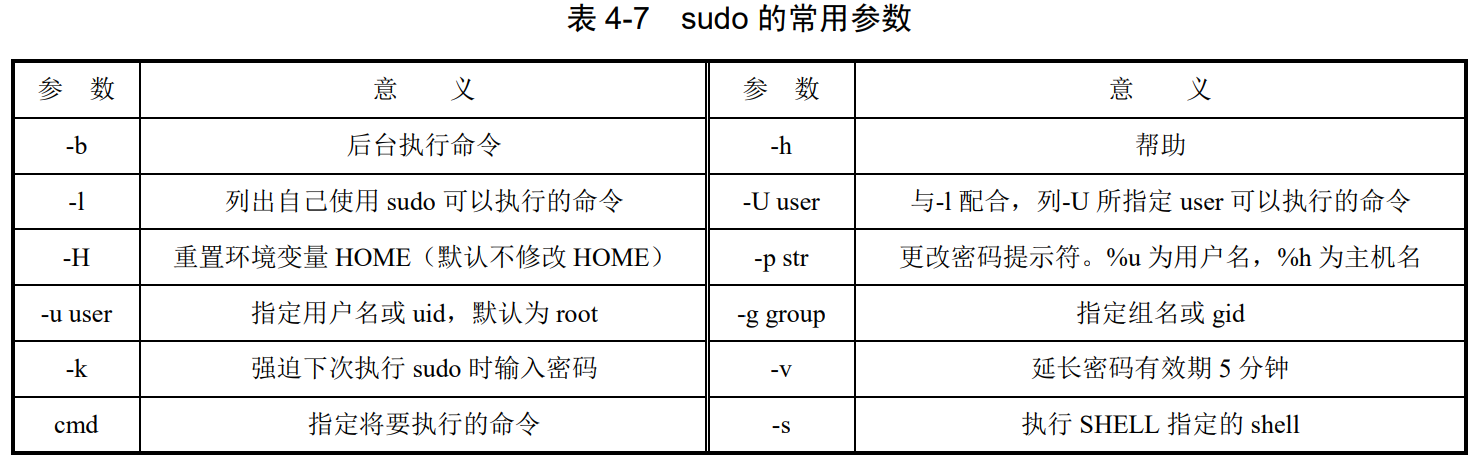
配置文件 /etc/sudoers
编辑命令 visudo
格式:
USERs HOSTs=(RUNASs) COMMANDs
USERs(用户或用户组),HOSTs(主机)可以是主机名(如 server1)、IP 地址或网络段(如 192.168.1.0/24),(RUNASs)(目标用户或身份),COMMANDs(命令)
配置示例:
root ALL=(ALL) ALL #root 可在任何位置以任何人的身份做任何事
%sudo ALL=(ALL) ALL #sudo 组中的用户可在任何位置以任何人的身份做任何事
%wheel ALL=(ALL) ALL #wheel 组中的用户可在任何位置以任何人的身份做任何事
zh3 ALL=(ALL) /sbin/shutdown #zh3 可在任何位置以任何人的身份执行/sbin/shutdown
sudo示例:
$ sudo -l #列出
第五章
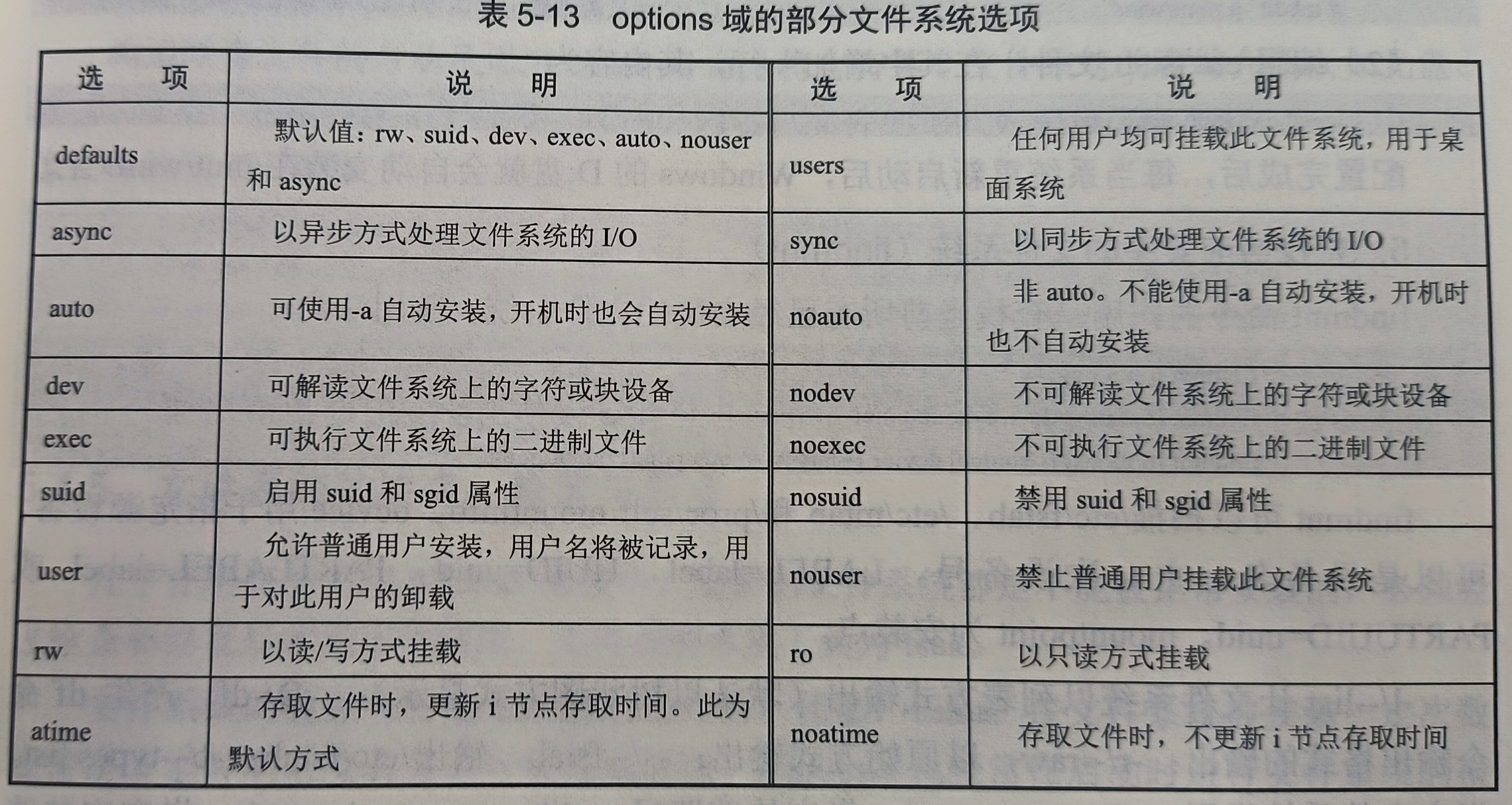
一选择,一综合(权限管理或文件系统挂载),6分
权限管理
p136,文件权限
- 三权
- r 读
- w 写
- x 执行
- 三人
- 用户主(user:u)
- 同组人(group:g)
- 其他人(other:o)
-
示例
每组 3 个字符表示读(r)、写(w)、执行(x) 权限,或
-(无权限):- 所有者(user):第2-4位(如
rwx)。 - 所属组(group):第5-7位(如
r-x)。 - 其他用户(others):第8-10位(如
r-x)。
-rwxr-xr-x. 1 root root 1086480 Sep 30 19:09 /bin/bash #普通文件,所有者:可读、写、执行(rwx)。组和其他用户:可读、执行(r-x),不可写。 lrwxrwxrwx. 1 root root 3 Mar 3 22:09 /dev/cdrom -> sr0 #符号链接的权限无实际意义(始终显示 rwxrwxrwx) brw-rw----. 1 root disk 8, 0 Mar 3 22:09 /dev/sda #块设备文件,所有者(root)和组(disk)可读写,其他用户无权限。 #目录需 x 权限才能进入,r 权限才能列出内容 - 所有者(user):第2-4位(如
-
数字表示
访问权限可用一个三位二进制数来表示。有为1,无为0。可转化为八进制数。
例如目录/dev 的权限为 rwxr-xr-x,111 101 101 即755
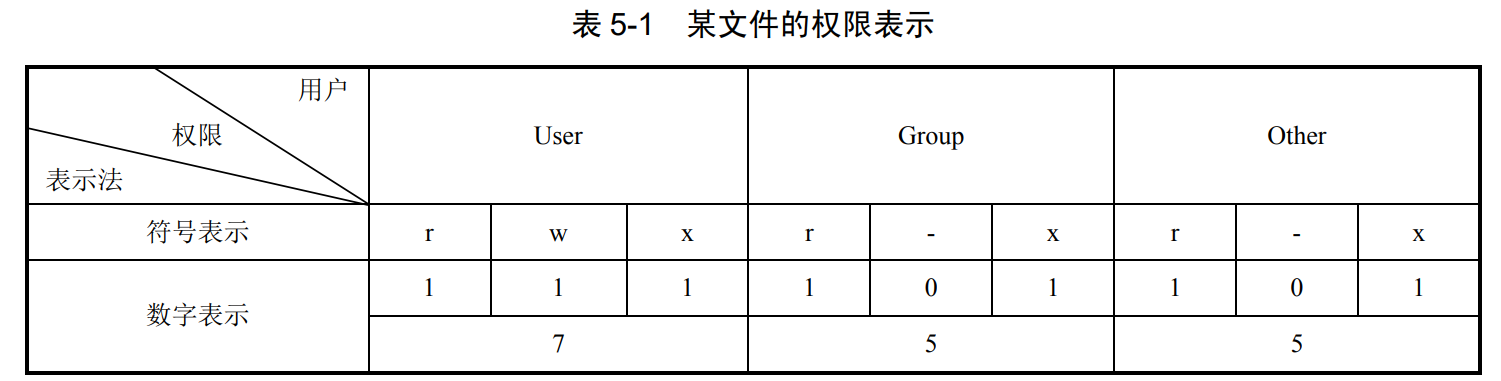
-
默认权限与 umask
在 UNIX/Linux 系统中,当用户创建文件或目录时,将为它们设置默认权限。文件或目 录的默认权限由文件权限掩码 umask 来控制。

p138,权限指令
- 改权限
(1)符号方式:
chmod [options] <+|-|=> ,… file …
(2)数值方式:
chmod [options] num_perm file …

示例
chmod a+x my_p1 my_p2
#为所有用户(all)对文件 my_p1、my_p2 增加执行权
chmod u+rwx,go+rx myp
#为文件主增加所有权限,为组和其他人增加读和执行权
chmod -R o-rwx /tmp/w123
#递归去掉/tmp/w123 内目录和文件对其他人的所有权限
chmod -R 777 /tmp/*
#将/tmp 中的所有文件和各级子目录及内容权限设置为 777
- 改变文件的所有者(chown)
chown root my_files #将 my_files 的所有者改为 root
chown zhang *.c #将当前目录下所有 C 语言文件的所有者改为 zhang
chown -R gjshao /tmp/mydir #递归将/tmp/mydir 的所有者改为 gjshao
chown -R gavin:bin mydat #递归将 mydat 的所有者改为 gavin,组改为 bin
chown -R :bin mydat #递归将 mydat 的组改为 bin
p147,5.4.2SCSI存储设备
SCSI(Small Computer System Interface)接口是小型计算机接口的简称,是一个多用途 的 I/O 接口,除可接磁盘外,还可接磁带机、光驱,扫描仪等设备。SCSI 总线上能连接的设 备类型很多,结构和控制上也与 IDE 不同,这里不做过多介绍。
SCSI 存储设备的形式为**/dev/sdmn**,其中,m∈(a,b,c,d,…)为字符代表物理设备,n∈ (1,2,3,…)为物理设备 n 上的逻辑分区编号。 SCSI 上硬盘设备的命名方法与 IDE 硬盘设备的命名方法相同。例如,/dev/sda、/dev/sdb 分别为第 1、2 个 SCSI 硬盘,/dev/sda1、/dev/sda2 分别代表第 1 个 SCSI 硬盘的第 1、2 分区。
dev/loop*(如/dev/loop15)是虚拟的块设备,称为 loop 设备(或循环设备)。它们的作用是将普通文件(如磁盘镜像、ISO 文件等)模拟成物理磁盘或分区,从而可以像操作真实硬盘一样对其进行分区、格式化或挂载
5.4.fdisk命令
实验五
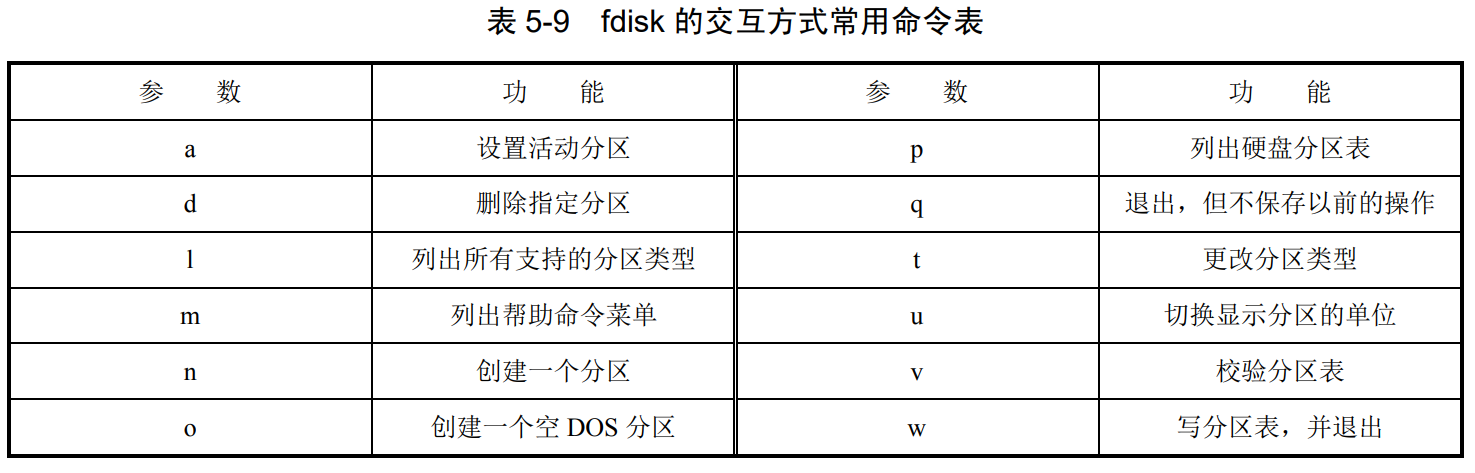
创建分区:
sudo fdisk /dev/sdb # 对 /dev/sdb 进行操作
$n #new
#一直回车用默认选项
$w #保存 q是不保存
创建文件系统:

lsblk -f /dev/sdb1 #查看
mkfs -t ext4 /dev/sdb1
文件系统安装(挂载):

$ mount /dev/sdb1 /newdisk #(挂载目录写绝对路径!)
