


构建永不宕机的服务器:高可用性架构设计与实践
本文还有配套的精品资源,点击获取 
简介:在IT行业中,确保服务器的高可用性对于企业持续运营至关重要。本文介绍了实现永不宕机服务器的关键技术与策略,包括冗余硬件、负载均衡、集群计算、热备与冷备、虚拟化技术、自动故障检测与恢复、数据备份与恢复、更新与维护策略、容错设计以及持续监控与性能优化。通过这些综合解决方案,可以显著提高系统的可用性,减少宕机事件,无限接近永不宕机的目标。 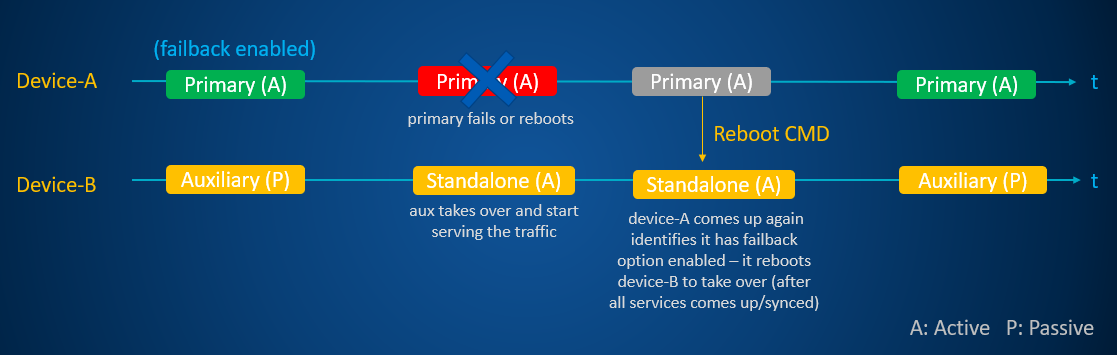
1. 永不宕机的服务器
在如今这个数据驱动的互联网时代,服务器的稳定性对于企业来说是至关重要的。宕机不仅意味着业务的暂时中断,更可能导致经济损失和品牌信誉的下降。因此,构建一个永不宕机的服务器成为了每个IT运维团队追求的目标。
1.1 服务器宕机的潜在威胁
服务器宕机可能是由软件故障、硬件故障、网络问题或外部攻击等多种原因引起的。在高流量和关键业务的场合,任何短时间的中断都可能造成巨大的影响。理解服务器宕机的潜在威胁是确保业务连续性的第一步。
1.2 构建永不宕机的策略基础
为了实现永不宕机的服务器,需要采取多种策略。这包括但不限于: - 多层冗余:确保所有关键组件都有备份,如电源、网络连接、存储设备等。 - 自动故障转移:通过心跳检测和主备切换机制,实现故障的及时转移。 - 负载均衡:合理分配网络和系统负载,避免单点过载。
下一章将深入探讨高可用性(HA)架构的核心概念,并进一步揭示如何设计出能够应对各种挑战的服务器系统。
2. 高可用性(HA)架构的核心概念
2.1 高可用性(HA)架构的定义和目标
2.1.1 高可用性(HA)架构的基本概念
高可用性(HA)架构是指设计和实施一系列的技术和管理措施,确保服务的连续性,在发生故障时能够迅速恢复,以最小化服务中断时间。在IT领域,HA架构至关重要,因为它直接关系到企业的业务连续性和竞争力。在HA架构中,通常会采用冗余组件、故障转移机制、负载均衡和数据复制等技术来提高系统整体的可靠性。
从系统设计的角度来看,高可用性架构旨在通过识别并减少单点故障,来降低系统故障的风险。例如,数据库系统可能采用主从复制,从而在主节点出现问题时,能够迅速切换到备用节点,保持数据库服务的连续运行。
2.1.2 高可用性(HA)架构的主要目标和优势
高可用性架构的主要目标是提高系统的正常运行时间,确保服务的稳定性和可靠性。其优势包括:
- 最小化停机时间 :通过冗余组件和快速故障转移,减少计划外的停机时间。
- 提升用户满意度 :持续提供服务,避免因系统故障导致用户不满。
- 增强业务连续性 :在关键业务系统中,HA架构能够确保在灾难发生时业务的连续性。
- 提高投资回报率 :通过减少系统维护和故障修复所需的时间和成本,提高整体的经济效益。
实现这些目标需要从架构设计的各个环节综合考虑,如硬件选择、软件配置、网络设计以及监控和维护策略的制定。
2.2 高可用性(HA)架构的设计原则
2.2.1 高可用性(HA)架构的设计原则和方法
构建高可用性架构时,通常遵循以下设计原则:
- 冗余性 :通过部署额外的组件和资源,确保当某个组件失败时,系统仍然可以继续运行。
- 故障转移 :设计机制确保在任何组件发生故障时,能够迅速将工作负载转移到备用组件。
- 负载均衡 :通过分散请求到不同的服务器,避免单个服务器过载,从而提高整体性能和可用性。
- 监控与预警 :实时监控系统状态,并在故障发生前发出预警,以便及时采取措施。
在方法上,设计高可用性架构时要综合考虑可用性、可维护性、成本效益和安全性。此外,HA架构的设计应该是一个迭代的过程,需要不断地评估、测试和改进以适应业务需求的变化。
2.2.2 高可用性(HA)架构的设计案例分析
以电子商务网站为例,该网站需要提供24/7的在线购物服务,保证订单处理的高可用性至关重要。在这种场景下,可以通过以下方法实现HA架构:
- 冗余部署 :使用多个数据库服务器和应用服务器,并通过主从复制保持数据同步。
- 负载均衡器 :采用负载均衡器分散用户请求,保证在流量高峰期间系统不会过载。
