


【YOLOv8】YOLOv8改进系列(2)----替换主干网络之FasterNet(CVPR 2023)

主页:HABUO🍁主页:HABUO
🍁YOLOv8入门+改进专栏🍁
🍁如果再也不能见到你,祝你早安,午安,晚安🍁
【YOLOv8改进系列】:
【YOLOv8】YOLOv8结构解读
YOLOv8改进系列(1)----替换主干网络之EfficientViT
YOLOv8改进系列(2)----替换主干网络之FasterNet
YOLOv8改进系列(3)----替换主干网络之ConvNeXt V2
YOLOv8改进系列(4)----替换C2f之FasterNet中的FasterBlock替换C2f中的Bottleneck
YOLOv8改进系列(5)----替换主干网络之EfficientFormerV2
YOLOv8改进系列(6)----替换主干网络之VanillaNet
YOLOv8改进系列(7)----替换主干网络之LSKNet
YOLOv8改进系列(8)----替换主干网络之Swin Transformer
YOLOv8改进系列(9)----替换主干网络之RepViT
目录
💯一、FasterNet介绍
简介
核心创新点
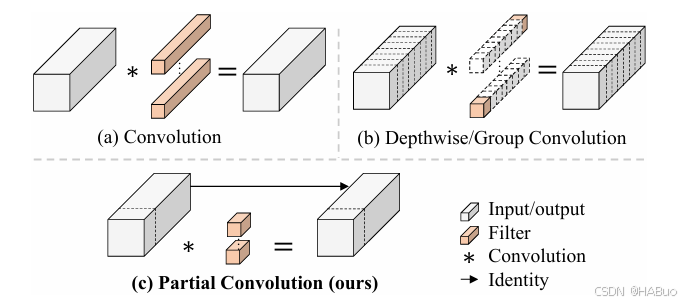
Partial Convolution(PConv,部分卷积)
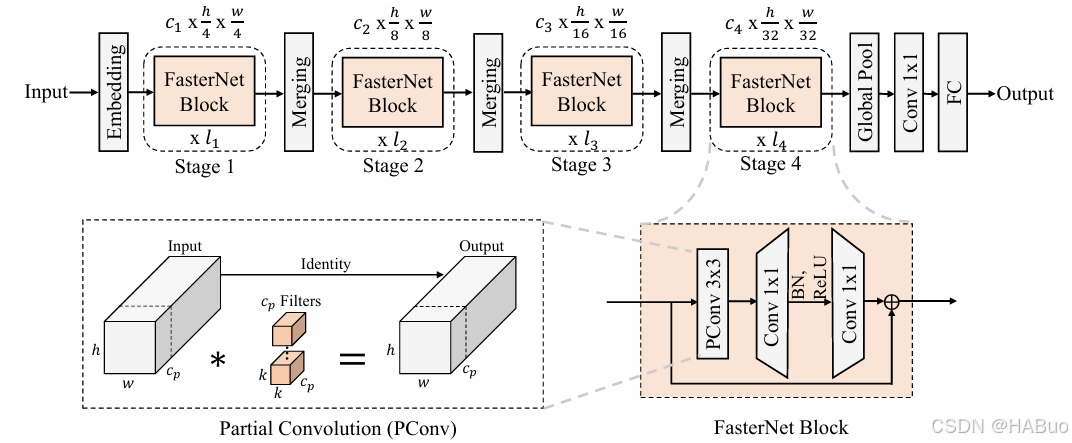
FasterNet架构
实验结果
关键贡献
💯二、网络结构
💯三、具体添加方法
第①步:创建FasterNet.py
第②步:修改task.py
(1) 引入创建的efficientViT文件
(2)修改_predict_once函数
(3)修改parse_model函数
第③步:yolov8.yaml文件修改
第④步:验证是否加入成功
💯一、FasterNet介绍
- 论文题目:《EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention》
- 论文地址:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
- 源码地址:github.com
简介
神经网络在计算机视觉任务(如图像分类、目标检测和分割)中取得了显著的性能提升,但随着应用的普及,对低延迟和高吞吐量的需求也日益增加。为了实现更快的神经网络,研究者们通常通过减少浮点运算次数(FLOPs)来降低计算复杂度。然而,论文指出,单纯减少FLOPs并不一定能显著降低延迟,因为许多网络在运行时受到内存访问效率的限制,导致实际的浮点运算速度(FLOPS)较低。
例如,许多轻量级网络(如MobileNets、ShuffleNets等)使用深度可分离卷积(DWConv)或分组卷积(GConv)来减少FLOPs,但这些操作会增加内存访问次数,从而降低FLOPS。此外,一些网络还会引入额外的数据操作(如拼接、洗牌和池化),这些操作在小模型中会显著增加运行时间。因此,论文的核心问题是:如何在减少FLOPs的同时,提高FLOPS,从而真正实现低延迟?