卸载:
umount dev_mounted #或
umount dir_mounted
5.4.4文件系统的自动挂载
sudo mount /dev/sdb1 /newMountPoint。临时挂载,重启之后就失效;修改/etc/fstab 文件, 永久挂载。
其结构为:
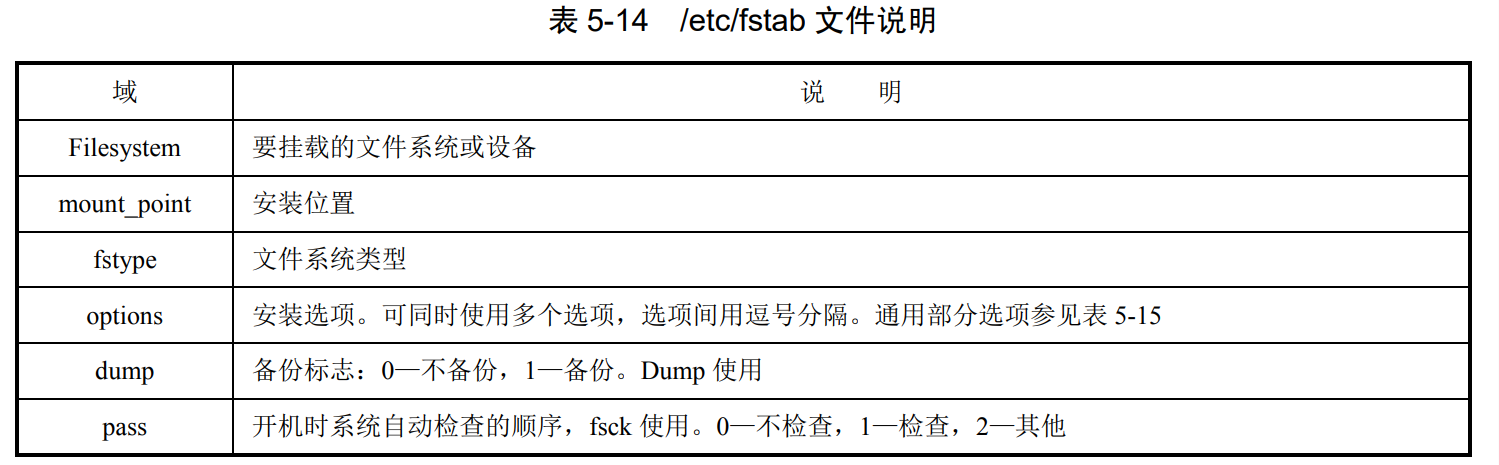

示例:
#1)创建一个安装点/mnt/wind。
mkdir -p /mnt/wind
#2)编辑/etc/fstab 文件,在其中增加一行,其内容为:
/dev/hda5 /mnt/wind vfat rw 0 0
#还可以
/dev/hda5 /mnt/wind vfat default 0 0
第六章
一选择,一综合(写crontab 文件),6分
实验六
p191,6.5.1特殊属性
SUID, Set User ID。有这个属性会以文件所有者的权限运行。它执行时的 uid(有效 uid)将是该程序所有者的 uid,记 为 euid,而执行者原来的 uid 称为真实 uid,记为 ruid。
SGID, Set Group ID。进程以文件所属组的权限运行。同理有egid与rgid。
suid/sgid 属性只对二进制可执行文件有效,而对可执行的脚本文件无效。
suid 和 sgid 的权限则为数字表示为 4000 和 2000。
字符方式则会用s/S替换对应位置的x
- 如果文件原本有执行权限(
x),则显示为s(小写)。 - 如果文件原本无执行权限(
-),则显示为S(大写)。
(1)字符方式。
#chmod u+s myp1 #为 myp1 设置 suid。修改后的权限为 rwsr-xr-x
#chmod g+s myp2 #为 myp2 设置 sgid。修改后的权限为 rwxrwsr-x
#chmod ug+s myp3 #为 myp3 同时设置 suid 和 sgid。修改后的权限为 rwsrwsrwx
(2)数字方法。
#chmod 4755 myp1 #为 myp1 设置 suid
#chmod 2775 myp2 #为 myp2 设置 sgid
#chmod 6777 myp3 #为 myp3 同时设置 suid 和 sgid
Sticky 位。当用于描述目录时,称为限制删除位,用于描述可执行文件时,称为粘着位。粘滞位在权限位的 最后一位
| 权限字符串 | 含义 |
|---|---|
drwxrwxrwx | 目录对所有用户开放读写执行,无粘滞位,任何用户可删除他人文件。 |
drwxrwxrwt | 目录设置了粘滞位(t),用户只能删除自己的文件。 |
drwxrwx--T | 目录设置了粘滞位(T),但其他用户无执行权限(罕见,通常无效)。 |
若目录,则只能被所有者或超级用户删除、更名或移动。
若文件,在早期的系统中,程序执行时的正文段映像 将被锁在交换区中,可使得程序装入更快速。
chmod +t mydir myfile #字符方式。修改后的权限为 1755 或 rwxr-xr-t
chmod 1755 mydir myfile #数字方式
chmod 7755 mydir myfile #数字方式,7就是设置Sticky 位、suid、sgid
6.6.2crontab 文件
at
at 可以接收的 timespec 时间格式为 HH:MM 或 HHMM 形式的时间.也可以now+时间
echo "ct20223465 >> /home/test.txt" | at now +1
minute
at 1200 < myjob #通过输入改道从 myjob 中读取作业,并规定在 12:00 执行
at 12:10 -f myjob #从 myjob 中读取作业,并规定在 12:10 执行
at 1230 #标准输入读取作业,并在 12:30 执行
at>ls -l >/tmp/`whoami`.a #进入 at 界面,输入相关命令。“at>”为提示符
#列出已提交的作业
at -l
#删除已提交的作业
at -d 23 25
crontab
crontab [-u user] file
crontab [-u user] [-l | -r | -e] [-i] [-s]
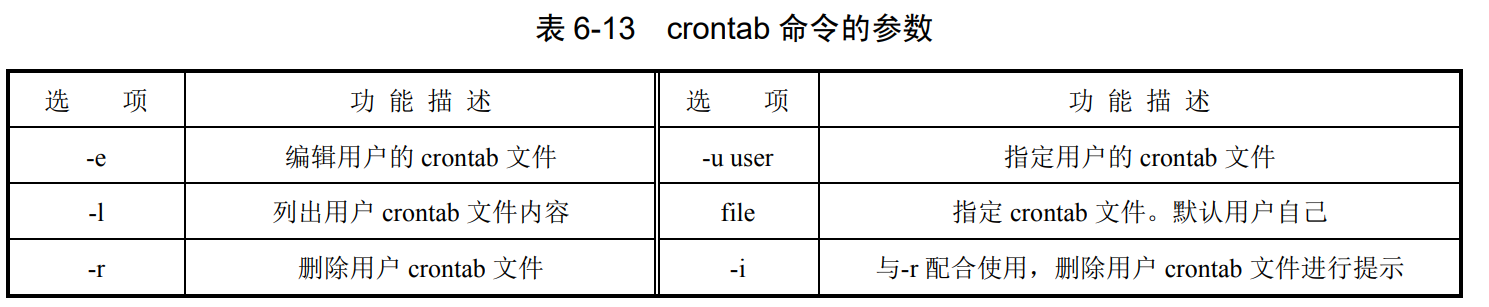
每个可以在/var/spool/cron 下创建与用户名相同的 crontab 文件,如 root、testUser 等
当使用-e 修改用户的 crontab 文件时, crontab 命令自动调用 vi 对文件进行编辑.ubuntu 允许在首次使用 crontab -e 时从已经安装的编辑器 ed、nano 或 vi 中选 择一个编辑器,
文件中#开始的行为注释行、空行无效。
minute hour day month day_of_week command
分 时 日 月 周 命令
#分别是分钟(0-59)、时(0-23)、日期(1-31)、月(1-12)和星期几(0-6,0 表示星期天),月份和星期几也可以用英文表示。
它们可以是以下形式:
(1)数字。
(2)由减号连接的两个数字,表示范围,如 1-5 表示从 1 到 5。
(3)一组由逗号分隔的数字(枚举),如 1,3,5。
(4)*表示所有或任何允许的值。
(5)*/s 表示步长,比如,0-23/2 表示从 0 到 23 每隔 2 个单位发生一次,即 0,2,4,
示例:
#编辑自己的
crontab -e
##定义环境变量 SHELL
SHELL=/bin/sh
##定义邮件接收者
MAILTO=gjshao
##每天的 00:05 执行$HOME/bin/daily.job(假设的任务和程序)
5 0 * * * $HOME/bin/daily.job >> /tmp/out 2>&1
##每周日 3:30 重启系统
30 3 * * 0 /sbin/init 6
##从周一~周五每天 22:00 向 gjshao 发邮件
0 22 * * 1-5 mail -s "It's 10pm" gjshao%Hi,%%Where are your?%
##在偶数点的半点向系统中的用户广播信息
30 0-23/2 * * * wall "run 30 minutes after midnight, evry 2 hours,everyday"
#查看
crontab -l
第七章
一选择,一填空,一个简答,一综合,13分
p204,7.1.2安装Lnux系统所需的基本分区
1.引导分区
引导分区是在硬盘上用于系统启动的分区,不需要太大,够用就行。在 Linux 中有 500MB 就足够了。在 MBR 格式系统中,可引导分区入口必须位于硬盘的 1024 道之前。 在 Linux 系统中也可不设置独立的引导区,此时它共享系统的根分区。这种情况下,对 于 MBR 结构的系统,根分区必须位于 1024 道之前,或者将 Linux 的引导程序 Grub 安装在 MBR 上。
2.根分区
根分区是 Linux 系统的主要工作分区,不能太小,要根据安装系统的内容和将来的用途 来决定,建议 10GB 以上。如果要在 Linux 系统上运行大型数据库则可能会需要更多硬盘空 间,当然数据库也可占用单独的裸分区。
3.交换区
交换区是 Linux 系统用于动态扩充内存的,安装时可以不指定,但是为了保证安装的成功率**,建议设置独立的交换区**。这个用于交换区的独立分区可是硬盘任何形式的分区,大小可参考实际物理内存来确定。对于 8GB 内存以下的系统,建议交换大小为物理内存的 1.5~ 2.5 倍,或再大一点;对于内存为 8GB 或以上者,可与内存容量相等,或小于物理内存。 不论是否指定了交换区,系统安装成功后,在运行时都是需要交换区的。若未指定交换区, 则系统会在自己的根分区上找一块连续的区域用作交换区,此时交换区会占用系统根分区空间。 系统安装完毕后,交换区还可以被扩展或更换,请参见交换区管理部分内容。
4.其他分区
仅从安装的角度,有引导区、根分区和交换区就可以了。在系统工作时可能还需要**/var、 /home、/tmp** 等分区,若不指定则共享系统的根分区。对于用于网络服务的系统**,建议/var使用独立分区**,避免因/var 过多占用,而导致根分区空间被挤占、被用完,从而影响系统的 正常运行。同样,对于运行大型数据库的系统,数据库系统所占用的分区也要足够大,或使 用独立的磁盘或磁盘分区。
7.4.2日志配置文件
怎么修改配置文件
/etc/rsyslog.conf 为 rsyslogd (用于日志管理的核心守护进程)的主配置文件,它规定系统中需要监视的事件和记录相应的 日志位置。描述未尽部分存放在/etc/rsyslog.d(这是个目录) 的子配置文件中。
ls /etc |grep rsys*
>>
rsyslog.conf
rsyslog.d
ls /etc/rsyslog.d/
>>
20-ufw.conf 21-cloudinit.conf 50-default.conf
