


05-mcp-server案例分享-用豆包大模型 1.6 手搓文生图视频 MCP-server发布到PyPI官网
1前言
上期给大家介绍过mcp-server案例分享-用豆包大模型 1.6 手搓文生图视频 MCP-server。当时部署的方式使用了一个私有云SSE的部署。当时缺少一个本地部署的方式,有的小伙伴给我留言能不能有一个本地话部署方式了。今天就给大家带来一个本地化部署的方案。
话不多说下面介绍一下具体如何打包和操作的。
2.打包发布Python库到PyPI
基于上期文章我们已经有了代码mcp_ai_server.py
# doubao_mcp_server.py
import time
import base64
import requests
import asyncio
from typing import Any, Dict, Optional, Union
from openai import OpenAI
from mcp.server.fastmcp import FastMCP
# 创建MCP服务器实例
mcp = FastMCP("AI Generation Server")
# 全局配置
API_KEY = None
BASE_URL = "https://ark.cn-beijing.volces.com/api/v3"
def initialize_client():
"""初始化OpenAI客户端"""
if not API_KEY:
raise ValueError("API key is required")
return OpenAI(api_key=API_KEY, base_url=BASE_URL)
@mcp.tool()
def set_api_key(api_key: str) -> str:
"""设置豆包API密钥"""
global API_KEY
API_KEY = api_key
return "API密钥设置成功"
@mcp.tool()
def text_to_image(
prompt: str,
size: str = "1024x1024",
model: str = "doubao-seedream-3-0-t2i-250415"
) -> Dict[str, Any]:
"""
文生图功能 - 根据文本描述生成图片
Args:
prompt: 图片描述提示词
size: 图片尺寸,格式为"宽x高",如"1024x1024"
model: 使用的模型名称
Returns:
包含图片URL或错误信息的字典
"""
try:
client = initialize_client()
params = {
"model": model,
"prompt": prompt,
"size": size,
"response_format": "url",
"n": 1,
}
