


【Linux】进程的地址空间
思维导图

学习内容
地址是一个很重要的名词,我们的每一个进程在内存中运行都会有若干个地址。在之前我们学习进程的时候,学过一个函数——fork(),这个函数仅仅被调用一次,却能够返回两次。这是为什么呢?那么这一篇博客将会解释这种现象——进程的地址空间。
学习目标
- 通过一些奇怪的现象来引入进程的地址空间
- 进程地址空间的概念
- 地址空间的理解
- 为什么要有地址空间
- 如何理解虚拟地址
- Linux的调度算法
一、进程地址空间的引入
1.1 一个奇怪的现象
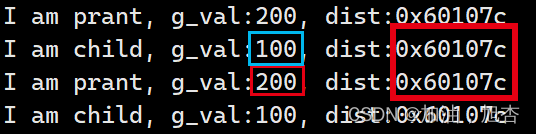
我们可以通过一个特别的代码来看到一个奇怪的现象:就是在同一个地址空间中,对于同一个变量的值是不同的,是不是感到很奇怪。在我们的认知和印象中,对于一个地址空间来说,只会有一个变量的大小,而不会出现多个值在同一个地址空间的现象,所以我们推断出这个地址空间一定不会是真正的物理地址,而是一种虚拟的地址空间。
进程 = 内核数据结构 + 代码(只读) + 数据,所以父子进程是具有独立性的。父子进程有一个进程退出不会影响其他进程。
#include
#include
#include
#include
#include
#include
#include
using namespace std;
int g_val = 100;
int main()
{
pid_t id = fork();
if(id == 0)
{
while (true)
{
cout << "I am child, g_val:" << g_val << ", dist:" << &g_val << endl;
sleep(1);
}
}
else if(id > 0)
{
g_val = 200;
while (true)
{
cout << "I am prant, g_val:" << g_val << ", dist:" << & g_val << endl;
sleep(1);
}
}
return 0;
}
1.2 看一看内存空间分布
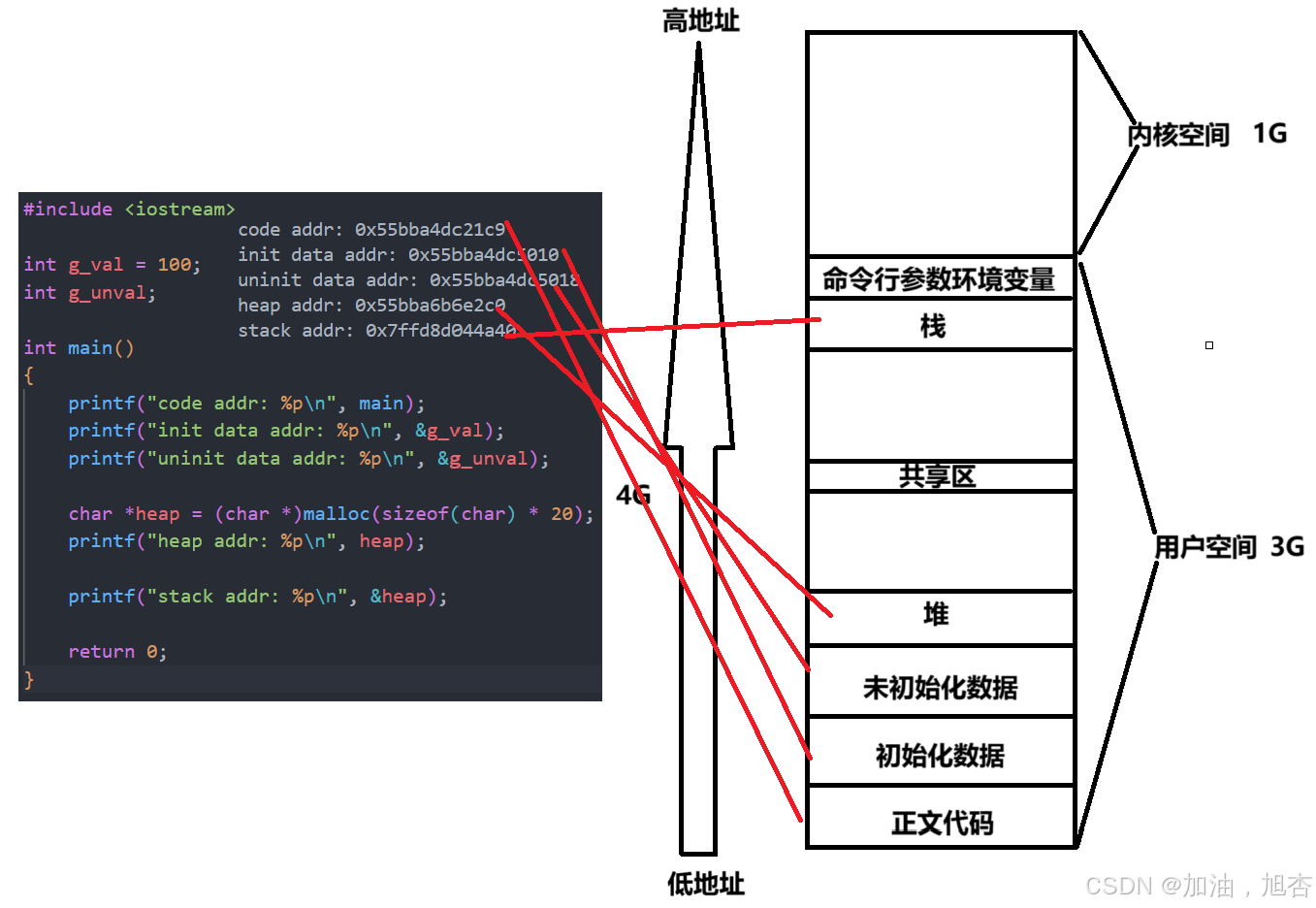
命令行参数和环境变量,无论是表还是表中指向的选项,都是在栈的上层。 平时在代码中存储的变量一般在栈区,但是被static修饰后,这个地址就会