| 文件名 | 作用范围 | 加载顺序 |
|---|---|---|
20-ufw.conf | 防火墙日志 | 高 |
21-cloudinit.conf | 云初始化日志 | 中 |
50-default.conf | 系统默认日志规则 | 低 |
为了对日志统一管理,系统 的各种日志文件存放在/var/log 目录内。管理员可以通过编辑配置文件 rsyslog 的办法来影响 系统日志的行为。
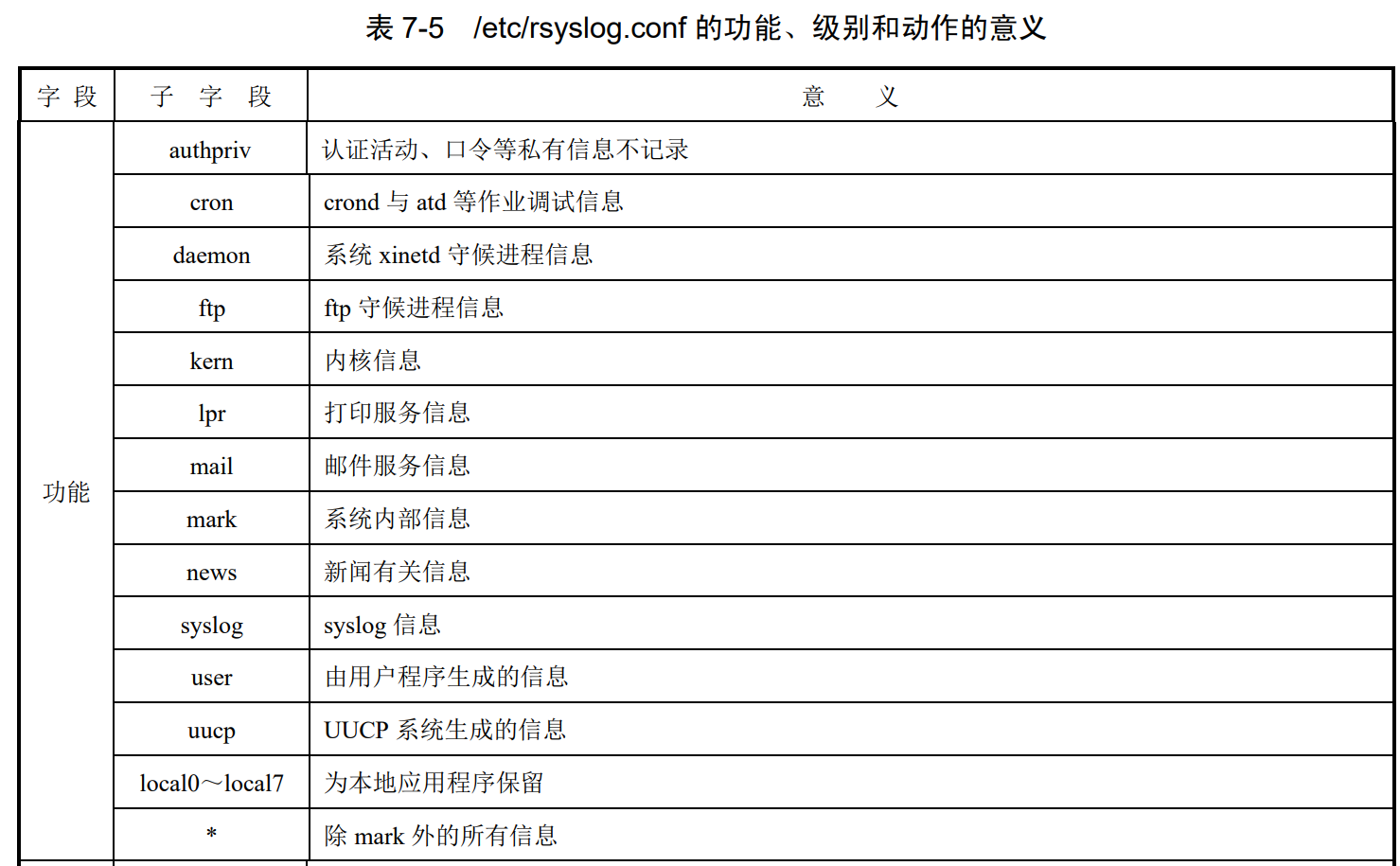

配置格式
日志配置文件每一有效行的格式如下:
选择 动作
可以进一步解释为:
功能.级别 动作
选项和路径之间的分隔符可以是任意数量的空格或制表符(Tab键)
级别操作
“.”代表只要**比后面的等级高的(包含该等级)**日志都记录。比如,“cron.info”代 表cron服务产生的日志,只要日志等级大于等于info级别,就记录。“.=”代表只记录所需等级的日志,其他等级的日志都不记录。比如,“*.=emerg” 代表人和日志服务产生的日志,只要等级是emerg等级,就记录。这种用法极少 见,了解就好。“.!”代表不等于,也就是除该等级的日志外,其他等级的日志都记录。
示例
(1)除内核信息外,将所有 critical 信息写到日志文件/var/log/critical 上。
*.=crit;kern.none /var/log/critical
(2)除了 mail、news、authpriv 和 cron 外,将 info 或更高级别的信息送到/var/log/messages 上。
*.info;mail.none;news.none;authpriv.none;cron.none /var/log/messages
(xx.none就是不记录某类日志)
(多个配置项用;间隔)
(3)将 mail 系统信息记录到/var/log/maillog。
mail.* /var/log/maillog
(4)将所有 emerg 信息以 wall 的形式发送给系统内的所有登录用户。
*.=emerg *
(5)将所有日志信息送往主机
loghost *.* @loghost
(6)将 news 服务的 crit、err 和 notice 分别 log 到/var/log/news/news.*。
news.=crit /var/log/news/news.crit
news.=err /var/log/news/news.err
news.notice /var/log/news/news.notice
p223,7.4.3非文本日志文件阅读;
非文本日志文件有/etc/log/wtmp、/var/log/btmp、/var/log/lastlog 和/var/run/utmp 等,它们 记录着用户登录的相关信息,可以使用 lastlog、last、lastb、who 和 w 来阅读。
| 文件 | 数据内容 | 持久性 | 关键命令 | 安全作用 |
|---|---|---|---|---|
/var/run/utmp | 当前登录会话 | 临时 | who, w | 实时监控用户活动 |
/var/log/wtmp | 历史登录/注销记录 | 持久 | last | 审计历史登录行为 |
/var/log/btmp | 失败登录尝试 | 持久 | lastb | 检测入侵尝试 |
/var/log/lastlog | 用户最后一次登录时间 | 持久 | lastlog | 识别闲置或异常账户 |
(1)lastlog
lastlog 根据文件/var/log/lastlog 内容显示系统中所有或指定用户的最近登录时间。
lastlog [-b DAYS] [-t DAYS] [-u user]
-d 和 -t 同时存在时,-t 会覆盖 -d 的设定
lastlog #显示所有用户的最后登录时间
>>
Username Port From Latest
root tty2 Mon Mar 20 14:19:19 +0800 2017
bin **Never logged in**
gdm tty1 Mon Mar 20 14:17:34 +0800 2017
rpcuser **Never logged in**
test tty2 Sat Mar 18 10:33:51 +0800 2017
lastlog -u root#显示指定用户的最后登录时间
lastlog -t 3 -u 500-510 #显示 UID 从 500 到 510 的用户中,最近 3 天内登录过的用户的最后一次登录信息
(2)last
last 用来显示自文件/var/log**/wtmp** 产生以来的用户登录信息。
last [-R|-a] [-i] [-num] [-n num] [diox] [-f FILE] [-s TIME] [-t TIME] [name] [tty]
-R 不输出-a 输出主机名;
-num 或-n num 用于指定显示的行数;
last -a -2
>>
ct tty2 Mon Apr 21 13:12 still logged in tty2
ct seat0 Mon Apr 21 13:12 still logged in login screen
last -R -n2
>>
ct tty2 Mon Apr 21 13:12 still logged in
ct seat0 Mon Apr 21 13:12 still logged in
-x 用于 指定只显示系统关闭和运行级切换的内容;
-f 用于指定文件 FILE 而取代默认文件;
last -f /var/run/utmp
>>
ct tty2 tty2 Mon Apr 21 13:12 still logged in
ct seat0 login screen Mon Apr 21 13:12 still logged in
reboot system boot 6.12.4 Mon Apr 21 13:10 still running
-s 和-t 用于指定时间开始和结束时间(时间格式为:YYYYMMDDhhmmss、YYYY-MM-DD hh:mm:ss、YYYY-MM-DD hh:mm、YYYY-MM-DD、hh:mm:ss 和 hh:mm 等);
last -s"2025-04-01 12:00"
>>
ct tty2 tty2 Mon Apr 21 13:12 still logged in
ct seat0 login screen Mon Apr 21 13:12 still logged in
reboot system boot 6.12.4 Mon Apr 21 13:10 still running
ct tty2 tty2 Wed Apr 2 15:02 - crash (18+22:08)
ct seat0 login screen Wed Apr 2 15:02 - crash (18+22:08)
name 用于指 定用户;tty 用于指定终端设备,且可缩写,如 tty1 可写为 1。若时间、用户名或终端名指定, 则只显示与之匹配的内容。
[tty]:筛选指定终端的记录(如 last tty1 或 last pts/0)。
last
>>
ct tty2 tty2 Mon Apr 21 13:12 still logged in
ct seat0 login screen Mon Apr 21 13:12 still logged in
reboot system boot 6.12.4 Mon Apr 21 13:10 still running
ct tty2 tty2 Wed Apr 2 15:02 - crash (18+22:08)
ct seat0 login screen Wed Apr 2 15:02 - crash (18+22:08)
reboot system boot 6.12.4 Wed Apr 2 15:01 still running
(3)lastb
其用法与 last 相同,所不同的是 lastb 使用的文件是/var/log**/btmp**。
3)内核启动日志
demsg
dmesg|grep disk
>>
[ 47.836448] sd 12:0:0:0: [sda] Attached SCSI disk
[ 47.844739] sd 12:0:1:0: [sdb] Attached SCSI disk
第八章
一选择,一填空,4分
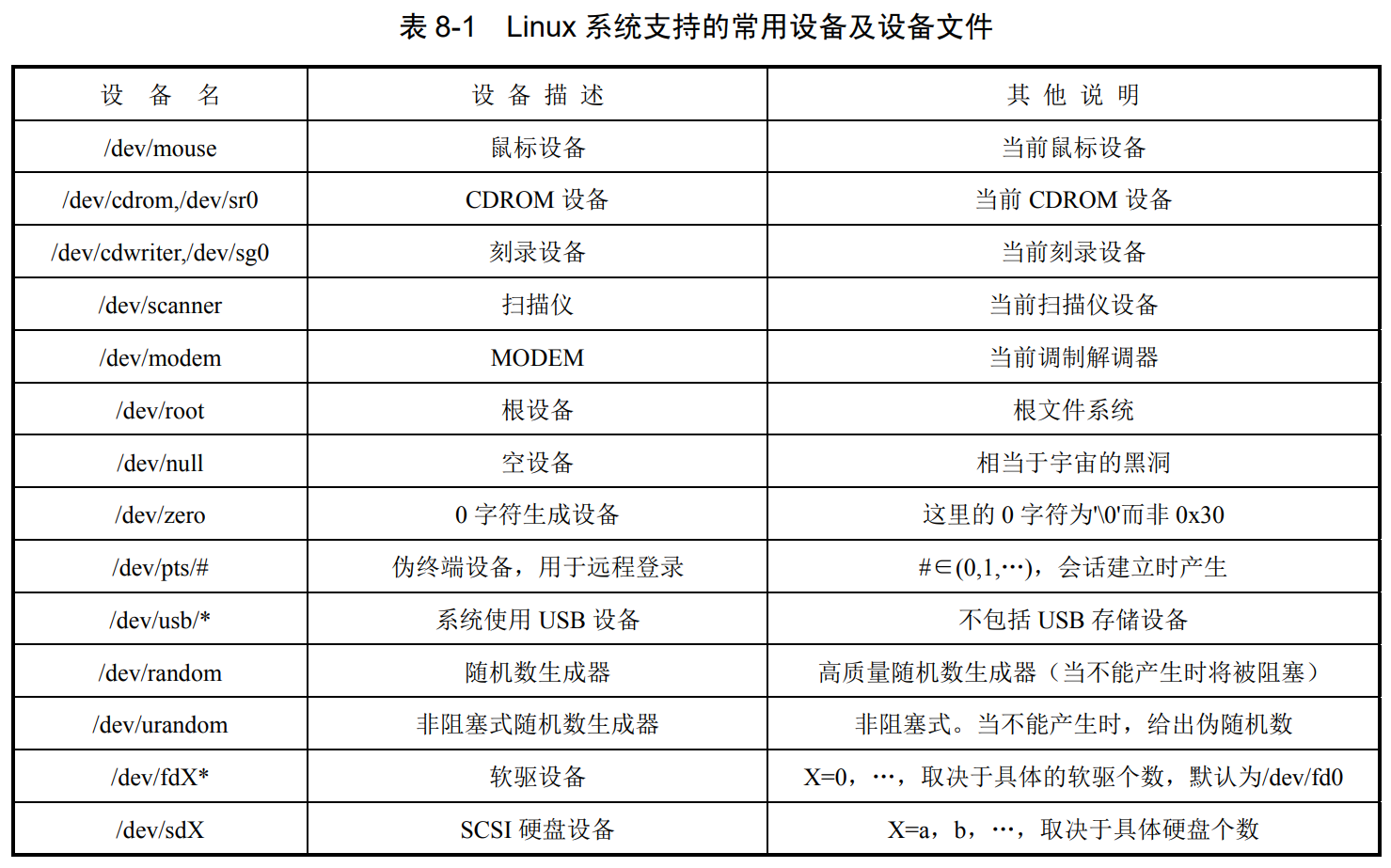
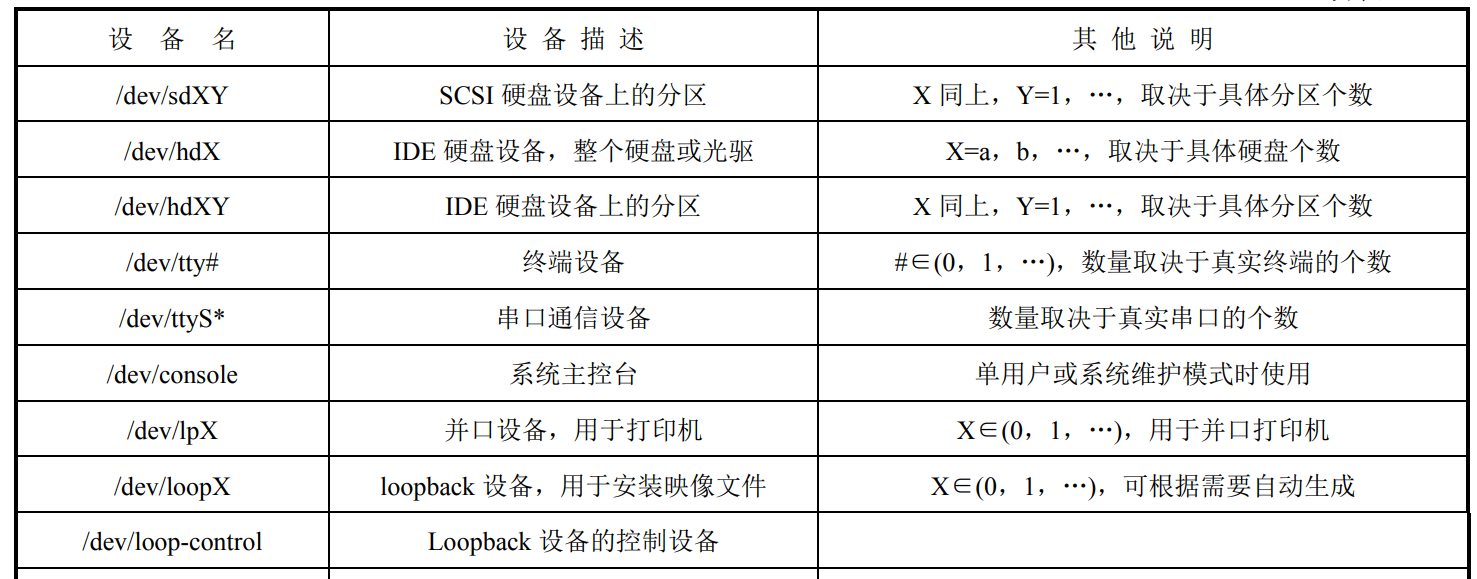
p237,8.1.1设备名称
设备文件统一存放在**/dev** 目录
p239,8.1.2设备管理命令lsblk以和blkid;
块设备查询(lsblk)
lsblk [options] [device...]
