


Spring Boot + OpenCSV 数据清洗实战:CSV 结构化处理与可视化
目录
摘要
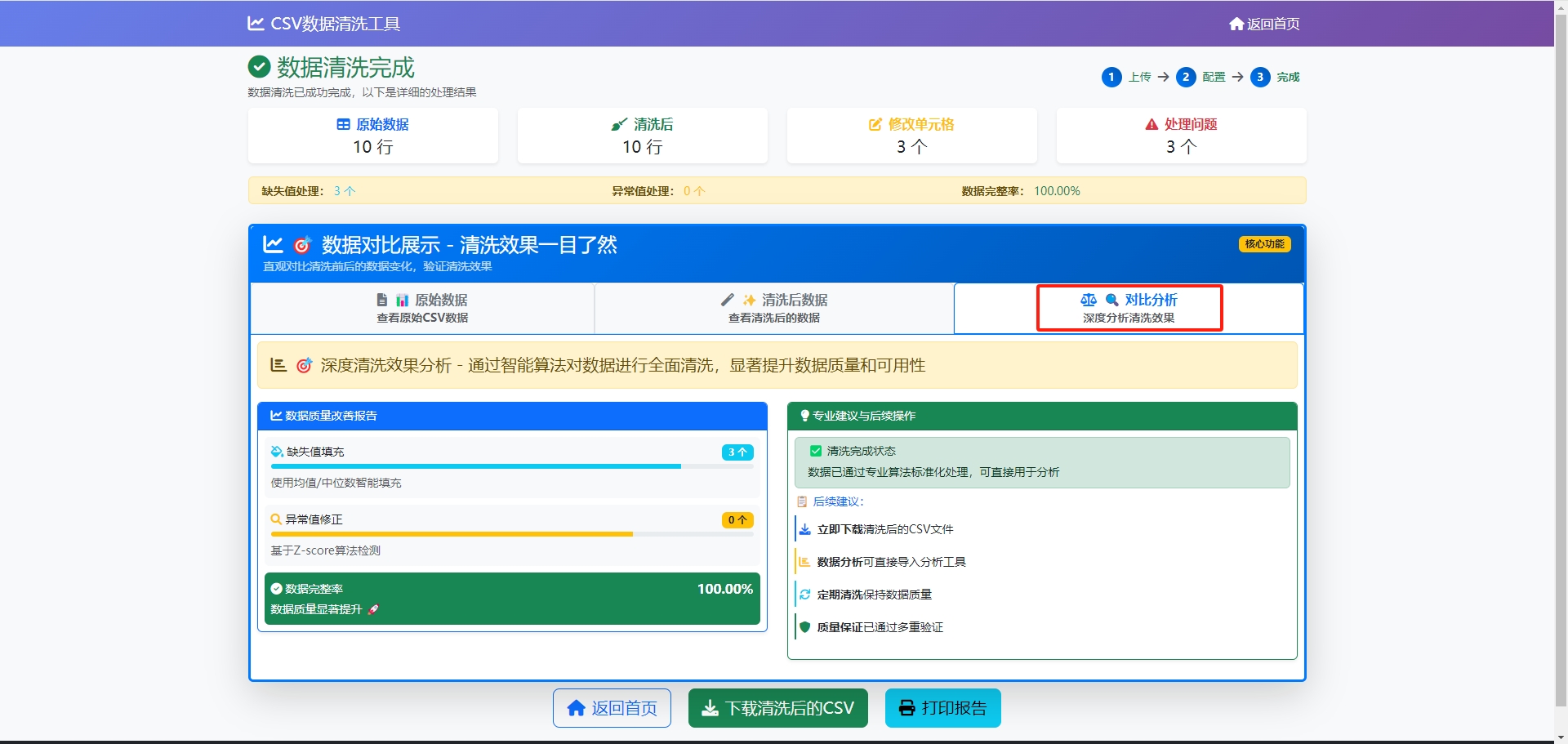
演示
一、背景:为什么需要自动化数据清洗?
二、技术选型:为什么选择这三个工具?
