
本文将介绍: 1.如何在Ubuntu server上安装ollama并运行deepseek-r1模型。(CPU运行) 2.如何在Ubuntu-server上安装nvidia驱


本文将介绍: 1.如何在Ubuntu server上安装ollama并运行deepseek-r1模型。(CPU运行) 2.如何在Ubuntu-server上安装nvidia驱

一、前言 目前,大语言模型已升级至Qwen2.5版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训
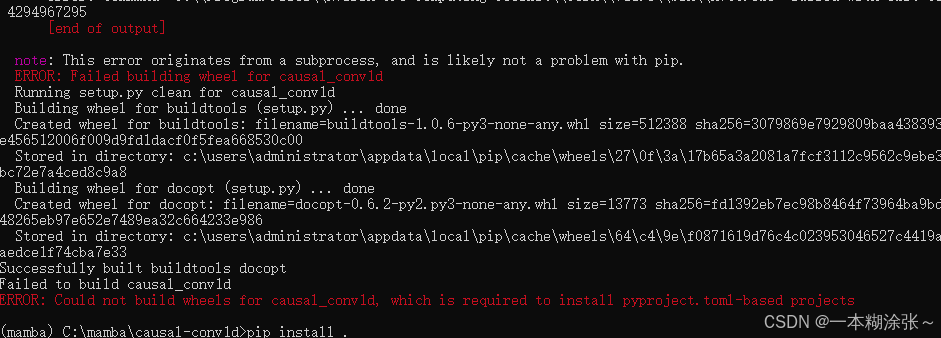
windows系统下安装mamba会遇到各种各样的问题。博主试了好几天,把能踩的坑都踩了,总结出了在windows下安装mamba的一套
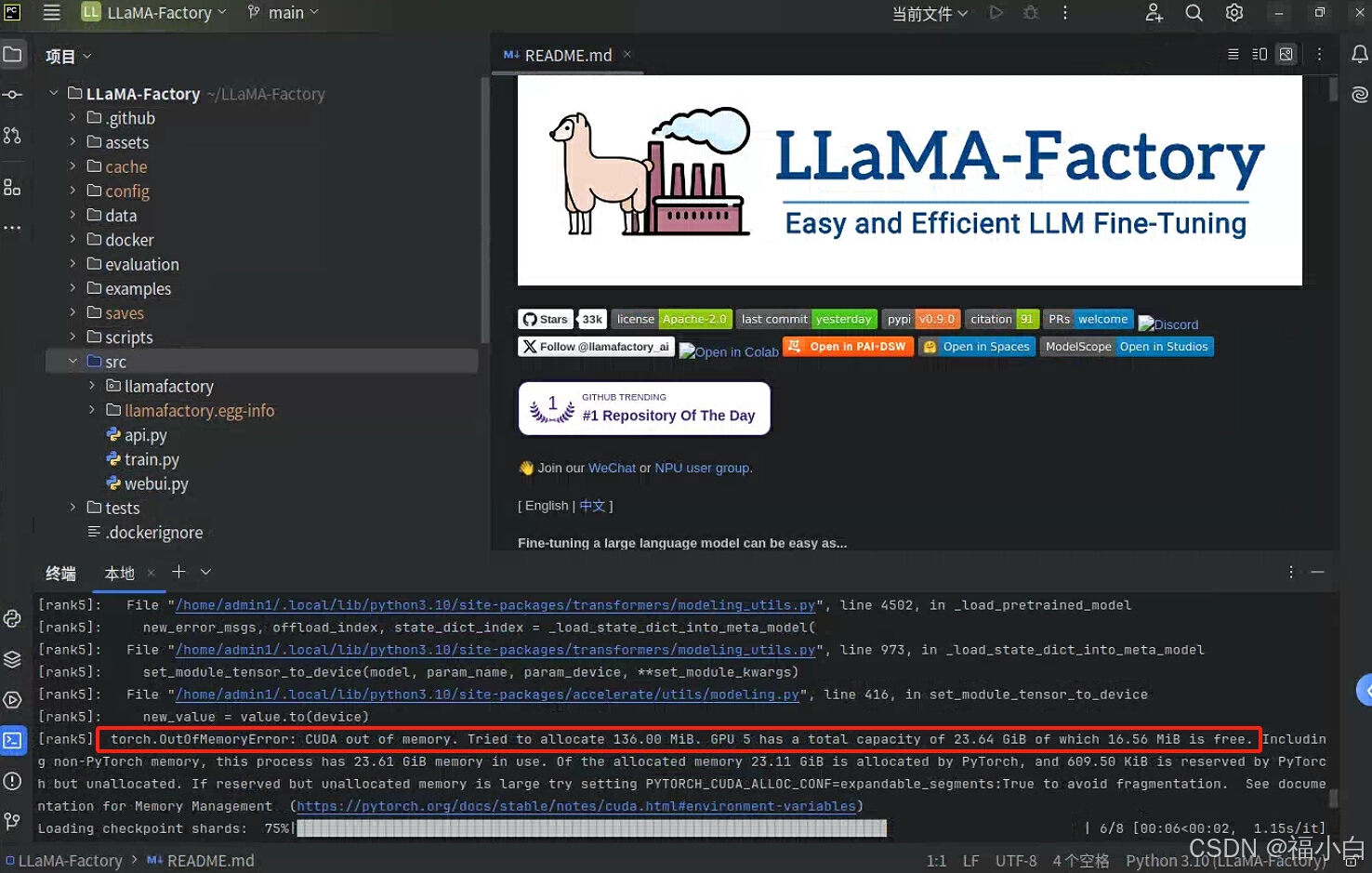
(llamafactory用多张4090卡,训练qwen14B大模型时oom(out of memory)报错,torch.OutOfMemoryError:CUDA out of memory,Trie

🎼个人主页:【Y小夜】 😎作者简介:一位双非学校的大三学生,编程爱好者, 专注于基础和实战分享,欢迎私信咨询


无论是想要学习人工智能当做主业营收,还是像我一样作为开发工程师但依然要了解这个颠覆开发的时代宠儿,都有必
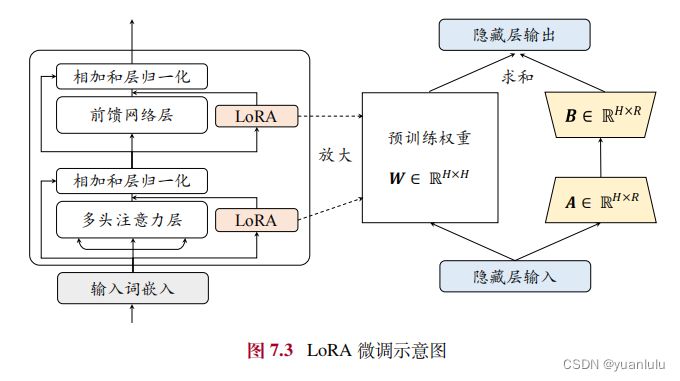
什么是lora微调 LoRA 提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练
教学视频链接6.租赁 GPU 服务器并微调 Llama-Factory 模型_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1NKNSeDEgt/
