linux文件管理
目录
原理
一 c语言接口
二 认识文件系统调用
三 访问文件的本质
四 重定向&&缓冲区
原理
1.文件=内容+属性
2.文件分为打开文件和未打开文件
3.打开的文件由进程打开--本质是研究进程和文件的关系
文件打开后属性一定加载到内存,他与进程1:n
操作系统内部存在在众多打开文件,管理方式为先描述,再组织,内核中,打开文件中必须包含自身的文件的打开对象,包含文件属性
4.没打开的文件在磁盘上,我们需要关注在众多没打开文件中,文件如何被分门别类的放置好--为进行增删查改快速找到文件。
一 c语言接口
源码
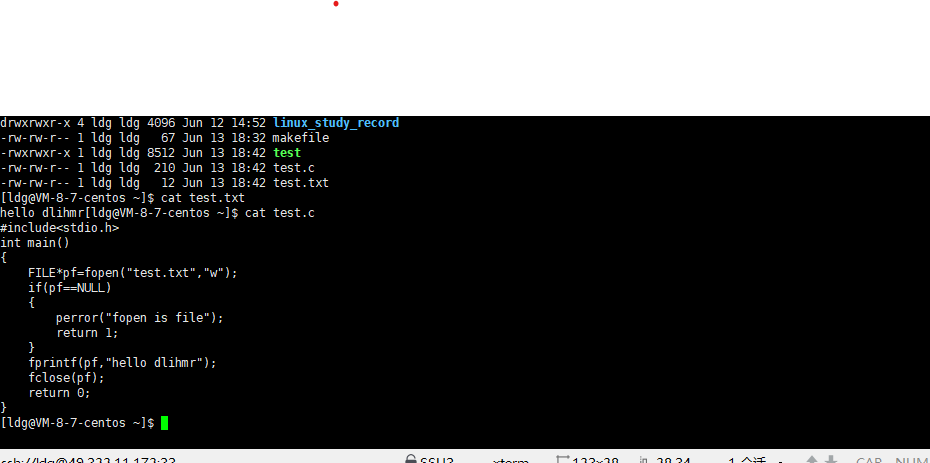
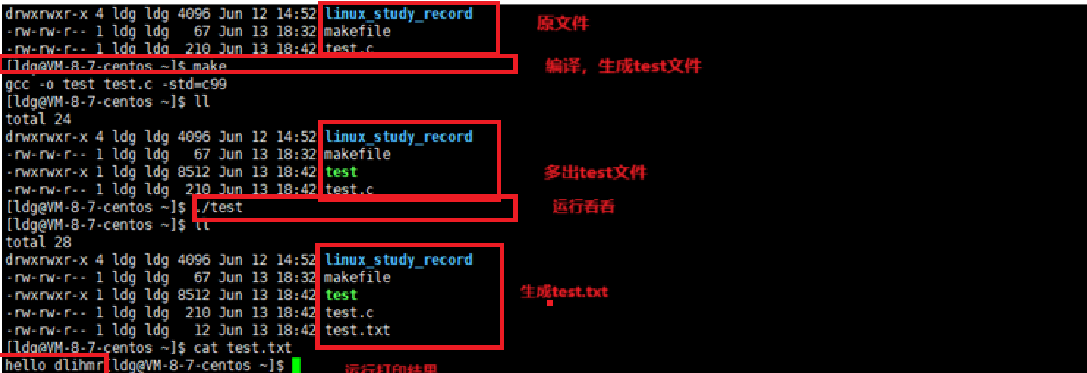
需要注意"w"是覆盖性写入,而"a"是追加型写入
fopen 是C语言中用于打开文件的标准库函数,功能是创建一个文件指针并关联指定文件,常见用法如下:
基本格式
FILE *fopen(const char *filename, const char *mode);
- filename :要打开的文件名(可含路径)
路径及CWD,有觉得路径相对路径两种,const char *filename,我们可以给完整路径(/home/ldg)或者给出文件名(test.c),进程会在他运行得当前路径为我们生成文件。
- mode :文件打开模式(如 "r" 读、 "w" 写、 "a" 追加等)
常用模式及说明
- 读操作:
- "r" :打开文本文件用于读取,文件需存在
- "rb" :以二进制模式读取
- 写操作:
- "w" :创建新文件写入,若文件存在则覆盖
- "wb" :二进制模式写入
- "a" :追加内容到文件末尾,文件不存在则创建
- 读写操作:
- "r+" :可读可写,文件需存在
- "w+" :创建新文件,可读可写(覆盖原文件)
返回值
- 成功时返回指向 FILE 结构体的指针
- 失败时返回 NULL (需用 perror 等函数查看错误原因)
注意事项
- 打开文件后必须用 fclose 关闭,避免资源泄漏
- 二进制模式需加 b (如 "rb" ),跨平台更安全
- 处理中文路径时需注意编码问题(Windows下常用GBK)
C常见文件操作接口
//1. 打开与关闭文件
- fopen() :打开文件并返回文件指针
FILE *fp = fopen("file.txt", "r"); // 以只读模式打开文本文件
- fclose() :关闭文件并释放资源
fclose(fp); // 关闭文件指针fp
//2. 字符级读写
- fgetc() :从文件读取单个字符
int ch = fgetc(fp); // 读取一个字符,返回EOF表示读取失败
- fputc() :向文件写入单个字符
fputc('A', fp); // 向文件写入字符'A'
//3. 行级读写
- fgets() :读取一行字符串(含换行符)