response = client.images.generate(**params)
if response.data and len(response.data) > 0:
return {
"success": True,
"image_url": response.data[0].url,
"message": "图片生成成功"
}
else:
return {
"success": False,
"error": "未返回图片数据"
}
except Exception as e:
return {
"success": False,
"error": f"生成图片时出错: {str(e)}"
}
@mcp.tool()
def image_to_video(
prompt: str,
image_base64: str,
duration: str = "5",
ratio: str = "16:9",
model: str = "doubao-seedance-1-0-lite-i2v-250428"
) -> Dict[str, Any]:
"""
图生视频功能 - 根据图片和文本描述生成视频
Args:
prompt: 视频描述提示词
image_base64: 图片的base64编码字符串
duration: 视频时长(秒)
ratio: 视频比例,如"16:9"
model: 使用的模型名称
Returns:
包含视频URL或错误信息的字典
"""
try:
# 构造图片数据URL
image_data_url = f"data:image/jpeg;base64,{image_base64}"
# 自动添加参数到提示词
if ratio and "--ratio" not in prompt:
prompt += f" --ratio adaptive"
if duration and "--duration" not in prompt and "--dur" not in prompt:
prompt += f" --duration {duration}"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# 构造请求内容
content = [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_data_url}}
]
request_data = {
"model": model,
"content": content
}
# 创建视频生成任务
response = requests.post(
f"{BASE_URL}/contents/generations/tasks",
headers=headers,
json=request_data
)
if response.status_code != 200:
return {
