【Linux】动静态库

文章目录
- 静态库
- 静态库的手动创建过程
- 动态库
- 动态库的特点
- 创建动态库
- 如何使用动态库
- 动态库和静态库的优先级
- 动态库 vs 静态库的优先级
- 库搜索顺序
- 总结
静态库
静态库是一种在编译阶段将库文件的内容直接整合到目标程序中的库文件形式。使用静态库后,库的代码会成为可执行文件的一部分,运行时不需要依赖外部库。
静态库的手动创建过程

我们写两个c文件,并且两个c文件都带有头文件:
my_stdio.c
#include "my_stdio.h"
#includemy_stdio.h
#pragma once
#include上面两个文件是我们模拟实现的一个简单的stdio.h的库。
my_string.c
#include "my_string.h"
int my_strlen(const char *s)
{
const char *end = s;
while(*end != '�') end++;
return end - s;
}
my_string.h
#pragma once
int my_strlen(const char *s);
另外两个文件则是实现的一个简单的string的一个接口,我们将用这四个文件来手动制作一个静态库。
方法1:
首先我们需要将两个.c文件编译为.o文件:
形成两个同名的.o文件
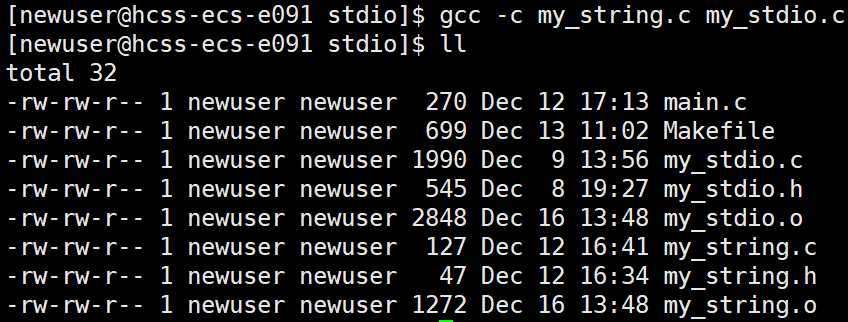
首先我们来了解一个命令:ar
ar命令是 Linux 下的一个归档工具,通常用于创建、修改和提取静态库(archive files)。它主要用于将多个文件(通常是目标文件 .o)组合成一个归档文件 .a,以便在编译过程中与其他代码链接使用。
常用选项:
c:创建归档文件。如果文件已存在,覆盖它。r:将文件添加到归档中。如果已存在相同文件,替换它。t:显示归档文件的内容列表。x:从归档文件中提取文件。d:从归档文件中删除文件。q:快速添加文件到归档末尾,不检查重复文件。s:生成归档文件的索引(一般用于加速链接过程)。
常用语法:
ar [options] archive_name file...
我们就用这个命令来创建静态库:
我们需要用到两个选项,一个是r,一个是c,如果没有这个文件的静态库,则创建,如果有则替换。
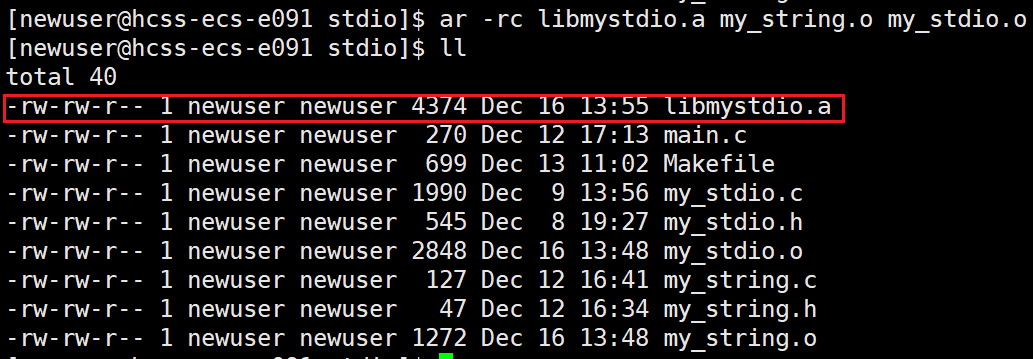
这样就形成了一个静态库,但是这样我们还是用不了,我们还需要将库安装到系统当中:

首先我们需要将头文件拷贝到usr目录下的include当中,然后将静态库拷贝到lib64这个文件当中:

注意:这里需要用超级用户来拷贝
在做好准备之后我们可以看见,还是形成不了可执行程序:
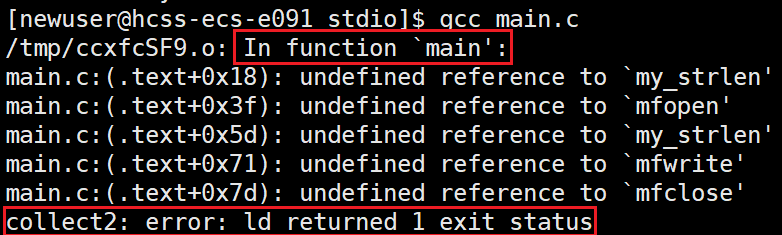
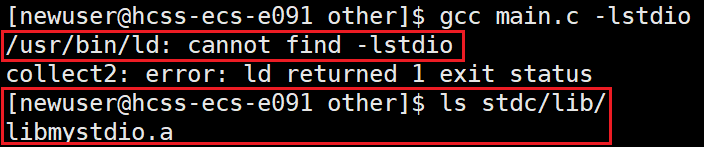
系统还是找不到我们要用的静态库,所以我们需要指定给他说我们的静态库是什么名字:

在 gcc 中,-l 选项用于指定链接的库(library)。它的作用是告诉编译器,在链接阶段需要链接某个特定的库。l后面可以加上空格,也可以不加,我们刚刚拷贝到lib64中的是libstdio.a,但是用选项来索引库的时候名字是stdio不需要加前面的lib和后缀.a
形成可执行程序之后我们来运行一下:

方法2:不需要将静态库拷贝到lib64当中
我们先将刚刚加载到系统当中的库删除

我们先将静态库和需要编译的代码放在另一个目录下,方便实验:

可以看见,放在当前目录下的一个指定目录下是不能编译成功的:
我们需要加上另一个选项:
在 gcc 中,-L 选项用于指定库文件的搜索路径。它告诉编译器在指定路径中查找库文件,而不是仅使用默认的库路径(如 /lib 或 /usr/lib)。
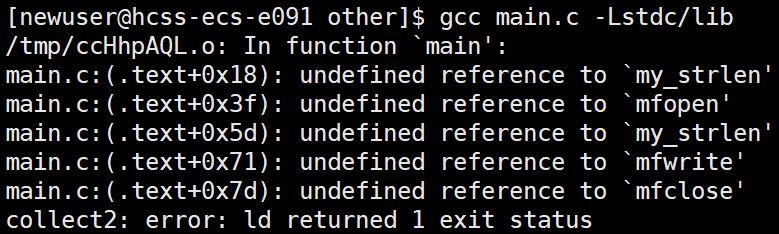
加上L的选项还是编译不成功,原因:
原因分析
-
-L只指定了路径,但没有指定具体要链接的库-L告诉编译器在哪里查找库,但不会自动链接路径下的库。- 必须使用
-l显式指定需要链接的库。
-
库文件的命名规则
gcc查找库文件时,遵循以下命名规则:- 静态库:文件名必须以
lib开头,扩展名为.a,例如libmylib.a。 - 动态库:文件名必须以
lib开头,扩展名为.so,例如libmylib.so。 - 当使用
-lmylib时,编译器会在-L指定的路径中查找libmylib.a或libmylib.so。
如果库文件不符合上述命名规则,例如文件名是
mylib.a或custom_library.so,gcc无法识别这些文件。 - 静态库:文件名必须以
-
直接使用库文件路径未显式指定路径
如果没有通过-l指定库,而直接提供库文件路径,则必须使用完整路径:gcc main.c /path/to/libmylib.a -o main
所以我们需要加上-l选项:

