
本篇文章旨在记录Ubuntu24.04下基于Docker运行Dify+Ollama+Xinference部署本地大模型工程,仅供参考。 目录 一、概述 二、部署

本篇文章旨在记录Ubuntu24.04下基于Docker运行Dify+Ollama+Xinference部署本地大模型工程,仅供参考。 目录 一、概述 二、部署
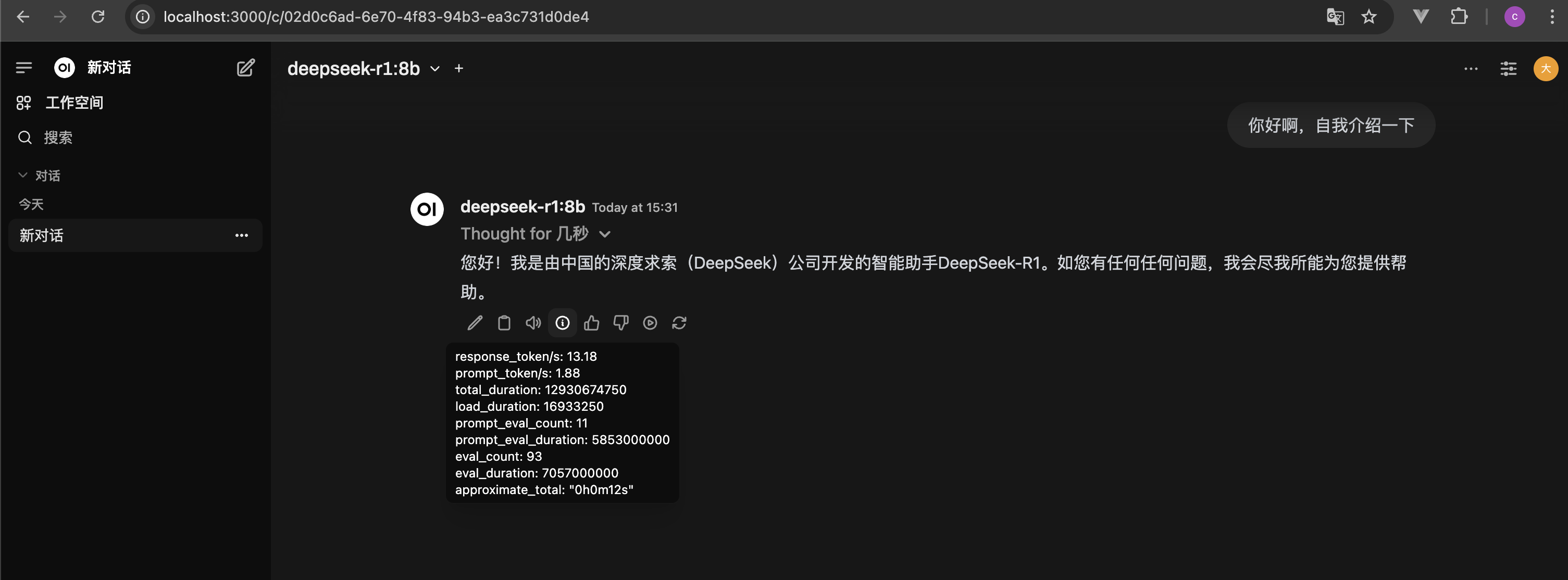
文章目录 前言电脑配置:安装的Deepseek版本:使用的UI框架:体验效果展示:本地部署体验总结 部署过程Ollama部署拉取模型
本篇文章旨在记录Ubuntu24.04下基于Docker运行Dify+Ollama+Xinference部署本地大模型工程,仅供参考。 