char buf[100];
fgets(buf, 99, fp); // 读取最多99个字符到buf
- fputs() :写入字符串(不包含末尾'�')
fputs("hello", fp); // 向文件写入"hello"
//4. 格式化读写
- fscanf() :按格式从文件读取数据
int num;
fscanf(fp, "%d", &num); // 从文件读取整数
- fprintf() :按格式向文件写入数据
fprintf(fp, "num = %d", 100); // 写入格式化字符串
//5. 块读写(二进制文件)
- fread() :读取二进制数据块
struct Data data;
fread(&data, sizeof(data), 1, fp); // 读取一个结构体
- fwrite() :写入二进制数据块
fwrite(&data, sizeof(data), 1, fp); // 写入一个结构体
//6. 文件定位
- fseek() :移动文件指针到指定位置
fseek(fp, 0, SEEK_SET); // 移动到文件开头(第二个参数:SEEK_SET=开头,SEEK_CUR=当前,SEEK_END=结尾)
- ftell() :获取当前文件指针位置
long pos = ftell(fp); // 返回当前偏移量(字节数)
- rewind() :重置文件指针到开头
rewind(fp); // 等价于fseek(fp, 0, SEEK_SET)
//7. 状态检查
- feof() :检查是否到达文件末尾
if (feof(fp)) printf("已到文件末尾");
- ferror() :检查文件操作是否出错
if (ferror(fp)) perror("文件操作错误");
- clearerr() :清除错误和EOF标志
clearerr(fp); // 重置错误状态
//8. 其他工具函数
- remove() :删除文件
remove("old.txt"); // 删除文件old.txt
- rename() :重命名文件
rename("old.txt", "new.txt"); // 重命名文件
//二进制文件操作需使用 "rb" / "wb" 模式(如 fopen("img.bin", "rb") )。
//- 操作文件前需检查指针是否为 NULL ,避免空指针错误。
//- 频繁读写时可配合 fflush() 刷新缓冲区(如 fflush(fp) 强制写入)。
二 认识文件系统调用
Linux下一位皆是文件
c语言默认启动会打开三个标准输入输出流(文件)
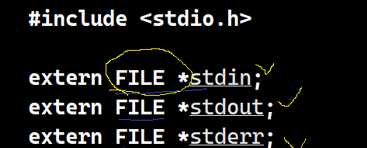
stdin(键盘文件) stdout stderr(显示器文件)
我们所说的文件其实存放在磁盘,访问文件其实就是访问磁盘,是外设硬件
用户不能直接访问硬件,需要借助操作系统内部帮助(几乎所以得库只要是访问硬件设备,必须要封装系统调用!!)