核心创新点
Partial Convolution(PConv,部分卷积)
- 动机:传统卷积(Conv)和深度可分离卷积(DWConv)在计算效率和内存访问上存在冗余。例如,DWConv虽减少了计算量,但未充分利用计算设备的并行能力。
- 设计思想:PConv仅对输入特征图的部分通道进行常规卷积运算(如1/4通道),其余通道保持原样。通过这种方式,减少冗余计算和内存访问次数,同时保留足够的信息提取能力。
- 技术细节:
- 部分通道处理:对输入特征图的连续或均匀分布的通道子集执行常规卷积。
- 逐点卷积补充:在PConv后接一个逐点卷积(Pointwise Conv),融合所有通道的信息。
- 优势:相比DWConv,PConv在相同计算量下能提取更丰富的空间特征,同时FLOPs和内存访问次数显著降低。
FasterNet架构
基于PConv,论文提出了一个新的神经网络家族——FasterNet。FasterNet的设计目标是在各种设备(如GPU、CPU和ARM处理器)上实现高运行速度,同时不牺牲准确性。
FasterNet架构特点
-
分层结构:FasterNet包含四个层次,每个层次由多个FasterNet块组成。每个块包含一个PConv层和两个PWConv层,形成一个倒置残差结构。
-
嵌入层和合并层:每个层次之前都有一个嵌入层(用于空间下采样)或合并层(用于通道扩展)。
-
简单高效:FasterNet的设计尽量简单,避免过多的归一化和激活层,以减少计算开销。例如,仅在中间PWConv后使用归一化和激活层。
-
多种变体:为了适应不同的计算预算,FasterNet提供了多种变体(如T0、T1、T2、S、M、L),这些变体在深度和宽度上有所不同。
实验结果
-
速度与精度平衡
- ImageNet-1K分类任务:
- 微型模型:FasterNet-T0在GPU、CPU、ARM上的推理速度分别比MobileViT-XXS快2.8×、3.3×、2.4×,同时Top-1精度提升2.9%。
- 大型模型:FasterNet-L达到83.5%的Top-1精度,与Swin-B相当,但GPU推理吞吐量提升49%,CPU计算时间减少42%。
- 下游任务:在目标检测(COCO)、语义分割(ADE20K)等任务中,FasterNet在速度和精度上均优于MobileNet、ConvNeXt等模型。
- ImageNet-1K分类任务:
-
硬件适应性
- 针对边缘设备(如ARM处理器)优化,显著降低内存占用和计算延迟,适合实时应用场景(如移动端图像处理)。
关键贡献
-
理论突破
- 提出计算效率(FLOPS)与模型速度的非线性关系,指出单纯降低FLOPs可能无法充分利用硬件算力,需优化实际计算密度。
- 通过实验证明,更高的FLOPS(合理设计下)可带来更快的实际推理速度。
-
工程价值
- PConv模块:可作为即插即用组件,替代传统卷积或DWConv,提升现有模型的效率。
- 开源实现:提供了FasterNet的代码和预训练模型,推动高效神经网络的实际部署。
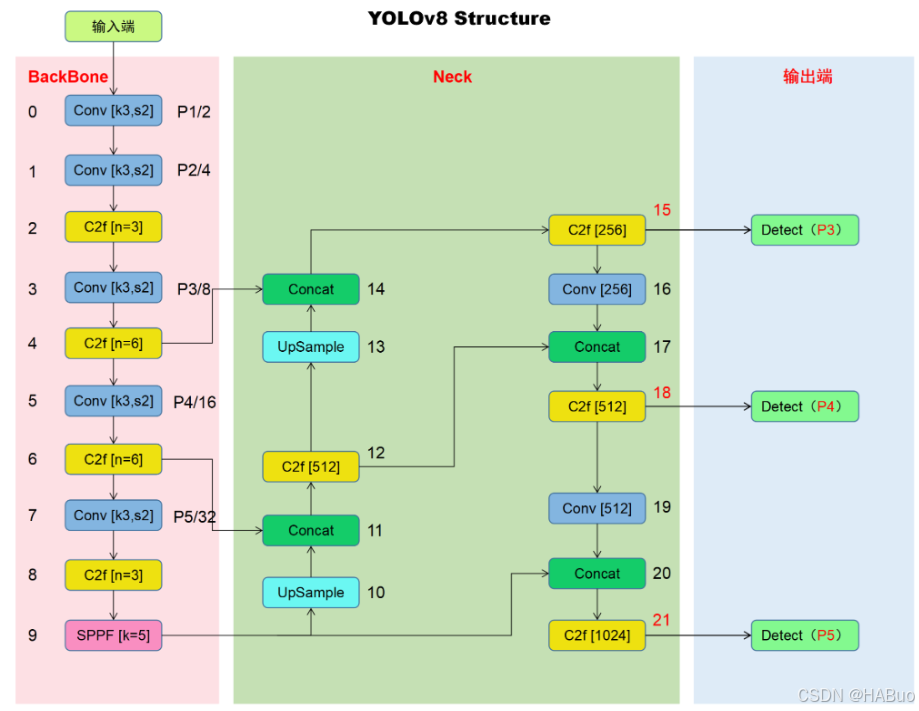
💯二、网络结构
YOLOv8结构
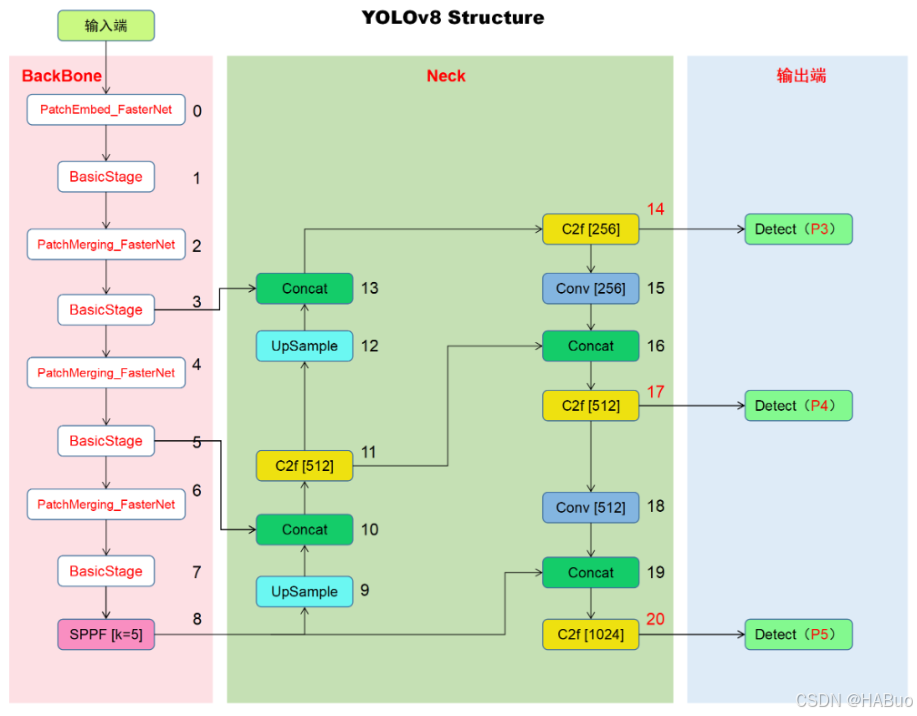
修改后结构:
💯三、具体添加方法
第①步:创建FasterNet.py
创建完成后,将下面代码直接复制粘贴进去:
import torch, yaml
import torch.nn as nn
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from functools import partial
from typing import List
from torch import Tensor
import copy
import os
import numpy as np
__all__ = ['fasternet_t0', 'fasternet_t1', 'fasternet_t2', 'fasternet_s', 'fasternet_m', 'fasternet_l']
class Partial_conv3(nn.Module):
def __init__(self, dim, n_div, forward):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x: Tensor) -> Tensor:
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
return x
class MLPBlock(nn.Module):
def __init__(self,
dim,