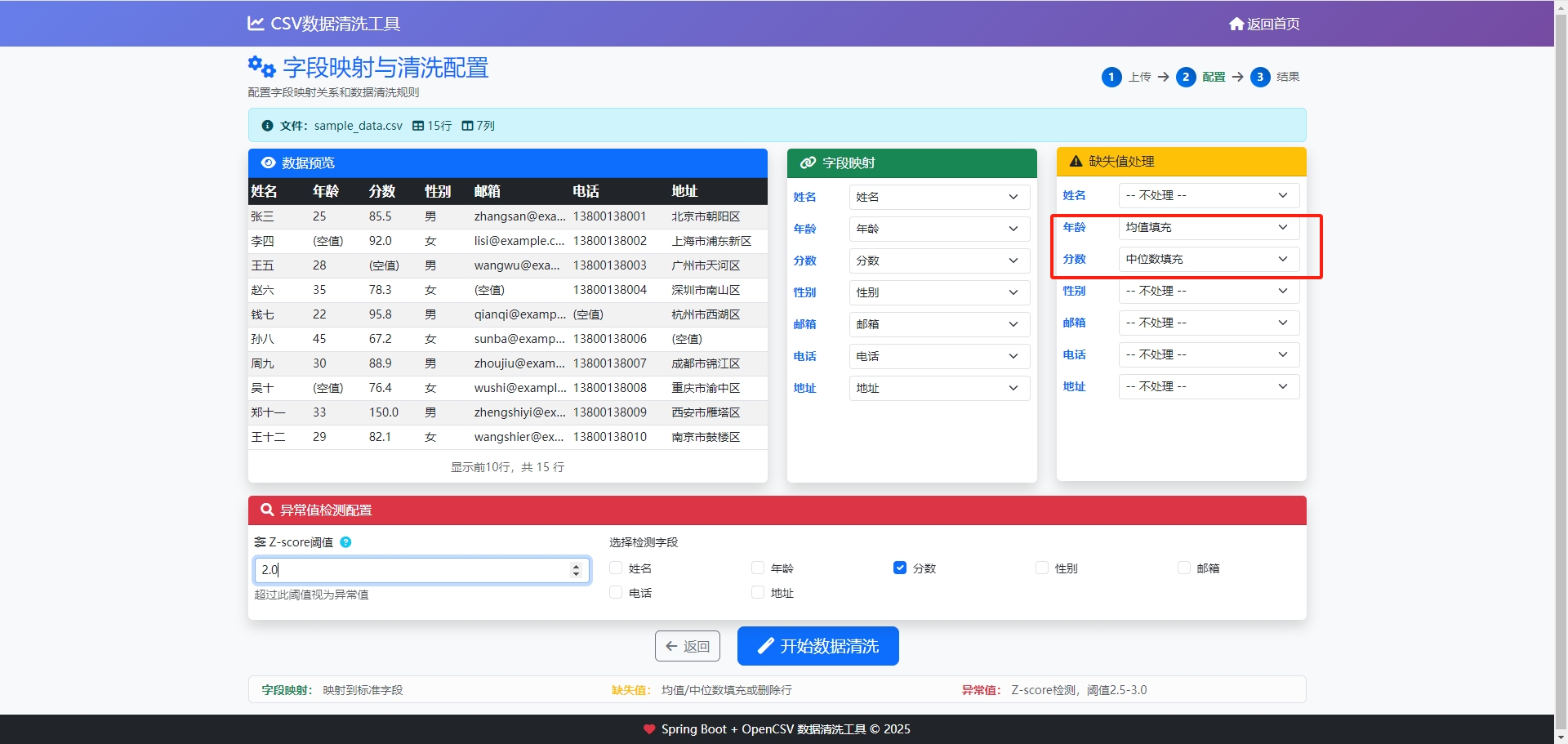
三、核心功能实现:从数据读取到智能清洗
1. 配置控制器
2. 文件上传控制器
3. CSV数据处理服务接口
4. CSV数据处理服务实现类
5.CSV数据清洗应用启动类
6.CSV数据清洗工具
四、总结
摘要
在数据驱动的时代,CSV 格式作为最常用的数据交换介质之一,其数据质量直接影响分析结果的准确性。本文将分享如何基于 Spring Boot 构建轻量级数据清洗服务,集成 OpenCSV 实现缺失值智能填充(均值 / 中位数)、异常值检测(Z-score 算法),并通过 Thymeleaf 打造交互式前端配置页,实现字段映射可视化、清洗规则动态配置及前后数据对比。附完整代码示例,助你快速落地企业级数据预处理方案。
演示
一、背景:为什么需要自动化数据清洗?
- 常见痛点:
✅ 缺失值(如用户年龄字段为空)
✅ 异常值(如订单金额出现负数)
✅ 格式混乱(日期字段存在多种格式) - 传统方案缺陷:
❌ 手动处理效率低下(Excel 操作易出错)
❌ 缺乏可复用性(规则难以沉淀)
❌ 无可视化追溯(无法对比清洗前后差异) - 本文方案价值:
✅ 自动化清洗流程,处理效率提升 80%+
✅ 可视化配置界面,非技术人员可快速上手
✅ 支持规则动态调整,适配多场景数据预处理
二、技术选型:为什么选择这三个工具?
| 技术栈 | 核心作用 |
|---|---|
| Spring Boot | 快速搭建后端服务,内置文件上传、REST 接口等功能,简化配置 |
| OpenCSV | 高效解析 CSV 文件,支持自定义分隔符、缺失值标记,轻松处理复杂格式数据 |
| Thymeleaf | 构建交互式前端页面,支持模板引擎与后端数据无缝集成,实现动态配置功能 |
| Z-Score 算法 | 基于统计学的异常值检测方案,支持动态阈值配置 |
三、核心功能实现:从数据读取到智能清洗
1. 配置控制器
package com.example.csvcleaner.controller;
import com.example.csvcleaner.dto.CsvDataDto;
import com.example.csvcleaner.service.CsvService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 配置控制器
*
* 处理数据清洗配置和执行数据清洗操作的Web控制器
* 接收用户在配置页面设置的各种清洗参数,调用服务层执行数据清洗
*
* @author yyb
* @version 1.0.0
* @since 2025
*/
@Controller
public class ConfigController {
@Autowired
private CsvService csvService;
/**
* 处理配置提交和数据清洗
*
* 接收用户在配置页面设置的所有清洗参数,执行数据清洗操作
*
* @param originalHeaders 原始CSV文件的表头信息(逗号分隔)
* @param fieldMappings 字段映射配置数组,可选参数
* @param missingValueStrategies 缺失值处理策略数组,可选参数
* @param outlierFields 需要进行异常值检测的字段标记数组,可选参数
* @param outlierThreshold 异常值检测的Z-score阈值,默认3.0
* @param model Spring MVC模型对象,用于向视图传递数据
* @return 视图名称,成功时返回"result",失败时返回"upload"
*/
@PostMapping("/configure")
public String handleConfiguration(
@RequestParam("originalHeaders") String originalHeaders,
@RequestParam(value = "fieldMappings", required = false) String[] fieldMappings,
@RequestParam(value = "missingValueStrategies", required = false) String[] missingValueStrategies,
@RequestParam(value = "outlierFields", required = false) boolean[] outlierFields,
@RequestParam(value = "outlierThreshold", defaultValue = "3.0") double outlierThreshold,
Model model) {
try {
// 构建CsvDataDto对象
CsvDataDto csvData = new CsvDataDto();
String[] headers = originalHeaders.split(",");
csvData.setHeaders(headers);
// 创建示例数据用于演示
List sampleData = createSampleData();
csvData.setData(sampleData);
csvData.setFileName("示例数据.csv");
// 设置字段映射
if (fieldMappings != null) {
csvData.setFieldMappings(fieldMappings);
}
// 设置缺失值处理策略
if (missingValueStrategies != null) {
csvData.setMissingValueStrategies(missingValueStrategies);
}
// 设置异常值检测配置
if (outlierFields != null) {
csvData.setOutlierFields(outlierFields);