-a/–all 输出所有设备;
-d/–nodeps 只显示主设备
-f/–fs 显示文件系统类型;
-l/–list 以表方式显示(默认以树状方式显示)
-O/–output-all 输出所有列;
-o,/–output +list 输出指定列;
-S/–scsi 只输出 SCSI 设备。
lsblk #显示所有块设备
lsblk -S #只显示 SCSI 设备
lsblk /dev/sda #只输出 sda 信息
lsblk -l -o"NAME,LABEL,UUID" #输出设备的 NAME、LABEL 和 UUID 信息
显示块设备属性(blkid)
blkid [-L label | -U uuid] [device]
项-L label 用于显示 LABEL 为 label 的块设备属性信息;-U uuid 用于显示 UUID 为 uuid 的块设备属性信息
blkid #显示所有块设备信息
blkid /dev/sda #显示 sda 设备信息
第九章
一填空,2分
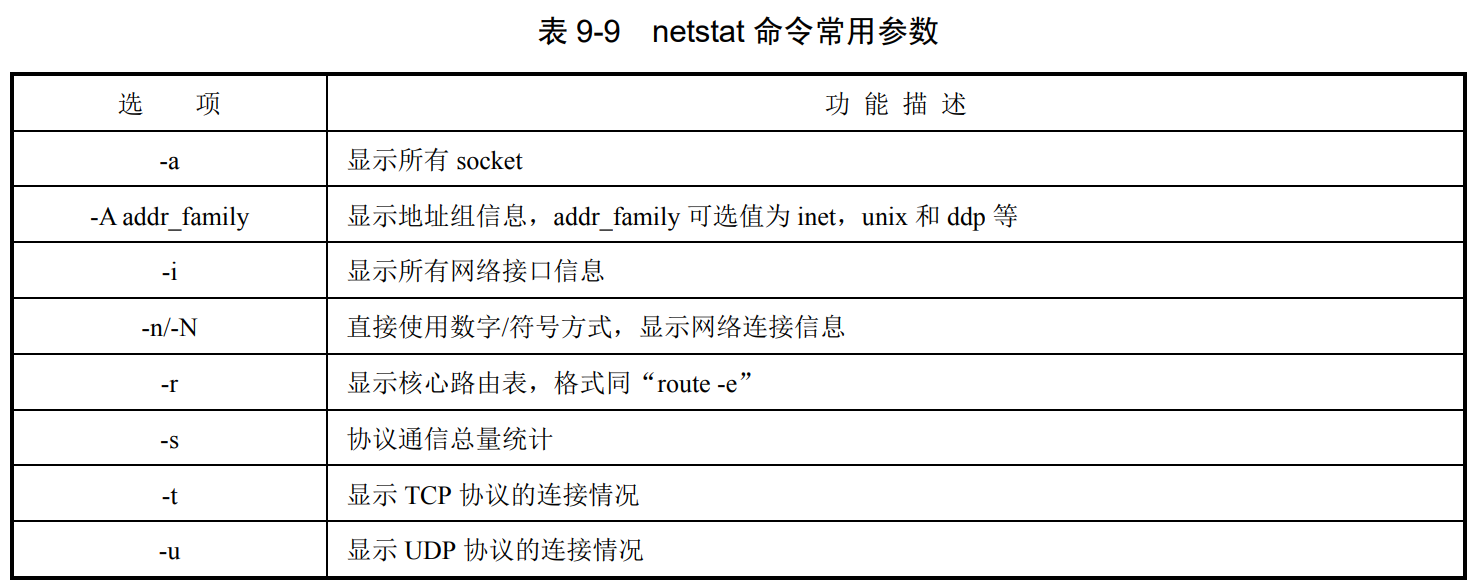
p264,9.3.1 网络管理命令
检查网络状态(netstat)
netstat -ta #显示所有 TCP 端口
#>>
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:32768 *:* LISTEN
… … …
tcp 0 0 127.0.0.1:smtp *:* LISTEN
tcp 0 0 202.196.233.54:34992 222.88.90.209:http ESTABLISHED
netstat -i
#>>
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 35014 0 0 0 8810 0 0 0 BMRU
lo 16436 0 82802 0 0 0 82802 0 0 0 LRU
netstat -nr
#>>
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
202.196.233.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo
第十章
一简答,5分
p278,Linux系统安全防范策略
1)物理环境保障
物理环境包括防水、火、盗、电磁辐射,物理网络隔离,用电环境,楼房建筑与机房位 置等诸多方面。
2)制度保障
建立各种规章制度,并强制执行,定期进行安全检查。
- (1)网络隔离制度。一般单位都要求内、外网隔离,业务网与办公网隔离。特殊情况需 ·275· 要相互渗透时要通过防火墙和中间件。
- (2)工作环境管理制度。要有防水、防火、防盗、防电磁辐射,防自然灾害等制度和应 急响应机制,要有安全可靠的电力保障。
- (3)人员管理制度。要建立外部人员来访管理制度,出入登记制度,系统使用登记制度, 岗位分工与管理制度,定期培训与换岗制度。
3)用户密码的安全性
密码是保障系统安全的关键。密码是防止别有用心的人本地和异地登录系统的第一道屏 障,为此,一定要保护好密码文件/etc/passwd 和/etc/shadow 的安全,不让无关的人员获得这 两个文件。同时,系统管理员还应该告诉用户在设置密码时要使用安全密码(使用非数字或 字母的特殊字符)并适当增加密码的长度(大于 6 个字符)。系统管理员还可以定期使用 Crack、 John 等破解程序对系统的/etc/passwd 文件和/etc/shadow 文件进行模拟字典攻击,若发现不安 全用户密码,要求用户必须修改。 关于密码的管理,还应有一套完整的制度,不论是系统密码还是用户密码都要定期或不 定期修改。
4)设置用户的权限
在创建新用户时,要仔细设置每个内部用户的权限和用户所在的组,授权时一般应遵循 “最小权限”原则,即仅给每个用户授予完成特定任务所必需的访问权限。
5)检查文件系统的安全性
文件系统的安全性是指限制文件和目录权限,慎重地使用 SUID 和 SGID 权限,检查并 删除多余和可疑的文件,并设置系统的默认权限方案。
6)加强对系统运行的监控和记录
系统管理员应该对整个系统的运行状况进行监控和记录。这样,通过分析记录的数据, 可以发现可疑的活动,从而及时采取措施阻止可能发生的入侵行为。若系统已经被入侵,利 用记录的运行状况数据,可以跟踪和识别入侵的非法用户及途径。 系统中的各种启动日志、管理日志、应用程序日志等也要记录完备。
7)软件更新与系统升级
定期检查系统更新和软件更新,但不能随便更新,也不要设置为自动更新。对于大型业务系统的软件更新,要统一安排、统一实施,以保证系统和软件版本的统一。不该更新的不能更新,系统和软件的更新也可能存在安全隐患。系统或软件升级也是要经过审批的。
8)数据备份
因为有人、自然和制度等多方面的因素,至今没有一种操作系统的运行是绝对安全可靠 的,也没有一种安全策略是万无一失的,所以要制订合适的数据备份计划和制度,并按制度 认真执行之,确保备份数据的有效性和可用性,一旦系统遭到破坏或攻击而发生瘫痪时,能 利用备份的数据迅速恢复工作。
9)提高系统的运行级别
很多操作系统可以运行在不同安全级别,提高系统的安全级别,可以增强系统的安全性。 不过安全与方便有时是矛盾的,必须在两者之间权衡,但安全是第一位的。
9)开启防火墙
在网络中,“防火墙”是指一种将内网和公网(如 Internet)分开的方法,实际上是一种隔 离技术。能通过防火墙规则设置最大限度地阻止网络中的非法或未经授权的访问,提高网络和 系统的安全性。强烈建议,在网络上运行的系统要开启防火墙,并合理设置防火墙的规则。
10)配置 SELinux
使用 SELinux(Security Enhanced Linux)进行文件系统的权限设置,从而有效地管理用 户存取数据时的行为。
第十一章
两填空,一综合,24分
正则表达式
正则表达式见第三章
grep
[见第三章"字符串过滤"](# 字符串过滤(grep))
流处理sed
1.介绍与用法
sed 是个流编辑器,其功能是对它的输入流进行按指定格式的转换。
sed 使用脚本语言对输入流进行加工,脚本可以在命令行或文件中输入。在工作时它只对输入流处理一遍。
sed 的输出对象为标准输出,若输出到文件可使用输出重定向。
sed [options] { scripts } [input-file]
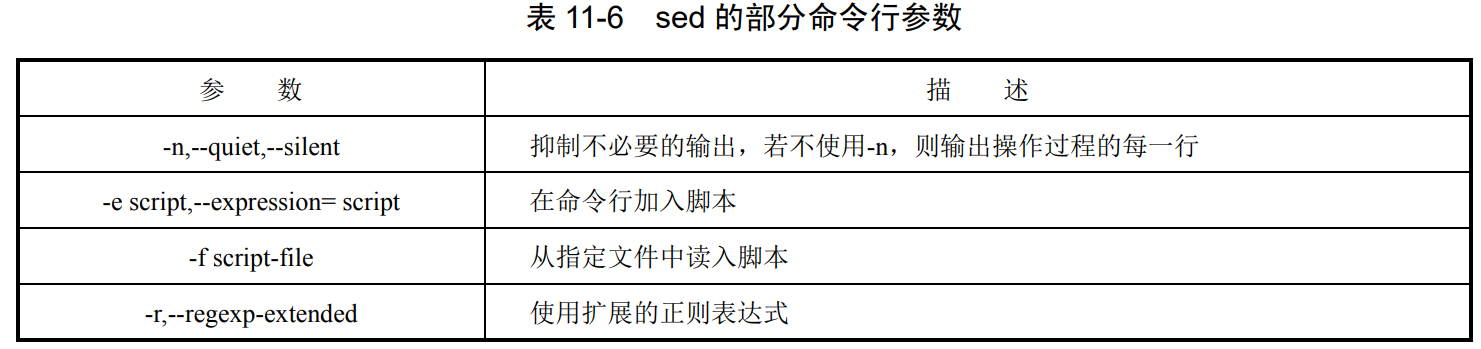
-i 写回,覆盖原始内容
若使用 -e 或 -f,则所有非选项参数均为输入文件。