n_div,
mlp_ratio,
drop_path,
layer_scale_init_value,
act_layer,
norm_layer,
pconv_fw_type
):
super().__init__()
self.dim = dim
self.mlp_ratio = mlp_ratio
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.n_div = n_div
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.spatial_mixing = Partial_conv3(
dim,
n_div,
pconv_fw_type
)
if layer_scale_init_value > 0:
self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.forward = self.forward_layer_scale
else:
self.forward = self.forward
def forward(self, x: Tensor) -> Tensor:
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(self.mlp(x))
return x
def forward_layer_scale(self, x: Tensor) -> Tensor:
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(
self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))
return x
class BasicStage(nn.Module):
def __init__(self,
dim,
depth,
n_div,
mlp_ratio,
drop_path,
layer_scale_init_value,
norm_layer,
act_layer,
pconv_fw_type
):
super().__init__()
blocks_list = [
MLPBlock(
dim=dim,
n_div=n_div,
mlp_ratio=mlp_ratio,
drop_path=drop_path[i],
layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer,
act_layer=act_layer,
pconv_fw_type=pconv_fw_type
)
for i in range(depth)
]
self.blocks = nn.Sequential(*blocks_list)
def forward(self, x: Tensor) -> Tensor:
x = self.blocks(x)
return x
class PatchEmbed(nn.Module):
def __init__(self, patch_size, patch_stride, in_chans, embed_dim, norm_layer):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
x = self.norm(self.proj(x))
return x
class PatchMerging(nn.Module):
def __init__(self, patch_size2, patch_stride2, dim, norm_layer):
super().__init__()
self.reduction = nn.Conv2d(dim, 2 * dim, kernel_size=patch_size2, stride=patch_stride2, bias=False)
if norm_layer is not None:
self.norm = norm_layer(2 * dim)
else:
self.norm = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
x = self.norm(self.reduction(x))
return x
class FasterNet(nn.Module):
def __init__(self,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=(1, 2, 8, 2),
mlp_ratio=2.,
n_div=4,
patch_size=4,