- 监控系统 :设置监控系统跟踪关键性能指标,及时发现并解决潜在的问题。
在这个案例中,一个有效的设计可能包括在不同地理位置部署数据中心,以应对区域性灾难。同时,还需要实现自动化的故障转移机制,确保网站在发生故障时能快速恢复。通过这些方法,即使在关键组件失效的情况下,也能保持网站的高可用性,从而满足用户的购物需求。
3. 硬件和软件层面的容错设计
3.1 冗余硬件的重要性
3.1.1 冗余硬件的基本概念和作用
在构建高可用性(HA)的服务器架构中,冗余硬件是确保系统能够持续运行的关键组件。冗余可以定义为在系统的关键部分放置额外的组件,这样在主要组件发生故障时,冗余组件可以立即接管工作,从而保持整个系统的运行不受影响。
冗余硬件的类型包括但不限于:冗余电源供应系统(RPS)、冗余存储解决方案、多台服务器以及网络设备的冗余配置。这种设计允许系统在部分组件失败的情况下继续运作,极大地提高了系统的容错能力和可靠性。
3.1.2 冗余硬件的设计和实施
实施冗余硬件解决方案通常涉及以下步骤:
- 需求评估 :首先评估系统的正常运行时间需求,确定哪些硬件组件是关键的,并且需要额外备份。
- 硬件选择 :根据评估结果,选择合适的冗余硬件。例如,对于服务器而言,可以采用双电源配置,对于网络来说,可以使用双路由器或交换机。
- 架构设计 :设计架构时,需要确保冗余硬件能够无缝地接管失效硬件的工作,这通常涉及到负载均衡和故障转移的策略。
- 实施与测试 :将冗余硬件集成到现有系统中,并进行充分的测试,以确保故障转移能够在实际发生硬件故障时正常工作。
示例代码块 :
# 假设我们有一个Web服务器和一个数据库服务器,需要实现电源冗余。
# 检查服务器是否配置了双电源
for server in webserver dbserver; do
ssh $server lshw | grep -i power
done
在上面的bash脚本中,我们使用 lshw 命令检查了 webserver 和 dbserver 是否都配置了双电源系统。脚本的输出将告诉我们关于电源的具体信息,我们可以根据这些信息来确认系统的冗余配置。
3.1.3 冗余硬件的成本效益分析
虽然冗余硬件能够显著提高系统的可用性,但是它们也需要额外的资本支出和运营支出。例如,冗余电源、网络设备和存储解决方案通常会比单个设备更昂贵,并且需要额外的电力、冷却和维护资源。
因此,在设计冗余硬件时,必须进行成本效益分析,以确保投资的回报大于成本。这一分析应当基于业务连续性需求和预算约束,对可能的硬件选择进行权衡。
3.1.4 维护与管理
冗余硬件的引入同时也增加了系统的复杂性。因此,需要考虑如何有效管理这些硬件资源。这包括:
- 监控状态 :对所有关键硬件组件进行定期的状态检查和健康监控,以便及时发现潜在的问题。
- 自动化故障转移 :确保在硬件故障时能够自动且快速地进行故障转移,以减少停机时间。
- 定期测试 :定期执行故障转移测试,以确保冗余系统能够按预期工作。
故障转移示例流程图 :
graph LR
A[检测到故障] --> B[触发故障转移]
B --> C[启动备用硬件]
C --> D[重新路由流量]
D --> E[通知管理员]
3.2 软件层面的容错设计
3.2.1 软件层面的容错设计基本概念和方法
在软件层面,容错设计意味着开发出能够处理运行时错误和潜在故障的程序。软件容错技术包括但不限于:
- 错误检测与处理 :在代码中使用异常处理机制来捕获和处理错误。
- 事务管理 :通过数据库事务确保数据的一致性。
- 服务降级和熔断机制 :在遇到高负载或错误时,系统可以自动降级或暂时切断服务,以避免整个系统的崩溃。
示例代码块 :
try {
// 尝试执行数据库操作
executeDatabaseQuery();
} catch (Exception e) {
// 捕获并处理异常
handleDatabaseError(e);
// 可以考虑记录错误日志
logError(e);
}