若未通过 -e 或 -f 显式指定脚本,则第一个非选项参数(即不以 - 开头的参数)会被视为 sed 的编辑脚本。后续的非选项参数均被视为输入文件。
sed 's/foo/bar/' file1.txt file2.txt
#'s/foo/bar/' 是第一个非选项参数,被视为脚本。
#file1.txt 和 file2.txt 是输入文件。
#操作:对 file1.txt 和 file2.txt 执行替换操作,结果输出到终端。
若未提供输入文件,则默认从标准输入(如键盘或管道)读取数据。
echo "hello foo" | sed 's/foo/bar/'
#脚本为 's/foo/bar/',无输入文件参数,因此从标准输入(管道)读取数据。
#输出:hello bar。
脚本命令
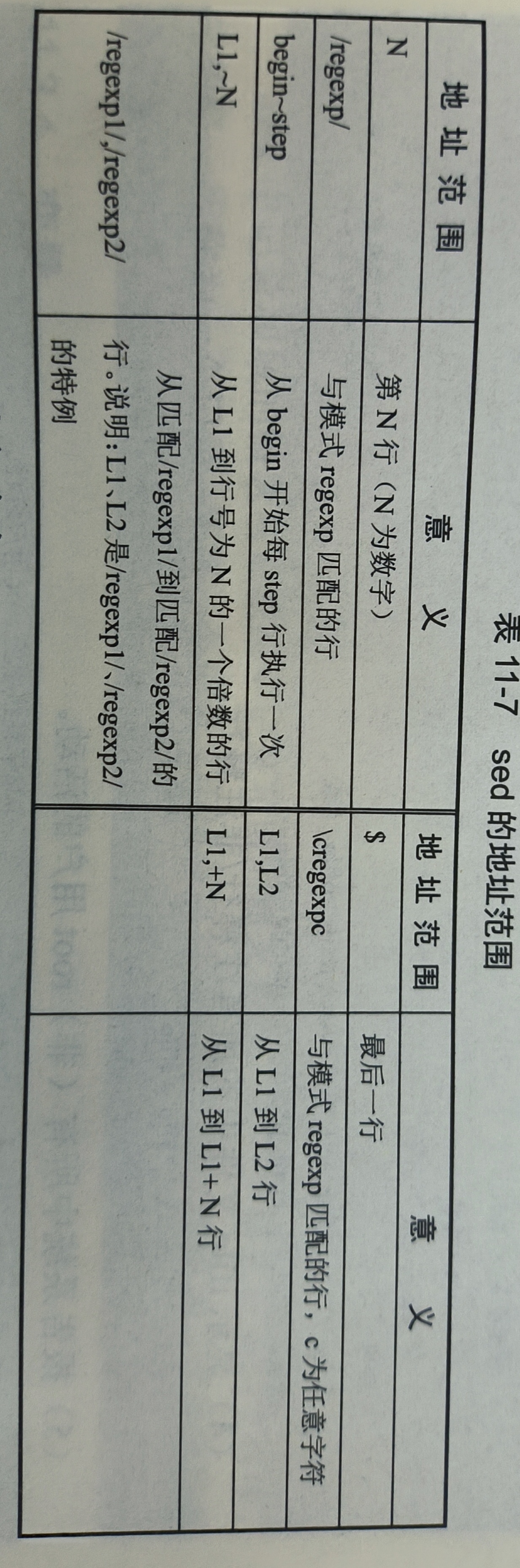
1.sed 的地址形式
在编写脚本程序时,要用到地址范围的概念。
2.sed脚本命令
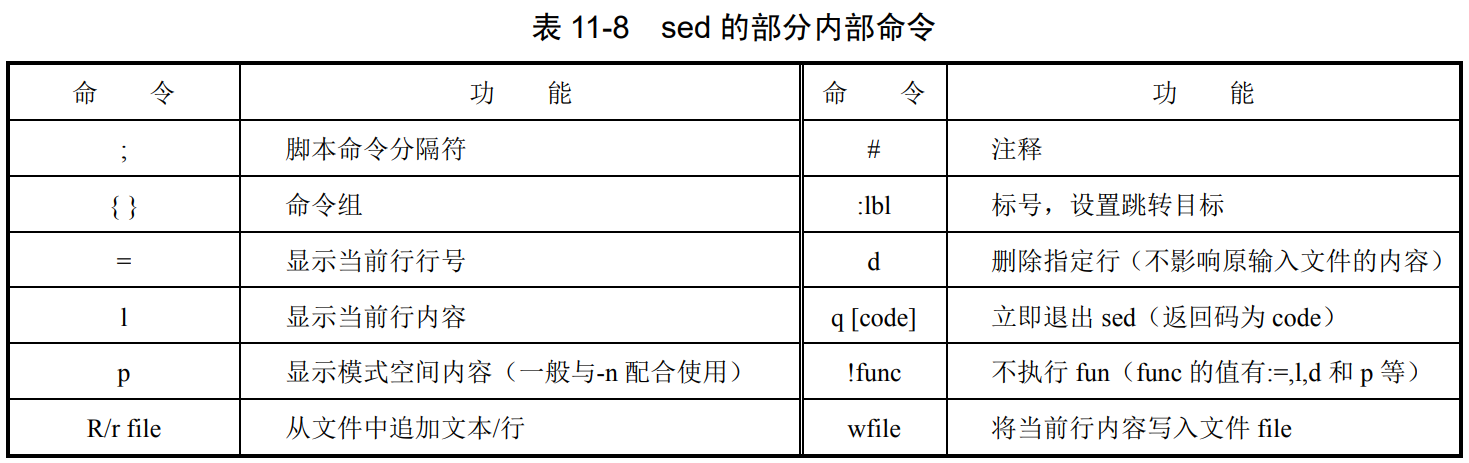
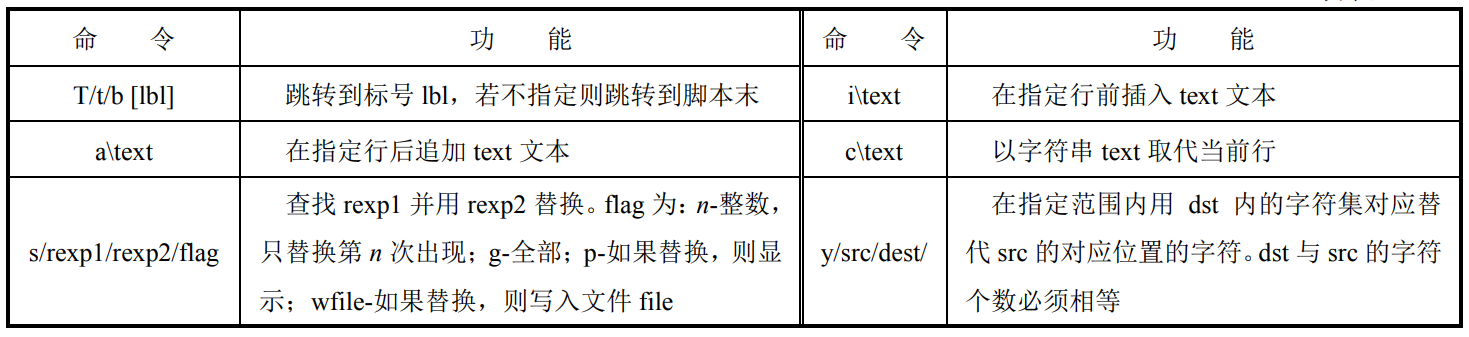
要注意:
1.没有用 -n 选项,且没有显式删除(d)或修改输出,sed默认会打印所有处理(扫描)过的行
2.!fun不是不执行操作,而是对不匹配的进行操作。
3.p与l的区别:
| 命令 | 作用 | 输出内容 | 适用场景 |
|---|---|---|---|
sed -n '/that/p' t.txt | 打印匹配行 | 原始文本 | 常规提取内容 |
sed -n '/that/l' t.txt | 可视化格式化匹配行 | 显示行末 $ 和转义字符 | 调试(检查隐藏字符) |
sed -n '/add/l' t.txt
>>
add some zhuanYi --$
sed -n '/that/!p' t.txt
sed -n '/add some/p' t.txt
add some zhuanYi --
示例
#删除注释
sed '/^#/d' t.txt
| 字符/部分 | 含义 |
|---|---|
sed | 调用 sed 命令 |
' | 单引号,包裹 sed 的指令 |
/^#/ | 正则表达式匹配: - / 表示正则的开始和结束 - ^ 匹配行首 - # 匹配 # 字符 |
d | sed 的删除(delete)命令 |
t.txt | 输入文件 |
#基本删除空行
sed '/^$/d' t.txt
| 字符/部分 | 含义 |
|---|---|
/^$/ | 匹配空行: - ^ 表示行首,$ 表示行尾 - ^$ 组合表示“行首和行尾之间无内容”的空行 |
d | 删除(delete)匹配的行 |
# 取消 PATH 行的注释
sed 's/^#PATH=/PATH=/' t.txt
| 字符/部分 | 含义 |
|---|---|
s | sed 的替换(substitute)命令 |
/^#PATH=/ | 匹配模式: - ^ 行首 - #PATH= 匹配 #PATH= |
/PATH=/ | 替换为 PATH= |
#在 SHELL= 行后插入一行
sed '/^SHELL=/aNEW_VAR="sed-append"' t.txt
#同时处理多个操作,-e指定脚本
sed -e '/^#/d' -e 's/^#PATH=/PATH=/' t.txt
书上例子:
#将 ifile 文件中的所有 sysman 替换成 System Manager 并输出到 ofile
sed -e 's/sysman/System Manager/g' <ifile >ofile
#计算件文件 ifile 的行数
sed -n '$=' <ifile
#不加-n的话sed 的默认行为是先输出每一行的原始内容,再最后加上行数
sed '$=' <ifile
#删除文件 ifile 中的空行,并将其他的内容输出到 ofile。
sed '
/^$/d
/^[:space:]*$/d #换行分隔脚本命令
' <ifile >ofile
#也可用;分隔命令写为:
sed '/^$/d; /^[:space:]*$/d' <ifile >ofile #或
sed '/^$/d; /^[:blank:]*$/d' <ifile >ofile
#显示 ifile 文件中的所有注释行/非注释行。
sed -e '/^#/!d' < ifile #显示注释行。参见不执行某命令!是对非匹配行
sed -e '/^#/d' < ifile #显示非注释行
#报告系统中所有(非)root 用户的活动。
#sed: 字符类型语法是 [[:space:]],不是 [:space:]
ps -ef | sed -e '/^[[:space:]]*root/!d' #显示系统中 root 用户进程
ps -ef | sed -e '/^[[:space:]]*root/d' #显示系统中的非 root 用户进程
#去除一个文本文件的所有行首和行末的白空格。
y/t/_/
s/^_*//
s/_*$//
模式搜索与处理awk
格式
awk 是一个用于模式搜索和处理的编程语言,对于格式化结构的文件特别有效。
awk [options] -f progfile [--] file
awk [options] [--]'program' file
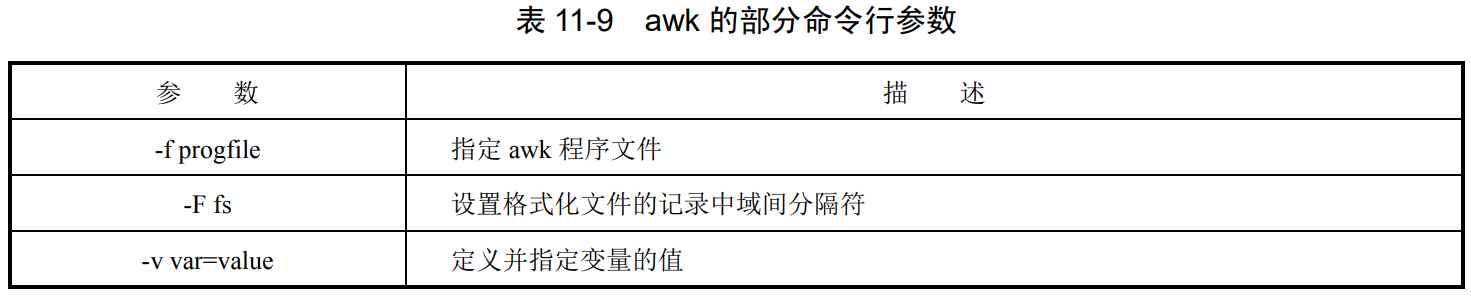
| – | 结束选项,其后为参数 |
|---|
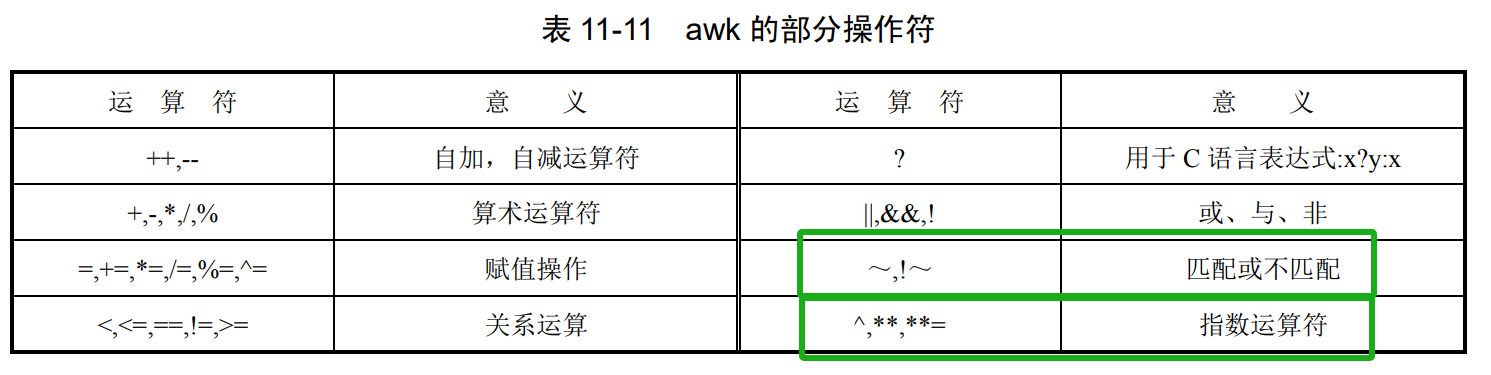
记录和域
在一个格式记录的文件里,它的 每一行称为一个记录,而每一个记录又由域分隔符,分隔的不同字段组成,这种字段就是记录中的域。在 awk 中整个记录用$0 表示,而组成记录的每个域依次表示为$1,$2……
变量
awk 中变量是动态定义,只有当它第一次被使用时变量才存在。由于是解释语言,变量可以是任何类型的,这取决于用户如何使用它。在 awk 中还可以使用数组。
-
内部变量
见下
-
自定义变量
由字母、数字和下画线组成,但是不能以数字开头。
如果变量 未被初始化,awk 会将字符串变量初始化为空串,将数值变量初始化为 0。必要时,awk 会 将字符型变量转换为数值型变量,或者反向转换。
在 awk 中引用自定义变量时不需在其名前面加上标志符“$”。 对变量的赋值语法支持 C 语言格式。
3.域变量
控制语句
(1)if 语句:if(condition)statement [ else statement ]
(2)while 语句:while(condition)statement