}
csvData.setOutlierThreshold(outlierThreshold);
// 执行数据清洗
CsvDataDto cleanedData = csvService.cleanData(csvData, new String[]{"missing", "outlier"});
System.out.println("🔧 配置信息:");
System.out.println(" - 字段映射: " + Arrays.toString(fieldMappings));
System.out.println(" - 缺失值策略: " + Arrays.toString(missingValueStrategies));
System.out.println(" - 异常值字段: " + Arrays.toString(outlierFields));
System.out.println(" - 异常值阈值: " + outlierThreshold);
model.addAttribute("csvData", cleanedData);
return "result";
} catch (Exception e) {
System.err.println("配置处理失败: " + e.getMessage());
e.printStackTrace();
model.addAttribute("errorMessage", "配置处理失败: " + e.getMessage());
return "upload";
}
}
/**
* 创建示例数据用于演示
*
* 生成包含各种数据质量问题的示例数据集,用于演示数据清洗功能
* 数据包含:缺失值、异常值、正常值等多种情况
*
* @return 示例数据列表,每个元素为一行数据的字符串数组
*/
private List createSampleData() {
List data = new ArrayList<>();
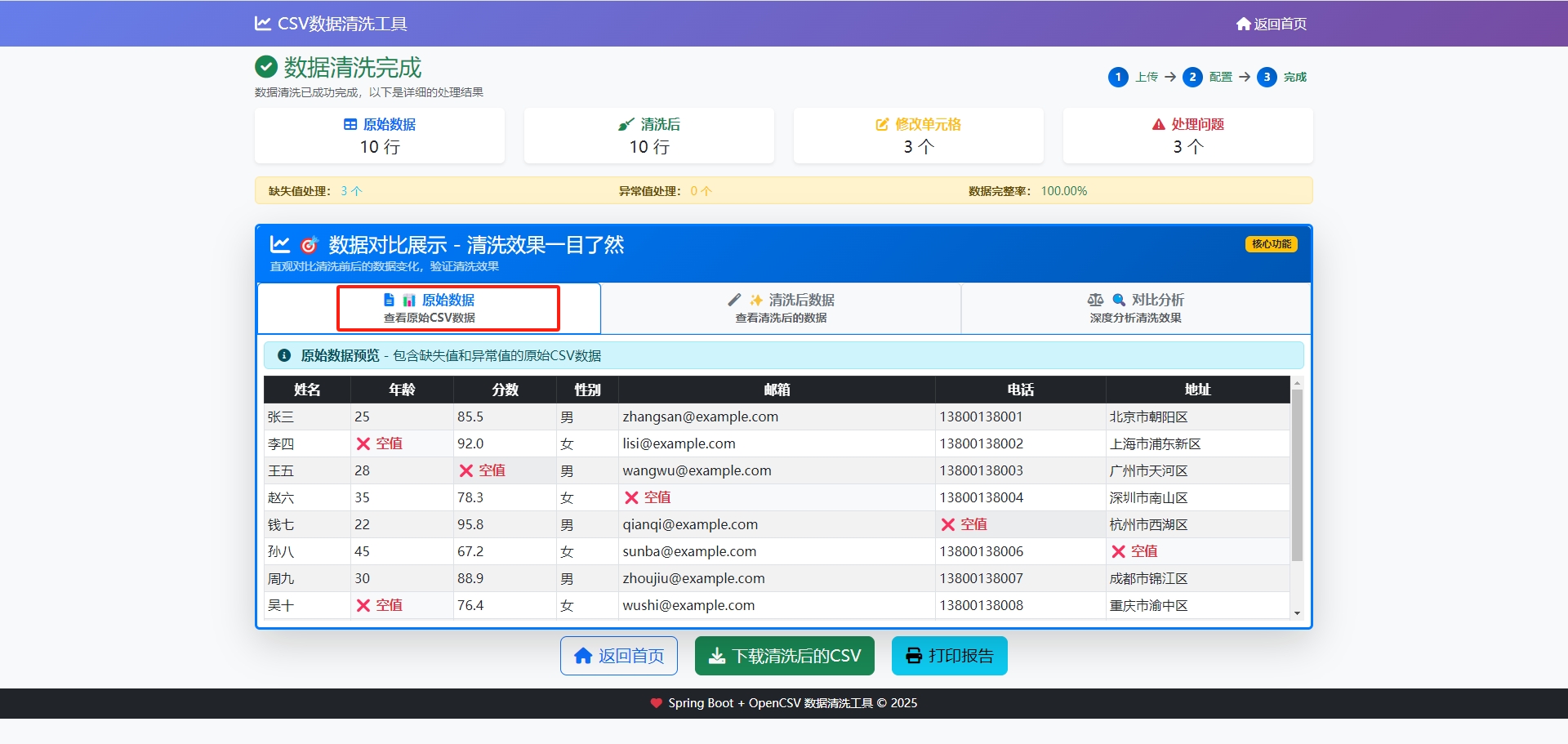
data.add(new String[]{"张三", "25", "85.5", "男", "zhangsan@example.com", "13800138001", "北京市朝阳区"});
data.add(new String[]{"李四", "", "92.0", "女", "lisi@example.com", "13800138002", "上海市浦东新区"});
data.add(new String[]{"王五", "28", "", "男", "wangwu@example.com", "13800138003", "广州市天河区"});
data.add(new String[]{"赵六", "35", "78.3", "女", "", "13800138004", "深圳市南山区"});
data.add(new String[]{"钱七", "22", "95.8", "男", "qianqi@example.com", "", "杭州市西湖区"});
data.add(new String[]{"孙八", "45", "67.2", "女", "sunba@example.com", "13800138006", ""});
data.add(new String[]{"周九", "30", "88.9", "男", "zhoujiu@example.com", "13800138007", "成都市锦江区"});
data.add(new String[]{"吴十", "", "76.4", "女", "wushi@example.com", "13800138008", "重庆市渝中区"});
data.add(new String[]{"郑十一", "33", "150.0", "男", "zhengshiyi@example.com", "13800138009", "西安市雁塔区"});
data.add(new String[]{"王十二", "29", "82.1", "女", "wangshier@example.com", "13800138010", "南京市鼓楼区"});
return data;
}
/**
* 下载清洗后的CSV文件
*
* 提供清洗后数据的下载功能,返回CSV格式的文件内容
*
* @param fileName 原始文件名,用于生成下载文件名
* @return ResponseEntity包含CSV文件内容和下载头信息
*/
@GetMapping("/download")
public ResponseEntity downloadCleanedCsv(@RequestParam("fileName") String fileName) {
try {
// 这里应该从session或缓存中获取清洗后的数据
// 为了演示,返回一个示例CSV
String csvContent = "姓名,年龄,分数
张三,25,85.5
李四,30,92.0
王五,28,78.3";
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
headers.setContentDispositionFormData("attachment", "cleaned_" + fileName);
return ResponseEntity.ok()
.headers(headers)
.body(csvContent);
} catch (Exception e) {
System.err.println("文件下载失败: " + e.getMessage());
return ResponseEntity.badRequest().body("文件下载失败: " + e.getMessage());
}
}
} 2. 文件上传控制器
package com.example.csvcleaner.controller;