目录 一、概述 二、部署
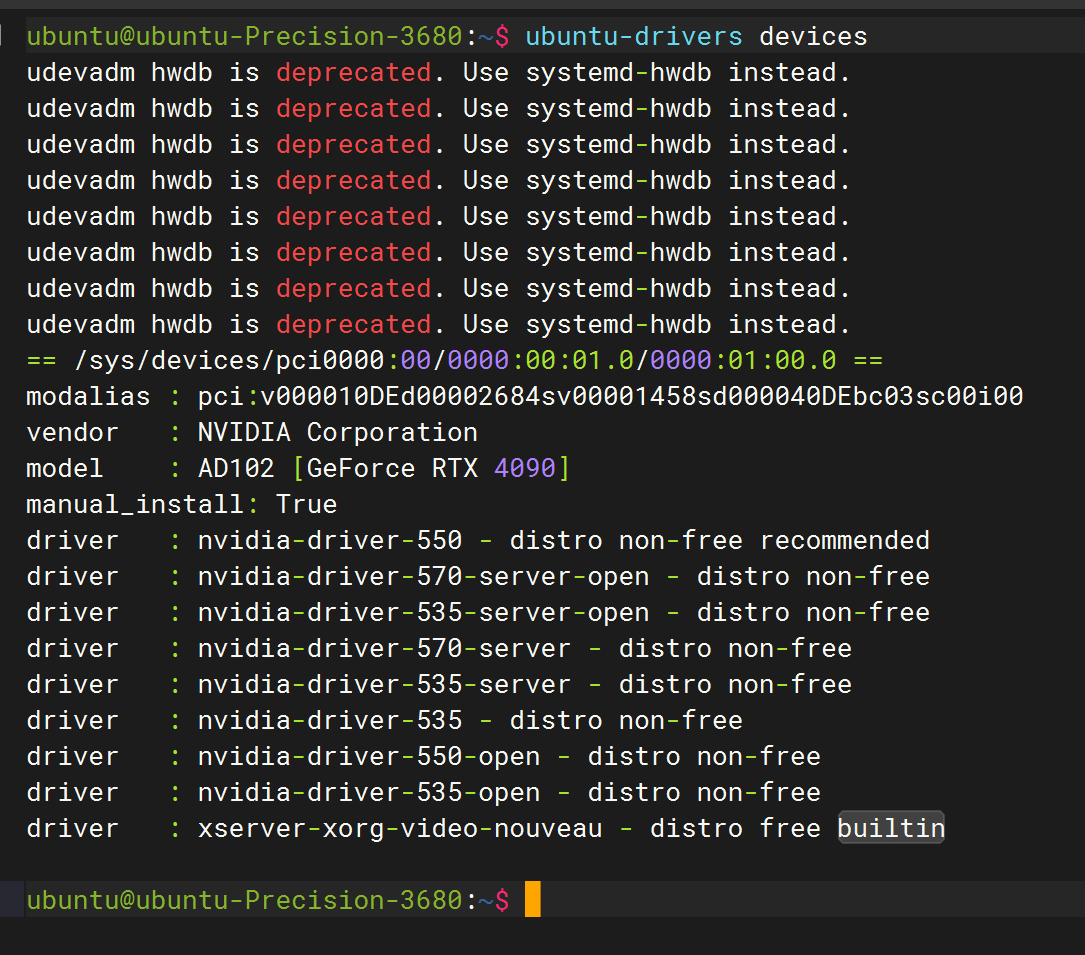
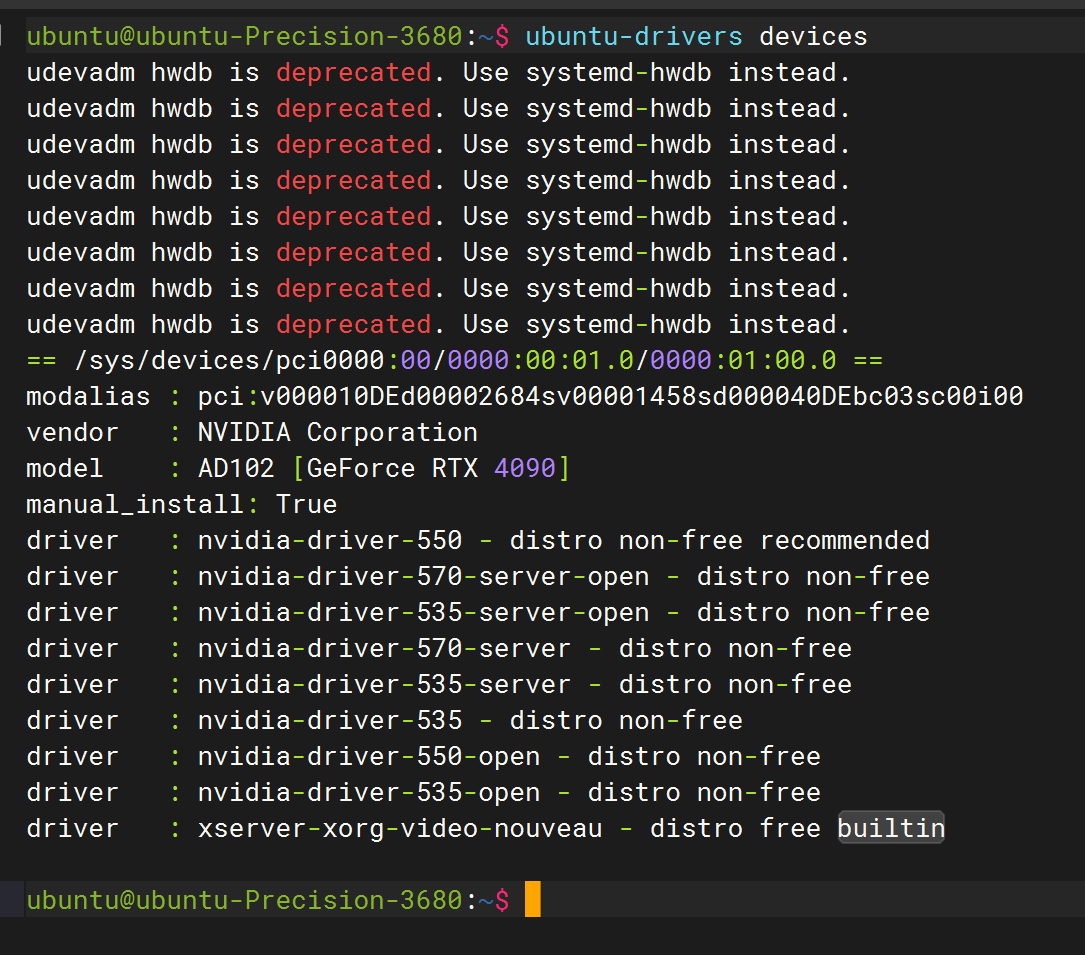
自己捣鼓玩玩哈,正好有机子 1. 