(3)do 语句:do statement while(condition)
(4)for 语句:
-
for(expr1;expr2;expr3)statement
-
for(var in arry)statement
(5)控制转移和退出语句:break,continue,exit
(6)语句组:{ statements }
语句块:
(1)BEGIN 块。
一般形式为 BEGIN 后面跟了一个操作块。awk 必须在对输入文件进行任何处理之前先执 行 BEGIN 块。不需要任何输入文件,也能对 BEGIN 块进行测试,因为 awk 要在执行完 BEGIN 操作块后才开始读取输入。BEGIN 操作常常被用来修改内置变量(比如 OFS、 RS、FS 等)的值,或为用户自定义变量赋初值。
(2)END 块。
一般形式为 END 后面跟一个操作块。awk 在处理完所有输入行之后才处理 END 块。
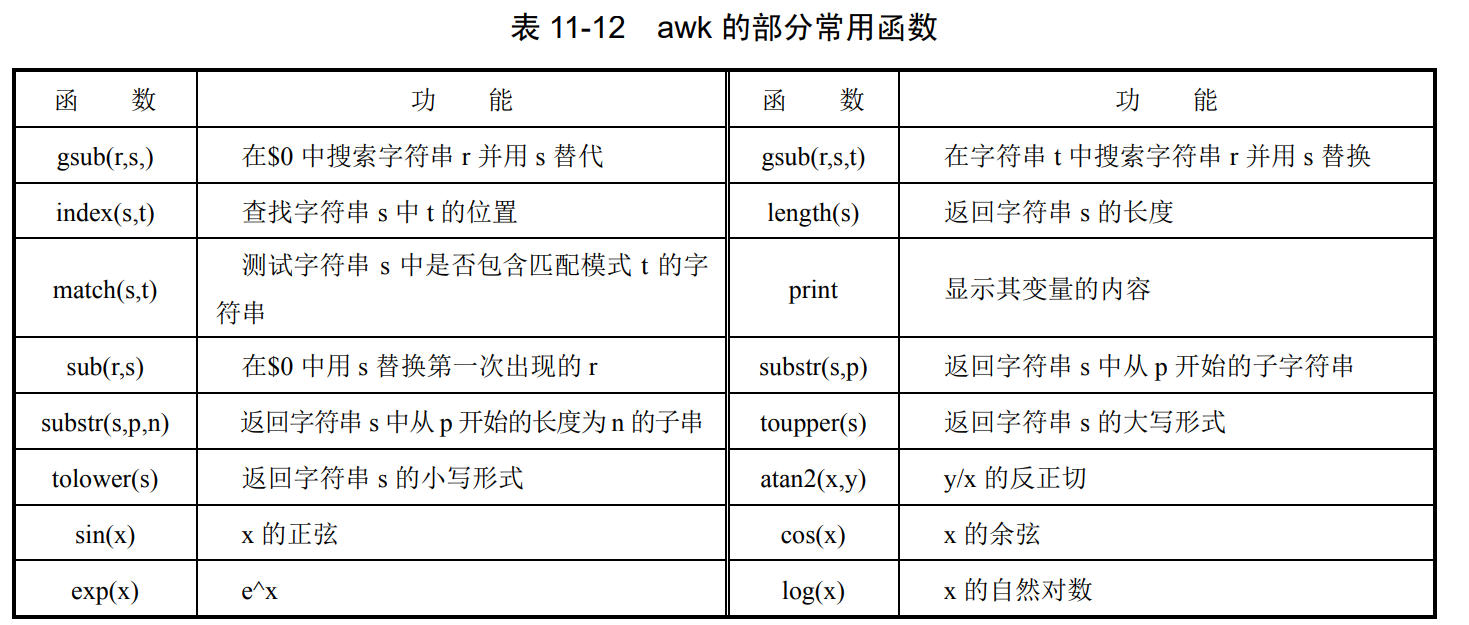
常用函数

程序执行
awk 由模式操作和函数语句序列组成,格式为:
#模式(正则表达式)
pattern { action statement } #省略模式则处理所有行
#行为对
function func_name ( param_list ) { statements }
awk 把输入文件的数据读入内存,然后操作内存中的输入数据副本,不修改输入文件的内容。
awk 总是输出到标准输出,可以使用输出重定向。
awk 对脚本程序处理的过程如下:
(1)如果 BEGIN 块存在,先执行 BEGIN 块指定的操作。
(2)awk 从输入文件中读取一行,称为一条输入记录(若文件省略,将从标准输入读)。
(3)awk 将读入的记录分隔成域,将第 1 个域放入变量$1 中,第 2 个域放入$2,依次类 推。$0 表示整条记录。域分隔符由 awk 内置变量 FS 的值来指定。
(4)把当前输入记录依次与每一个 awk 命令中的 pattern 比较,看是否匹配,如果相匹配, 就执行对应的操作。否则就跳过对应的操作,直到比较完所有的 awk 命令。
(5)当一条输入记录比较了所有的 awk 命令后,awk 读取输入的下一行,继续重复步骤 (3)和(4),这个过程一直持续,直到 awk 读取到文件尾。
(6)当 awk 读完所有的输入行后,如果存在 END,就执行 END 块。
示例
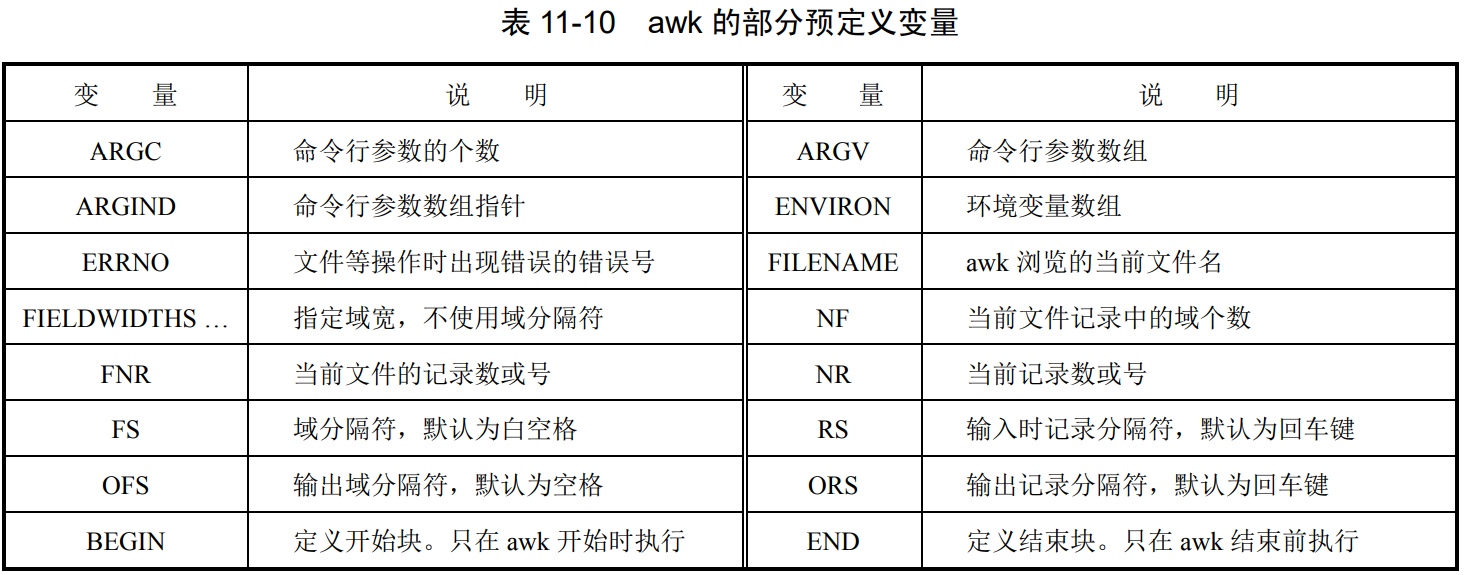
内部变量:
#1显示系统内 root 用户进程的进程号和进程名
ps -ef | awk '/root/{ print $1, $2, $8 }'
#2显示系统内非 root 用户进程的进程号和进程名
ps -ef | awk '!/root/{ print $1, $2, $8 }'
#3计算文件 infile 内数字的和。假设 t.txt 内容为数字串,每行可有任意多个数字串
awk '{ for (i=1; i<=NF; i++) s +=$i } END { print s }' ifile
#4显示系统内已经注册(创建)的所有用户名(/etc/passwd 内的所有用户)
awk -F: '{ print $1 }' /etc/passwd
#还可以指定别的域分隔符
awk -F'[:/]' '{ print $1 }' /etc/passwd #'[:/]'是一个正则表达式
#5在每一行前面添加行号
awk '{print NR, $0}' ifile
#6对文本文件行中具有某特殊字符串的行执行 shell 命令。
awk '/date/{system("date +%D%t%T")}' t.txt
#(7)实现 wc 的功能:统计文本文件中的行数、字数和字符数
#!/usr/bin/awk -f
BEGIN { w=0; l=0; c=0 }
{
w += NF; l++; c += length($0) + 1
}
END { print"l=" l,"w=" w,"c=" c }
awk -f wc.awk t.txt
>>
l=15 w=84 c=542
#加权限chmod +x wc.awk
#直接运行
./wc.awk t.txt
Bourne shell 及其编程
Linux 系统的默认 shell 是 bashell。 bashell 兼容 bshell。
特殊字符
(1)*,?,[ - ],[ !- ]:通配符。
(2)<,<<,>,>>,|:I/O 重定向符。
(3);:命令分隔符。
(4)&:命令后台执行。
(5)",',`:三种引号。
(6):转义字符。
(7)$:变量引用前导符。
(8){,},[,],(,):括号。
(9)~:波浪号扩展(为用户的家目录),与$HOME 相同。
(10)&&,||:命令的与或结构及条件执行。
变量与参数
参数排列的位置被编号为 0,1,…,其中 0#参数为命令本身的名字,1#,2#,…等分别为它所携带 的第一个参数,第二个参数
myprog first xyz 123
0#参数为程序名 myprog,1#参数为 first,2#参数为 xyz,3#参数为 123。
但能直接访问的只有$0~ 910 个。对第 10 个以后位置参数,需要使用 9 10 个。对第 10 个以后位置参数,需要 使用 910个。对第10个以后位置参数,需要使用{}的办法来处理,比如第 11 个位置参数为${11}。当命令行参数超过 10 个时,访问不 便,可使用 shift 进行调整,将后边的前移。
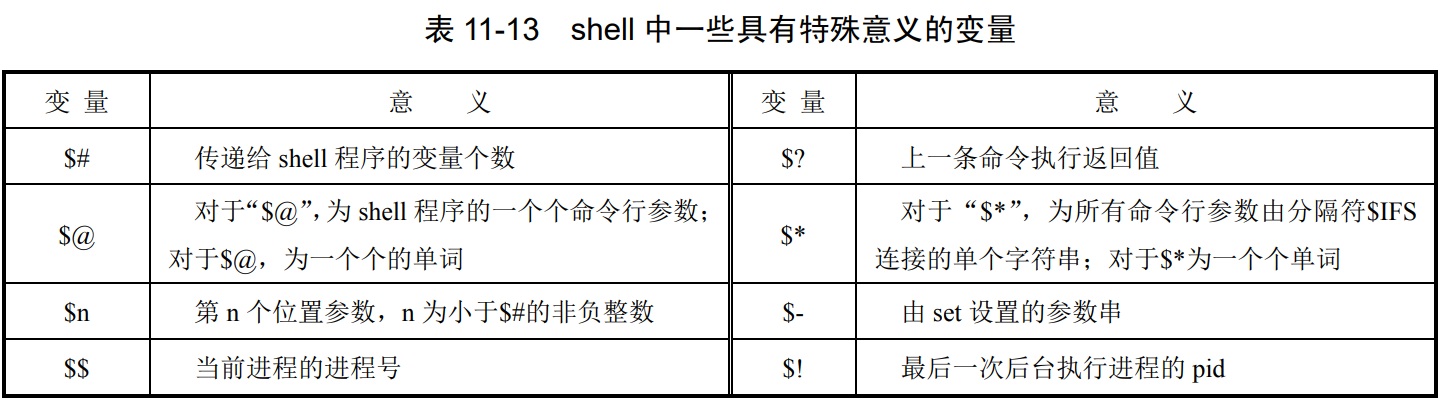
$*将所有命令行参数拼接成一个单一字符串,参数之间用 $IFS分隔。
#!/bin/bash
for arg in $*; do
echo "[$arg]"
done
#运行 ./script.sh "arg 1" "arg 2" 输出:
[arg]
[1]
[arg]
[2]
$@将每个命令行参数视为独立的、引号包裹的字符串,保留参数的原始边界
#!/bin/bash
for arg in "$@"; do
echo "[$arg]"
done
#运行 ./script.sh "arg 1" "arg 2" 输出:
[arg 1]
[arg 2]
条件替换:
-
${var:-val}如果var未定义或为空,则返回val,但 不修改 var 的值 -
${var:=val}如果var未定义或为空,则返回val并将val赋值给var -