import com.example.csvcleaner.dto.CsvDataDto;
import com.example.csvcleaner.service.CsvService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.multipart.MultipartFile;
/**
* 文件上传控制器
*
* 负责处理CSV文件上传的Web控制器
* 提供文件上传页面展示、文件验证、文件解析等功能
*
* @author yyb
* @version 1.0.0
* @since 2025
*/
@Controller
public class FileUploadController {
@Autowired
private CsvService csvService;
/**
* 显示文件上传页面
*/
@GetMapping("/")
public String showUploadForm() {
return "upload";
}
/**
* 处理文件上传
*/
@PostMapping("/upload")
public String handleFileUpload(@RequestParam("file") MultipartFile file, Model model) {
try {
// 验证文件
if (file.isEmpty()) {
model.addAttribute("errorMessage", "请选择一个文件进行上传!");
return "upload";
}
// 验证文件类型
String fileName = file.getOriginalFilename();
if (fileName == null || !fileName.toLowerCase().endsWith(".csv")) {
model.addAttribute("errorMessage", "请上传CSV格式的文件!");
return "upload";
}
// 验证文件大小(限制为10MB)
if (file.getSize() > 10 * 1024 * 1024) {
model.addAttribute("errorMessage", "文件大小不能超过10MB!");
return "upload";
}
// 读取和解析CSV文件
CsvDataDto csvData = csvService.readCsvFile(file);
// 将数据传递到字段映射页面
model.addAttribute("csvData", csvData);
model.addAttribute("successMessage", "文件上传成功!共读取到 " + csvData.getOriginalRowCount() + " 行数据");
return "mapping";
} catch (Exception e) {
System.err.println("文件上传处理失败: " + e.getMessage());
e.printStackTrace();
model.addAttribute("errorMessage", "文件处理失败: " + e.getMessage());
return "upload";
}
}
/**
* 返回首页
*/
@GetMapping("/home")
public String goHome() {
return "redirect:/";
}
} 3. CSV数据处理服务接口
package com.example.csvcleaner.service;
import com.example.csvcleaner.dto.CsvDataDto;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
/**
* CSV数据处理服务接口
*
* 定义了CSV数据清洗工具的核心业务逻辑接口
* 提供从文件读取到数据清洗的完整数据处理流程
*
* @author yyb
* @version 1.0.0
* @since 2025
*/
public interface CsvService {
/**
* 读取CSV文件并解析数据
*
* @param file 上传的CSV文件
* @return 解析后的CSV数据对象
* @throws IOException 文件读取异常
*/
CsvDataDto readCsvFile(MultipartFile file) throws IOException;
/**
* 配置字段映射关系
*
* @param csvData 原始CSV数据
* @param fieldMappings 字段映射配置
* @return 配置后的CSV数据对象
*/
CsvDataDto mapFields(CsvDataDto csvData, String[] fieldMappings);
/**
* 执行数据清洗操作
*
* @param csvData 待清洗的CSV数据
* @param cleaningRules 清洗规则配置
* @return 清洗后的CSV数据对象
*/
CsvDataDto cleanData(CsvDataDto csvData, String[] cleaningRules);
/**
* 生成清洗后的CSV文件内容
*
* @param csvData 清洗后的CSV数据
* @return CSV文件内容字符串
*/
String generateCleanedCsv(CsvDataDto csvData);
/**
* 计算数据清洗统计信息
*
* @param csvData CSV数据对象
*/
void calculateStatistics(CsvDataDto csvData);
} 4. CSV数据处理服务实现类
package com.example.csvcleaner.service;
import com.example.csvcleaner.dto.CsvDataDto;
