【Linux仓库】Linux内核:深度解剖Makefile如何管理百万行代码?
🌟 各位看官好,我是egoist2023!
🌍 Linux == Linux is not Unix !
🚀 今天来学习make/Makefile知识,让多文件仅通过Makefile就可以生成可执行程序。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦!

背景
- 会不会写makefile,从⼀个侧⾯说明了⼀个⼈是否具备完成⼤型⼯程的能⼒。
- ⼀个⼯程中的源⽂件不计数,其按类型、功能、模块分别放在若⼲个⽬录中,makefile定义了⼀系列的规则来指定,哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,甚⾄于进⾏更复杂的功能操作。
- makefile带来的好处就是⸺“⾃动化编译”,⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率。
- make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具,⼀般来说,⼤多数的IDE都有这个命令,⽐如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可⻅,makefile都成为了⼀种在⼯程⽅⾯的编译⽅法。
- make是⼀条命令,makefile是⼀个⽂件,两个搭配使⽤,完成项⽬⾃动化构建。
理解make/Makefile
make是一个Linux系统内置的命令;
Makefile是一个需要工程师自己建立的的一个文件!
编写代码
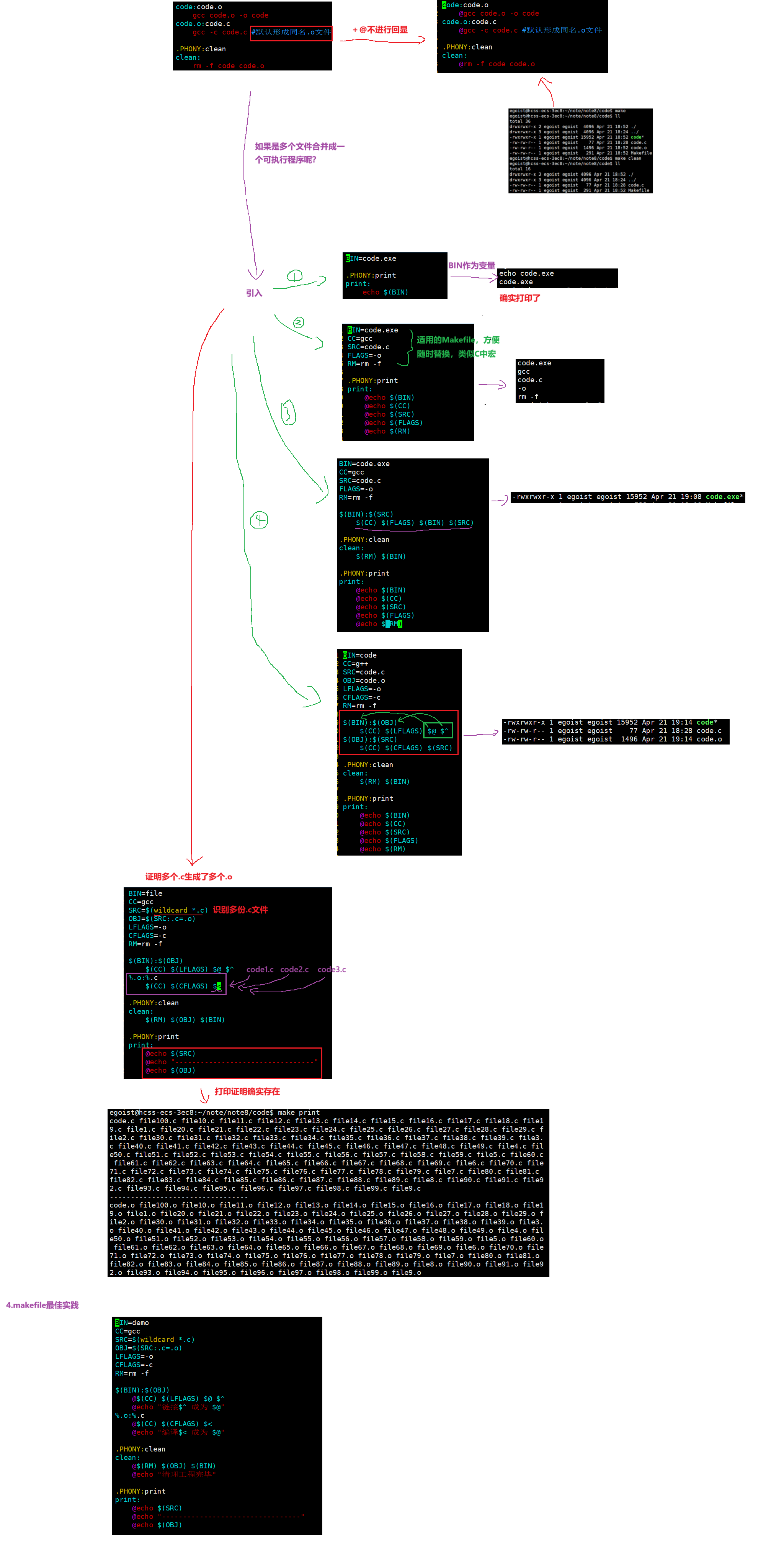
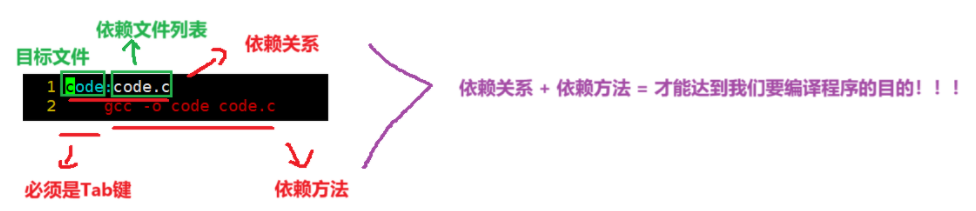
code:code.c
gcc -o code code.c
.PHONY:clean
clean:
rm -f code得到理论
上面这段代码中各自代表什么含义呢?
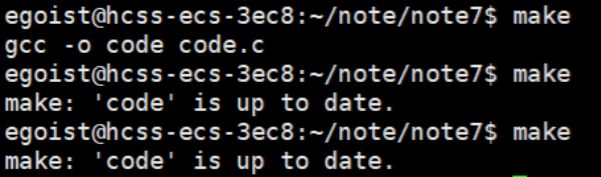

可以看到程序写完后,进行make时第一次没问题,但是多次make后会显示已是最新的,不能重新编译;但我们进行make clean时却可以无限次,这是为啥呢?
- 重复编译是需要耗费时间的,如果多次编译但源代码都是同一份显然是没有必要的;
- clean清除所有的⽬标⽂件,以便重编译,且能多次运行。
可以发现,clean的左边加上了 .PHONY ,这是什么意思呢?
.PHONY表示:被修饰的目标是一个伪目标,且伪目标总是被执行的。
啊?伪目标总是被执行是什么意思呢?由小编带着大家一步步解析。
要理解被执行,我们可以从总是不被执行作为切入点。
上图中多次make不会再次编译,这就是不被执行。那它又是如何做到不被执行的呢?