patch_stride=4,
patch_size2=2, # for subsequent layers
patch_stride2=2,
patch_norm=True,
feature_dim=1280,
drop_path_rate=0.1,
layer_scale_init_value=0,
norm_layer='BN',
act_layer='RELU',
init_cfg=None,
pretrained=None,
pconv_fw_type='split_cat',
**kwargs):
super().__init__()
if norm_layer == 'BN':
norm_layer = nn.BatchNorm2d
else:
raise NotImplementedError
if act_layer == 'GELU':
act_layer = nn.GELU
elif act_layer == 'RELU':
act_layer = partial(nn.ReLU, inplace=True)
else:
raise NotImplementedError
self.num_stages = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_stages - 1))
self.mlp_ratio = mlp_ratio
self.depths = depths
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
patch_size=patch_size,
patch_stride=patch_stride,
in_chans=in_chans,
embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None
)
# stochastic depth decay rule
dpr = [x.item()
for x in torch.linspace(0, drop_path_rate, sum(depths))]
# build layers
stages_list = []
for i_stage in range(self.num_stages):
stage = BasicStage(dim=int(embed_dim * 2 ** i_stage),
n_div=n_div,
depth=depths[i_stage],
mlp_ratio=self.mlp_ratio,
drop_path=dpr[sum(depths[:i_stage]):sum(depths[:i_stage + 1])],
layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer,
act_layer=act_layer,
pconv_fw_type=pconv_fw_type
)
stages_list.append(stage)
# patch merging layer
if i_stage < self.num_stages - 1:
stages_list.append(
PatchMerging(patch_size2=patch_size2,
patch_stride2=patch_stride2,
dim=int(embed_dim * 2 ** i_stage),
norm_layer=norm_layer)
)
self.stages = nn.Sequential(*stages_list)
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
raise NotImplementedError
else:
layer = norm_layer(int(embed_dim * 2 ** i_emb))
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def forward(self, x: Tensor) -> Tensor:
# output the features of four stages for dense prediction
x = self.patch_embed(x)
outs = []
for idx, stage in enumerate(self.stages):
x = stage(x)
if idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
return outs