介绍接口open
在Linux系统中, open 是用于文件操作的系统调用接口,属于POSIX标准,相比C语言标准库的 fopen 更底层,直接操作文件描述符。以下是其核心用法和解析:
1. 函数原型与头文件
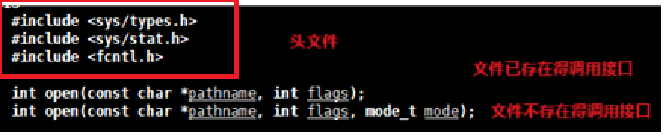
- 参数说明:
- pathname :文件路径(绝对路径或相对路径)。
- flags :打开文件的标志(必选,可通过 | 组合多个标志)。
- mode :创建文件时的权限(仅当使用 O_CREAT 标志时有效)。
2. 常用flags标志
基础打开模式(必选其一)
- O_RDONLY :只读模式(返回文件描述符为可读)。
- O_WRONLY :只写模式。
- O_RDWR :读写模式。
扩展标志(可组合使用)
- O_CREAT :若文件不存在则创建(需配合 mode 参数)。
- O_APPEND :追加写入(每次写入从文件末尾开始)。
- O_TRUNC :若文件已存在,清空文件内容。
- O_EXCL :与 O_CREAT 配合使用时,若文件已存在则打开失败。
- O_NONBLOCK :非阻塞模式(适用于设备文件,如管道、套接字)。
3. mode参数(文件权限)
当使用 O_CREAT 时,需指定文件权限,通常用八进制表示:
- 示例: 0666 (所有者、组、其他用户均可读可写)。
- 实际权限会受当前进程的umask影响(如 umask 002 时,最终权限为 0666 & ~002 = 0664 )。
可以通过umask接口修改umask值
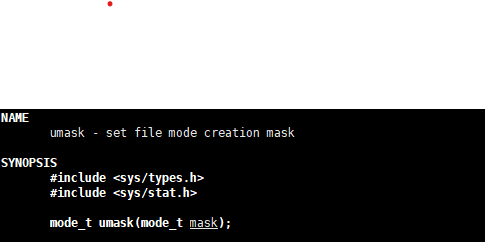
4. 返回值与错误处理
- 成功:返回文件描述符(非负整数,默认最小可用值,如 3 ,标准输入/输出/错误占用 0/1/2 )。
- 失败:返回 -1 ,可通过 errno 变量或 perror() 查看错误原因(如 ENOENT 文件不存在、 EACCES 权限拒绝)。
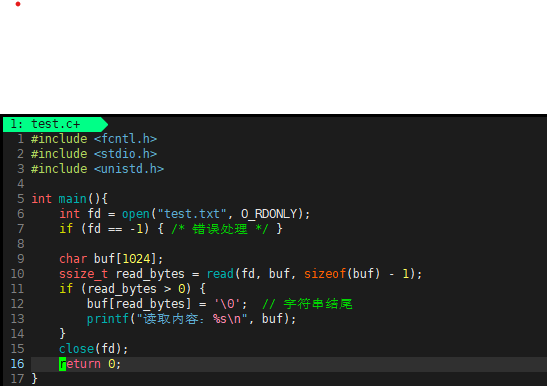
5. 核心操作示例
打开文件并写入
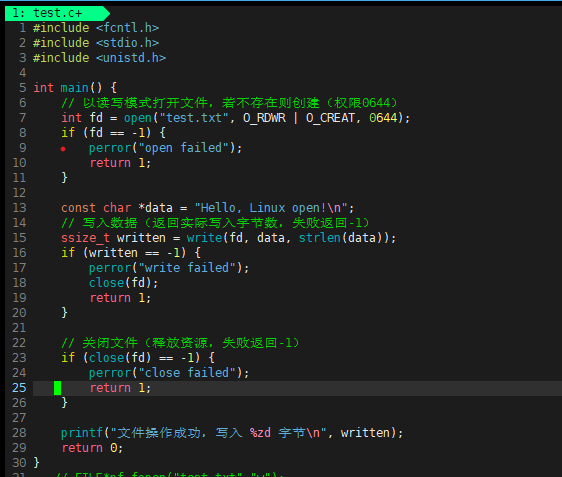
读取文件内容
6. 与fopen的区别
| 特性 | open (系统调用) | fopen (C标准库) |
| 接口层级 | 底层(直接操作文件描述符) | 高层(封装文件流指针) |
| 返回值 | 文件描述符(int类型) | FILE* 指针 |
| 缓冲机制 | 无标准缓冲(需手动管理) | 自带缓冲(提升I/O效率) |
| 跨平台性 | Linux/UNIX专用 跨平台 | (Windows/Linux等) |
| 错误处理 | 通过 errno 或 perror() | 通过返回值和 ferror() 等 |