"success": False,
"error": f"创建视频生成任务失败,状态码: {response.status_code}, 信息: {response.text}"
}
task_id = response.json().get("id")
if not task_id:
return {
"success": False,
"error": "未获取到任务ID"
}
# 轮询等待任务完成
max_retries = 60
for retry in range(max_retries):
time.sleep(5)
task_resp = requests.get(
f"{BASE_URL}/contents/generations/tasks/{task_id}",
headers=headers
)
if task_resp.status_code != 200:
return {
"success": False,
"error": f"查询任务失败,状态码: {task_resp.status_code}"
}
task_data = task_resp.json()
status = task_data.get("status")
if status == "succeeded":
video_url = task_data.get("content", {}).get("video_url")
return {
"success": True,
"video_url": video_url,
"message": "视频生成成功",
"task_id": task_id
}
elif status in ("failed", "canceled"):
return {
"success": False,
"error": f"任务{status}"
}
return {
"success": False,
"error": "视频生成超时"
}
except Exception as e:
return {
"success": False,
"error": f"生成视频时出错: {str(e)}"
}
@mcp.tool()
def text_to_video(
prompt: str,
duration: str = "5",
ratio: str = "16:9",
model: str = "doubao-seedance-1-0-lite-t2v-250428"
) -> Dict[str, Any]:
"""
文生视频功能 - 根据文本描述生成视频
Args:
prompt: 视频描述提示词
duration: 视频时长(秒)
ratio: 视频比例,如"16:9"
model: 使用的模型名称
Returns:
包含视频URL或错误信息的字典
"""
try:
# 自动添加参数到提示词
if ratio and "--ratio" not in prompt:
prompt += f" --ratio {ratio}"
if duration and "--duration" not in prompt and "--dur" not in prompt:
prompt += f" --duration {duration}"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
request_data = {
"model": model,
"content": [{"type": "text", "text": prompt}]
}
# 创建视频生成任务
response = requests.post(
f"{BASE_URL}/contents/generations/tasks",
headers=headers,
json=request_data
)
if response.status_code != 200:
return {
"success": False,
"error": f"创建视频生成任务失败,状态码: {response.status_code}, 信息: {response.text}"
}
task_id = response.json().get("id")
if not task_id:
return {
"success": False,
"error": "未获取到任务ID"
}
# 轮询等待任务完成
max_retries = 60
for retry in range(max_retries):
time.sleep(5)
task_resp = requests.get(
f"{BASE_URL}/contents/generations/tasks/{task_id}",
headers=headers
)
if task_resp.status_code != 200:
return {
"success": False,
"error": f"查询任务失败,状态码: {task_resp.status_code}"
}
task_data = task_resp.json()
status = task_data.get("status")
if status == "succeeded":
video_url = task_data.get("content", {}).get("video_url")
return {
"success": True,
"video_url": video_url,
"message": "视频生成成功",
"task_id": task_id
}
elif status in ("failed", "canceled"):
return {
"success": False,
"error": f"任务{status}"
}
return {