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def fasternet_t0(weights=None, cfg='ultralytics/nn/backbone/faster_cfg/fasternet_t0.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
def fasternet_t1(weights=None, cfg='ultralytics/nn/backbone/faster_cfg/fasternet_t1.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
def fasternet_t2(weights=None, cfg='ultralytics/nn/backbone/faster_cfg/fasternet_t2.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
def fasternet_s(weights=None, cfg='ultralytics/nn/backbone/faster_cfgg/fasternet_s.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
def fasternet_m(weights=None, cfg='ultralytics/nn/backbone/faster_cfg/fasternet_m.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
def fasternet_l(weights=None, cfg='ultralytics/nn/backbone/faster_cfg/fasternet_l.yaml'):
with open(cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
model = FasterNet(**cfg)
if weights is not None:
pretrain_weight = torch.load(weights, map_location='cpu')
model.load_state_dict(update_weight(model.state_dict(), pretrain_weight))
return model
if __name__ == '__main__':
import yaml
model = fasternet_t0(weights='fasternet_t0-epoch.281-val_acc1.71.9180.pth', cfg='cfg/fasternet_t0.yaml')
print(model.channel)
inputs = torch.randn((1, 3, 640, 640))
for i in model(inputs):
print(i.size())之后在该路径下即backbone,将下述代码拷贝到对应文件:
fasternet_l.yaml
mlp_ratio: 2
embed_dim: 192
depths: [3, 4, 18, 3]
feature_dim: 1280
patch_size: 4
patch_stride: 4
patch_size2: 2
patch_stride2: 2
layer_scale_init_value: 0 # no layer scale
drop_path_rate: 0.3
norm_layer: BN
act_layer: RELU
n_div: 4fasternet_m.yaml
mlp_ratio: 2
embed_dim: 144
depths: [3, 4, 18, 3]
feature_dim: 1280
patch_size: 4
patch_stride: 4
patch_size2: 2
patch_stride2: 2
layer_scale_init_value: 0 # no layer scale
drop_path_rate: 0.2
norm_layer: BN
act_layer: RELU
n_div: 4fasternet_t0.yaml
mlp_ratio: 2
embed_dim: 40
depths: [1, 2, 8, 2]
feature_dim: 1280
patch_size: 4
patch_stride: 4
patch_size2: 2
patch_stride2: 2
layer_scale_init_value: 0 # no layer scale
drop_path_rate: 0.