第三种方法:当静态库和头文件都没有放在系统文件当中时
先将include的中的头文件删除了

将头文件和静态库分别放在这两个目录当中

然后我们编译main.c:
在使用 gcc 编译时,-I 选项用于指定头文件的搜索路径,让编译器能够找到自定义或非标准路径中的头文件。

这几个分别是库的名字,和定位库,还有定位头文件。
动态库
动态库是一种在程序运行时加载的库文件,相比静态库,它可以实现代码共享和更小的程序体积。
动态库的特点
-
文件扩展名:
- 在 Linux 系统中,动态库通常以
.so为扩展名(Shared Object),例如:libmylib.so。
- 在 Linux 系统中,动态库通常以
-
动态加载:
- 程序运行时才会加载动态库,大幅减少可执行文件的大小。
-
共享性:
- 同一动态库可以被多个程序同时使用,节省内存资源。
-
版本更新方便:
- 更新库文件后,无需重新编译程序,只需确保接口兼容即可。
创建动态库
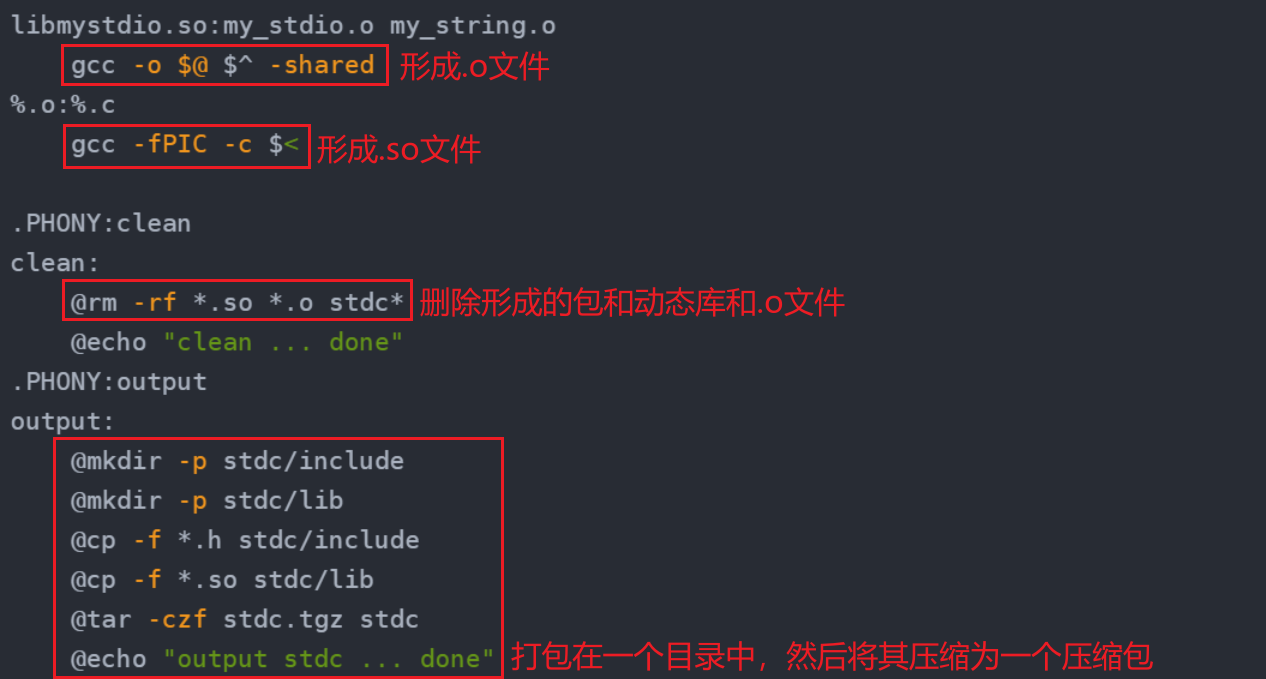
我们先来写一个简单Makfile
libmystdio.so:my_stdio.o my_string.o