7. 其他相关系统调用
- close() :关闭文件描述符
close(fd); // 成功返回0,失败返回-1- lseek() :文件指针定位
off_t new_pos = lseek(fd, 0, SEEK_END); // 移动到文件末尾- read() / write() :读写数据
ssize_t n = read(fd, buf, size); // 读取size字节到buf- fcntl() :文件描述符控制(如设置非阻塞、获取/修改标志)
注意事项
- 文件描述符是进程级资源,不同进程可通过相同描述符操作文件。
- 二进制文件无需特殊标志(如 O_BINARY ),Linux系统不区分文本/二进制文件。
- 多线程环境中需注意文件描述符的线程安全(如共享描述符时加锁)。
三 访问文件的本质
一、文件描述符表的本质与作用
- 文件描述符(File Descriptor):是进程访问文件的唯一标识符,通常为非负整数(如0、1、2等)。
- 文件描述符表:每个进程都有独立的文件描述符表,表中存储了进程当前打开的所有文件的映射关系,每个表项对应一个文件描述符,指向内核中的“文件表项”。
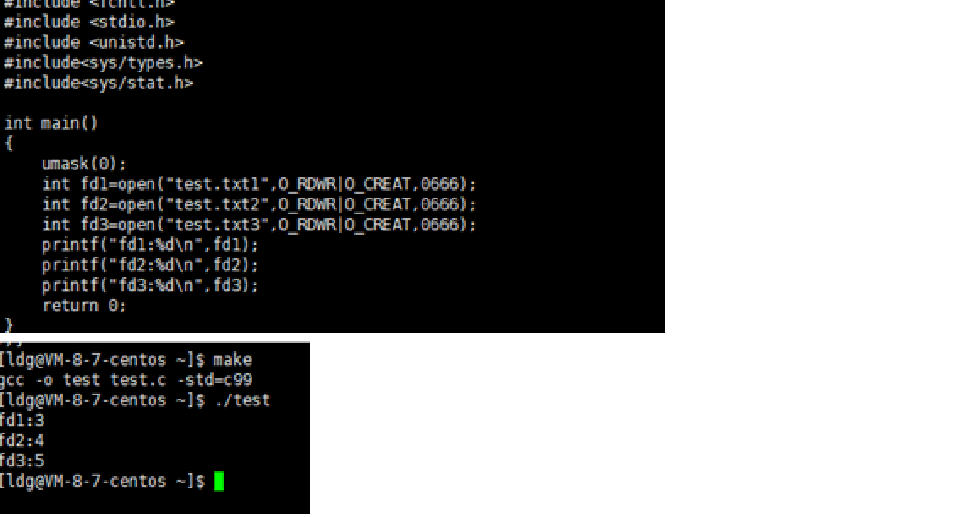
二、访问磁盘文件的核心流程
1. 打开文件时的映射建立
- 进程调用 open() 函数打开磁盘文件时,内核会:
- 分配一个空闲的文件描述符(通常从最小未使用的整数开始,如3)。
从三开始的原因:stdin,stdout,stderr的占位(进程初始化阶段完成)
- 创建“文件表项”,记录文件的当前偏移量、打开模式(读/写/追加等)、文件状态标志等信息。
- 将文件描述符与文件表项绑定,存入进程的文件描述符表。
2. 通过文件描述符操作文件
- 进程调用 read() 、 write() 等函数时,只需传入文件描述符:
- 内核根据文件描述符查找进程的文件描述符表,定位到对应的文件表项。
- 通过文件表项找到文件的“索引节点(Inode)”指针,Inode中存储了文件在磁盘上的物理位置、权限、类型等元数据。
- 根据Inode信息访问磁盘物理块,完成读写操作。
3. 关闭文件时的资源释放
- 进程调用 close() 函数时,内核会:
- 从文件描述符表中删除对应表项,释放文件描述符。
- 减少文件表项的引用计数,若计数为0,则释放文件表项及相关资源(如内存缓冲区)。
三、关键数据结构与内核层交互
- 三层数据结构关联:
进程文件描述符表 → 文件表项 → 索引节点(Inode)→ 磁盘物理块
- 文件表项:由内核维护,多个进程可通过不同文件描述符指向同一文件表项(如父子进程共享文件)。
- Inode:每个文件唯一对应一个Inode,存储文件的物理地址映射(如块号数组)。
- 缓冲区的作用:
内核为文件操作设置缓冲区(如页缓存),读写操作先在内存缓冲区中完成,再由内核异步刷新到磁盘,提升I/O效率。
四、举个简单例子辅助理解
- 假设进程用 open("/data/file.txt", O_RDONLY) 打开文件:
1. 内核分配文件描述符 fd=3 ,创建文件表项(记录偏移量0、读模式)。
2. 进程调用 read(fd, buf, 100) 时,内核通过 fd=3 找到文件表项,根据Inode找到文件在磁盘的位置,从偏移量0读取100字节到 buf 。
3. 读取后文件表项的偏移量更新为100,下次读取从该位置开始。
五、总结核心逻辑
文件描述符表是进程访问文件的“索引工具”,通过它将用户空间的描述符映射到内核空间的文件控制结构,最终实现对磁盘文件的物理访问。这一机制确保了进程对文件的安全管理和高效操作。
四 重定向&&缓冲区
重定向
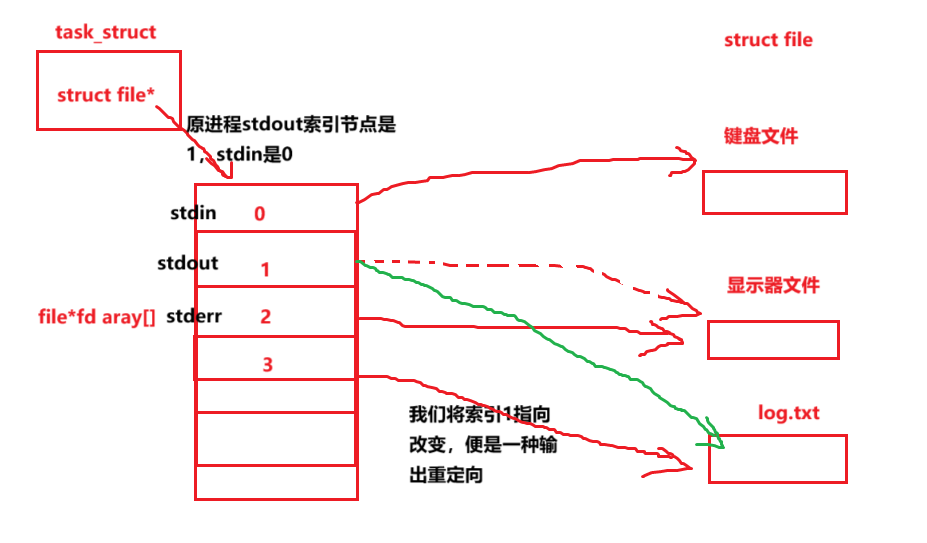
代码示例 (传统示例)
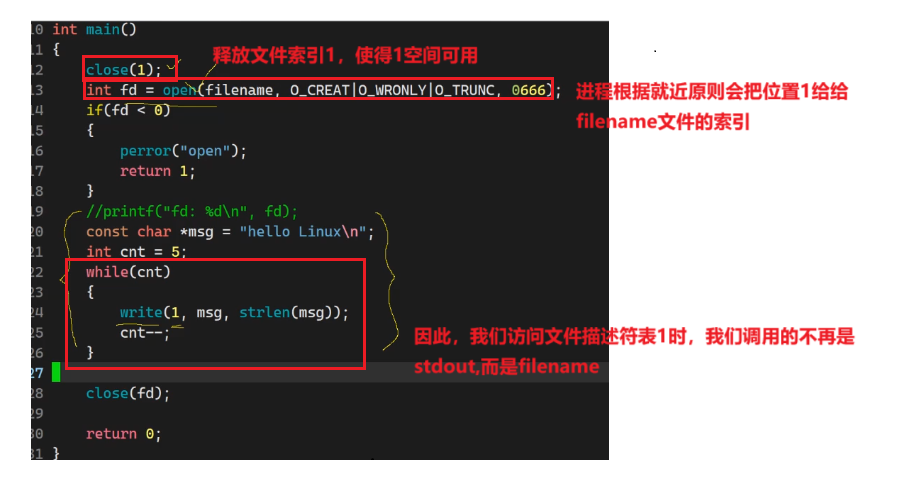
代码示例 (现代示例)
函数介绍dup
在Linux系统中, dup2() 是一个系统调用函数,用于复制文件描述符,其函数原型为:
#include
int dup2(int oldfd, int newfd); 下面详细介绍它的功能、参数及使用场景:
功能
dup2() 的主要作用是将 oldfd (旧文件描述符)复制到 newfd (新文件描述符)。如果 newfd 已经打开, dup2() 会先关闭 newfd ,然后再执行复制操作,使得 newfd 和 oldfd 指向同一个文件、管道或者其他I/O资源,即它们共享相同的文件表项 ,共享文件偏移量和文件状态标志等信息。
参数
- oldfd :需要被复制的旧文件描述符,它必须是一个有效的、已经打开的文件描述符。
- newfd :指定要复制到的目标文件描述符。如果 newfd 的值等于 oldfd ,那么 dup2() 直接返回 newfd ,不执行任何复制操作;否则, newfd 会被设置为与 oldfd 相同的状态,指向相同的文件或资源。
返回值
- 成功时, dup2() 返回 newfd ,它和 oldfd 一样,都可以用来对目标文件或资源进行读写等操作。
- 失败时,返回 -1 ,并且会设置相应的 errno 错误码,常见的错误码如 EBADF ( oldfd 不是有效的文件描述符 或 newfd 是一个无效的文件描述符) 、 EMFILE (进程已达到其打开文件描述符的最大数量限制 )等。
常见使用场景
- 重定向标准输入输出:在编写程序时,想要改变程序的标准输入或输出方向。比如,将标准输出重定向到一个文件中,示例代码如下:
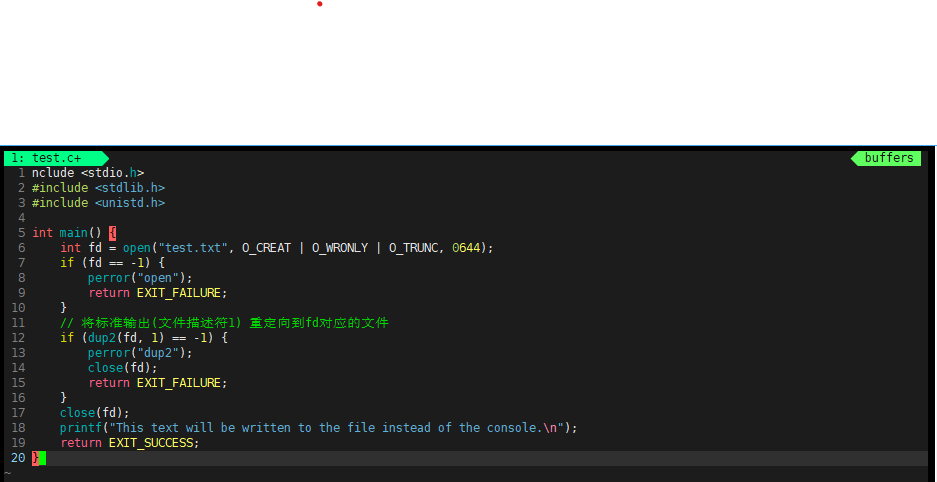