norm_layer: BN
act_layer: GELU
n_div: 4fasternet_t1.yaml
mlp_ratio: 2
embed_dim: 64
depths: [1, 2, 8, 2]
feature_dim: 1280
patch_size: 4
patch_stride: 4
patch_size2: 2
patch_stride2: 2
layer_scale_init_value: 0 # no layer scale
drop_path_rate: 0.02
norm_layer: BN
act_layer: GELU
n_div: 4fasternet_t2.yaml
mlp_ratio: 2
embed_dim: 96
depths: [1, 2, 8, 2]
feature_dim: 1280
patch_size: 4
patch_stride: 4
patch_size2: 2
patch_stride2: 2
layer_scale_init_value: 0 # no layer scale
drop_path_rate: 0.05
norm_layer: BN
act_layer: RELU
n_div: 4文件命名如下:

第②步:修改task.py
(1) 引入创建的efficientViT文件

from ultralytics.nn.backbone.fasternet import *(2)修改_predict_once函数
可直接将下述代码替换对应位置
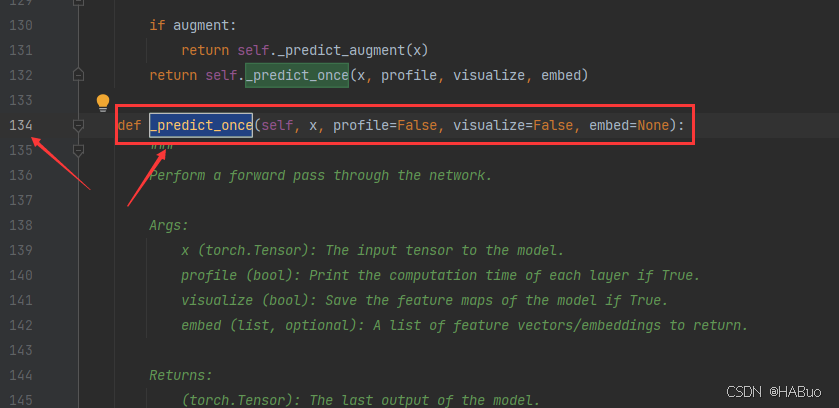
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
for idx, m in enumerate(self.model):
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x if x_ is not None])}')
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
# if type(x) in {list, tuple}:
# if idx == (len(self.model) - 1):
# if type(x[1]) is dict:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x[1]["one2one"]])}')
# else:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x[1]])}')
# else:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x if x_ is not None])}')
# elif type(x) is dict:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x["one2one"]])}')
# else:
# if not hasattr(m, 'backbone'):
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{x.size()}')
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x(3)修改parse_model函数
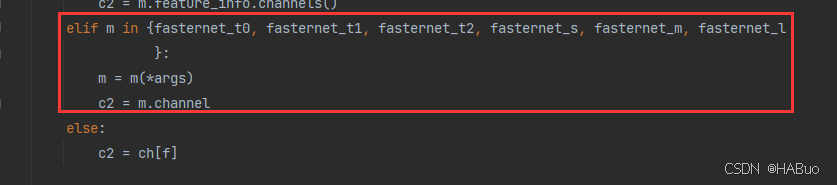
可以直接把下面的代码粘贴到对应的位置中
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""
Parse a YOLO model.yaml dictionary into a PyTorch model.
Args:
d (dict): Model dictionary.
ch (int): Input channels.