"success": False,
"error": "视频生成超时"
}
except Exception as e:
return {
"success": False,
"error": f"生成视频时出错: {str(e)}"
}
@mcp.tool()
def encode_image_to_base64(image_path: str) -> Dict[str, Any]:
"""
将本地图片文件编码为base64字符串
Args:
image_path: 图片文件路径
Returns:
包含base64编码字符串或错误信息的字典
"""
try:
with open(image_path, 'rb') as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return {
"success": True,
"base64_string": encoded_string,
"message": "图片编码成功"
}
except Exception as e:
return {
"success": False,
"error": f"编码图片失败: {str(e)}"
}
@mcp.resource("config://models")
def get_available_models() -> str:
"""获取可用的AI模型列表"""
models = {
"text_to_image": [
"doubao-seedream-3-0-t2i-250415"
],
"image_to_video": [
"doubao-seedance-1-0-lite-i2v-250428"
],
"text_to_video": [
"doubao-seedance-1-0-lite-t2v-250428"
]
}
return f"可用模型列表: {models}"
@mcp.resource("config://settings")
def get_server_settings() -> str:
"""获取服务器配置信息"""
settings = {
"base_url": BASE_URL,
"api_key_set": bool(API_KEY),
"supported_image_sizes": ["512x512", "768x768", "1024x1024", "1024x1792", "1792x1024"],
"supported_video_ratios": ["16:9", "9:16", "1:1"],
"max_video_duration": "10s"
}
return f"服务器配置: {settings}"
def main():
"""主函数入口点"""
mcp.run(transport="stdio")
if __name__ == "__main__":