安装驱动前的系统配置工作 卸载原有驱动并禁用nouveau sudo apt remove --purge nvidia*su
随着人工智能技术的飞速发展,本地部署大型语言模型(LLM)已成为许多技术爱好者的热门选择。本地部署不仅能够保护隐私,还能

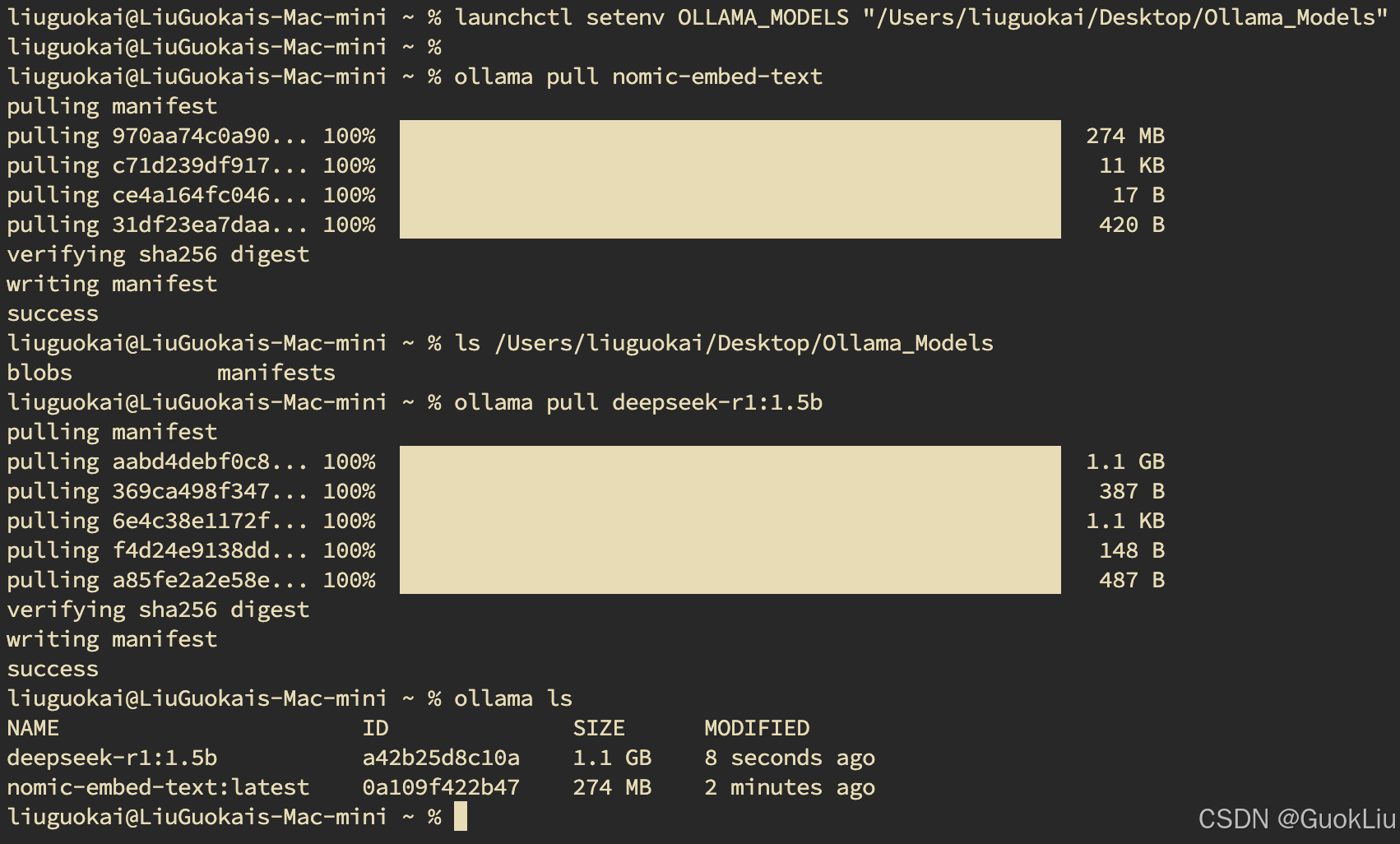
