Ubuntu-22.04基于docker安装部署的K8s集群(版本1.30.1)
基础环境
| 主机名 | 配置 | 角色 | 系统版本 | IP | 安装的组件 |
|---|---|---|---|---|---|
| k8s-master | 4核8G | master | Ubuntu22.04 | 172.18.10.70 | apiserver、controller-manager、scheduler、kubelet、etcd、kube-proxy、calico、chrony |
| k8s-node1 | 4核8G | worker | Ubuntu22.04 | 172.18.10.71 | Kube-proxy、 calicocoredns、kubelet、chrony |
| k8s-node2 | 4核8G | worker | Ubuntu22.04 | 172.18.10.72 | Kube-proxy、 calicocoredns、kubelet、chrony |
系统初始化配置
配置本地解析
集群内主机都需要执行
$ cat >> /etc/hosts << EOF
172.18.10.70 k8s-master
172.18.10.71 k8s-node1
172.18.10.72 k8s-node2
EOF关闭系统的交换分区swap
集群内主机都需要执行
sed -ri 's/^([^#].*swap.*)$/#/' /etc/fstab && grep swap /etc/fstab && swapoff -a && free -h时间同步 在所有节点上安装chrony
apt install -y chrony在master节点上配置/etc/chrony/chrony.conf
#这是原有的ntp 我这里是注释了 使用下边的阿里云的ntp服务
#pool ntp.ubuntu.com iburst maxsources 4
#pool 0.ubuntu.pool.ntp.org iburst maxsources 1
#pool 1.ubuntu.pool.ntp.org iburst maxsources 1
#pool 2.ubuntu.pool.ntp.org iburst maxsources 2
#自己添加的阿里云的ntp
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
#定义要和master同步时间的 node IP
allow 172.18.10.71
allow 172.18.10.72
在两台node节点上同样配置/etc/chrony/chrony.conf
#同样注释默认的ntp
#pool ntp.ubuntu.com iburst maxsources 4
#pool 0.ubuntu.pool.ntp.org iburst maxsources 1
#pool 1.ubuntu.pool.ntp.org iburst maxsources 1
#pool 2.ubuntu.pool.ntp.org iburst maxsources 2
#定义从master节点172.18.10.70同步时间
server 172.18.10.70 iburst时间同步可以参考:Ubuntu使用Chrony配置NTP服务器和客户端-CSDN博客
安装docker
集群内主机都需要执行
apt update
apt install -y ca-certificates curl gnupg lsb-release
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
apt-get update
apt install docker-ce docker-ce-cli containerd.io docker-compose -y
cat > /etc/docker/daemon.json <安装最新版本的kubeadm、kubelet 和 kubectl
集群内主机都需要执行
配置安装源
其中新版 kubernetes 源按照安装版本区分不同仓库,该文档示例为配置 1.30 版本,如需其他版本请在对应位置字符串替换即可。
比如需要安装 其他版本,则需要将如下配置中的 v1.30 替换成 其他版本号
apt-get update && apt-get install -y apt-transport-https
#配置安装源
# kubeadm.yaml
kubernetesVersion: ${K8S_VERSION}.1 # 或者根据实际情况调整小版本号
curl -fsSL https://mirrors.aliyun.com/kubernetesnew/core/stable/${K8S_VERSION}/deb/Release.key |
gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/${K8S_VERSION}/deb/ /" |
tee /etc/apt/sources.list.d/kubernetes.list
#这是我自己安装时候的配置
curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/Release.key |
gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/ /" |
tee /etc/apt/sources.list.d/kubernetes.list
安装kubelet、kubeadm 和 kubectl
apt update
apt install -y kubelet kubeadm kubectl设置kubelet自启
此时,还不能启动kubelet,因为集群还没有配置起来,现在仅仅设置开机自启动
systemctl enable kubeletcri-dockerd
集群内主机都需要执行
Kubernetes自v1.24移除了对docker-shim的支持,而Docker Engine默认又不支持CRI规范,因而二者将无法整合在一起。Mirantis和Docker联合创建了cri-dockerd项目,用于为Docker Engine提供一个能够支持到CRI规范的载体,从而能够让Kubernetes基于CRI控制Docker 。
cri-dockerd项目提供了rpm包

下载地址:GitHub - Mirantis/cri-dockerd: dockerd as a compliant Container Runtime Interface for Kubernetes
安装 cri-dockerd
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.14/cri-dockerd_0.3.14.3-0.ubuntu-jammy_amd64.deb
dpkg -i ./cri-dockerd_0.3.14.3-0.ubuntu-jammy_amd64.deb配置 cri-dockerd
从国内 cri-dockerd 服务无法下载 k8s.gcr.io上面相关镜像,导致无法启动,所以需要修改cri-dockerd 使用国内镜像源
修改配置文件,设置国内镜像源
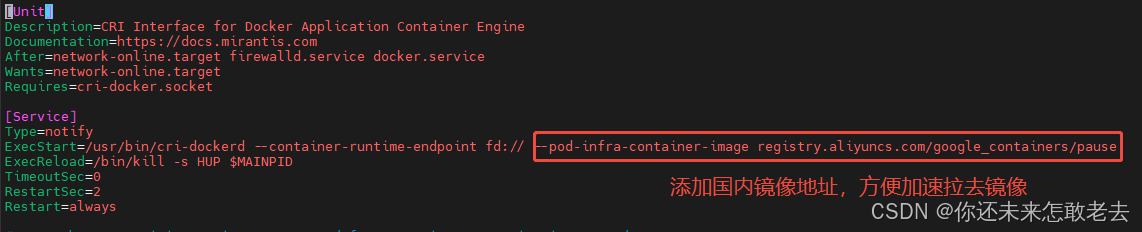
$ sed -ri 's@^(.*fd://).*$@ --pod-infra-container-image registry.aliyuncs.com/google_containers/pause@' /usr/lib/systemd/system/cri-docker.service
# 重启
$ systemctl daemon-reload && systemctl restart cri-docker && systemctl enable cri-docker#修改镜像地址为国内镜像地址
vim /usr/lib/systemd/system/cri-docker.service
# 由于国内网络环境可能无法直接访问 k8s.gcr.io 镜像仓库,导致 cri-dockerd 无法拉取 pause 镜像,从而启动失败。
# 因此,需要修改 cri-docker.service 配置文件,将默认的 pause 镜像地址替换为国内镜像源。
# registry.aliyuncs.com/google_containers/pause 镜像是一个基础的 pause 容器镜像,用于支持 Kubernetes 的 Pod 网络模型。
在master节点上初始化
集群内master主机需要执行
生成初始化配置文件
kubeadm config print init-defaults > kubeadm.yaml修改配置文件
vim kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
# 修改成本master的ip
advertiseAddress: 172.18.10.70
bindPort: 6443
nodeRegistration:
# 修改成cri-dockerd的sock
#criSocket: unix:///run/cri-dockerd.sock
criSocket: unix:///var/run/dockershim.sock
imagePullPolicy: IfNotPresent
# 修改成本master的主机名
name: k8s-master
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
# 修改etcd的数据目录
dataDir: /data/etcd
# 修改加速地址
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
# 修改成具体对应的版本好
kubernetesVersion: 1.30.1
# 如果是多master节点,就需要添加这项,指向代理的地址,这里就设置成master的节点
# 单 master 节点可以注释掉此项,kubeadm 会自动配置为当前 master 节点的 IP 地址。
#controlPlaneEndpoint: "master:6443"