main()
包代码开发
将您MCP server本地脚本打包,需要在doubao_mcp_server目录新建一个文件__init__.py
init.py
from .doubao_mcp_server import main
__all__ = ["main"]
本地测试
打包后测试可以将这个mcp server作为模块来运行,而不是直接通过脚本运行。
# 以模块运行
uv run -m mcp_ai_server
或者也可以在MCP 客户端比如Cherry Studio上配置config测试
{
"mcpServers": {
"r-FY6A48OrPGz5fknShHt": {
"name": "doubao-mcp-server",
"type": "stdio",
"description": "",
"isActive": true,
"registryUrl": "https://pypi.tuna.tsinghua.edu.cn/simple",
"command": "uv",
"args": [
"--directory",
"F:workcodeAIcodedoubao_mcp_server",
"run",
"doubao-mcp-server.py"
]
}
}
Cherry Studio上 界面配置
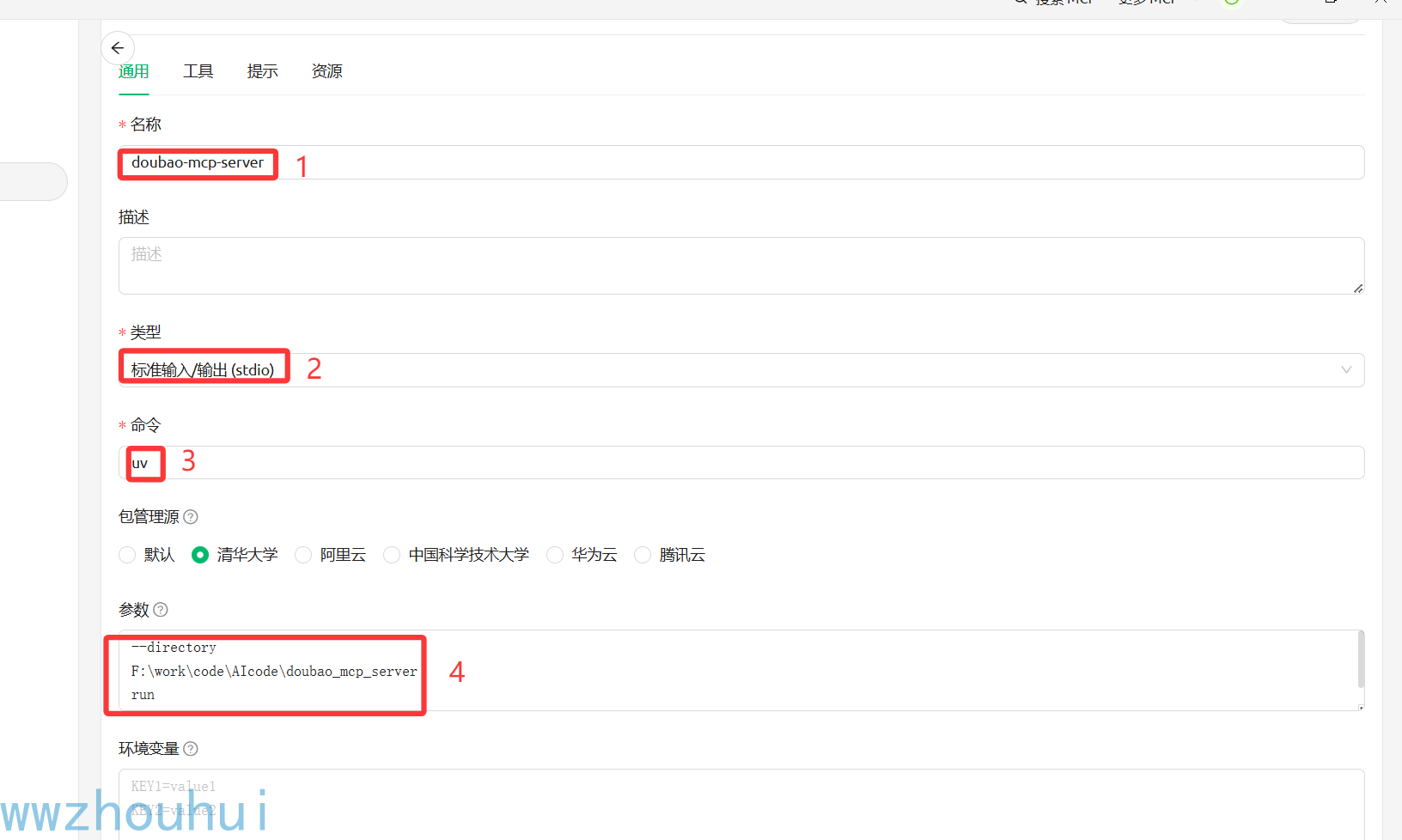
点击保存验证一下,查看下工具列表
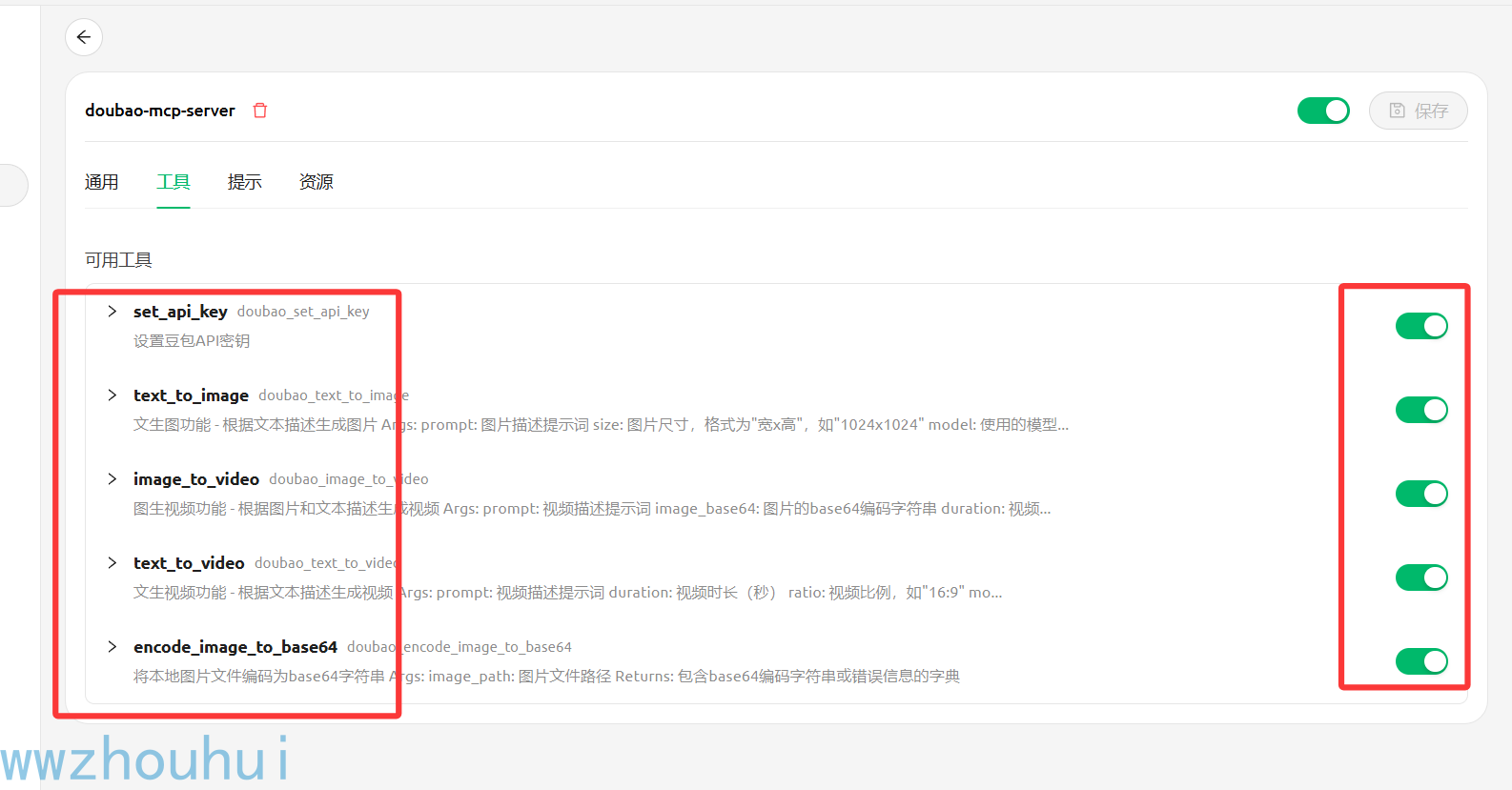
看到这个说明可以在客户端使用这个MCP-Server了。
作为一个包发布到PyPI
编写pyproject.toml
您需要确保在您的项目根目录,存在一个完整的pyproject.toml文件(在前面的步骤中应该已经自动生成)。这个文件的内容包括:
- 包的元信息:名字、版本、描述、作者
- 依赖项
- 构建系统配置
- MCP入口
pyproject.toml文件:
[project]
name = “doubao-mcp-server”
version = “0.1.0”
description = “主要实现的是火山引擎的提供的豆包文生图、文生视频、图生视频MCP-Server”
authors = [
{name = “wwzhouhui”,email = “75271002@qq.com”}
]
readme = “README.md”
requires-python = “>=3.13”
dependencies = [
“mcp[cli]>=1.9.4”, # 添加requests依赖
“requests>=2.31.0”,
“openai>=1.86.0”,
]
[project.scripts]
doubao-mcp-server = “doubao_mcp_server:main”
[build-system]