在上述Java代码块中, executeDatabaseQuery 方法尝试执行一个数据库查询,如果遇到异常,则会通过 catch 块中的 handleDatabaseError 方法来处理错误,并且记录错误信息到日志中。
3.2.2 软件层面的容错设计案例分析
以下是一个软件层面容错设计的实际案例分析:
服务降级
服务降级是指在系统负载高或服务出现问题时,通过关闭或简化非关键服务来保证核心服务的可用性。例如,在电商系统中,系统可以在流量高峰时关闭用户评论功能,确保商品浏览和购买服务的正常运行。
熔断机制
熔断机制类似于电路中的熔断器。在分布式系统中,如果一个服务节点连续失败,系统会自动断开与该节点的连接,防止故障蔓延到整个系统。
import circuitbreaker
def order_service():
try:
# 尝试调用订单服务
order_info = get_order_info()
return order_info
except Exception as ex:
# 调用失败时触发熔断
circuitbreaker.fail()
raise ex
在上面的Python示例中,我们使用了一个名为 circuitbreaker 的库来实现熔断逻辑。当调用 order_service 函数时,如果发生异常,系统会触发熔断,并抛出异常。
3.2.3 软件容错设计的未来趋势
随着云计算和容器技术的不断发展,软件容错设计越来越倾向于使用服务网格和声明式管理工具。例如,Istio、Linkerd等服务网格能够提供细粒度的流量控制和故障注入等高级容错能力。
3.2.4 软件层面容错设计的挑战和策略
在软件层面实现容错设计面临诸多挑战,其中包括:
- 分布式系统的复杂性 :随着系统规模和复杂性的增加,确保各组件之间的协同和容错变得越来越困难。
- 资源消耗 :容错措施(如冗余和备份)可能会显著增加资源消耗。
- 维持更新和兼容性 :随着软件的不断更新,维护容错策略的兼容性和有效性也是一项持续的挑战。
针对这些挑战,采取的策略可能包括:
- 微服务架构 :通过微服务化,将复杂系统拆分为多个小的、独立的服务,从而降低整体复杂度。
- 自动化测试和持续集成 :通过自动化测试确保新加入或更新的服务不会破坏原有的容错逻辑。
- 监控和日志分析 :使用先进的监控工具和日志分析来实时跟踪系统状态,快速响应可能出现的问题。
通过上述策略,可以有效地在软件层面实现和维护高可用性架构。在设计容错系统时,始终需要牢记,没有一种单一的解决方案可以适用于所有情况。结合硬件和软件层面的容错措施,才能构建出真正强大的高可用性系统。
4. 负载均衡与服务器集群的应用
4.1 负载均衡的作用和方法
4.1.1 负载均衡的基本概念和作用
负载均衡是分布式系统中常用的技术之一,用于将工作负载分配到多个计算资源,如服务器、处理器、网络链路或存储设备。通过负载均衡,可以提高系统的可用性、可靠性和响应速度。负载均衡的作用主要体现在以下几个方面:
- 性能优化 :负载均衡可以分散请求到不同的服务器,避免单个服务器过载,提高响应速度和用户体验。
- 高可用性 :当某个服务器出现问题时,负载均衡器可以将请求重定向到健康的服务器,从而保证服务的连续性。
- 扩展性 :负载均衡支持横向扩展,可以通过增加服务器数量来提高系统处理能力。
4.1.2 负载均衡的实施和优化
实施负载均衡需要选择合适的负载均衡算法和负载均衡器。常见的负载均衡算法包括轮询法、最少连接法、源地址哈希法和URL哈希法等。负载均衡器可以是软件或硬件形式,如Nginx、HAProxy、F5 BIG-IP等。
以下是使用Nginx作为负载均衡器的一个基本配置示例:
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}
参数说明: - upstream 指令用于定义服务器组。 - server 指令列出负载均衡的目标服务器。 - proxy_pass 指令用于将请求转发到上游服务器组。