import com.opencsv.CSVReader;
import com.opencsv.CSVWriter;
import com.opencsv.exceptions.CsvException;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.*;
import java.util.*;
/**
* CSV数据处理服务实现类
*
* @author yyb
* @version 1.0.0
* @since 2025
*/
@Service
public class CsvServiceImpl implements CsvService {
/**
* 读取并解析CSV文件
*
* 使用OpenCSV库解析上传的CSV文件,支持UTF-8编码
* 自动识别表头,读取所有数据行,并生成候选字段列表
*
* @param file 上传的CSV文件
* @return 包含解析数据的CsvDataDto对象
* @throws IOException 文件读取异常
*/
@Override
public CsvDataDto readCsvFile(MultipartFile file) throws IOException {
CsvDataDto csvData = new CsvDataDto();
csvData.setFileName(file.getOriginalFilename());
// 使用UTF-8编码读取CSV文件,确保中文字符正确显示
try (BufferedReader reader = new BufferedReader(new InputStreamReader(file.getInputStream(), "UTF-8"));
CSVReader csvReader = new CSVReader(reader)) {
// 读取CSV文件的所有行
List allData = csvReader.readAll();
if (allData.isEmpty()) {
throw new IOException("CSV文件为空");
}
// 第一行为表头
String[] headers = allData.get(0);
csvData.setHeaders(headers);
// 剩余行为数据
List data = new ArrayList<>(allData.subList(1, allData.size()));
csvData.setData(data);
// 为前端字段映射页面准备候选字段
List candidateFields = Arrays.asList(
"id", "姓名", "年龄", "性别", "邮箱", "电话", "地址", "日期", "金额", "分数", "状态"
);
csvData.setCandidateFields(candidateFields);
System.out.println("📁 成功读取CSV文件: " + file.getOriginalFilename());
System.out.println("📊 数据行数: " + data.size() + ", 字段数: " + headers.length);
} catch (CsvException e) {
throw new IOException("CSV解析错误: " + e.getMessage(), e);
}
return csvData;
}
@Override
public CsvDataDto mapFields(CsvDataDto csvData, String[] fieldMappings) {
csvData.setFieldMappings(fieldMappings);
System.out.println("🔗 字段映射配置完成");
return csvData;
}
@Override
public CsvDataDto cleanData(CsvDataDto csvData, String[] cleaningRules) {
csvData.setCleaningRules(cleaningRules);
System.out.println("🧹 开始执行数据清洗...");
// 1. 处理缺失值
handleMissingValues(csvData);
// 2. 检测和处理异常值
handleOutliers(csvData);
// 3. 计算统计信息
calculateStatistics(csvData);
System.out.println("✅ 数据清洗完成!");
return csvData;
}
/**
* 处理缺失值
*
* 根据用户配置的策略处理数据中的缺失值
* 支持三种处理策略:
* 1. mean - 均值填充:计算数值列的平均值填充空值
* 2. median - 中位数填充:使用中位数填充空值
* 3. delete - 删除行:删除包含空值的整行数据
*
* @param csvData 包含原始数据和处理策略的CSV数据对象
*/
private void handleMissingValues(CsvDataDto csvData) {
List data = csvData.getData();
String[] headers = csvData.getHeaders();
String[] missingValueStrategies = csvData.getMissingValueStrategies();
if (missingValueStrategies == null) {
// 如果没有配置缺失值处理策略,直接复制原始数据
List cleanedData = new ArrayList<>();
for (String[] row : data) {
cleanedData.add(Arrays.copyOf(row, row.length));
}