在这个例子中,程序打开一个文件,然后使用 dup2() 将标准输出文件描述符(值为1)复制为打开文件的文件描述符,之后 printf 函数输出的内容就会写入到打开的文件中,而不是打印到终端。
- 在进程间通信中复用文件描述符:当一个进程创建了管道或其他类型的I/O资源,需要子进程继承并使用时,可以通过 dup2() 来复制文件描述符,确保子进程能够正确访问和操作这些资源。
为什么会有两个显示器文件?(stdout,stderr)
在Linux系统中,进程并非直接对应“两个显示器文件”,而是通过文件描述符(File Descriptor) 管理输入输出。其中与终端显示相关的主要是标准输入(STDIN,文件描述符0)、标准输出(STDOUT,文件描述符1)和标准错误(STDERR,文件描述符2)。
为什么标准输出和标准错误要分开?
1. 功能分离:
- 标准输出(STDOUT):用于程序正常运行时的输出(如打印结果、日志),通常指向终端屏幕或文件。
- 标准错误(STDERR):专门用于输出程序运行中的错误信息(如异常、警告),即使标准输出被重定向(如输出到文件),错误信息也能直接显示在终端,避免被忽略。
2. 灵活性:
分开后可独立控制输出流向,例如:
- command > output.txt 2>&1 :将标准输出和错误都重定向到文件。
- command 2> error.txt :仅记录错误,正常输出仍显示在终端。
本质:文件描述符的设计哲学
Linux将所有设备视为文件,进程通过文件描述符操作输入输出。这种设计让进程能统一处理终端、文件、网络等不同设备,而标准输出和错误的分离,本质是为了区分“正常输出”和“异常信息”,提升调试和日志管理的效率。
./mytest 1>all.log 2>err.log这是 Linux 系统中的命令行操作,用于执行 ./mytest.o 程序并重定向输出:
- 1>all.log :将程序的标准输出(正常运行的输出内容)重定向到 all.log 文件中,会覆盖文件原有内容。
- 2>err.log :将程序的标准错误输出(运行错误或异常信息)重定向到 err.log 文件中,同样会覆盖原有内容。
这样操作后,程序的正常输出和错误信息会被分别记录到不同文件,方便后续查看和调试。如果希望追加内容而非覆盖,可将 > 改为 >> 。
缓冲区
缓冲区刷新问题方式
1.无缓冲--直接刷新
2.行缓冲--不刷新直到遇到 --显示器
3.全缓冲--缓冲区满了,才刷新--文件写入
进程退出也会刷新
缓冲区解决用户效率问题的同时配合格式化,他位于FILE->FD。
C语言中缓冲区的 FILE 对象属于用户,对应的缓冲区是用户级缓冲区。
FILE 结构体是由C标准库定义和维护的,其中封装了文件描述符等信息,还包含对应打开文件的缓冲区字段和维护信息。当使用 fopen 等函数打开文件时,会在用户空间中为该文件分配一个 FILE 对象以及相应的缓冲区。