逻辑分析: - Nginx根据定义的负载均衡策略,将到达80端口的HTTP请求分配给 myapp1 服务器组。 - 这里简单使用轮询策略,Nginx会按顺序将请求平均分配给 srv1.example.com 、 srv2.example.com 和 srv3.example.com 。
4.2 服务器集群的应用和优势
4.2.1 服务器集群的基本概念和作用
服务器集群是一种将多个服务器节点组成一个统一的计算资源池的技术。集群中的每个节点都可以处理请求,从而提高计算能力、可扩展性和容错能力。服务器集群的作用包括:
- 计算能力的增强 :通过节点的协作,集群可以提供比单个服务器更高的计算能力。
- 高可用性保障 :节点的冗余设计保证了即使部分节点失效,整个集群仍能继续提供服务。
- 易于扩展 :当业务量增加时,可以通过增加节点来提升集群性能。
4.2.2 服务器集群的实施和优化
实施服务器集群需要考虑集群的拓扑结构、节点间通信机制和数据一致性。常用的集群技术包括Kubernetes、Docker Swarm、Redis Cluster等。以下是使用Kubernetes集群的一个简单配置示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: myapp:1.0.0
ports:
- containerPort: 8080
逻辑分析: - replicas: 3 表明这个部署将创建3个副本,即集群中将有3个节点运行相同的容器。 - matchLabels 用于选择节点,确保服务负载均衡到每个节点。 - containers 部分定义了容器的镜像和端口信息,Kubernetes将会启动这个镜像,并监听8080端口。
服务器集群的优化可以从多个方面进行,包括但不限于资源调度策略的优化、节点自动扩展机制、负载均衡策略的动态调整等。随着业务需求的变化,持续的优化可以确保集群的高性能和高可用性。
5. 故障检测、恢复与数据备份策略
5.1 自动故障检测与恢复机制
故障是任何系统都无法完全避免的现实,但通过实施有效的故障检测与自动恢复机制,可以最小化故障对服务的影响。自动故障检测机制能够实时监控系统状态,快速识别问题并触发相应的恢复流程,以保证系统高可用性。
自动故障检测与恢复的基本概念和作用
自动故障检测与恢复机制通常包括心跳检测、阈值告警、异常行为分析等技术。心跳检测通过定期发送信号,确认系统组件是否正常运行。一旦检测到心跳信号异常,系统将采取预定的恢复措施,如自动重启服务、切换到备用节点等。
自动故障检测与恢复的实施和优化
在实施故障检测和恢复策略时,首先需要配置监控系统以收集系统状态数据。使用诸如Nagios、Zabbix等开源监控工具,可以对关键指标进行实时监控,并设置相应的阈值和告警规则。
# 示例:使用Nagios检查HTTP服务状态
define service{
use generic-service
host_name localhost
service_description HTTP Service
check_command check_http!-I localhost -p 80 -u /
check_period 24x7
notification_period 24x7
notification_options d,u,r
contact_groups admins
register 0
}
接下来,配置告警系统,当监控到的服务状态不符合预期时,通过邮件、短信或即时通讯工具向管理员发出通知。此外,可以利用脚本自动化恢复流程,例如,下面的bash脚本可以用于重启一个简单的Web服务。
#!/bin/bash
# 检查Web服务状态
if systemctl is-active --quiet httpd.service; then
echo "Web服务正在运行."
else
# 尝试重启服务
systemctl restart httpd.service
# 检查服务是否重启成功
if systemctl is-active --quiet httpd.service; then
echo "Web服务已重启成功."