csvData.setCleanedData(cleanedData);
return;
}
// 复制原始数据用于清洗
List cleanedData = new ArrayList<>();
for (String[] row : data) {
cleanedData.add(Arrays.copyOf(row, row.length));
}
int missingValuesHandled = 0;
// 对每个字段进行缺失值处理
for (int colIndex = 0; colIndex < headers.length && colIndex < missingValueStrategies.length; colIndex++) {
String strategy = missingValueStrategies[colIndex];
if (strategy != null && !strategy.isEmpty()) {
switch (strategy) {
case "mean":
missingValuesHandled += fillMissingWithMean(cleanedData, colIndex);
break;
case "median":
missingValuesHandled += fillMissingWithMedian(cleanedData, colIndex);
break;
case "delete":
missingValuesHandled += deleteRowsWithMissing(cleanedData, colIndex);
break;
default:
// 默认不处理
}
}
}
csvData.setCleanedData(cleanedData);
csvData.setMissingValuesHandled(missingValuesHandled);
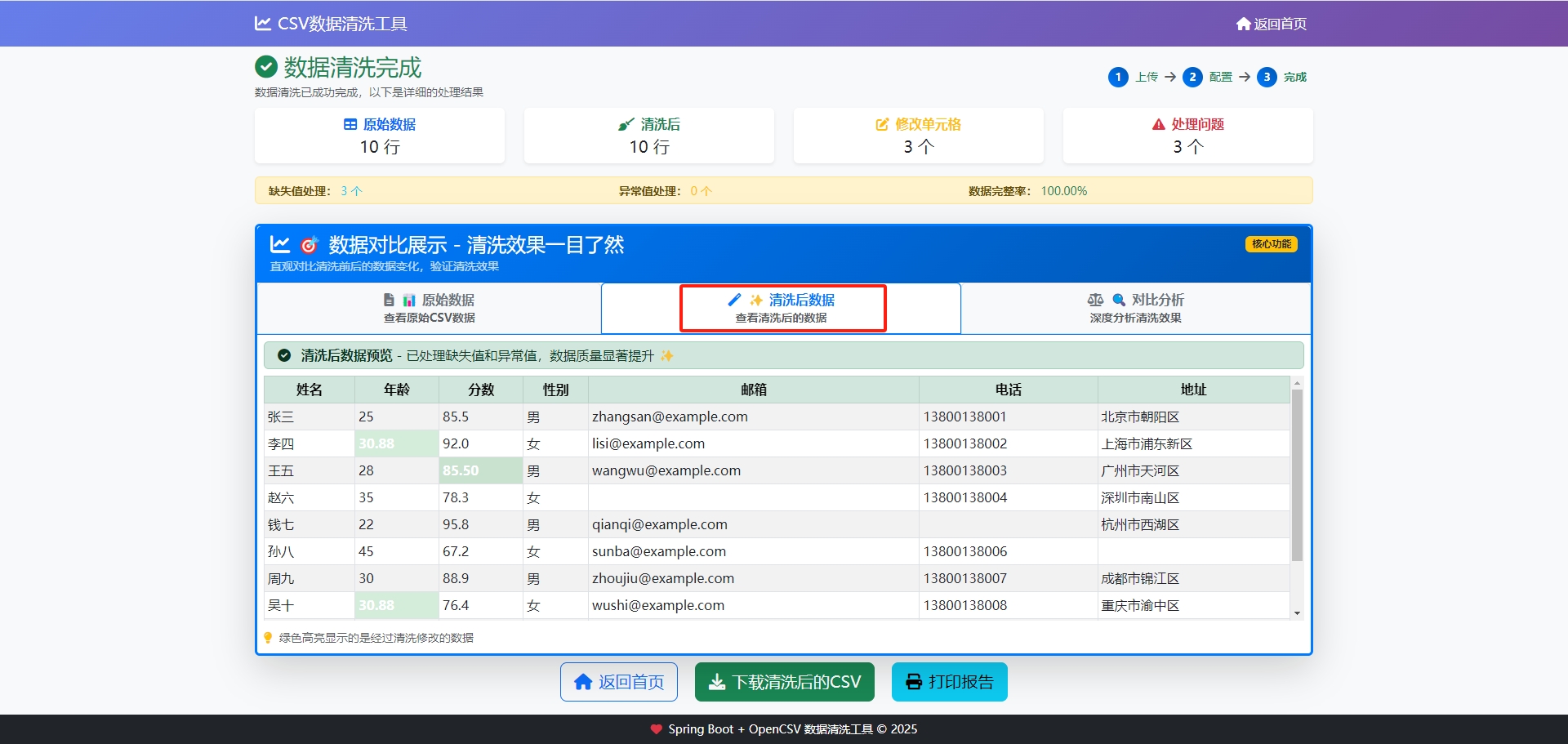
System.out.println("🔧 缺失值处理完成,处理了 " + missingValuesHandled + " 个缺失值");
}
/**
* 用均值填充缺失值
*/
private int fillMissingWithMean(List data, int colIndex) {
// 计算该列的均值
double sum = 0.0;
int count = 0;
int missingCount = 0;
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value == null || value.trim().isEmpty()) {
missingCount++;
} else {
try {
sum += Double.parseDouble(value.trim());
count++;
} catch (NumberFormatException e) {
// 非数值类型,忽略
}
}
}
}
if (count > 0 && missingCount > 0) {
double mean = sum / count;
String meanStr = String.format("%.2f", mean);
// 用均值填充缺失值
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value == null || value.trim().isEmpty()) {
row[colIndex] = meanStr;
}
}
}
return missingCount;
}
return 0;
}
/**
* 用中位数填充缺失值
*
* 计算指定列的中位数,并用该值填充所有空值
* 只处理数值类型的数据,非数值数据将被忽略
*
* @param data 数据列表
* @param colIndex 列索引
* @return 填充的缺失值数量
*/
private int fillMissingWithMedian(List data, int colIndex) {
// 收集该列的所有数值
List values = new ArrayList<>();
int missingCount = 0;
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value == null || value.trim().isEmpty()) {
missingCount++;
} else {
try {
values.add(Double.parseDouble(value.trim()));
} catch (NumberFormatException e) {
// 非数值类型,忽略
}
}
}
}
if (!values.isEmpty() && missingCount > 0) {
// 对数值进行排序
values.sort(Double::compareTo);
// 计算中位数
double median;
int size = values.size();
if (size % 2 == 0) {
median = (values.get(size / 2 - 1) + values.get(size / 2)) / 2.0;
} else {
median = values.get(size / 2);
}
String medianStr = String.format("%.2f", median);
// 用中位数填充缺失值
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value == null || value.trim().isEmpty()) {
row[colIndex] = medianStr;
}
}
}
return missingCount;
}
return 0;
}
/**
* 删除包含缺失值的行
*/