gcc -o $@ $^ -shared
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
@rm -rf *.so *.o stdc*
@echo "clean ... done"
.PHONY:output
output:
@mkdir -p stdc/include
@mkdir -p stdc/lib
@cp -f *.h stdc/include
@cp -f *.so stdc/lib
@tar -czf stdc.tgz stdc
@echo "output stdc ... done"
gcc -fPIC -c $<
这个选项中的-fPIC是形成与位置无关码
如何使用动态库
第一种方法:拷贝到系统文件当中
第一种方法和静态库的一样,这里就不做赘述。
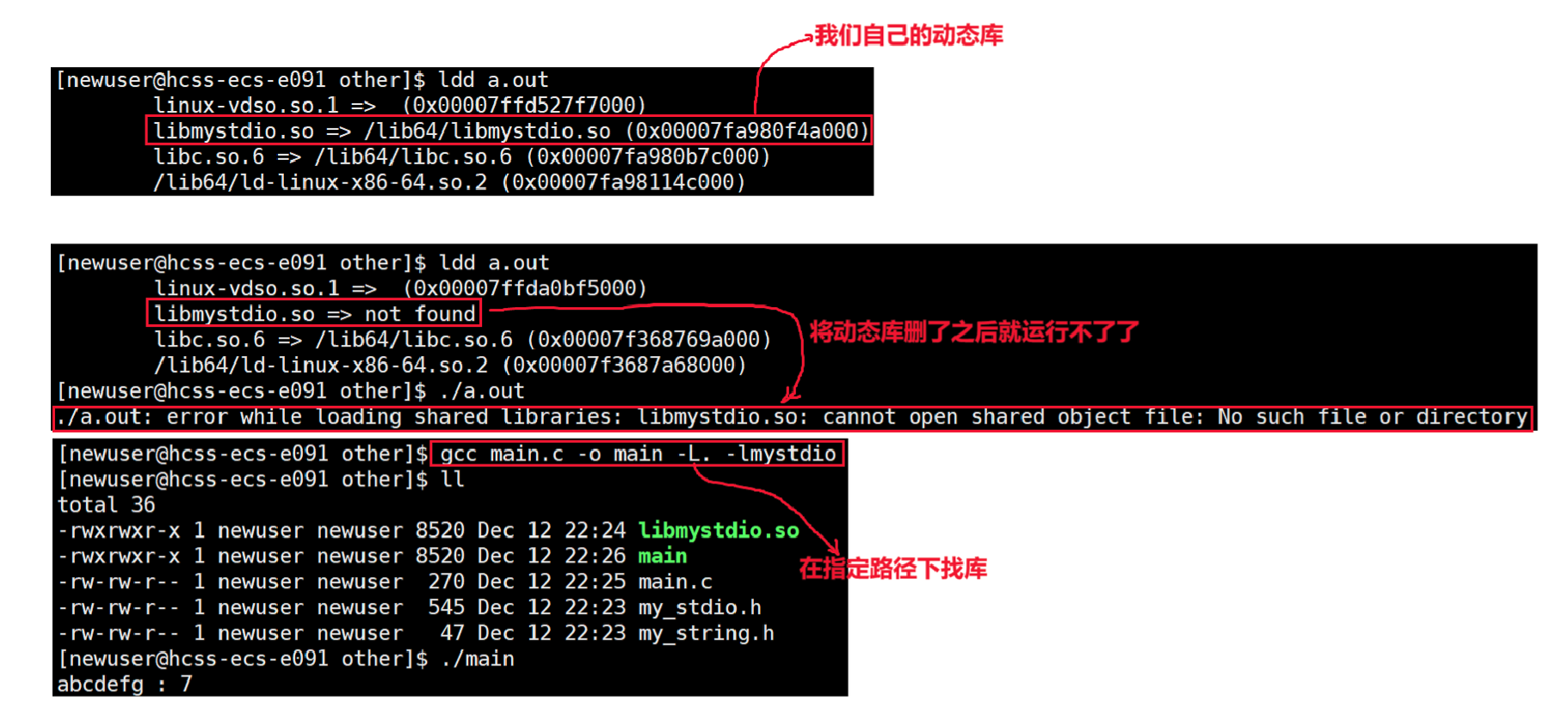
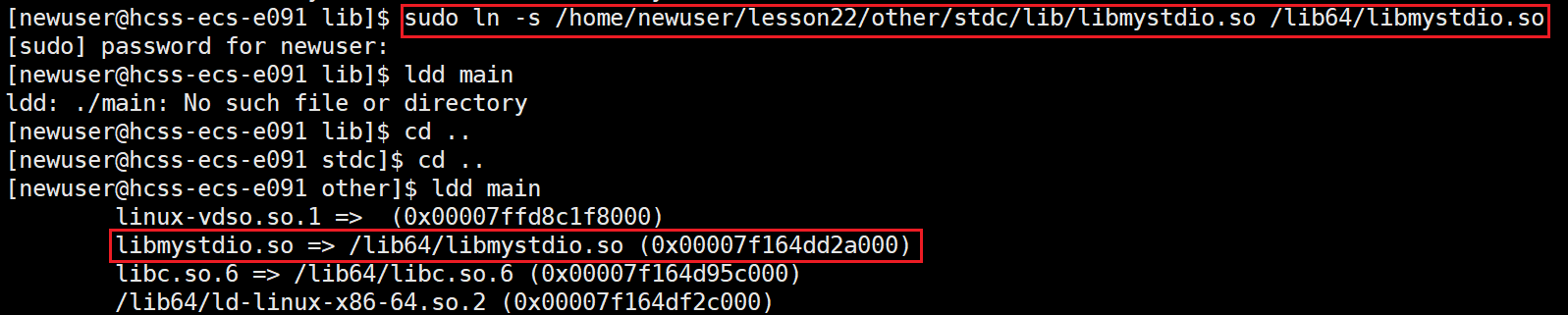
第二种方法:建立软链接
可以看见,虽然形成了可执行程序,但是运行的时候还是找不到对应的库