else
echo "Web服务重启失败,可能需要进一步检查."
fi
fi
5.2 数据备份与恢复的基本概念和作用
数据备份是指将数据从主存储设备复制到其他存储设备的过程。数据恢复则是指在数据丢失或损坏时,通过备份数据将系统恢复到某个可用状态的过程。有效的备份和恢复策略是确保数据持久性和业务连续性的关键。
数据备份与恢复的实施和优化
备份策略通常包括全备份、增量备份和差异备份等技术。全备份是对整个系统进行一次性的完整备份。增量备份只备份自上次任何类型备份以来发生变化的数据,而差异备份则备份自上次全备份以来发生变化的数据。
选择合适的备份工具对于实施备份策略至关重要。常用的备份工具有rsync、Bacula等。下面的示例展示了如何使用rsync进行全备份:
# 定期备份脚本示例
#!/bin/bash
SOURCE_DIR="/path/to/source" # 源目录路径
BACKUP_DIR="/path/to/backup" # 备份目录路径
DATE=$(date +%Y%m%d) # 获取当前日期
rsync -av $SOURCE_DIR $BACKUP_DIR/$DATE/
在数据恢复方面,应当定期进行恢复测试,以验证备份数据的完整性和可用性。此外,应当确保备份数据的安全性,包括对备份数据进行加密和安全存储。
5.3 更新与维护的策略
更新和维护是保持系统稳定运行和安全的重要环节。没有适当的更新与维护策略,系统的漏洞和缺陷可能被利用,导致安全风险或系统故障。
更新与维护的基本概念和作用
更新包括操作系统、软件补丁和应用程序的升级,以修复已知的漏洞和缺陷。维护则包括对系统性能的优化、故障排除以及硬件的升级和替换。
更新与维护的实施和优化
实施更新和维护时,应当遵循最小权限原则,确保更新操作不会对系统正常运行造成影响。更新之前,建议进行详尽的测试,以及使用诸如Ansible、Puppet等配置管理工具进行自动化部署。
# Ansible playbook示例:更新Ubuntu系统
- hosts: all
become: yes
tasks:
- name: 更新软件包索引
apt:
update_cache: yes
cache_valid_time: 3600
- name: 安装所有可用更新
apt:
upgrade: dist
定期进行维护有助于提高系统的整体性能和可靠性,例如,清理不再使用的软件包、优化数据库性能、检查硬件故障等。
5.4 持续监控与性能优化方法
持续监控是确保系统稳定性的基石,而性能优化则是提升用户体验和系统效率的重要手段。两者共同作用于系统的整个生命周期,确保系统能够应对不断变化的工作负载。
持续监控与性能优化的基本概念和作用
持续监控关注于实时跟踪系统的性能指标和健康状况,如CPU使用率、内存消耗、磁盘I/O、网络流量等。性能优化则包括识别性能瓶颈、调整系统配置、优化代码等操作。
持续监控与性能优化的实施和优化
实施持续监控时,可以使用Prometheus结合Grafana进行系统监控。Prometheus负责收集监控数据,而Grafana则用于数据的可视化展示。
graph LR
A[Prometheus] -->|抓取| B[目标系统]
B -->|暴露指标| A
A -->|查询| C[Grafana]
C -->|展示数据| D[仪表板]
在性能优化方面,可以使用sysstat等工具来监控系统性能,并进行调优。此外,优化数据库查询、减少不必要的进程和任务、升级硬件等方法也是常见的性能优化手段。
综上所述,故障检测、恢复机制、数据备份、更新维护以及持续监控和性能优化是确保系统高可用性和稳定运行的五个重要方面。通过实施上述策略,可以最大限度地降低故障发生的风险,并在出现问题时快速响应和恢复。
本文还有配套的精品资源,点击获取
简介:在IT行业中,确保服务器的高可用性对于企业持续运营至关重要。本文介绍了实现永不宕机服务器的关键技术与策略,包括冗余硬件、负载均衡、集群计算、热备与冷备、虚拟化技术、自动故障检测与恢复、数据备份与恢复、更新与维护策略、容错设计以及持续监控与性能优化。通过这些综合解决方案,可以显著提高系统的可用性,减少宕机事件,无限接近永不宕机的目标。
本文还有配套的精品资源,点击获取