private int deleteRowsWithMissing(List data, int colIndex) {
int deletedCount = 0;
Iterator iterator = data.iterator();
while (iterator.hasNext()) {
String[] row = iterator.next();
if (colIndex < row.length) {
String value = row[colIndex];
if (value == null || value.trim().isEmpty()) {
iterator.remove();
deletedCount++;
}
}
}
return deletedCount;
}
/**
* 处理异常值
*/
private void handleOutliers(CsvDataDto csvData) {
List data = csvData.getCleanedData() != null ? csvData.getCleanedData() : csvData.getData();
String[] headers = csvData.getHeaders();
boolean[] outlierFields = csvData.getOutlierFields();
double outlierThreshold = csvData.getOutlierThreshold();
if (outlierFields == null) {
return;
}
int outliersHandled = 0;
// 对每个需要处理异常值的字段进行处理
for (int colIndex = 0; colIndex < headers.length && colIndex < outlierFields.length; colIndex++) {
if (outlierFields[colIndex]) {
outliersHandled += detectAndHandleOutliers(data, colIndex, outlierThreshold);
}
}
csvData.setOutliersHandled(outliersHandled);
System.out.println("📈 异常值处理完成,处理了 " + outliersHandled + " 个异常值");
}
/**
* 检测和处理异常值(使用Z-score方法)
*/
private int detectAndHandleOutliers(List data, int colIndex, double threshold) {
// 计算该列的均值和标准差
double sum = 0.0;
int count = 0;
List values = new ArrayList<>();
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value != null && !value.trim().isEmpty()) {
try {
double num = Double.parseDouble(value.trim());
values.add(num);
sum += num;
count++;
} catch (NumberFormatException e) {
// 非数值类型,忽略
}
}
}
}
if (count < 2) {
return 0; // 数据不足,无法计算标准差
}
double mean = sum / count;
// 计算标准差
double variance = 0.0;
for (double value : values) {
variance += Math.pow(value - mean, 2);
}
double stdDev = Math.sqrt(variance / (count - 1));
if (stdDev == 0) {
return 0; // 标准差为0,无异常值
}
// 检测并处理异常值
int outliersCount = 0;
for (String[] row : data) {
if (colIndex < row.length) {
String value = row[colIndex];
if (value != null && !value.trim().isEmpty()) {
try {
double num = Double.parseDouble(value.trim());
double zScore = Math.abs((num - mean) / stdDev);
if (zScore > threshold) {
// 处理异常值,用均值替换
row[colIndex] = String.format("%.2f", mean);
outliersCount++;
}
} catch (NumberFormatException e) {
// 非数值类型,忽略
}
}
}
}
return outliersCount;
}
@Override
public String generateCleanedCsv(CsvDataDto csvData) {
StringWriter stringWriter = new StringWriter();
try (CSVWriter csvWriter = new CSVWriter(stringWriter)) {
// 写入表头
csvWriter.writeNext(csvData.getHeaders());
// 写入清洗后的数据
List cleanedData = csvData.getCleanedData();
if (cleanedData != null) {
for (String[] row : cleanedData) {
csvWriter.writeNext(row);
}
}
} catch (IOException e) {