在指令章节介绍了stat指令,它可以列出一个文件的访问、内容修改、属性修改时间。
- Modify: 内容变更,时间更新
- Change:属性变更,时间更新
- Access:常指的是文件最近一次被访问的时间。在Linux的早期版本中,每当⽂件被访问时,其atime都会更新。但这种机制会导致⼤量的IO操作。(因此可能是多次访问只会修改一次)
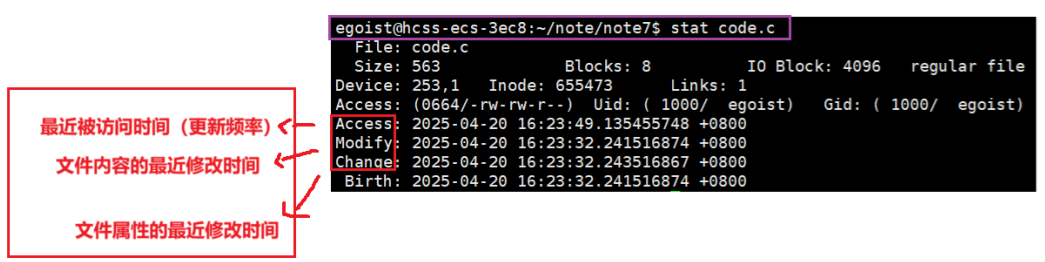
在下图中,我们对一个未修改文件进行修改时,其文件内容最近修改时间发生了变化,此时可以重新make了。
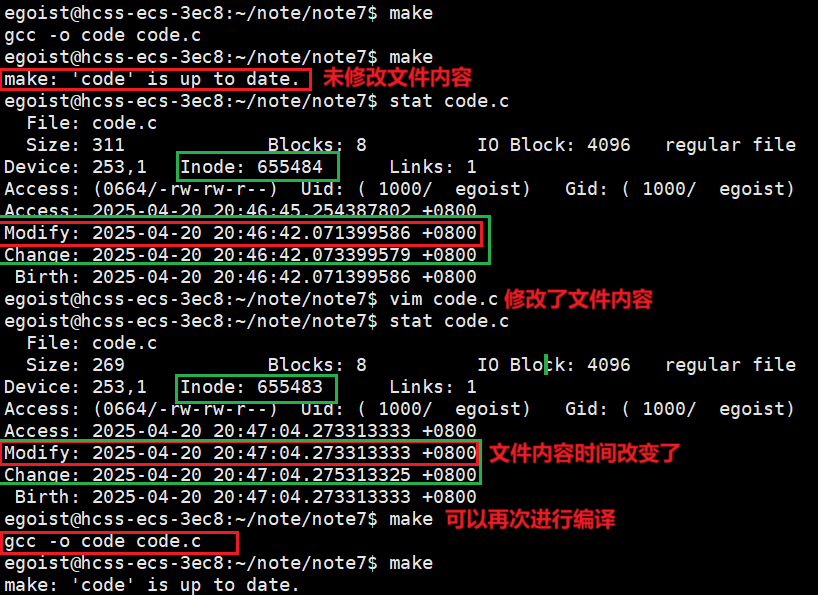
因此,不被执行是根据文件内容最近修改时间与exe时间对比来决定是否需要重新编译 !
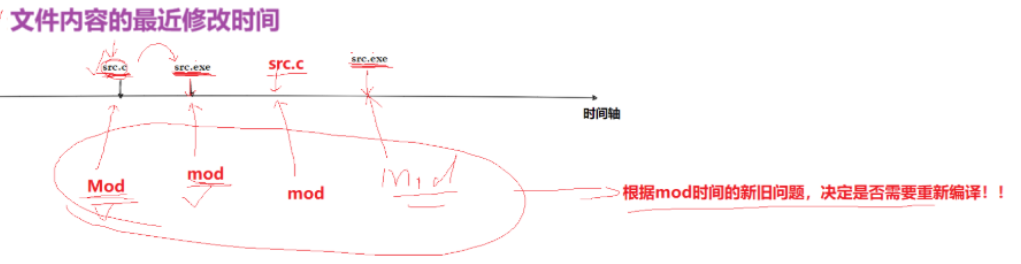 那么,总不被执行即是忽略exe和文件内容最近修改时间对比。
那么,总不被执行即是忽略exe和文件内容最近修改时间对比。
结论:.PHONY:让make忽略源⽂件和可执⾏⽬标⽂件的M时间对⽐!
最佳实践:可执行程序,不需要修饰成.PHONY,clean修饰成总是被执行!