在 macOS 上,Ollama 默认将模型存储在 ~/.ollama/models 目录。如果您希望更改模型的存储路径,可以通过设置环境变量 OLLA
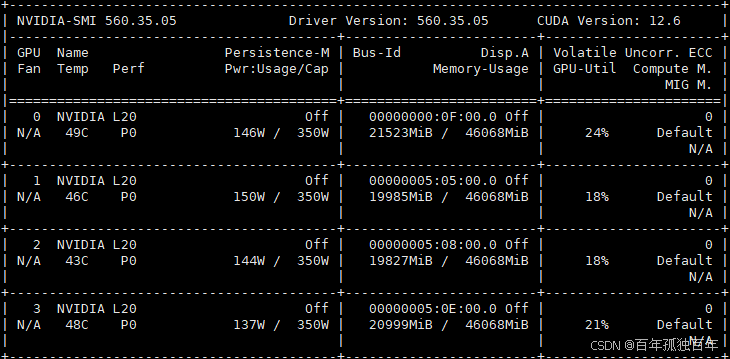
文章目录 省流结论机器配置不同量化模型占用显存1. 创建虚拟环境2. 创建测试jsonl文件3. 新建测试脚本3. 默认加载方式,单
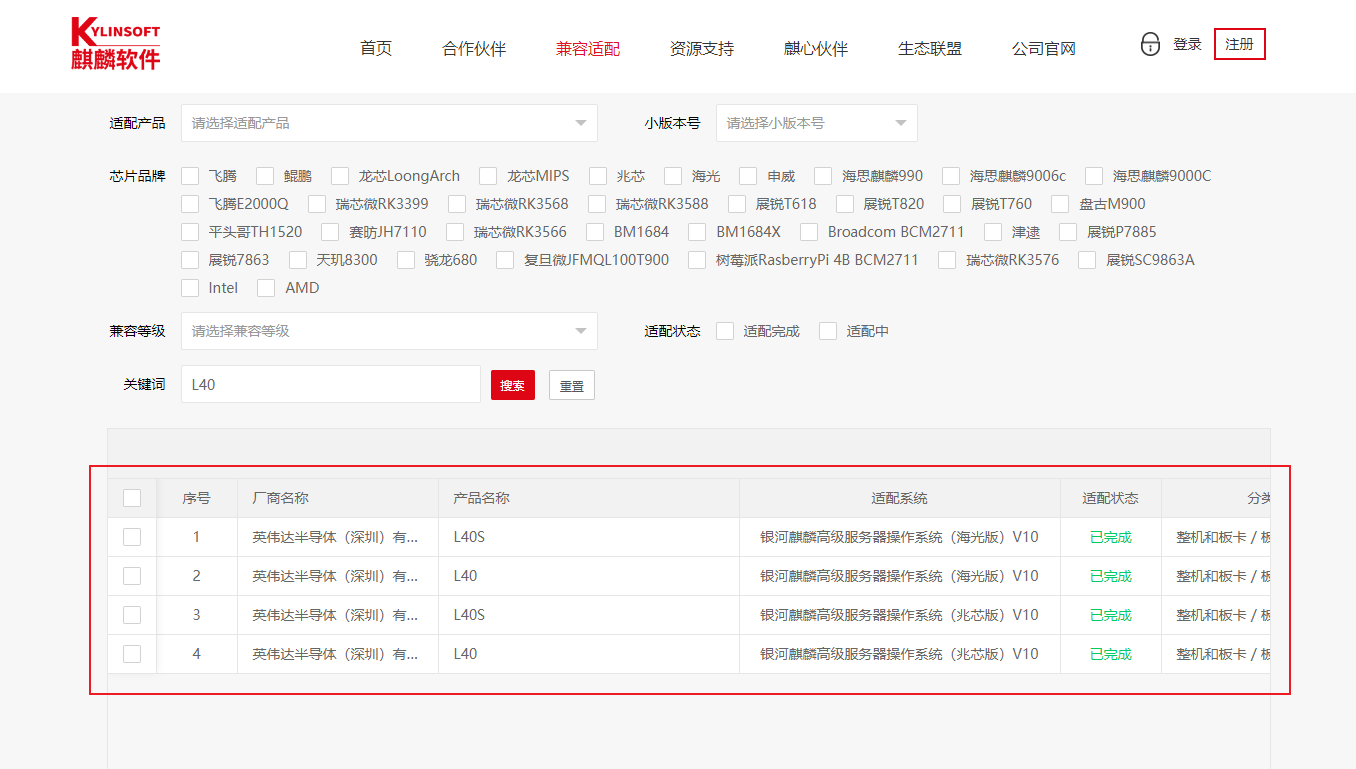
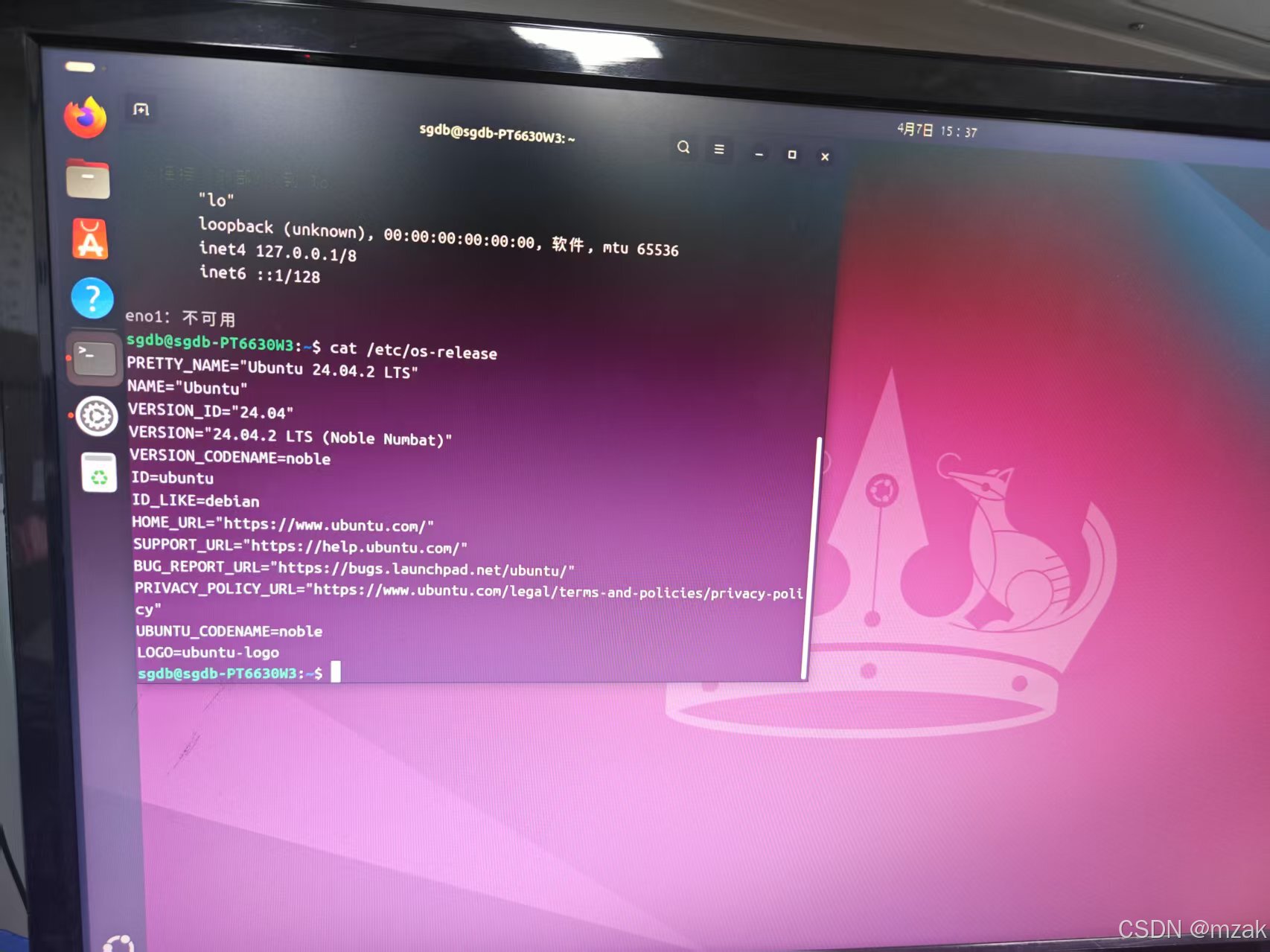
前期说明 麒麟官方适配列表查找没有L40,只有海光和兆芯适配麒麟V10,不适配Intel芯片 但是我在英伟达驱动列表查到是适配的