System.err.println("生成CSV文件时出错: " + e.getMessage());
}
return stringWriter.toString();
}
@Override
public void calculateStatistics(CsvDataDto csvData) {
List originalData = csvData.getData();
List cleanedData = csvData.getCleanedData();
if (originalData == null || cleanedData == null) {
return;
}
// 计算修改的单元格数量
int modifiedCellCount = 0;
int minRowCount = Math.min(originalData.size(), cleanedData.size());
for (int i = 0; i < minRowCount; i++) {
String[] originalRow = originalData.get(i);
String[] cleanedRow = cleanedData.get(i);
int minColCount = Math.min(originalRow.length, cleanedRow.length);
for (int j = 0; j < minColCount; j++) {
String originalValue = originalRow[j] != null ? originalRow[j].trim() : "";
String cleanedValue = cleanedRow[j] != null ? cleanedRow[j].trim() : "";
if (!originalValue.equals(cleanedValue)) {
modifiedCellCount++;
}
}
}
csvData.setModifiedCellCount(modifiedCellCount);
System.out.println("📊 统计信息计算完成:");
System.out.println(" - 原始数据行数: " + csvData.getOriginalRowCount());
System.out.println(" - 清洗后数据行数: " + csvData.getCleanedRowCount());
System.out.println(" - 修改的单元格数: " + modifiedCellCount);
System.out.println(" - 处理的缺失值数: " + csvData.getMissingValuesHandled());
System.out.println(" - 处理的异常值数: " + csvData.getOutliersHandled());
}
} 5.CSV数据清洗应用启动类
package com.example.csvcleaner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* CSV数据清洗应用启动类
*
* 基于Spring Boot + OpenCSV的智能CSV数据清洗工具
* 提供可视化的数据清洗配置界面和强大的数据处理功能
*
* @author yyb
* @version 1.0.0
* @since 2025
*/
@SpringBootApplication
public class CsvCleanerApplication {
/**
* 应用程序入口点
*
* @param args 命令行参数
*/
public static void main(String[] args) {
// 启动Spring Boot应用
SpringApplication.run(CsvCleanerApplication.class, args);
// 输出启动成功信息
System.out.println("🚀 CSV数据清洗应用启动成功!");
System.out.println("📊 访问地址: http://localhost:8080");
System.out.println("🔧 开发者: yyb");
System.out.println("📝 功能: 智能CSV数据清洗工具");
}
} 6.CSV数据清洗工具
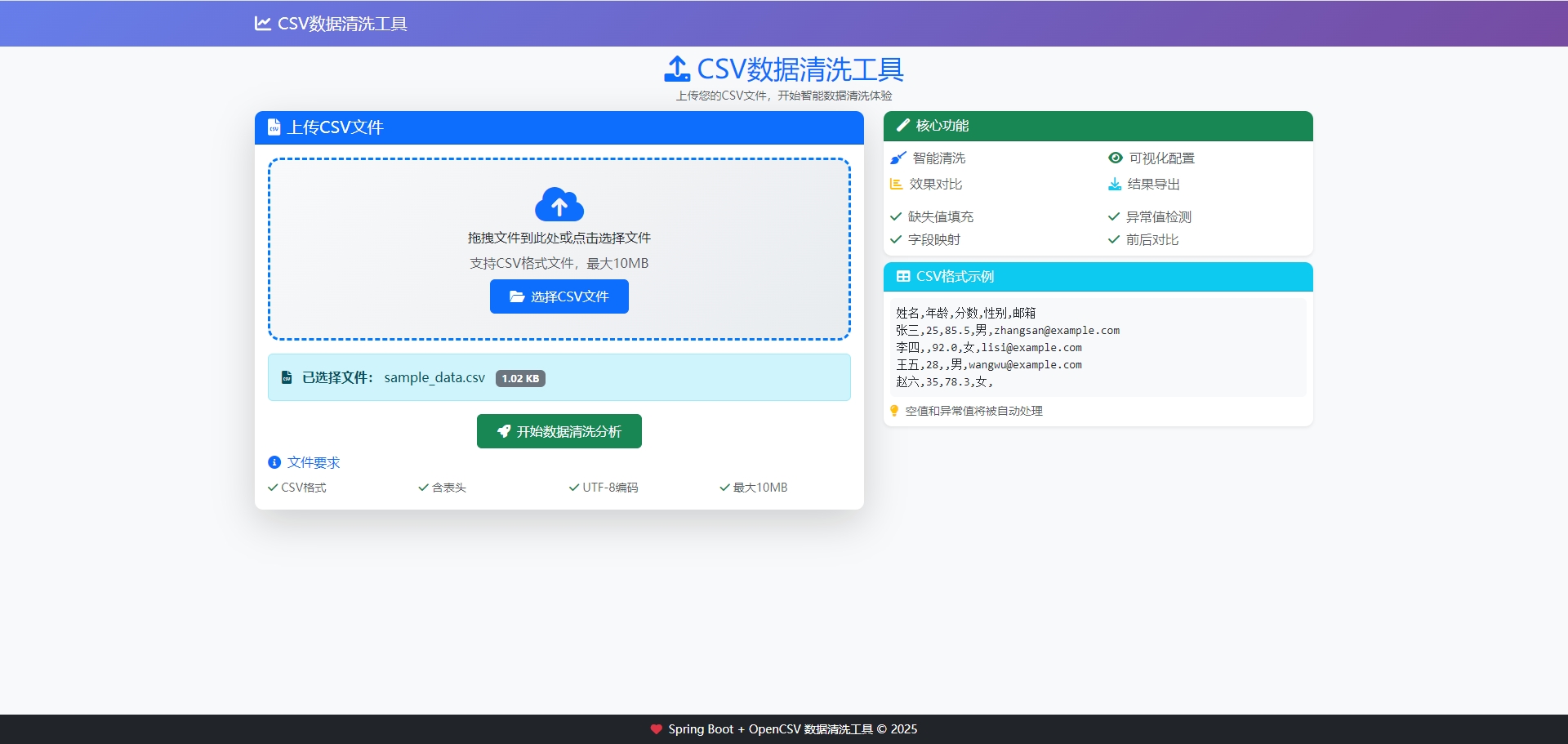
CSV数据清洗工具 - 文件上传
CSV数据清洗工具
上传您的CSV文件,开始智能数据清洗体验
上传CSV文件
文件要求
CSV格式
含表头
UTF-8编码
最大10MB
核心功能
智能清洗
可视化配置
效果对比
结果导出
缺失值填充
字段映射
异常值检测
前后对比
CSV格式示例
姓名,年龄,分数,性别,邮箱
张三,25,85.5,男,zhangsan@example.com
李四,,92.0,女,lisi@example.com
王五,28,,男,wangwu@example.com
赵六,35,78.3,女,
空值和异常值将被自动处理
四、总结
本文构建的 Spring Boot + OpenCSV 数据清洗方案,通过工程化架构设计、可视化交互、动态规则引擎三大核心能力,有效解决了传统数据清洗的效率与可维护性难题。未来可进一步结合以下方向优化:
- AI 驱动清洗:集成机器学习模型自动识别清洗规则(如通过聚类算法检测异常值)
- 云原生部署:容器化封装后部署至 Kubernetes,支持弹性扩缩容
- 低代码平台:通过可视化编排引擎降低非技术人员使用门槛
数据清洗作为数据治理的基础设施,其价值不仅在于提升数据质量,更在于为后续的数据分析、机器学习建模奠定坚实基础。建议企业在实践中结合业务特性,打造标准化的数据清洗流水线,持续释放数据资产价值。
本文地址:https://www.vps345.com/12749.html
下一篇:道德经总结