requires = [“hatchling”]
build-backend = “hatchling.build”
Python包创建一个README.md
这个地方我们省略
编译打包
构建你Python包,这个地方我稍微讲一下
cd F:workcodeAIcodedoubao_mcp_server
uv build
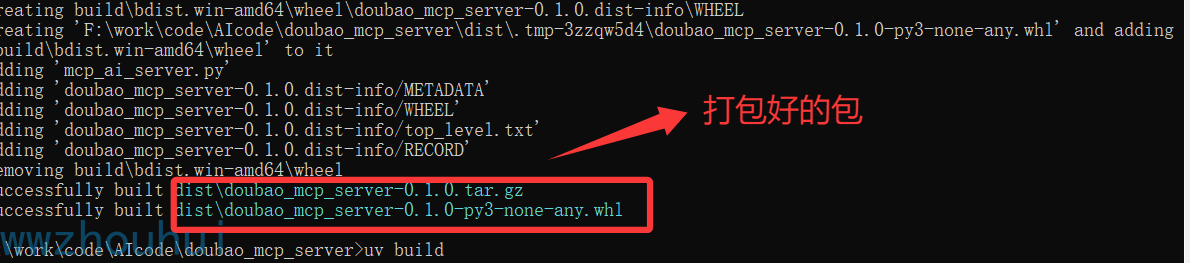
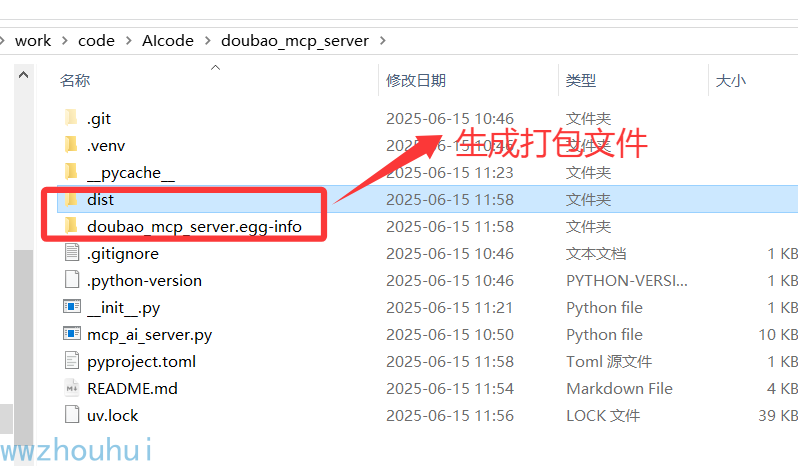
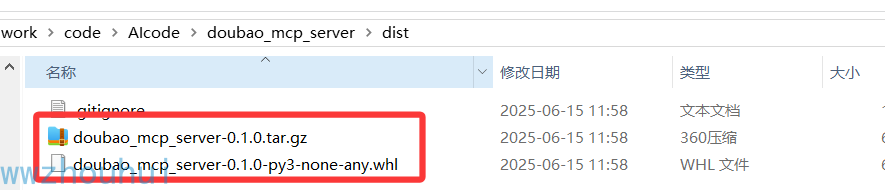
检查打包文件
在dist/目录下看见.whl和.tar.gz的两个文件
准备PyPI账户
我需要登录PyPI官网:https://pypi.org/account/login/ 注册一个账号(如果之前没有的话)
关于PyPI注册比较麻烦,这里不做详细展开。主要是注册之后还需要微软的Authenticator 手机上安装,然后通过双重身份验证完成登录

完整双重身份验证后,我们就可以实现打包文件上传了。
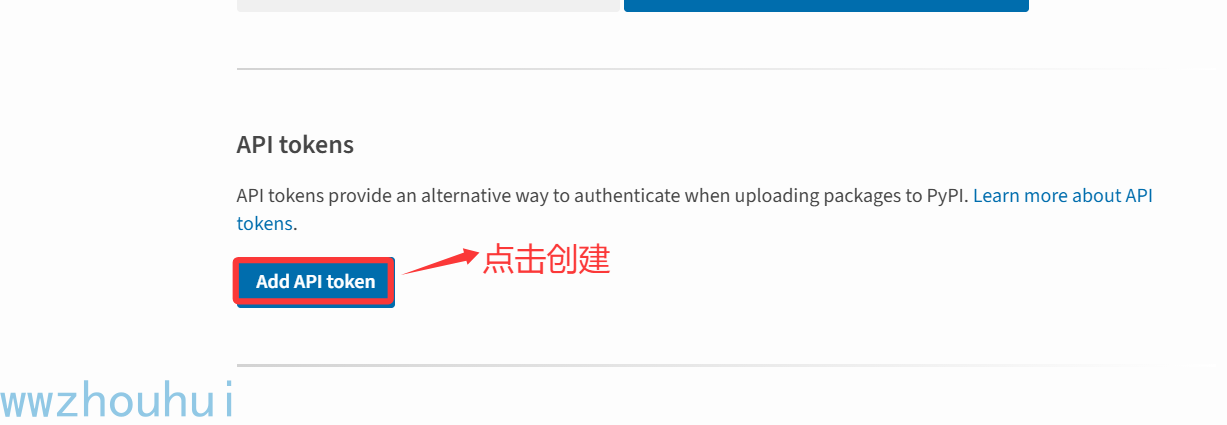
pypi api token创建
双重身份验证通过后,我们点击“add api token” 创建一个api
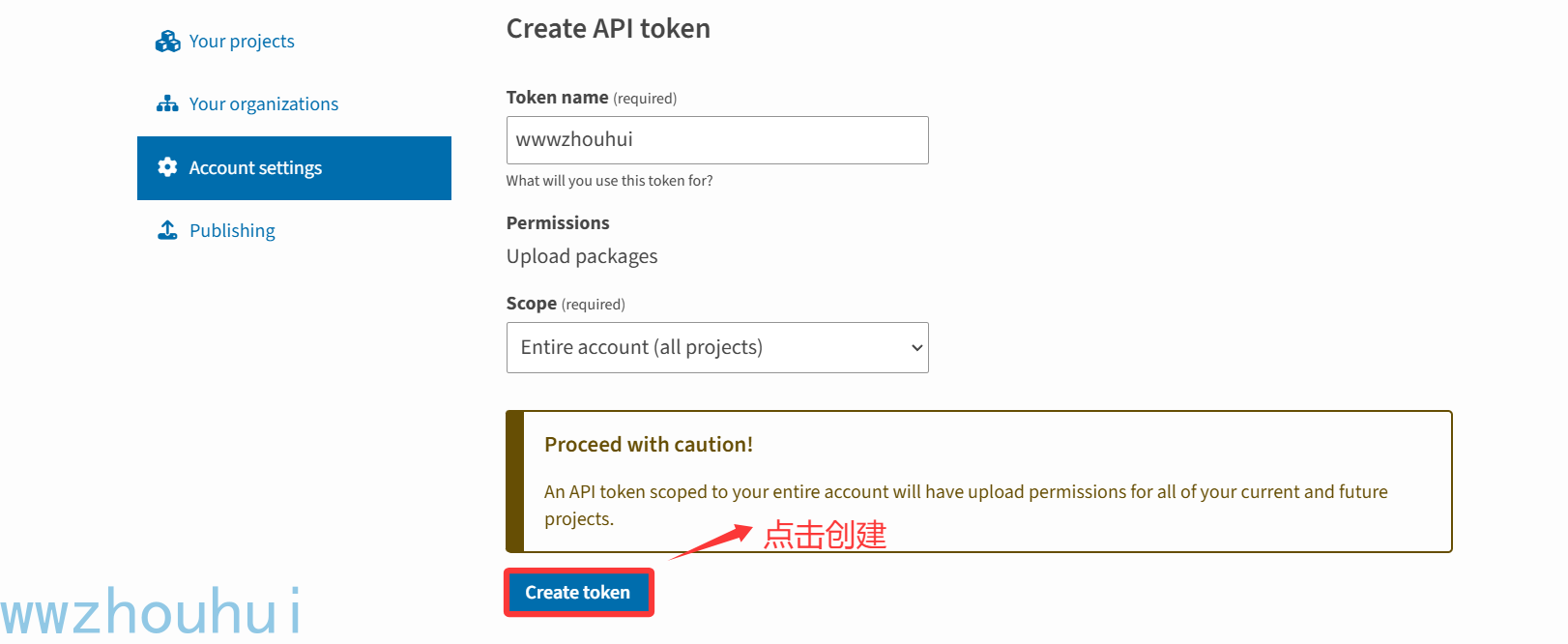
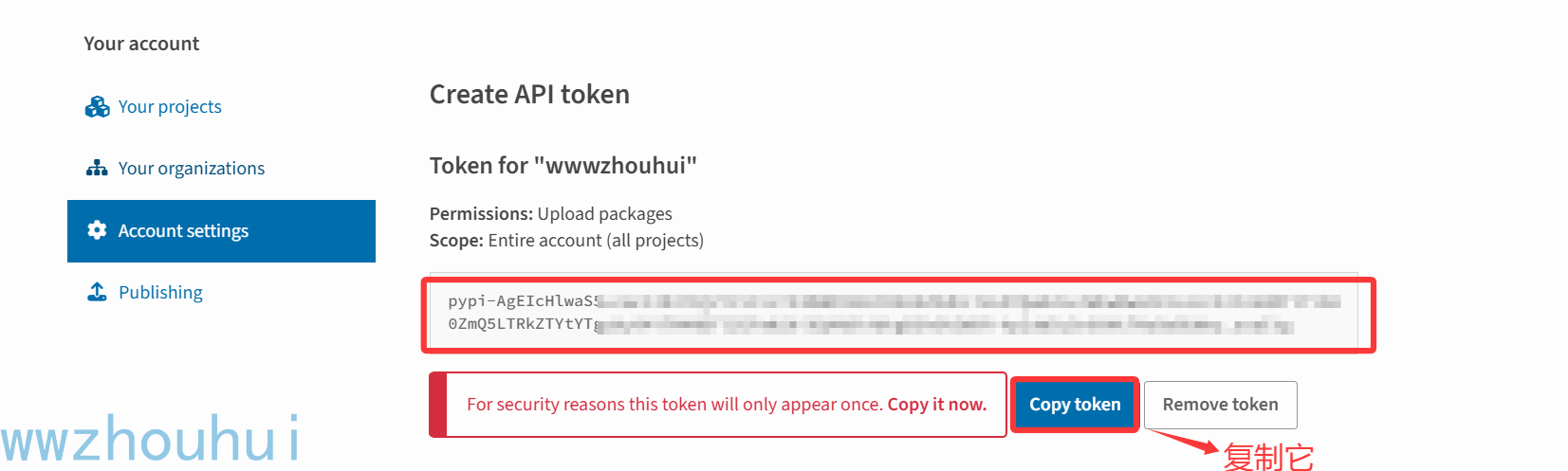
复制上面的token用记事本保存好。
上传您的Python包
我们在命令行窗口输入如下命令
uv publish --token pypi-xxxxxx

我们去pypi 查看我们上传的包
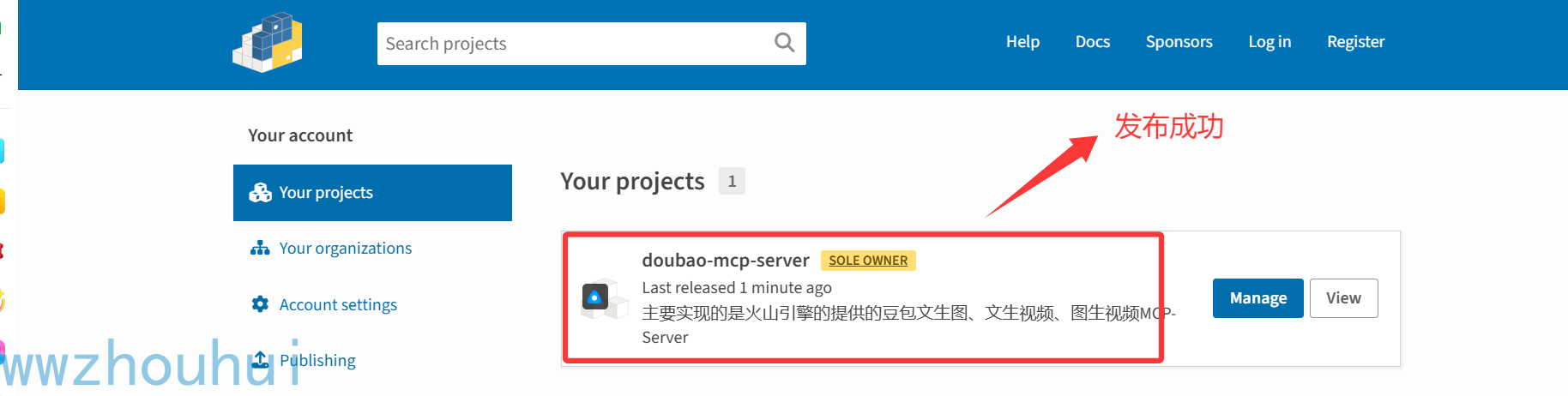
打开view 我们就查看刚刚上传的详细的依赖包
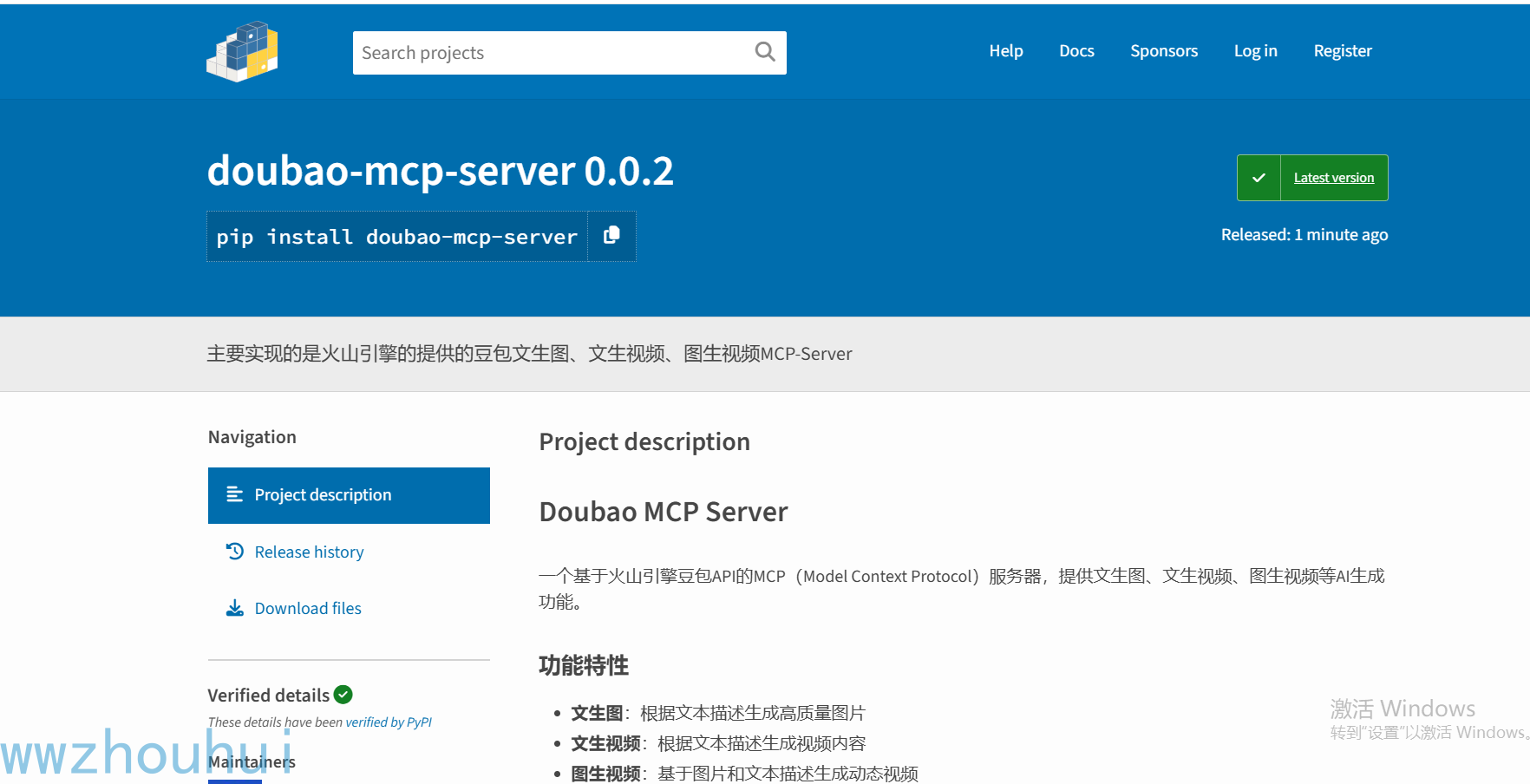
MCP客户端测试
一旦发布完成, 用户就可以通过uvx安装和使用您的 MCP server。uvx会创建一个临时环境,安装依赖并执行这个包,非常的简洁优雅。
接下来我们使用trae 来下载安装我们刚才上传的pypi依赖包
我们在trae 添加如下mcp-server配置
{
"mcpServers": {
"doubao-mcp-server": {
"command": "uvx",
"args": [
"doubao-mcp-server"
],
"env": {
"DOUBAO_API_KEY": "your-api-key-here"
}
}
}
}
配置完成后
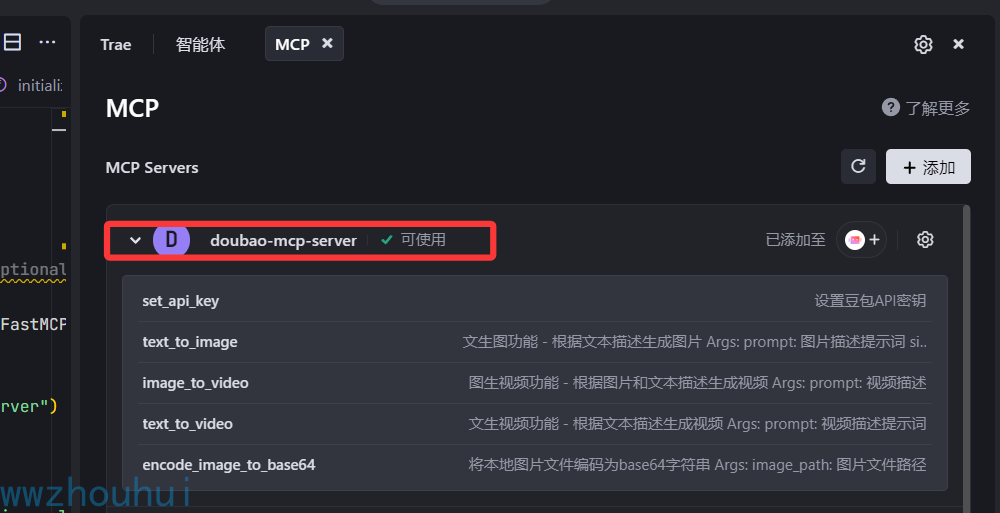
我们测试一下
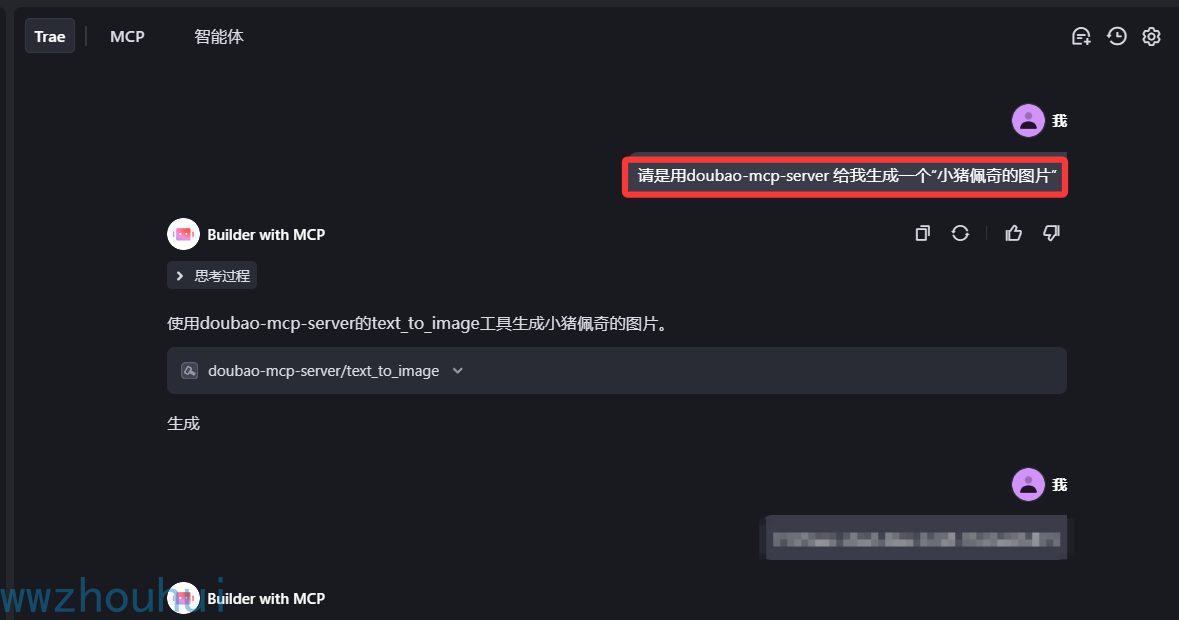