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
# 添加pod的IP地址
podSubnet: 10.244.0.0/16
scheduler: {}
# 在最后添加上下面两部分
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd初始化集群
kubeadm init --config=kubeadm.yaml执行命令出现如下输出 则表示初始化成功
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.140.75:6443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:0deaa9ceed7266c28c5f5241ed9efea77c798055ebcc7a27dc03f6c97323c8a0 按照提示要求,创建配置文件目录以及复制配置文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config加入worker节点
集群内只在worker主机需要执行
kubeadm join 192.168.140.75:6443
--token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:0deaa9ceed7266c28c5f5241ed9efea77c798055ebcc7a27dc03f6c97323c8a0
--cri-socket unix:///run/cri-dockerd.sock注意,一定要加上 --cri-socket unix:///run/cri-dockerd.sock
指定容器运行时
执行完成,查看节点
root@k8s-master:/# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane 9m12s v1.30.1
k8s-node1 NotReady 4m43s v1.30.1
k8s-node2 NotReady 5m15s v1.30.1
root@k8s-master:/# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok
安装pod网络calico
可以看到,虽然worker节点虽然添加上去了,但是状态时NotReady的,所以需要安装网络
只需要在其中一个master节点上执行
下载资源清单文件
下载链接地址: https://docs.projectcalico.org/manifests/calico.yaml
wget https://docs.projectcalico.org/manifests/calico.yaml修改资源清单文件
查找 DaemonSet
找到下面的容器containers部分
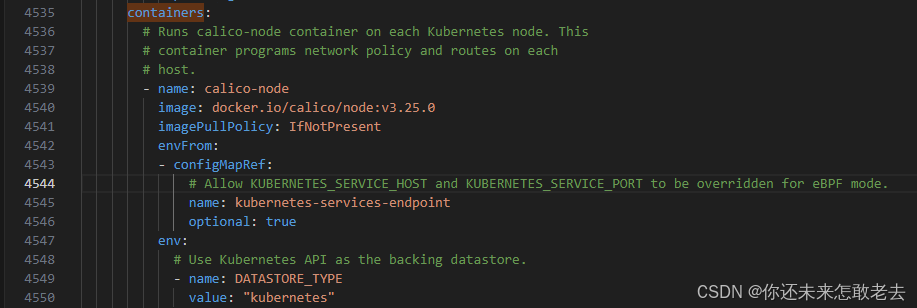
修改网卡为自己的网卡名称

修改CIDR,将CIDR修改成上面初始化时pod的内部网段
对应项:
- --pod-network-cidr=10.244.0.0/16
- podSubnet: 10.244.0.0/16
# The default IPv4 pool to create on startup if none exists. Pod IPs will be
# chosen from this range. Changing this value after installation will have
# no effect. This should fall within `--cluster-cidr`.
#
#这部分原本是注释的,需要去掉#号,将192.168.0.0/16修改成10.244.0.0/16
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
# Disable file logging so `kubectl logs` works.
- name: CALICO_DISABLE_FILE_LOGGING
value: "true"安装calico
kubectl apply -f calico.yaml命令观察各服务的状态
watch kubectl get pods --all-namespaces -o wide查看节点状态
当看到pod都正常运行了,就可以查看状态了
root@k8s-master:/# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 29h v1.30.10
k8s-node1 Ready 29h v1.30.10
k8s-node2 Ready 29h v1.30.10
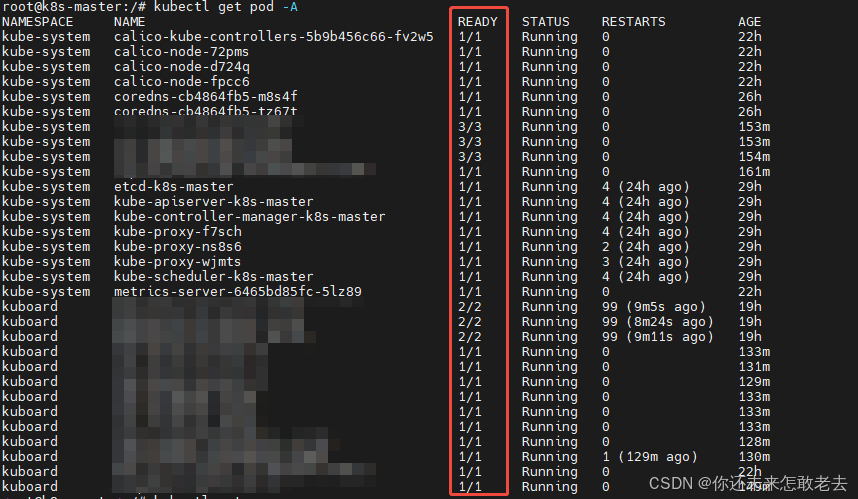
如果pod 状态都为Ready即成功
在执行kubectl get pod -A READY没有0出现那就说明我们的集群已经搭建成功
以上是我个人结合教程搭建的过程,分享给大家。如有不足之处可指出留言指导!