虽然告诉系统库在哪了,但是链接的时候还是没找到。
可以看见在lib64下建立软链接系统就可以找到我们库的位置了
第三种方法:通过控制环境变量来控制系统查找的规则
LD_LIBRARY_PATH 是 Linux 系统中用于指定动态库搜索路径的环境变量。在运行时,动态链接器会根据此变量的值查找所需的共享库文件(.so 文件)。
-
动态库的运行时搜索路径:
- 默认情况下,动态链接器会在以下路径中查找共享库:
/lib/usr/lib/usr/local/lib
- 如果动态库存放在非默认路径,需要通过
LD_LIBRARY_PATH指定额外的搜索路径。
- 默认情况下,动态链接器会在以下路径中查找共享库:
-
临时加载动态库:
- 在不修改系统配置文件(如
/etc/ld.so.conf)的情况下,为某些程序临时指定动态库路径。
- 在不修改系统配置文件(如

当修改完环境变量之后,ldd我们的可执行程序,可以看见就可以查看到动态库了。

动态库和静态库的优先级
在 Linux 系统中,使用 gcc 或类似工具进行编译和链接时,动态库(shared library, .so) 和 静态库(static library, .a) 的优先级由动态链接器和链接器的搜索顺序决定。
动态库 vs 静态库的优先级
- 默认情况下,链接器优先选择 动态库。
- 如果没有找到对应的动态库,链接器才会选择 静态库。
这种行为的主要原因是:
- 动态库可以减少可执行文件的大小,并支持运行时共享。
- 静态库将整个库文件嵌入可执行文件中,增加了文件体积,且无法享受动态链接的更新优势。
库搜索顺序
-
动态库优先搜索路径:
- 在默认路径中(如
/lib,/usr/lib,/usr/local/lib),动态库.so文件会被优先查找。 - 如果通过
-L指定了自定义路径,也会优先查找.so。
- 在默认路径中(如
-
静态库备选:
- 如果动态库不存在,或者编译时显式指定了使用静态库的选项,链接器会尝试查找
.a文件。
- 如果动态库不存在,或者编译时显式指定了使用静态库的选项,链接器会尝试查找
总结
本文详细介绍了静态库与动态库的概念、创建方法及其使用方式。静态库通过将代码直接打包到可执行文件中,提供了程序独立性;而动态库则通过共享库文件实现了代码复用,减小了程序体积。在实际开发中,理解动态库和静态库的优缺点,合理选择库的类型尤为重要。
此外,文章还探讨了动态库和静态库的优先级以及库的搜索顺序,通过控制编译器选项(如 -L 和 -I)以及环境变量(如 LD_LIBRARY_PATH)来管理库的使用路径。掌握这些基础知识,将帮助开发者更灵活地处理程序链接和依赖问题,提升项目开发效率与可维护性。
总结一句话:熟练掌握静态库和动态库的原理与实践方法,是成为优秀开发者的必经之路。