${var:+val}仅当var已设置且非空时,返回val;否则返回空。#!/bin/bash # var5 未设置 echo "var5 is ${var5:+replaced}" # 输出: var5 is # var6 已设置 var6="exists" echo "var6 is ${var6:+replaced}" # 输出: var6 is replaced -
${var:?message}若var未设置或为空,则打印message并 终止脚本执行#!/bin/bash # var7 未设置 echo "var7 is ${var7:?Error: var7 is unset or empty}" # 报错并退出 echo "This line will not run." # 若 var8 已设置,则正常执行 var8="ok" echo "var8 is ${var8:?Error}" # 输出: var8 is ok
shell程序设计
1.bashell 的常用命令
(1)::空命令。什么都不做,只有返回一个值 0。
(2). shell_prog:在当前 shell 中执行程序。
(3);:命令分隔符。同一行中可写多个命令,但命令与命令之间要用“;”分隔。
(4)cd [-L | -P] [arg]:改变工作目录。
(5)pwd [-L | -P]:显示当前工作目录。
(6)echo [args]:显示字符串或变量的值。
(7)exit [n]:强迫 shell 退出[退出码为 n]。
(8)return [n]:函数内强制返回[返回码为 n]。
(9)read [arg1 … ]:从标准输入读入变量值(参见 3.2.8 节)。
(10)readonly [arg1 … ]:将变量 arg1 等标识为只读,只读变量的值不能再被修改。
(11)export:向子 shell 传递自定义环境变量。
(12)break [n]:从 for、while 或 until 循环内跳出,n 代表跳出的层数。
(13)continue [n]:从 for、while 或 until 循环的开始处执行,n 代表循环的层数。
(14)trap [-lp] [func] signals:设置信号或软中断的处理办法。
(15)times cmd [args]:显示 shell 和 shell cmd 在系统和用户态执行的累计时间。 time cmd [args]:显示 cmd 在系统、用户态的执行时间和累计时间。
(16)umask [ -S ] [ mask ]:设置文件创建掩码。
(17)wait [ n ]:等待某个进程的结束,并报告它的结束状态。若不指定 n,则所有子进 程都将被等待。如果 n 为某个不存在的进程,则 wait 返回 127,其他情况下,wait 的返回值 与被等待进程的返回值相同。
(18)expr:用于对表达式进行运算。并将结果显示到标准输出上.当 expr 操作的表达式既不 为空也不为 0 时,返回 0;为空或 0 时返回 1;无效语句返回 2,其他错误返回 3。
expr 要求每个参数之间必须用空格分隔,且一些操作符需要使用“”进行转义。
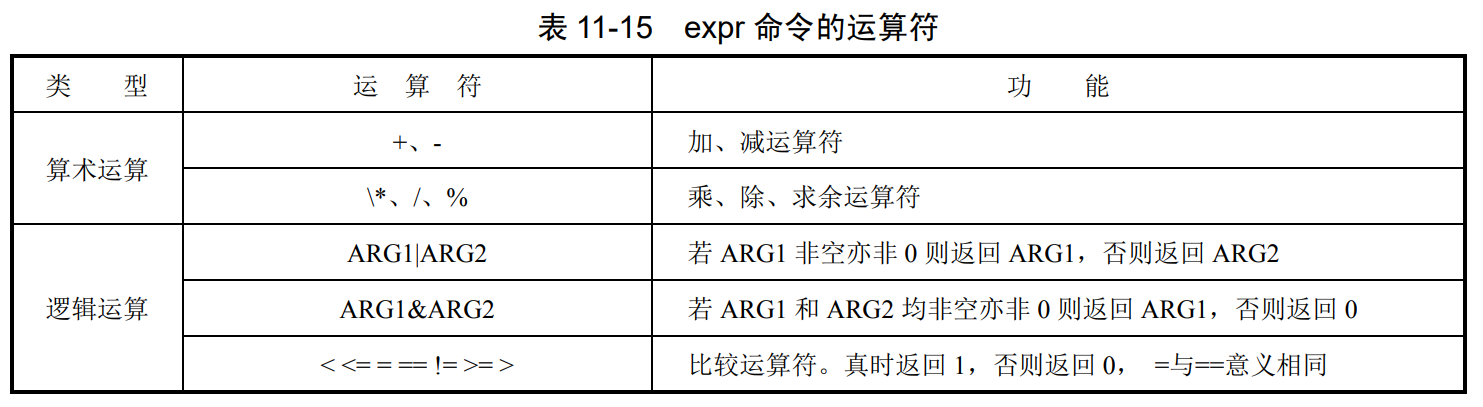
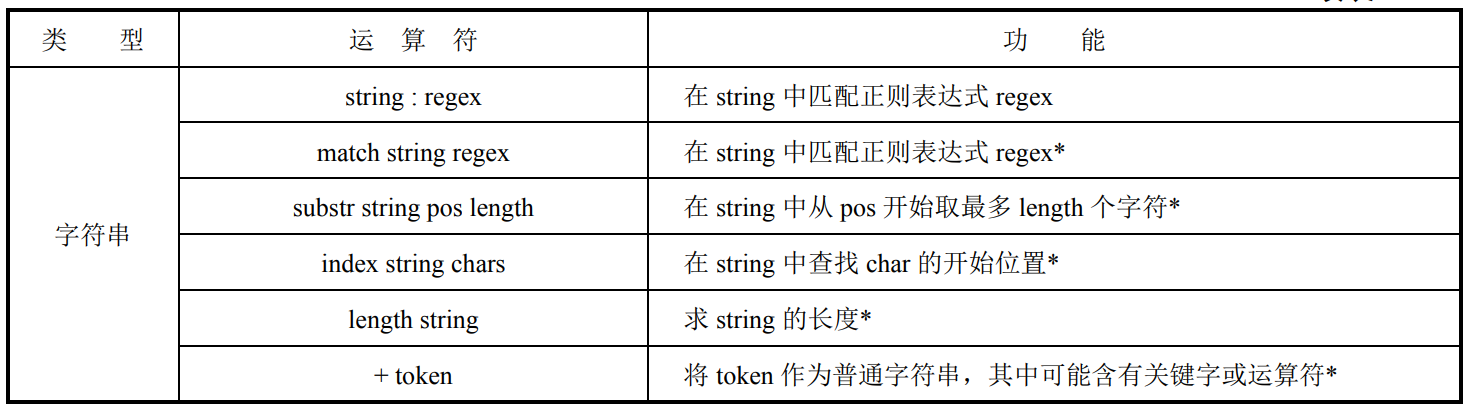
expr示例
#1计算表达式"50 * ( 40 - 25 )"的值。
expr 50 * ( 40 - 25 ) #输出 750
#2 更新某个变量的值
num=1; num=`expr $num + 5` #num 的值 6
#3模式匹配:
#()中是捕获范围,. 表示任意单字符
expr abc : 'a(.)c' #输出 b
expr abc : '(a.c)' #输出 abc
expr index "Who is Mr Shao" Mr #查找最早出现那个字符的位置,索引1开始。 M最早8,r最早9,最终输出 8
expr index "Who is Mr Shao" Shao #S:未出现(注意大小写敏感)。h:第一次出现在第 2 个字符(Who is Mr Shao)。a:第一次出现在第 12 个字符。o:第一次出现在第 3 个字符。最终输出 2
(20)exec:在当前 shell 中执行命令,当前 shell 将被新的执行程序替换或覆盖。exec 的 用法为:
exec [-lc] [-a name ] cmd args
若没有指定选项则 exec 在当前 shell 内执行命令 cmd args;若设定-l 则 shell 在向 cmd 传 递第 0 号参数时,在它的前面加上一个“−”号。若指定-a name,则 shell 在向 cmd 传递环境 变量时将把 name 作为 cmd 命令的第 0 号参数。若指定-c,则 shell 只是向 cmd 传递一个空环 境。例如:
#设有一个可能执行程序 dispargs 专用来显示自己的全部命令行参数
exec -l dispargs a1 b2 c3 #输出为:-dispargs a1 b2 c3
exec -a xyx dispargs a1 b2 c3 #输出为:xyz a1 b2 c3
(21)shift:调整位置参数,其用法为:
shift [n]
shift [n]的功能为将第 n+1,n+2,…变量的值变为$1,$2,…前 n 个参数($1 到 $n)被丢弃,不可再访问。n 必须为大于 0 的整数,默认值 为 1。若 n 的值等于 0 或大于KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲,命令执行失败,返回非零值。若…#= $#− n。
(22)test:用于测试条件表达式的值。test 命令主要用于测试某条件的返回值,成功或 真时为 0,不成功或假时为非 0,其用法为:
test condition
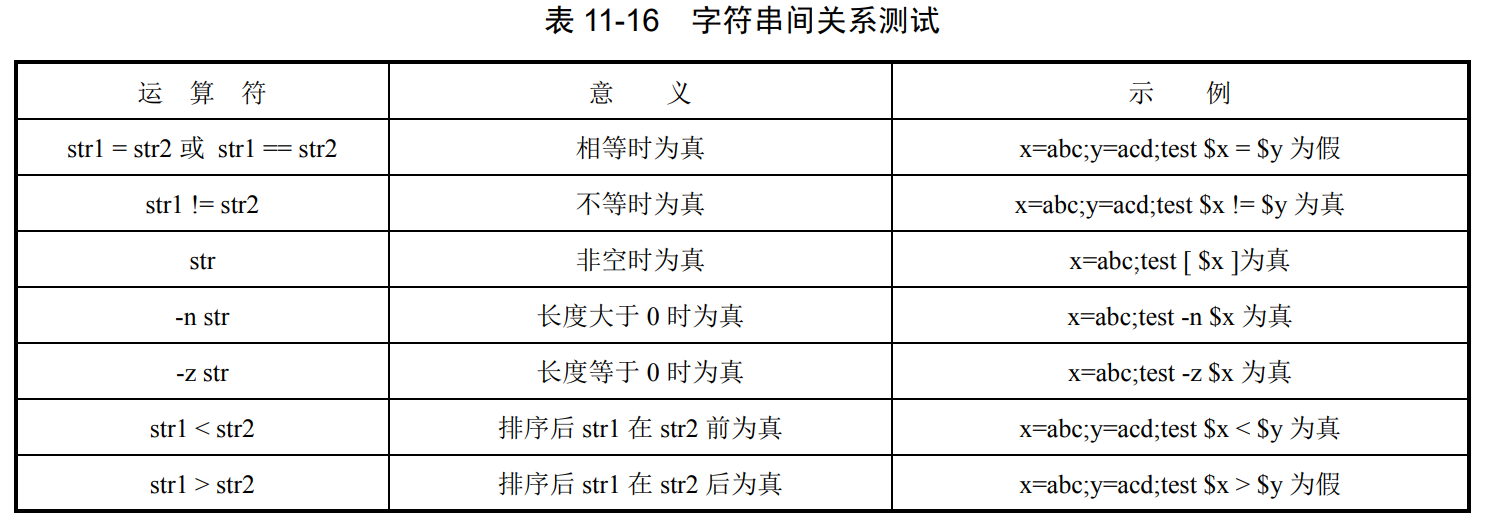
#str1=123;str2="123"
#test $str1 = $str2; echo $? #$?为上一条语句的返回值,输出结果为 0
#test $str1 -eq $str2; echo $? #结果为 0
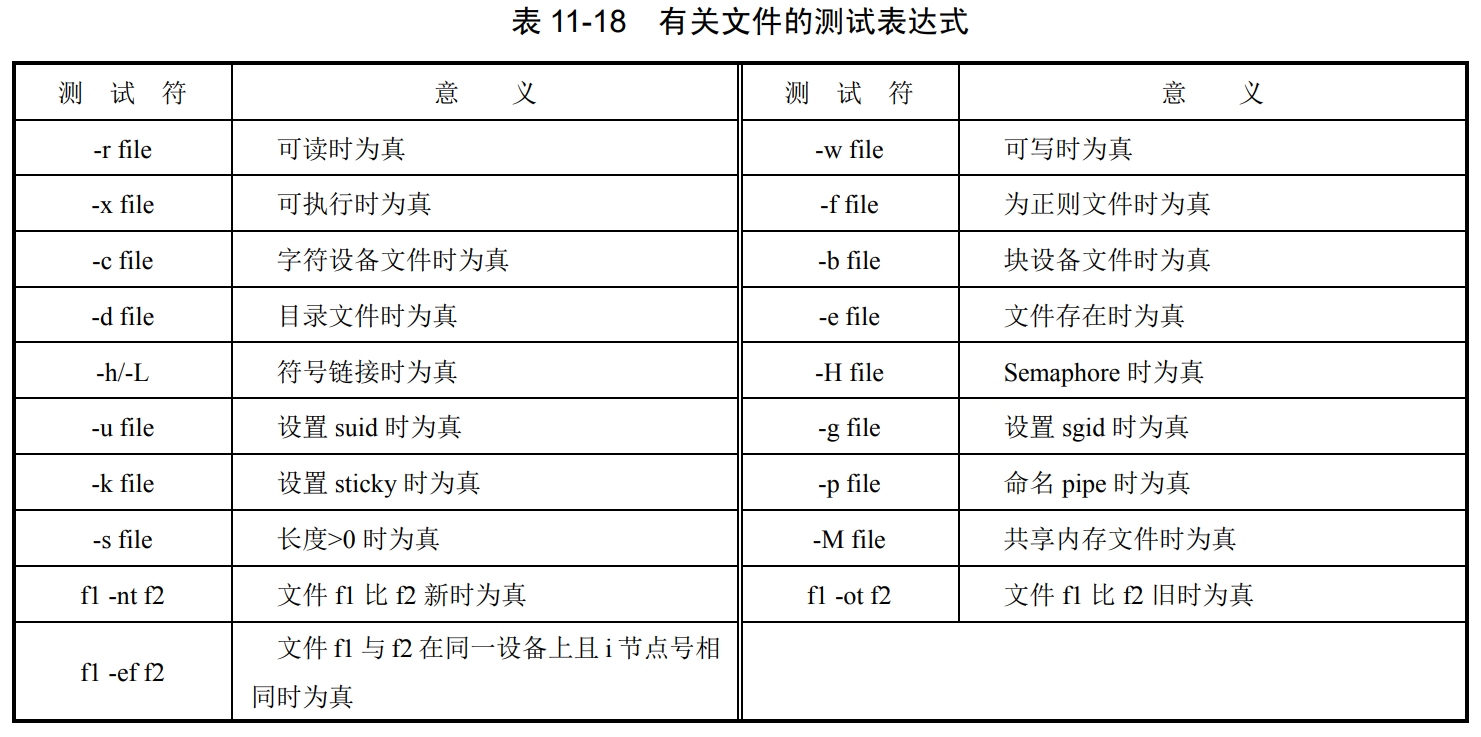
④ 复杂条件测试。当测试语句中的条件不止一个时,可根据实际情况使用逻辑**与(-a)、 或(-o)、非(!)**进行组合。例如:
test -s file -a -r file #如果文件长度>0 且可读时为真
test $val -lt 0 -o $val -gt 7 #如果变量 val 的值<0 或>7 时为真
(23)[]:另一种执行 test 命令的方法,这个符号的逻辑运算为是与(&&)、或(||)和非(!)