C库函数如 printf 、 fwrite 等会自带缓冲区,而这些函数是在系统调用的上层,是对系统调用的封装。数据会先写入C语言层面的缓冲区,再根据一定的刷新策略调用系统调用 write 将数据写入到操作系统内核缓冲区。所以,C语言的缓冲区是用户级缓冲区,它在用户空间中,用于暂存数据,以提高文件读写的效率。

这段代码不会有显示,
原因就在于,C语言将数据加载到用户级内存区,之后直接关闭内核中的缓冲区,导致return时用户级缓冲区数据无法刷新到内核缓冲区,进而是的数据无法呈现在显示器上
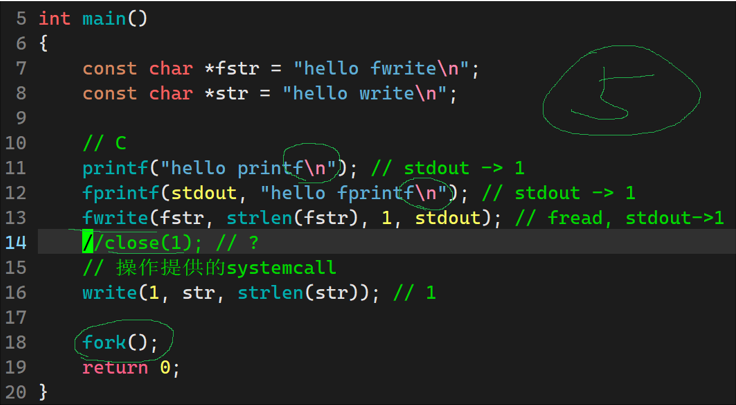
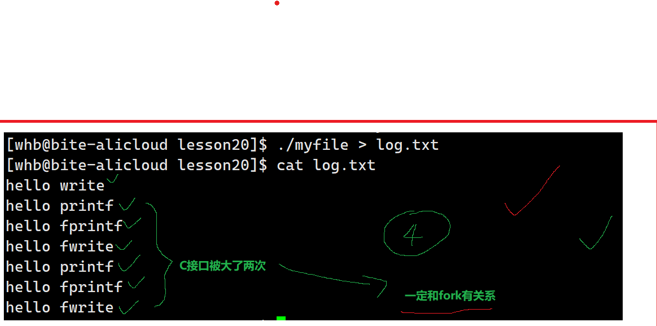
上述这段代码则输出了七行,同时"hello write"本应该出现在末尾,却出现在首行;
现象分析:
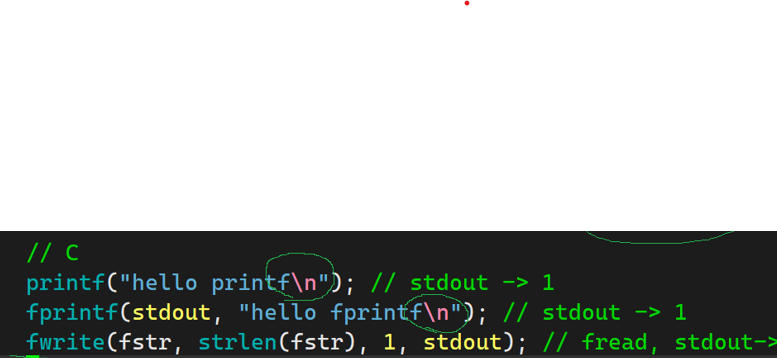
这写代码被加载进用户级缓冲区,因为没有return刷新缓存区,因此不会直接刷新内容在显示器上,

由于write是直接刷新到内核缓冲区中,因内核与外设效率差异,会优先输出 "hello write"
之后fork创建子进程,实现数据拷贝,那么子进程中变也会有相同代码,缓冲区没输出的数据中自然也会被拷贝
return刷新时刷新缓冲区,1(write)+3(父进程C缓冲区)+3 (子进程缓存区)=7
inode和软硬连接
未打开的文件存放在磁盘中,
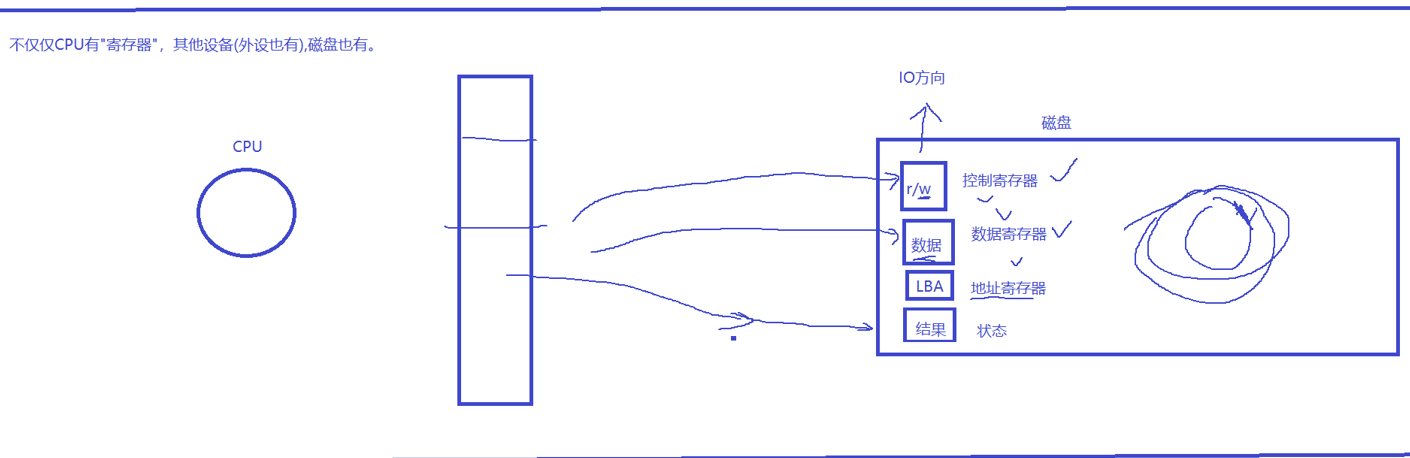
磁盘的物理划分:柱面、扇面、磁道
- 柱面:由于机械硬盘存在多个盘片,不同盘片上相同编号的磁道垂直对齐,这些磁道组成的圆柱面被称为柱面。在进行数据读写时,优先在一个柱面内进行操作,这样可以减少磁头的移动距离,提高读写效率 。
- 扇面:磁道进一步被划分成若干个弧段,这些弧段就是扇区(也可以理解为扇面的一部分) 。扇区是磁盘进行数据读写的基本单位,通常大小为512字节或4096字节等。每个扇区都有唯一的地址标识,以便磁头能够准确找到需要读写的位置 。
- 磁道:在机械硬盘中,盘片在电机驱动下高速旋转,磁头在盘片表面径向移动,磁头在盘片上留下的轨迹就是磁道 。磁道是一个个同心圆环,从盘片的最外侧到最内侧分布,不同的磁道编号不同,用于标识数据存储的位置 。
分区与块组划分
- 磁盘会先进行分区(如 MBR/GPT 分区),每个分区可独立格式化。格式化时,文件系统(如 EXT4 )把分区空间切分成多个Block group(块组) ,就像图片里的 Block group 0 、 Block group n 。
- 这么做是为了分散元数据(管理数据的数据),降低故障影响,还能提升读写效率(磁头不用跨大区域找数据)。每个块组逻辑上对应磁盘物理空间的一段,背后映射着若干磁道、扇区的物理存储区域。