推导过程
上面这种方式是一步到位的,能否像gcc那样生成 .i , .s , .o 的临时文件呢?可以的。
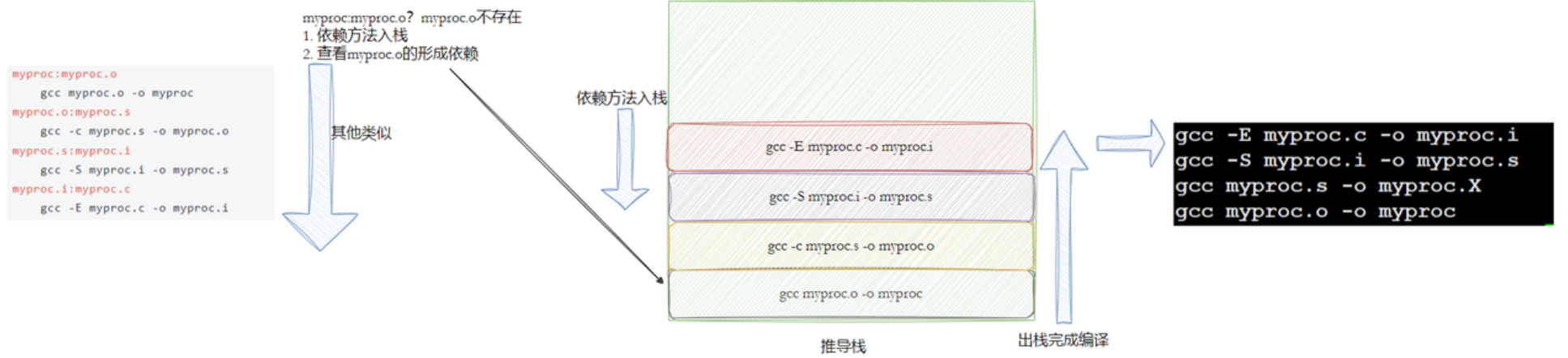
myproc:myproc.o
gcc myproc.o -o myproc
myproc.o:myproc.s
gcc -c myproc.s -o myproc.o
myproc.s:myproc.i
gcc -S myproc.i -o myproc.s
myproc.i:myproc.c
gcc -E myproc.c -o myproc.i
.PHONY:clean
clean:
rm -f *.i *.s *.o myproc根据上面这段程序及make工作规则进行解析:
- make会在当前⽬录下找名字叫“Makefile”或“makefile”的⽂件。
- 如果找到,它会找⽂件中的第⼀个⽬标⽂件(target),在上⾯的例⼦中,他会找到 myproc 这个⽂件,并把这个⽂件作为最终的⽬标⽂件。
- 如果 myproc ⽂件不存在,或是 myproc 所依赖的后⾯的 myproc.o ⽂件的⽂件修改时间要⽐ myproc 这个⽂件新,那么,他就会执⾏后⾯所定义的命令来生成myproc 这个⽂件。
- 如果 myproc 所依赖的 myproc.o ⽂件不存在,那么 make 会在当前⽂件中找⽬标为myproc.o ⽂件的依赖性,如果找到则再根据那⼀个规则⽣成 myproc.o ⽂件。(像⼀个堆栈的过程)
- 这就是整个make的依赖性,make会⼀层⼜⼀层地去找⽂件的依赖关系,直到最终编译出第⼀个⽬标⽂件。
- 在找寻的过程中,如果出现错误,⽐如最后被依赖的⽂件找不到,那么make就会直接退出,并报错,⽽对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管⽂件的依赖性,即如果在我找了依赖关系之后,冒号后⾯的⽂件还是不在,那么对不起,我就不⼯作啦。
简单而言 make/makefile 只默认形成一个目标,就是从上到下遇到的第一个目标,并根据依赖关系寻找,如果没有找到依赖关系就会报错,直到找到源文件为止。
但上面这种方法在实践中并不经常使用,像 .i .s 这种临时文件一般是不需要保留的,在vs上也是这样处理的,只保留 .o文件和 可执行程序。因此Makefile的最佳实践如下所示
code:code.c
gcc -o $@ $^ //$@ 代表:左边部分 $^代表:右边部分
.PHONY:clean
clean:
rm -f code扩展