[ -s file ] && [ -r file ] #如果文件长度>0 且可读时为真
[ $val -lt 0 ] || [ $val -gt 7 ] #如果变量 val 的值<0 或>7 时为真
(24)dirname、basename:确定文件的路径名和基本名 dirname 和 basename 用于确定一个带有路径文件名的路径名和文件名,其用法为:
dirname names
basename [-a |-s, --suffix=suffix ] names
常用参数和选项有:names 为带有路径的文件名;-a 用于多文件名处理,若不使用-a 则 只处理第一个;-s,–suffix=suffix 用于在输出中删除扩展名。 dirname 用于输出带有路径文件名的路径名,若没有路径则输出“.”,表示当前路径。 basename 用于输出带有路径文件名的纯文件名,若使用了-s suffix 或 --suffix=suffix,则只输 出文件的主名。示例如下:
dirname /usr/bin/ /usr/include/stdio.h #输出/usr 和/usr/include
basename -a /usr/bin/ /usr/include/stdio.h #输出 bin 和 stdio.h
basename -a -s .h /usr/bin/ /usr/include/stdio.h #输出 bin 和 stdio
bash的其他扩展
1)参数或变量条件扩展
${#var}:变量 var 值的长度。
v a r : o f f 、 {var:off}、 var:off、{var:off:len}:var 中从 off 开始长度为 len 的子串。
KaTeX parse error: Expected '}', got '#' at position 5: {var#̲val}、{var##val}:从 var 头部去除由模式 val 匹配的最小和最大部分,返回剩余 部分。
KaTeX parse error: Expected '}', got 'EOF' at end of input: {var%val}、{var%%val}:从 var 尾部去除由模式 val 匹配的最小和最大部分,返回剩 余部分。
v a r / p a t t e r n / s t r 、 {var/pattern/str}、 var/pattern/str、{var//pattern/str}:pattern 为像文件扩展一样被扩展的匹配模式,var 也被扩展,且将 pattern 在 var 中的最大匹配替换为 str。前者仅进行首次匹配替换,后者将进 行所有的匹配替换。如果 pattern 的首字符为#/%,则从行首/尾进行匹配和替换。当 str 为 NULL 时,删除匹配的串。如果 var 为*或@,则替换将在位置参数上依次进行
2)“{ }”扩展与路径名扩展
如 a{a, b, c,}d 将被替换为 aad,abd,acd,这种替换常用在命令 行参数替换中。
mkdir /home/zh3/a{1,2,3}dir
#将在/home/zh3/创建 a1ddir、a2dir 和 a3dir 目录。
3) ′ s t r ′ 和 'str'和 ′str′和"str"与字符串扩展
转义字符会按照 ANSI C 的标准被替换
c=$'' #c 为响铃,而非字符串''
str=$'
' #str 为回车换行,而非字符串'
'
4)“(( ))”和“[[ ]]”
“((expr))”对算术表达式 expr 求值,如果这个值不是零,则返回状态是零,否则返回 1。 比如:
x=5; ((y=x++)); echo "x=$x y=$y" #x=6 y=5
5)$((expression)):计算表达式 expression 的值
以包括 C 语言除指针以外的几 乎所有运算符
x=3;y=4;z=5;x=$((z**2-x*y));echo $x #结果为 13
补充一下echo与printf
| 特性 | echo | printf |
|---|---|---|
| 自动换行 | 默认自动在末尾添加换行符 (
) | 不会自动添加换行符,需显式写
|
| 转义字符支持 | 依赖选项 (-e),非所有 Shell 兼容 | 默认支持转义字符(如 ,
) |
| 格式化输出 | 不支持复杂格式化 | 支持类 C 语言的格式化(如 %s, %d) |
echo "Hello" "World" # 输出:Hello World
printf "%s %s
" "Hello" "World" # 需明确格式
函数与基本结构
函数
函数定义时不必使用形式参数,对函数参数的引用如同在 shell 中使用位置参数一样。在 函数体内的 1 代表函数的第一个参数, 1 代表函数的第一个参数, 1代表函数的第一个参数,i 代表函数的第 i 个参数,KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲代表函数参数的个数**,*** 代表所有参数,$0 不代表函数名,而是它所在的 shell 程序名。
func_name( ) {
函数体
}
#调用
func_name param1 param2
例如:
#!/bin/sh
sysinfo() {
echo "$0 has $# param(s),they are: $*"
echo "I have $# param(s), and the 1'st param is: $1"
date +"%D%t%T"
uname –s
}
if-then-fi
if test_cmd
then
cmd_1
…
cmd_n
fi
#(1)首先判断是否带有一个参数,若无,则显示用法信息后报错返回 1;
#(2)若带有参数,则首先判断该参数作为文件是否存在,若不存在,报错返回 2;
#(3)若存在,判断是不是目录,若是则列目录的内容后返回 0;否则,提示用户参数不是目录,显示提示信息后返回 3。
---------
#!/bin/sh
#让系统调用 bshell 解释程序,此行不能直接跟在#!/bin/sh 的后面
if [ $#-lt 1 ] #参数中数小于1
then #无参数
echo -e "Usage:
$0 dir" #-e允许 echo 解析字符串中的 反斜杠转义字符
exit 1 #返回 1
fi
if [ ! -e "$1" ]; then #-e 是一个 文件测试运算符,用于检查文件或目录是否存在,依题意若不存在返回 2
echo -e "$1 doesn't exist!"; exit 2
fi
if [ -d "$1" ]; then #判断是否为目录
ls $1/*; exit 0; #列目录内容,返回 0
fi
echo " $1 is not a directory" #警告信息
exit 3 #返回 3
#改成if-then-elif-else-fi
----------
#!/bin/sh
if [ $#-ne 1 ]; then echo -e "Usage:
$0 dir"; exit 1
elif [ ! -e "$1" ]; then echo -e "$1 doesn't exist!"; exit 2
elif [ -d "$1" ]; then ls $1/*; exit 0
else echo "Warn: $1 is not a directory";exit 3
fi
while 结构
while condition
do
do_list #命令或语句系列
done
设计一个菜单程序,循环接收键盘输入,根据所输入的键来执行不同的功能,直到接收 到 0、q 或 Q 键退出。要求捕获信号 2。 为了简化设计又能说明问题,这里提供 3 个功能:func1、func2 和 Quit。实现 func 1 和 func 2 的功能键分别“1”和“2”,对应函数分别为 func1()和 func2();用于退出的功能键为 “0”、“q”或“Q”。
#!/bin/sh
func1( ){ #定义菜单功能函数 func1,用于完成功能 1
echo "This is function1!"
}
func2( ){ #定义菜单功能函数 func2,用于完成功能 2
echo "This is function2!"
}
trap "" 2 #捕获信号 2,忽略^C
#主程序
while true #循环接收用户输入
do
clear #清屏
echo -n " #-n取消输出末尾的自动换行符
+--------------------------------------------------+
| 1. func1 2. func2 0/q/Q.Exit |
+--------------------------------------------------+
Please get a choice: "
read x
case $x in
1) #处理键 1,执行 func1
func1;;
2) func2;; #处理键 2,执行 func2
0|Q|q) exit $?;; #处理 q 或 Q:返回上条命令执行结果
*) echo -e "";; #响铃表示非法输入
esac
read -p "Press Enter to continue: " x #供观察用,回车继续下一轮循环
done
until 结构
until condition
do
do_list #命令或语句系列
done
#设计一个程序,计算前 10 个正整数的和。
#!/bin/sh
x=0; y=1 #x 和 y 分别为和和控制变量,分别被初始化为 0 和 1
until [ $y -gt 10 ]
do
x=`expr $x + $y` #x=x+y
y=`expr $y + 1` #y=y+1
done
echo "1+ ... +10=$x" #输出结果
for 结构
for var in val1 val2 …
do
do_list
done
# 从命令行接收一些数值参数并计算这些参数的和
----------
#!/bin/sh
if [$# -It 1 ]
then echo -e"Usage:
$0 Number...
"; exit 1;
fi
x=0 #x 为和变量,初始化为 0
for y in $* #遍历所有命令行参数
do #没有判断参数的合法性,因为它们可能是非数值数据
x=`expr $x + $y` #累加 x=x+y
done
echo "The Sum is: $x" #输出结果
break continue
从循环中跳出:
break [n]
继续下一个循环:
continue [n]
#设计一个程序,计算前 n 个正整数的和,n 由命令行输入
#!/bin/sh
if [$# -It 1 ]
then echo -e"Usage:
$0 Integer...
"; exit 1;
fi
x=0; y=1 #x 和 y 分别为和和控制变量,分别被初始化为 0 和 1
while true
do
x=`expr $x + $y`; y=`expr $y + 1` #x=x+y; y=y+1
if [ $y -gt $1 ]; then break; fi #$1 为命令行参数,要为正整数
done
echo "1+...+$1=$x" #输出结果
shell调试
一般调试方法是通过 set 命令设置用于调试的参数-n、-v 和-x 等。当然 用户也可以在 shell 程序中的适当位置加入一些 echo 或 printf 命令用于调试、跟踪或观察。
| 选项 | 作用 | 输出内容 | 适用场景 |
|---|---|---|---|
-n | 仅语法检查 | 无执行,仅报错 | 预检查脚本语法 |
-v | 显示原始代码行 | 打印未解析的代码 | 跟踪脚本逻辑流程 |
-x | 显示展开后的命令 | 带 + 前缀的实际执行命令 | 调试变量替换和命令执行 |
#-n 无输出,仅检查语法。若语法错误(如缺少 fi),会报错。
#!/bin/bash
set -n # 启用语法检查
echo "这一行不会执行"
if [ 1 -eq 1 ]; then
echo "条件语句也不会执行"
fi
#-v显示脚本的每一行原始代码(未经解析)
#!/bin/bash
set -v # 启用逐行打印
name="Alice"
echo "Hello, $name"
date
./s2.sh #执行
>>
name="Alice"
echo "Hello, $name"
Hello, Alice
date
2025年 04月 22日 星期二 01:55:33 CST
#-x打印每条命令及其展开后的参数(如变量值),前缀为 +
#!/bin/bash
set -x # 启用追踪
dir="/tmp"
ls "$dir" | wc -l
./s3.sh
>>
+ dir=/tmp
+ ls /tmp #这里代码中"$dir" 被其值替换掉了
+ wc -l
14
#-vx可以一起使用
#!/bin/bash
set -vx # 同时启用逐行打印和追踪
file="test.txt"
touch "$file"
echo "Created: $file"
>>
file="test.txt"
+ file=test.txt
touch "$file"
+ touch test.txt
echo "Created: $file"
+ echo Created: test.txt
Created: test.txt
,执行 func1
func1;;
2) func2;; #处理键 2,执行 func2
0|Q|q) exit $?;; #处理 q 或 Q:返回上条命令执行结果
*) echo -e "";; #响铃表示非法输入
esac
read -p "Press Enter to continue: " x #供观察用,回车继续下一轮循环
done
until 结构
until condition
do
do_list #命令或语句系列
done
#设计一个程序,计算前 10 个正整数的和。
#!/bin/sh
x=0; y=1 #x 和 y 分别为和和控制变量,分别被初始化为 0 和 1
until [ $y -gt 10 ]
do
x=`expr $x + $y` #x=x+y
y=`expr $y + 1` #y=y+1
done
echo "1+ ... +10=$x" #输出结果
for 结构
for var in val1 val2 …
do
do_list
done
# 从命令行接收一些数值参数并计算这些参数的和
----------
#!/bin/sh
if [$# -It 1 ]
then echo -e"Usage:
$0 Number...
"; exit 1;
fi
x=0 #x 为和变量,初始化为 0
for y in $* #遍历所有命令行参数
do #没有判断参数的合法性,因为它们可能是非数值数据
x=`expr $x + $y` #累加 x=x+y
done
echo "The Sum is: $x" #输出结果
break continue
从循环中跳出:
break [n]
继续下一个循环:
continue [n]
#设计一个程序,计算前 n 个正整数的和,n 由命令行输入
#!/bin/sh
if [$# -It 1 ]
then echo -e"Usage:
$0 Integer...
"; exit 1;
fi
x=0; y=1 #x 和 y 分别为和和控制变量,分别被初始化为 0 和 1
while true
do
x=`expr $x + $y`; y=`expr $y + 1` #x=x+y; y=y+1
if [ $y -gt $1 ]; then break; fi #$1 为命令行参数,要为正整数
done
echo "1+...+$1=$x" #输出结果
shell调试
一般调试方法是通过 set 命令设置用于调试的参数-n、-v 和-x 等。当然 用户也可以在 shell 程序中的适当位置加入一些 echo 或 printf 命令用于调试、跟踪或观察。
| 选项 | 作用 | 输出内容 | 适用场景 |
|---|---|---|---|
-n | 仅语法检查 | 无执行,仅报错 | 预检查脚本语法 |
-v | 显示原始代码行 | 打印未解析的代码 | 跟踪脚本逻辑流程 |
-x | 显示展开后的命令 | 带 + 前缀的实际执行命令 | 调试变量替换和命令执行 |
#-n 无输出,仅检查语法。若语法错误(如缺少 fi),会报错。
#!/bin/bash
set -n # 启用语法检查
echo "这一行不会执行"
if [ 1 -eq 1 ]; then
echo "条件语句也不会执行"
fi
#-v显示脚本的每一行原始代码(未经解析)
#!/bin/bash
set -v # 启用逐行打印
name="Alice"
echo "Hello, $name"
date
./s2.sh #执行
>>
name="Alice"
echo "Hello, $name"
Hello, Alice
date
2025年 04月 22日 星期二 01:55:33 CST
#-x打印每条命令及其展开后的参数(如变量值),前缀为 +
#!/bin/bash
set -x # 启用追踪
dir="/tmp"
ls "$dir" | wc -l
./s3.sh
>>
+ dir=/tmp
+ ls /tmp #这里代码中"$dir" 被其值替换掉了
+ wc -l
14
#-vx可以一起使用
#!/bin/bash
set -vx # 同时启用逐行打印和追踪
file="test.txt"
touch "$file"
echo "Created: $file"
>>
file="test.txt"
+ file=test.txt
touch "$file"
+ touch test.txt
echo "Created: $file"
+ echo Created: test.txt
Created: test.txt