磁道线性划分存取文件,其文件属性存入inode,代码数据则存入DAte blocks;

每一个block group又划分为

- Boot Block(引导块):位于磁盘分区的起始位置,用于存储引导程序,负责在计算机启动时加载操作系统内核。只有一个活动分区中的引导块会被BIOS调用,用于启动系统 。
- Block group(块组):磁盘被划分为多个块组,每个块组都包含了文件系统的部分元数据和数据块。这么做是为了提高文件系统的可靠性和性能,例如在某个块组损坏时,其他块组的数据仍可正常访问 。
- Super Block(超级块):记录了文件系统的整体信息,比如文件系统的类型、大小、块大小、inode总数等。在文件系统挂载时,超级块会被读取到内存中,内核通过它来管理文件系统 。
- Group Descriptor Table(组描述符表):记录当前块组的属性(比如块组内 Block Bitmap 、 inode Bitmap 、 inode Table 、 Data blocks 的起始位置 )。它把块组内的逻辑区域,和物理磁道扇区的实际存储位置关联起来,让文件系统知道去哪儿找管理数据和真实文件内容。
- Block Bitmap(块位图):是一个二进制映射表,其中每一位对应一个数据块,用来标识该数据块是否被占用。例如,某位为0表示对应的数据块空闲,为1则表示已被占用 。
- inode Bitmap(inode位图):与块位图类似,也是二进制映射表,每一位对应一个inode,用于标记inode是否被使用。inode是存储文件元数据(如文件权限、所有者、大小、创建时间等)的地方,除了数据内容,文件的其他信息基本都保存在inode中 。
- inode Table(inode表
(单个文件所有属性)):存储了文件系统中所有inode的属性(无文件名称)。通过inode编号可以快速定位到对应的inode,进而获取文件的元数据 。
- Data blocks(数据块):实际存储文件内容的区域,以块为单位进行分配。文件的数据会被分散存储在不同的数据块中,文件系统通过inode中的信息来记录这些数据块的位置 。
4. 总结:从磁道到文件系统结构的转化逻辑
简单说,磁道扇区是物理基础,文件系统格式化时,把磁盘分区切分成块组,再在块组内用超级块、组描述符表、位图、inode 表等,把物理磁道扇区的“原始存储”,转化为逻辑可管理的元数据和数据块 。这样,系统不用直接操作复杂的磁道扇区,而是通过文件系统的逻辑结构( inode 、数据块 ),就能高效存、取、管理文件,把底层物理存储“翻译”成用户/程序能理解的文件形式。
本质上,就是把硬件层面“磁道扇区的物理分布”,包装成软件层面“文件系统的逻辑组织”,让数据存储更有序、更易用 。