verbose (bool): Whether to print model details.
Returns:
(tuple): Tuple containing the PyTorch model and sorted list of output layers.
"""
import ast
# Args
max_channels = float("inf")
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
if len(scales[scale]) == 3:
depth, width, max_channels = scales[scale]
elif len(scales[scale]) == 4:
depth, width, max_channels, threshold = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"
{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<60}{'arguments':<50}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
is_backbone = False
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
try:
if m == 'node_mode':
m = d[m]
if len(args) > 0:
if args[0] == 'head_channel':
args[0] = int(d[args[0]])
t = m
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
except:
pass
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
try:
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
except:
args[j] = a
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in {
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, ELAN1, AConv, SPPELAN, C2fAttn, C3, C3TR,
C3Ghost, nn.Conv2d, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, PSA, SCDown, C2fCIB
}:
if args[0] == 'head_channel':
args[0] = d[args[0]]
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
elif m in {AIFI}:
args = [ch[f], *args]
c2 = args[0]
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
cm = make_divisible(min(cm, max_channels) * width, 8)
args = [c1, cm, c2, *args[2:]]
if m in (HGBlock):
args.insert(4, n) # number of repeats
n = 1
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in frozenset({Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn, v10Detect}):
args.append([ch[x] for x in f])
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
elif m is CBLinear:
c2 = make_divisible(min(args[0][-1], max_channels) * width, 8)
c1 = ch[f]
args = [c1, [make_divisible(min(c2_, max_channels) * width, 8) for c2_ in args[0]], *args[1:]]
elif m is CBFuse:
c2 = ch[f[-1]]
elif isinstance(m, str):
t = m
if len(args) == 2:
m = timm.create_model(m, pretrained=args[0], pretrained_cfg_overlay={'file': args[1]},
features_only=True)
elif len(args) == 1:
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {fasternet_t0, fasternet_t1, fasternet_t2, fasternet_s, fasternet_m, fasternet_l
}:
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
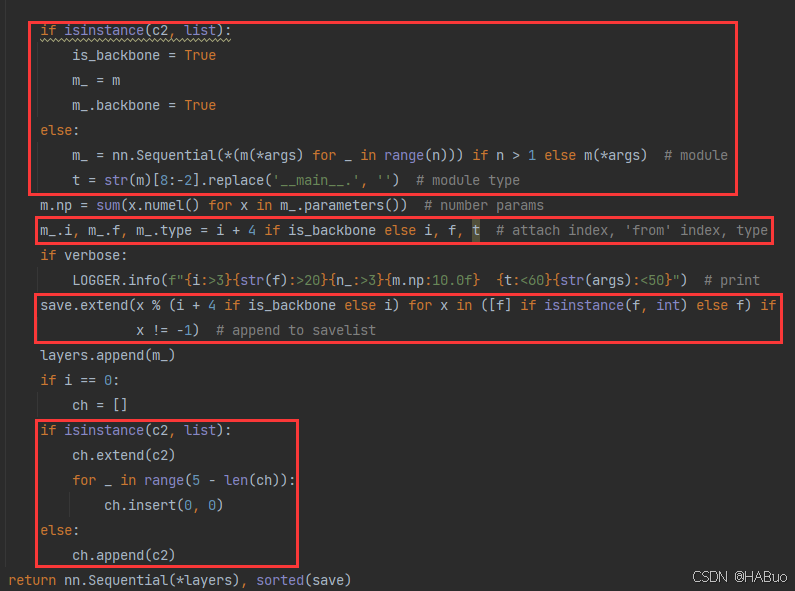
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if is_backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<60}{str(args):<50}") # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if
x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
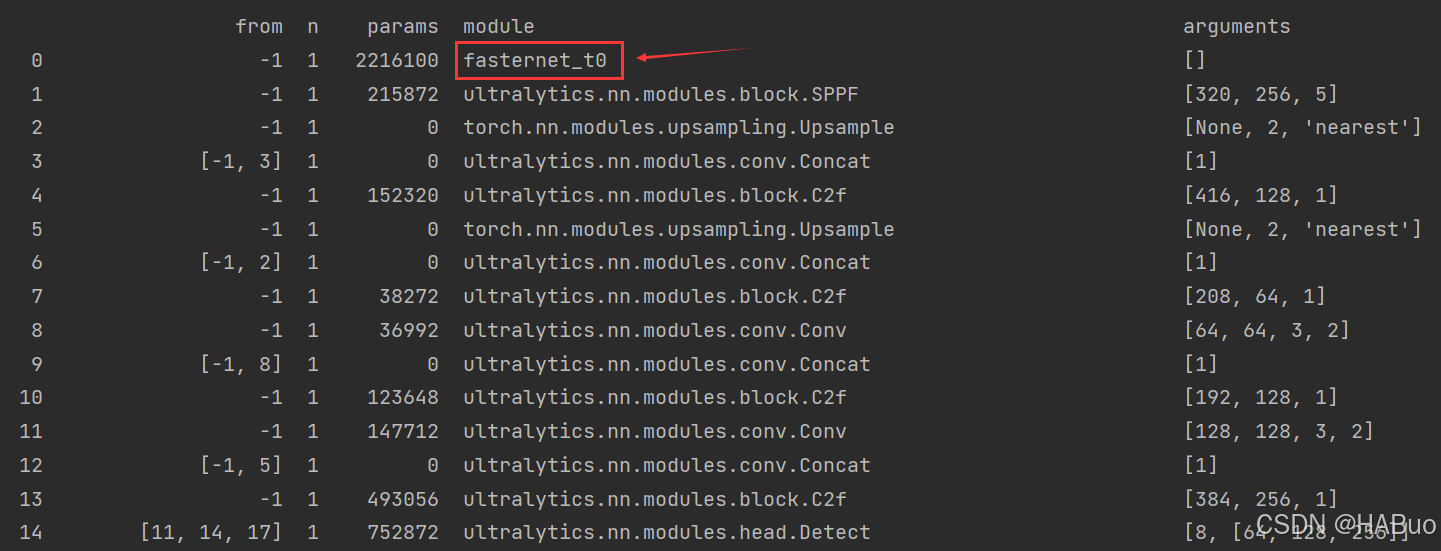
return nn.Sequential(*layers), sorted(save)具体改进差别如下图所示:
第③步:yolov8.yaml文件修改
在下述文件夹中创立yolov8-fasternet.yaml
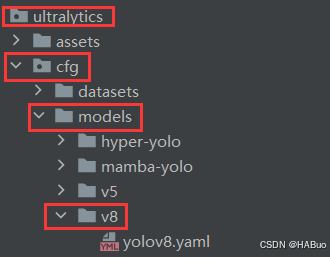
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, fasternet_t0, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
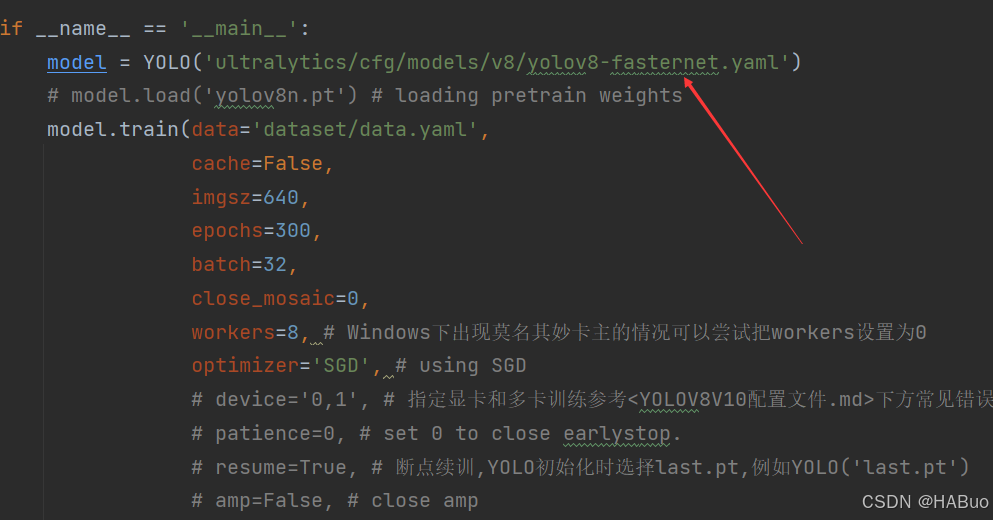
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)第④步:验证是否加入成功
将train.py中的配置文件进行修改,并运行
🏋不是每一粒种子都能开花,但播下种子就比荒芜的旷野强百倍🏋
🍁YOLOv8入门+改进专栏🍁
【YOLOv8改进系列】:
【YOLOv8】YOLOv8结构解读
YOLOv8改进系列(1)----替换主干网络之EfficientViT
YOLOv8改进系列(2)----替换主干网络之FasterNet
YOLOv8改进系列(3)----替换主干网络之ConvNeXt V2
YOLOv8改进系列(4)----替换C2f之FasterNet中的FasterBlock替换C2f中的Bottleneck
YOLOv8改进系列(5)----替换主干网络之EfficientFormerV2
YOLOv8改进系列(6)----替换主干网络之VanillaNet
YOLOv8改进系列(7)----替换主干网络之LSKNet
YOLOv8改进系列(8)----替换主干网络之Swin Transformer
YOLOv8改进系列(9)----替换主干网络之RepViT