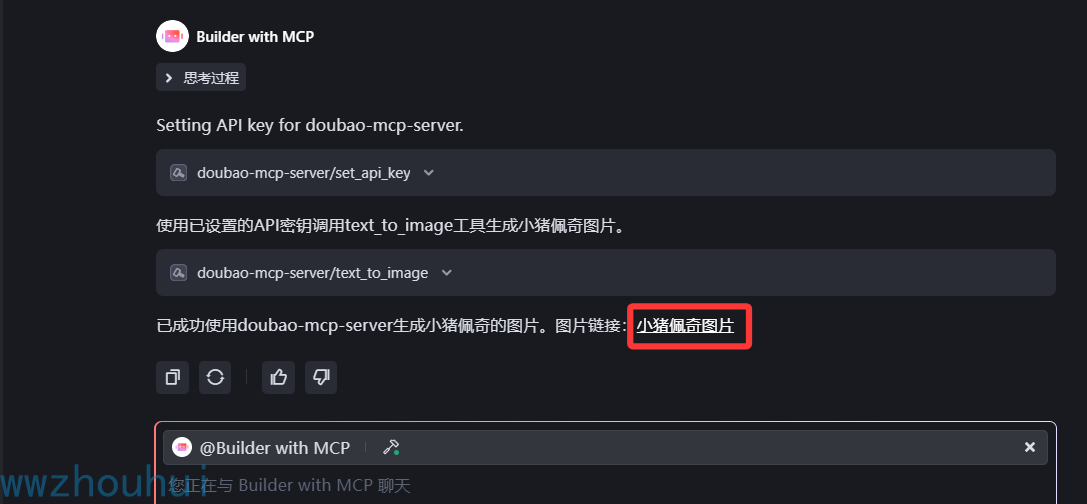

有点丑,不过确实已经弄个调用生产图片了。
3.部署到魔搭MCP广场
我们也可以把这个MCP部署到魔搭社区的MCP广场上给大家使用。
-
进入魔搭MCP广场
MCP广场地址:modelscope.cn/mcp

-
基础信息填写
创建类型:选择“GitHub快速创建”
英文名称:英文MCP Server名字,
中文名称:中文MCP Server名字,
来源地址:代码我们已经上传github地址:https://github.com/wwwzhouhui/doubao_mcp_server
所有者:默认已填好
托管类型:选择“可托管部署”
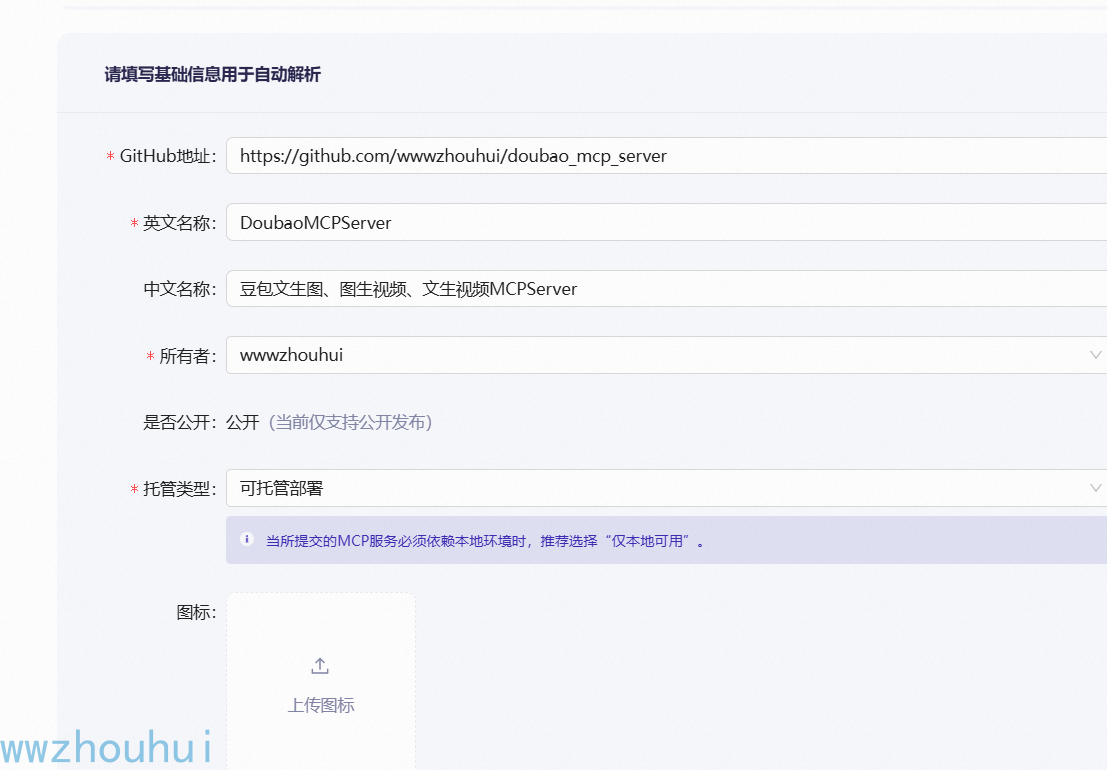
完成部署
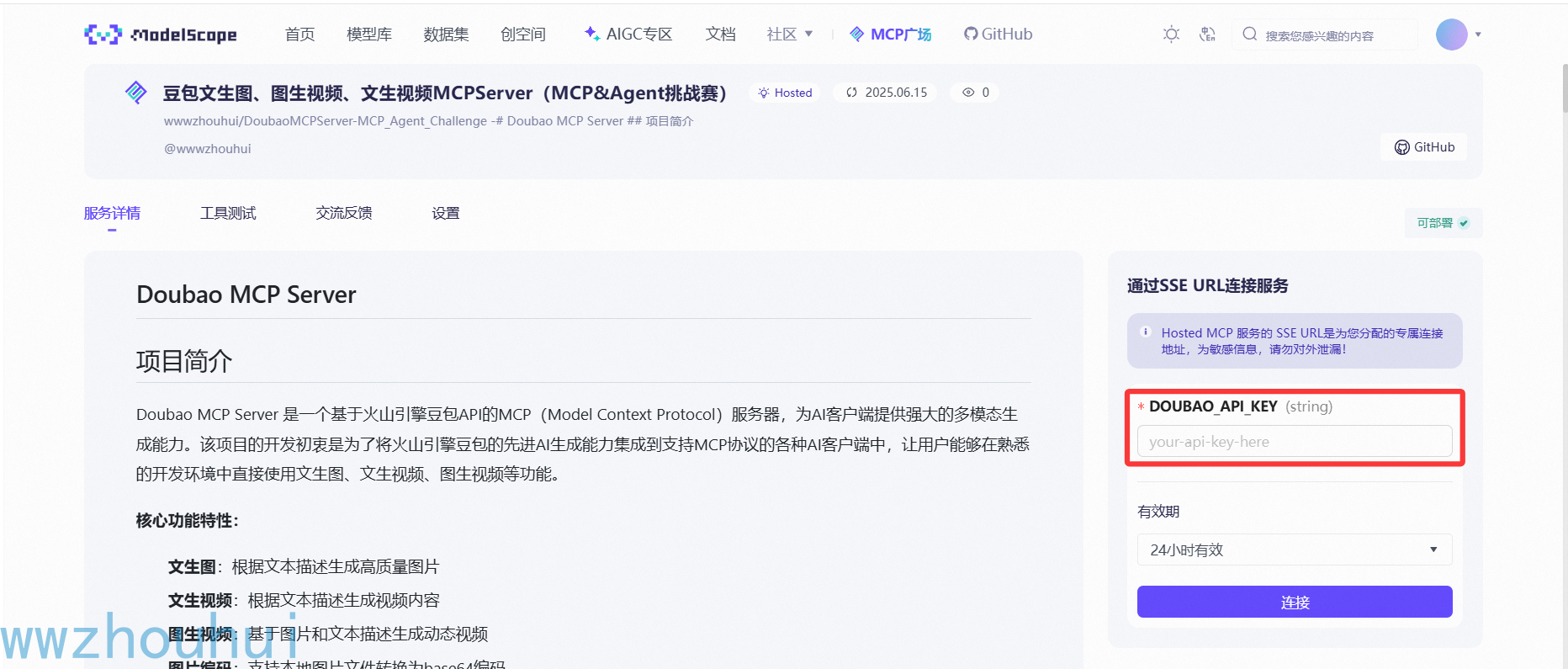
上面填写APIkey 就可以体验了。按照下面填写APIkey
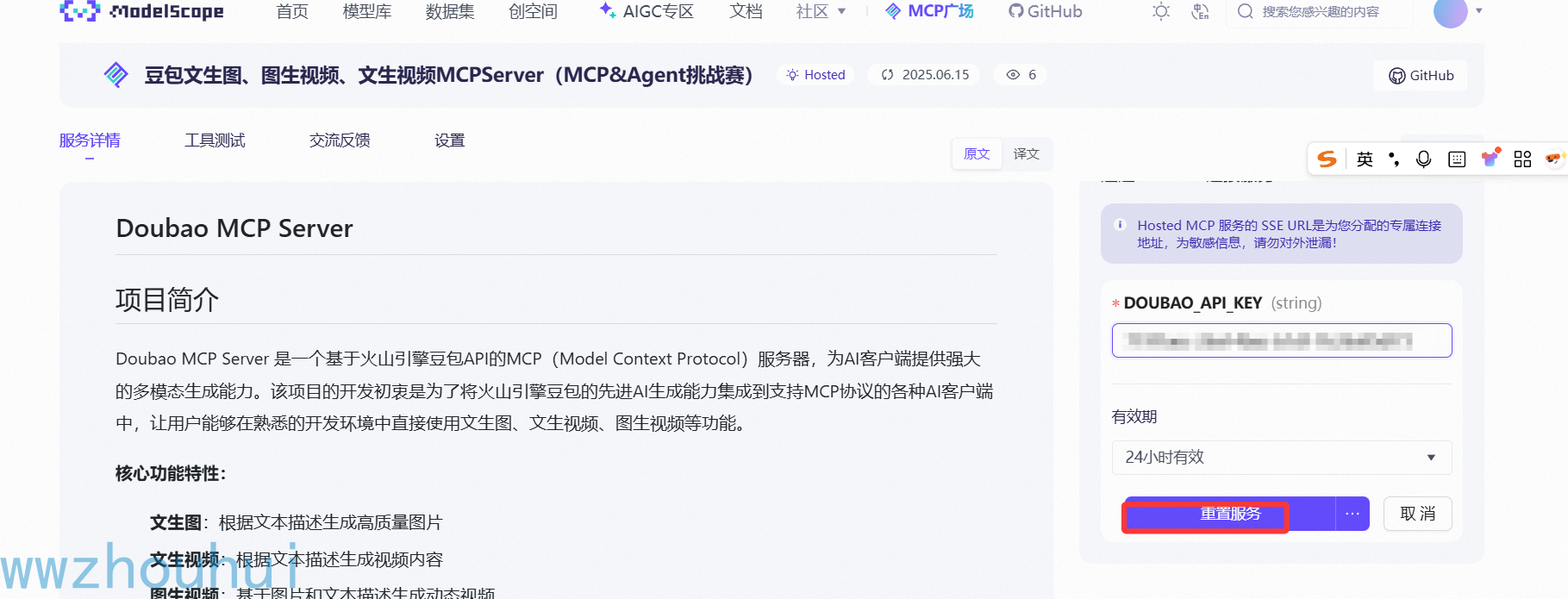
生成SSE URL 地址(上面地址有效期时间24个小时,也可以设置长期有效)
{
"mcpServers": {
"DoubaoMCPServer-MCP_Agent_Challenge": {
"type": "sse",
"url": "https://mcp.api-inference.modelscope.net/aee3086059a34e/sse"
}
}
}
接下来我们也可以在魔搭的应用广场上体验了。我们点击“试用” 就可以在魔搭社区免费体验了。
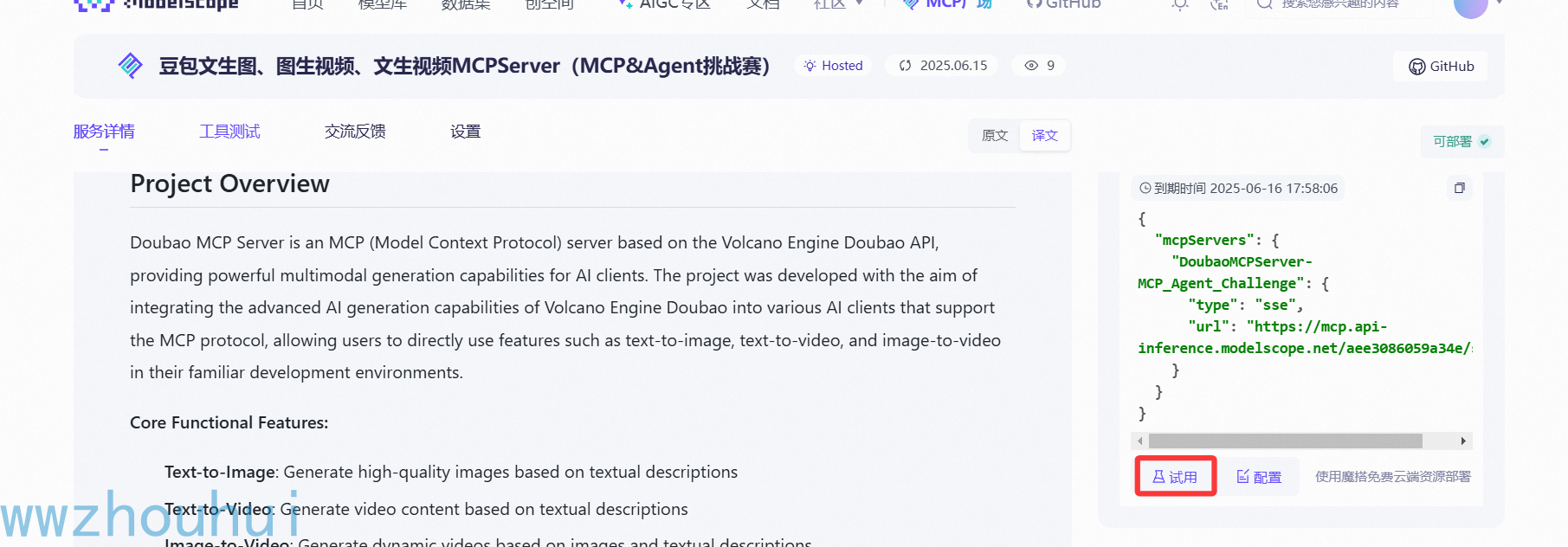
摩搭社区MCP应用广场测试
进入应用广场 输入下面的提示词
文生图
给我画一个 小白兔吃萝卜
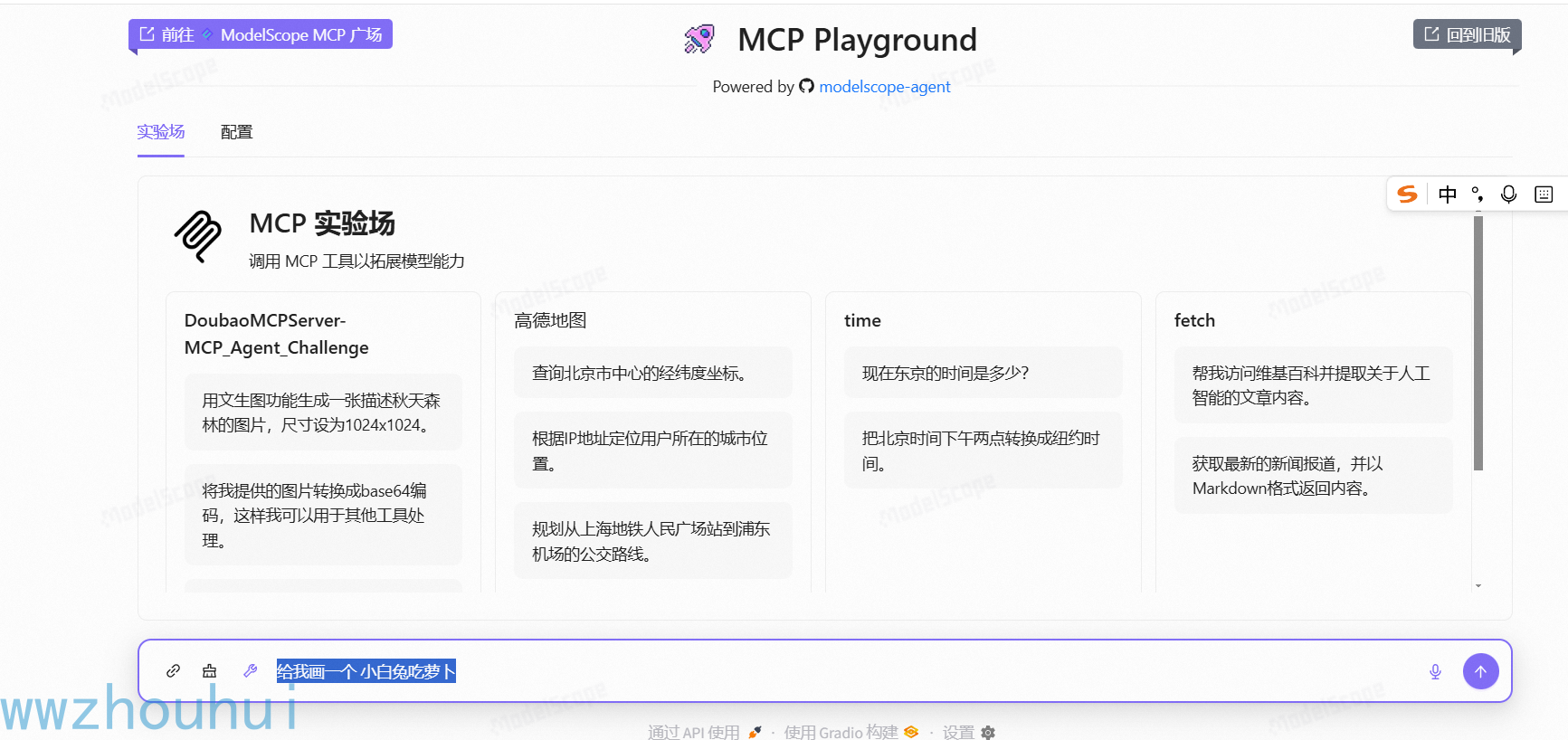
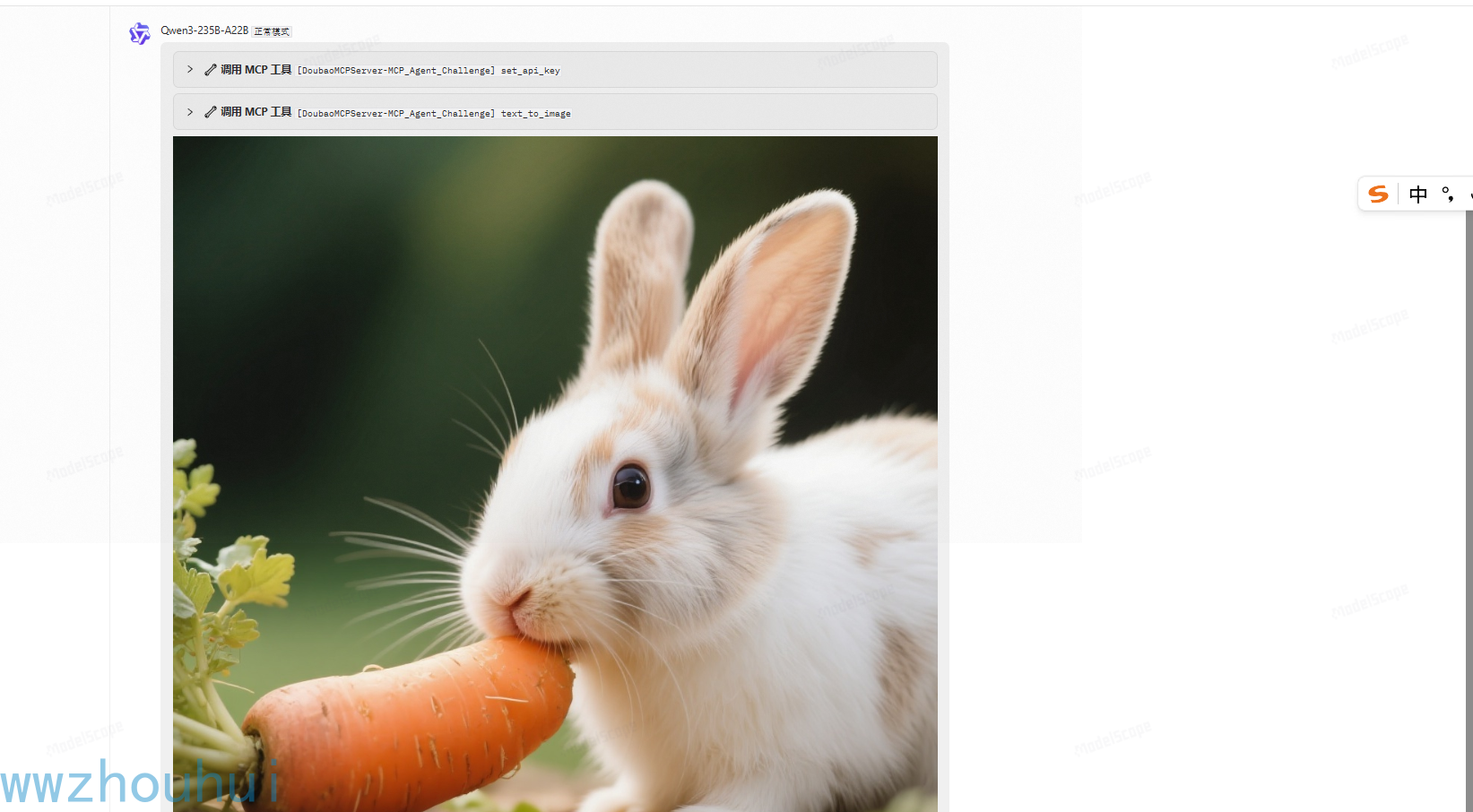
这样我们在魔搭社区里面也可以使用我我们刚才部署打包的MCP-server了。
文生视频
提示词:给我生成一个小白兔吃萝卜的视频

4.总结
今天主要带大家了解并实现了基于豆包大模型 1.6 发布的文生图、文生视频、图生视频功能的 MCP-Server 本地化部署与发布方案。通过将 MCP Server 脚本打包为 Python 库并发布至 PyPI,我们成功实现了可跨平台调用的 AI 生成服务。借助火山引擎提供的文生图、文生视频、图生视频模型 API,我们构建了一个功能完整的 MCP-Server,支持通过文本描述生成高质量图片和视频内容。
通过本文的方案,开发者可以轻松搭建自己的文生图、文生视频、图生视频服务,为应用程序添加强大的 AI 生成能力。感兴趣的小伙伴可以按照本文步骤去尝试搭建自己的 MCP-Server。今天的分享就到这里结束了,我们下一篇文章见。








